 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback
Aug 17, 2025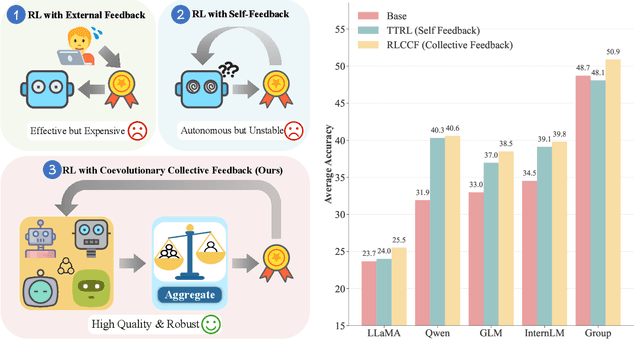
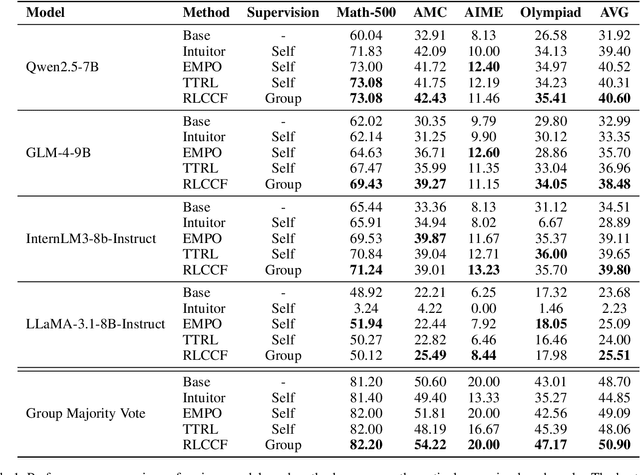
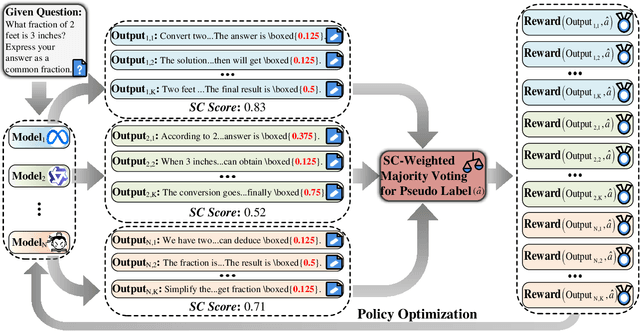
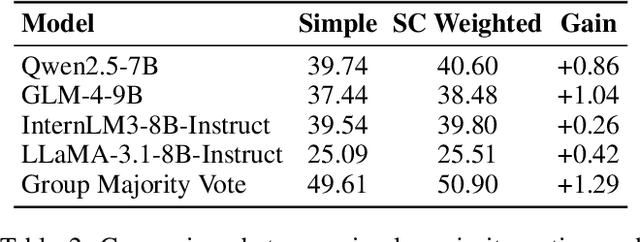
Reinforcement learning (RL) has significantly enhanced the reasoning capabilities of large language models (LLMs), but its reliance on expensive human-labeled data or complex reward models severely limits scalability. While existing self-feedback methods aim to address this problem, they are constrained by the capabilities of a single model, which can lead to overconfidence in incorrect answers, reward hacking, and even training collapse. To this end, we propose Reinforcement Learning from Coevolutionary Collective Feedback (RLCCF), a novel RL framework that enables multi-model collaborative evolution without external supervision. Specifically, RLCCF optimizes the ability of a model collective by maximizing its Collective Consistency (CC), which jointly trains a diverse ensemble of LLMs and provides reward signals by voting on collective outputs. Moreover, each model's vote is weighted by its Self-Consistency (SC) score, ensuring that more confident models contribute more to the collective decision. Benefiting from the diverse output distributions and complementary abilities of multiple LLMs, RLCCF enables the model collective to continuously enhance its reasoning ability through coevolution. Experiments on four mainstream open-source LLMs across four mathematical reasoning benchmarks demonstrate that our framework yields significant performance gains, achieving an average relative improvement of 16.72\% in accuracy. Notably, RLCCF not only improves the performance of individual models but also enhances the group's majority-voting accuracy by 4.51\%, demonstrating its ability to extend the collective capability boundary of the model collective.
