 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Tuning of Large Language Models for Knowledge-Grounded Dialogue Generation
Apr 10, 2025Large language models (LLMs) demonstrate remarkable text comprehension and generation capabilities but often lack the ability to utilize up-to-date or domain-specific knowledge not included in their training data. To address this gap, we introduce KEDiT, an efficient method for fine-tuning LLMs for knowledge-grounded dialogue generation. KEDiT operates in two main phases: first, it employs an information bottleneck to compress retrieved knowledge into learnable parameters, retaining essential information while minimizing computational overhead. Second, a lightweight knowledge-aware adapter integrates these compressed knowledge vectors into the LLM during fine-tuning, updating less than 2\% of the model parameters. The experimental results on the Wizard of Wikipedia and a newly constructed PubMed-Dialog dataset demonstrate that KEDiT excels in generating contextually relevant and informative responses, outperforming competitive baselines in automatic, LLM-based, and human evaluations. This approach effectively combines the strengths of pretrained LLMs with the adaptability needed for incorporating dynamic knowledge, presenting a scalable solution for fields such as medicine.
OmniCaptioner: One Captioner to Rule Them All
Apr 09, 2025We propose OmniCaptioner, a versatile visual captioning framework for generating fine-grained textual descriptions across a wide variety of visual domains. Unlike prior methods limited to specific image types (e.g., natural images or geometric visuals), our framework provides a unified solution for captioning natural images, visual text (e.g., posters, UIs, textbooks), and structured visuals (e.g., documents, tables, charts). By converting low-level pixel information into semantically rich textual representations, our framework bridges the gap between visual and textual modalities. Our results highlight three key advantages: (i) Enhanced Visual Reasoning with LLMs, where long-context captions of visual modalities empower LLMs, particularly the DeepSeek-R1 series, to reason effectively in multimodal scenarios; (ii) Improved Image Generation, where detailed captions improve tasks like text-to-image generation and image transformation; and (iii) Efficient Supervised Fine-Tuning (SFT), which enables faster convergence with less data. We believe the versatility and adaptability of OmniCaptioner can offer a new perspective for bridging the gap between language and visual modalities.
Computational Efficient Informative Nonignorable Matrix Completion: A Row- and Column-Wise Matrix U-Statistic Pseudo-Likelihood Approach
Apr 05, 2025In this study, we establish a unified framework to deal with the high dimensional matrix completion problem under flexible nonignorable missing mechanisms. Although the matrix completion problem has attracted much attention over the years, there are very sparse works that consider the nonignorable missing mechanism. To address this problem, we derive a row- and column-wise matrix U-statistics type loss function, with the nuclear norm for regularization. A singular value proximal gradient algorithm is developed to solve the proposed optimization problem. We prove the non-asymptotic upper bound of the estimation error's Frobenius norm and show the performance of our method through numerical simulations and real data analysis.