JanusNet: Hierarchical Slice-Block Shuffle and Displacement for Semi-Supervised 3D Multi-Organ Segmentation
Aug 06, 2025



Limited by the scarcity of training samples and annotations, weakly supervised medical image segmentation often employs data augmentation to increase data diversity, while randomly mixing volumetric blocks has demonstrated strong performance. However, this approach disrupts the inherent anatomical continuity of 3D medical images along orthogonal axes, leading to severe structural inconsistencies and insufficient training in challenging regions, such as small-sized organs, etc. To better comply with and utilize human anatomical information, we propose JanusNet}, a data augmentation framework for 3D medical data that globally models anatomical continuity while locally focusing on hard-to-segment regions. Specifically, our Slice-Block Shuffle step performs aligned shuffling of same-index slice blocks across volumes along a random axis, while preserving the anatomical context on planes perpendicular to the perturbation axis. Concurrently, the Confidence-Guided Displacement step uses prediction reliability to replace blocks within each slice, amplifying signals from difficult areas. This dual-stage, axis-aligned framework is plug-and-play, requiring minimal code changes for most teacher-student schemes. Extensive experiments on the Synapse and AMOS datasets demonstrate that JanusNet significantly surpasses state-of-the-art methods, achieving, for instance, a 4% DSC gain on the Synapse dataset with only 20% labeled data.
Agentar-Fin-R1: Enhancing Financial Intelligence through Domain Expertise, Training Efficiency, and Advanced Reasoning
Jul 24, 2025Large Language Models (LLMs) exhibit considerable promise in financial applications; however, prevailing models frequently demonstrate limitations when confronted with scenarios that necessitate sophisticated reasoning capabilities, stringent trustworthiness criteria, and efficient adaptation to domain-specific requirements. We introduce the Agentar-Fin-R1 series of financial large language models (8B and 32B parameters), specifically engineered based on the Qwen3 foundation model to enhance reasoning capabilities, reliability, and domain specialization for financial applications. Our optimization approach integrates a high-quality, systematic financial task label system with a comprehensive multi-layered trustworthiness assurance framework. This framework encompasses high-quality trustworthy knowledge engineering, multi-agent trustworthy data synthesis, and rigorous data validation governance. Through label-guided automated difficulty-aware optimization, tow-stage training pipeline, and dynamic attribution systems, we achieve substantial improvements in training efficiency. Our models undergo comprehensive evaluation on mainstream financial benchmarks including Fineva, FinEval, and FinanceIQ, as well as general reasoning datasets such as MATH-500 and GPQA-diamond. To thoroughly assess real-world deployment capabilities, we innovatively propose the Finova evaluation benchmark, which focuses on agent-level financial reasoning and compliance verification. Experimental results demonstrate that Agentar-Fin-R1 not only achieves state-of-the-art performance on financial tasks but also exhibits exceptional general reasoning capabilities, validating its effectiveness as a trustworthy solution for high-stakes financial applications. The Finova bench is available at https://github.com/antgroup/Finova.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
FADE: Adversarial Concept Erasure in Flow Models
Jul 16, 2025

Diffusion models have demonstrated remarkable image generation capabilities, but also pose risks in privacy and fairness by memorizing sensitive concepts or perpetuating biases. We propose a novel \textbf{concept erasure} method for text-to-image diffusion models, designed to remove specified concepts (e.g., a private individual or a harmful stereotype) from the model's generative repertoire. Our method, termed \textbf{FADE} (Fair Adversarial Diffusion Erasure), combines a trajectory-aware fine-tuning strategy with an adversarial objective to ensure the concept is reliably removed while preserving overall model fidelity. Theoretically, we prove a formal guarantee that our approach minimizes the mutual information between the erased concept and the model's outputs, ensuring privacy and fairness. Empirically, we evaluate FADE on Stable Diffusion and FLUX, using benchmarks from prior work (e.g., object, celebrity, explicit content, and style erasure tasks from MACE). FADE achieves state-of-the-art concept removal performance, surpassing recent baselines like ESD, UCE, MACE, and ANT in terms of removal efficacy and image quality. Notably, FADE improves the harmonic mean of concept removal and fidelity by 5--10\% over the best prior method. We also conduct an ablation study to validate each component of FADE, confirming that our adversarial and trajectory-preserving objectives each contribute to its superior performance. Our work sets a new standard for safe and fair generative modeling by unlearning specified concepts without retraining from scratch.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
VIS-Shepherd: Constructing Critic for LLM-based Data Visualization Generation
Jun 16, 2025Data visualization generation using Large Language Models (LLMs) has shown promising results but often produces suboptimal visualizations that require human intervention for improvement. In this work, we introduce VIS-Shepherd, a specialized Multimodal Large Language Model (MLLM)-based critic to evaluate and provide feedback for LLM-generated data visualizations. At the core of our approach is a framework to construct a high-quality visualization critique dataset, where we collect human-created visualization instances, synthesize corresponding LLM-generated instances, and construct high-quality critiques. We conduct both model-based automatic evaluation and human preference studies to evaluate the effectiveness of our approach. Our experiments show that even small (7B parameters) open-source MLLM models achieve substantial performance gains by leveraging our high-quality visualization critique dataset, reaching levels comparable to much larger open-source or even proprietary models. Our work demonstrates significant potential for MLLM-based automated visualization critique and indicates promising directions for enhancing LLM-based data visualization generation. Our project page: https://github.com/bopan3/VIS-Shepherd.