Multi-Dimensional AGV Path Planning in 3D Warehouses Using Ant Colony Optimization and Advanced Neural Networks
Mar 30, 2025Within modern warehouse scenarios, the rapid expansion of e-commerce and increasingly complex, multi-level storage environments have exposed the limitations of traditional AGV (Automated Guided Vehicle) path planning methods--often reliant on static 2D models and expert-tuned heuristics that struggle to handle dynamic traffic and congestion. Addressing these limitations, this paper introduces a novel AGV path planning approach for 3D warehouse environments that leverages a hybrid framework combining ACO (Ant Colony Optimization) with deep learning models, called NAHACO (Neural Adaptive Heuristic Ant Colony Optimization). NAHACO integrates three key innovations: first, an innovative heuristic algorithm for 3D warehouse cargo modeling using multidimensional tensors, which addresses the challenge of achieving superior heuristic accuracy; second, integration of a congestion-aware loss function within the ACO framework to adjust path costs based on traffic and capacity constraints, called CARL (Congestion-Aware Reinforce Loss), enabling dynamic heuristic calibration for optimizing ACO-based path planning; and third, an adaptive attention mechanism that captures multi-scale spatial features, thereby addressing dynamic heuristic calibration for further optimization of ACO-based path planning and AGV navigation. NAHACO significantly boosts path planning efficiency, yielding faster computation times and superior performance over both vanilla and state-of-the-art methods, while automatically adapting to warehouse constraints for real-time optimization. NAHACO outperforms state-of-the-art methods, lowering the total cost by up to 24.7% on TSP benchmarks. In warehouse tests, NAHACO cuts cost by up to 41.5% and congestion by up to 56.1% compared to previous methods.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025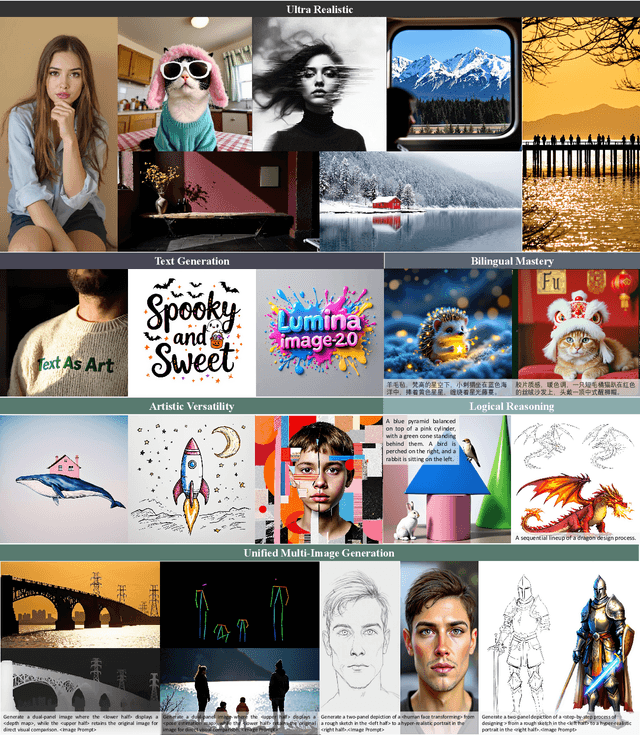
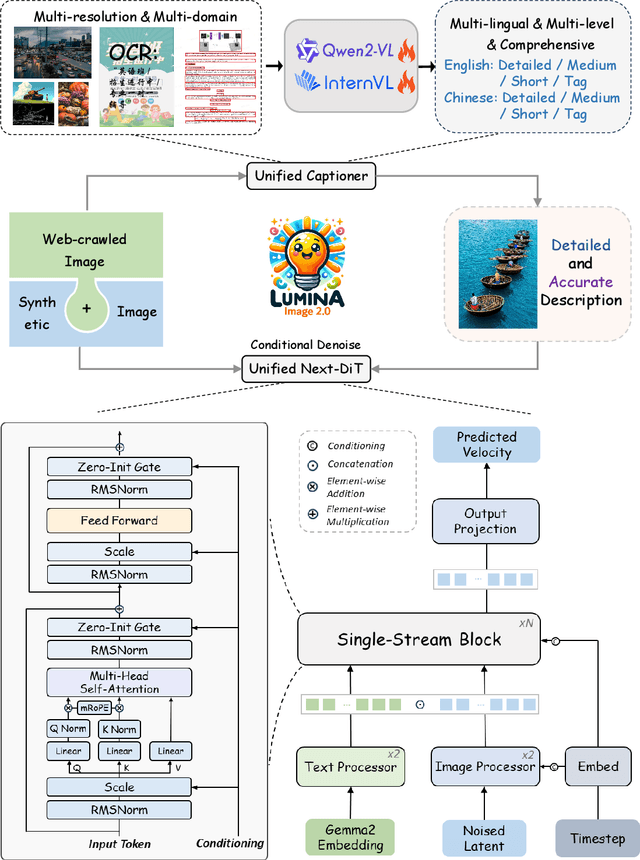

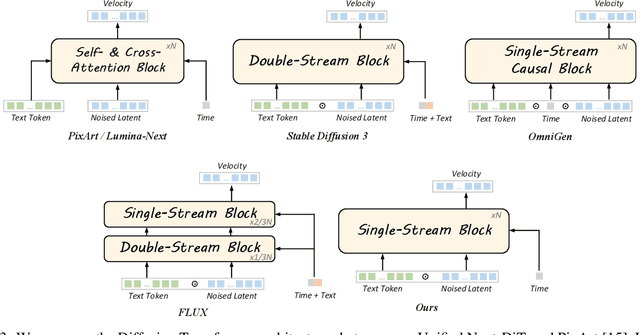
We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
BACE-RUL: A Bi-directional Adversarial Network with Covariate Encoding for Machine Remaining Useful Life Prediction
Mar 14, 2025Prognostic and Health Management (PHM) are crucial ways to avoid unnecessary maintenance for Cyber-Physical Systems (CPS) and improve system reliability. Predicting the Remaining Useful Life (RUL) is one of the most challenging tasks for PHM. Existing methods require prior knowledge about the system, contrived assumptions, or temporal mining to model the life cycles of machine equipment/devices, resulting in diminished accuracy and limited applicability in real-world scenarios. This paper proposes a Bi-directional Adversarial network with Covariate Encoding for machine Remaining Useful Life (BACE-RUL) prediction, which only adopts sensor measurements from the current life cycle to predict RUL rather than relying on previous consecutive cycle recordings. The current sensor measurements of mechanical devices are encoded to a conditional space to better understand the implicit inner mechanical status. The predictor is trained as a conditional generative network with the encoded sensor measurements as its conditions. Various experiments on several real-world datasets, including the turbofan aircraft engine dataset and the dataset collected from degradation experiments of Li-Ion battery cells, show that the proposed model is a general framework and outperforms state-of-the-art methods.