Wavelet-based Disentangled Adaptive Normalization for Non-stationary Times Series Forecasting
Jun 06, 2025Forecasting non-stationary time series is a challenging task because their statistical properties often change over time, making it hard for deep models to generalize well. Instance-level normalization techniques can help address shifts in temporal distribution. However, most existing methods overlook the multi-component nature of time series, where different components exhibit distinct non-stationary behaviors. In this paper, we propose Wavelet-based Disentangled Adaptive Normalization (WDAN), a model-agnostic framework designed to address non-stationarity in time series forecasting. WDAN uses discrete wavelet transforms to break down the input into low-frequency trends and high-frequency fluctuations. It then applies tailored normalization strategies to each part. For trend components that exhibit strong non-stationarity, we apply first-order differencing to extract stable features used for predicting normalization parameters. Extensive experiments on multiple benchmarks demonstrate that WDAN consistently improves forecasting accuracy across various backbone model. Code is available at this repository: https://github.com/MonBG/WDAN.
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
May 29, 2025The emergence of large language model (LLM)-based agents has significantly advanced the development of autonomous machine learning (ML) engineering. However, most existing approaches rely heavily on manual prompt engineering, failing to adapt and optimize based on diverse experimental experiences. Focusing on this, for the first time, we explore the paradigm of learning-based agentic ML, where an LLM agent learns through interactive experimentation on ML tasks using online reinforcement learning (RL). To realize this, we propose a novel agentic ML training framework with three key components: (1) exploration-enriched fine-tuning, which enables LLM agents to generate diverse actions for enhanced RL exploration; (2) step-wise RL, which enables training on a single action step, accelerating experience collection and improving training efficiency; (3) an agentic ML-specific reward module, which unifies varied ML feedback signals into consistent rewards for RL optimization. Leveraging this framework, we train ML-Agent, driven by a 7B-sized Qwen-2.5 LLM for autonomous ML. Remarkably, despite being trained on merely 9 ML tasks, our 7B-sized ML-Agent outperforms the 671B-sized DeepSeek-R1 agent. Furthermore, it achieves continuous performance improvements and demonstrates exceptional cross-task generalization capabilities.
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
May 27, 2025Logical reasoning is a fundamental aspect of human intelligence and an essential capability for multimodal large language models (MLLMs). Despite the significant advancement in multimodal reasoning, existing benchmarks fail to comprehensively evaluate their reasoning abilities due to the lack of explicit categorization for logical reasoning types and an unclear understanding of reasoning. To address these issues, we introduce MME-Reasoning, a comprehensive benchmark designed to evaluate the reasoning ability of MLLMs, which covers all three types of reasoning (i.e., inductive, deductive, and abductive) in its questions. We carefully curate the data to ensure that each question effectively evaluates reasoning ability rather than perceptual skills or knowledge breadth, and extend the evaluation protocols to cover the evaluation of diverse questions. Our evaluation reveals substantial limitations of state-of-the-art MLLMs when subjected to holistic assessments of logical reasoning capabilities. Even the most advanced MLLMs show limited performance in comprehensive logical reasoning, with notable performance imbalances across reasoning types. In addition, we conducted an in-depth analysis of approaches such as ``thinking mode'' and Rule-based RL, which are commonly believed to enhance reasoning abilities. These findings highlight the critical limitations and performance imbalances of current MLLMs in diverse logical reasoning scenarios, providing comprehensive and systematic insights into the understanding and evaluation of reasoning capabilities.