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Mar 13, 2025Large Language Models have demonstrated remarkable reasoning capability in complex textual tasks. However, multimodal reasoning, which requires integrating visual and textual information, remains a significant challenge. Existing visual-language models often struggle to effectively analyze and reason visual content, resulting in suboptimal performance on complex reasoning tasks. Moreover, the absence of comprehensive benchmarks hinders the accurate assessment of multimodal reasoning capabilities. In this paper, we introduce R1-Onevision, a multimodal reasoning model designed to bridge the gap between visual perception and deep reasoning. To achieve this, we propose a cross-modal reasoning pipeline that transforms images into formal textural representations, enabling precise language-based reasoning. Leveraging this pipeline, we construct the R1-Onevision dataset which provides detailed, step-by-step multimodal reasoning annotations across diverse domains. We further develop the R1-Onevision model through supervised fine-tuning and reinforcement learning to cultivate advanced reasoning and robust generalization abilities. To comprehensively evaluate multimodal reasoning performance across different grades, we introduce R1-Onevision-Bench, a benchmark aligned with human educational stages, covering exams from junior high school to university and beyond. Experimental results show that R1-Onevision achieves state-of-the-art performance, outperforming models such as GPT-4o and Qwen2.5-VL on multiple challenging multimodal reasoning benchmarks.
JiSAM: Alleviate Labeling Burden and Corner Case Problems in Autonomous Driving via Minimal Real-World Data
Mar 13, 2025Deep-learning-based autonomous driving (AD) perception introduces a promising picture for safe and environment-friendly transportation. However, the over-reliance on real labeled data in LiDAR perception limits the scale of on-road attempts. 3D real world data is notoriously time-and-energy-consuming to annotate and lacks corner cases like rare traffic participants. On the contrary, in simulators like CARLA, generating labeled LiDAR point clouds with corner cases is a piece of cake. However, introducing synthetic point clouds to improve real perception is non-trivial. This stems from two challenges: 1) sample efficiency of simulation datasets 2) simulation-to-real gaps. To overcome both challenges, we propose a plug-and-play method called JiSAM , shorthand for Jittering augmentation, domain-aware backbone and memory-based Sectorized AlignMent. In extensive experiments conducted on the famous AD dataset NuScenes, we demonstrate that, with SOTA 3D object detector, JiSAM is able to utilize the simulation data and only labels on 2.5% available real data to achieve comparable performance to models trained on all real data. Additionally, JiSAM achieves more than 15 mAPs on the objects not labeled in the real training set. We will release models and codes.
Temporal Overlapping Prediction: A Self-supervised Pre-training Method for LiDAR Moving Object Segmentation
Mar 10, 2025



Moving object segmentation (MOS) on LiDAR point clouds is crucial for autonomous systems like self-driving vehicles. Previous supervised approaches rely heavily on costly manual annotations, while LiDAR sequences naturally capture temporal motion cues that can be leveraged for self-supervised learning. In this paper, we propose \textbf{T}emporal \textbf{O}verlapping \textbf{P}rediction (\textbf{TOP}), a self-supervised pre-training method that alleviate the labeling burden for MOS. \textbf{TOP} explores the temporal overlapping points that commonly observed by current and adjacent scans, and learns spatiotemporal representations by predicting the occupancy states of temporal overlapping points. Moreover, we utilize current occupancy reconstruction as an auxiliary pre-training objective, which enhances the current structural awareness of the model. We conduct extensive experiments and observe that the conventional metric Intersection-over-Union (IoU) shows strong bias to objects with more scanned points, which might neglect small or distant objects. To compensate for this bias, we introduce an additional metric called $\text{mIoU}_{\text{obj}}$ to evaluate object-level performance. Experiments on nuScenes and SemanticKITTI show that \textbf{TOP} outperforms both supervised training-from-scratch baseline and other self-supervised pre-training baselines by up to 28.77\% relative improvement, demonstrating strong transferability across LiDAR setups and generalization to other tasks. Code and pre-trained models will be publicly available upon publication.