 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Beyond Distributions in Testing Machine Learned Models
Dec 06, 2021Testing practices within the machine learning (ML) community have centered around assessing a learned model's predictive performance measured against a test dataset, often drawn from the same distribution as the training dataset. While recent work on robustness and fairness testing within the ML community has pointed to the importance of testing against distributional shifts, these efforts also focus on estimating the likelihood of the model making an error against a reference dataset/distribution. We argue that this view of testing actively discourages researchers and developers from looking into other sources of robustness failures, for instance corner cases which may have severe undesirable impacts. We draw parallels with decades of work within software engineering testing focused on assessing a software system against various stress conditions, including corner cases, as opposed to solely focusing on average-case behaviour. Finally, we put forth a set of recommendations to broaden the view of machine learning testing to a rigorous practice.
* Neural Information Processing System, NeurIPS 2021 workshop on Distribution Shifts
Re-imagining Algorithmic Fairness in India and Beyond
Jan 27, 2021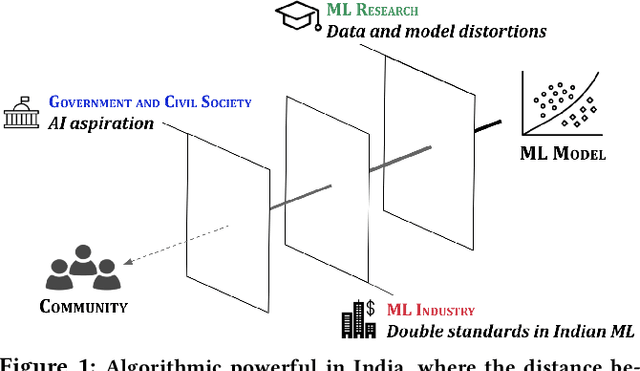

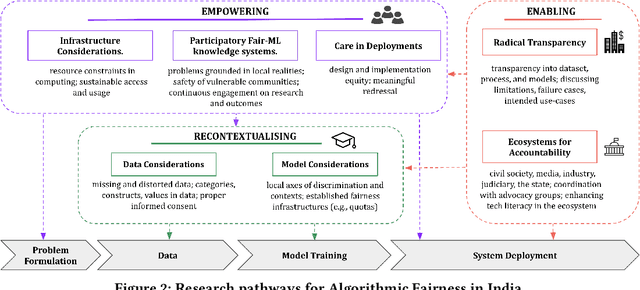
Conventional algorithmic fairness is West-centric, as seen in its sub-groups, values, and methods. In this paper, we de-center algorithmic fairness and analyse AI power in India. Based on 36 qualitative interviews and a discourse analysis of algorithmic deployments in India, we find that several assumptions of algorithmic fairness are challenged. We find that in India, data is not always reliable due to socio-economic factors, ML makers appear to follow double standards, and AI evokes unquestioning aspiration. We contend that localising model fairness alone can be window dressing in India, where the distance between models and oppressed communities is large. Instead, we re-imagine algorithmic fairness in India and provide a roadmap to re-contextualise data and models, empower oppressed communities, and enable Fair-ML ecosystems.
Non-portability of Algorithmic Fairness in India
Dec 08, 2020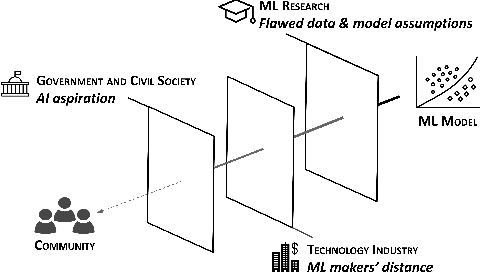
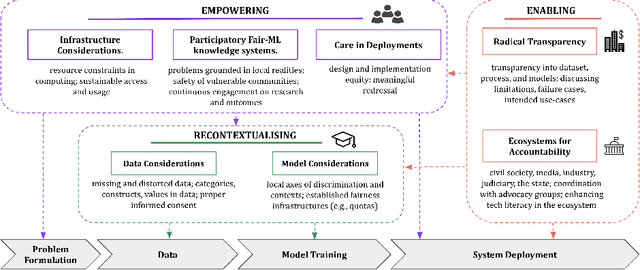
Conventional algorithmic fairness is Western in its sub-groups, values, and optimizations. In this paper, we ask how portable the assumptions of this largely Western take on algorithmic fairness are to a different geo-cultural context such as India. Based on 36 expert interviews with Indian scholars, and an analysis of emerging algorithmic deployments in India, we identify three clusters of challenges that engulf the large distance between machine learning models and oppressed communities in India. We argue that a mere translation of technical fairness work to Indian subgroups may serve only as a window dressing, and instead, call for a collective re-imagining of Fair-ML, by re-contextualising data and models, empowering oppressed communities, and more importantly, enabling ecosystems.
Fairness Preferences, Actual and Hypothetical: A Study of Crowdworker Incentives
Dec 08, 2020
How should we decide which fairness criteria or definitions to adopt in machine learning systems? To answer this question, we must study the fairness preferences of actual users of machine learning systems. Stringent parity constraints on treatment or impact can come with trade-offs, and may not even be preferred by the social groups in question (Zafar et al., 2017). Thus it might be beneficial to elicit what the group's preferences are, rather than rely on a priori defined mathematical fairness constraints. Simply asking for self-reported rankings of users is challenging because research has shown that there are often gaps between people's stated and actual preferences(Bernheim et al., 2013). This paper outlines a research program and experimental designs for investigating these questions. Participants in the experiments are invited to perform a set of tasks in exchange for a base payment--they are told upfront that they may receive a bonus later on, and the bonus could depend on some combination of output quantity and quality. The same group of workers then votes on a bonus payment structure, to elicit preferences. The voting is hypothetical (not tied to an outcome) for half the group and actual (tied to the actual payment outcome) for the other half, so that we can understand the relation between a group's actual preferences and hypothetical (stated) preferences. Connections and lessons from fairness in machine learning are explored.
Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure
Oct 23, 2020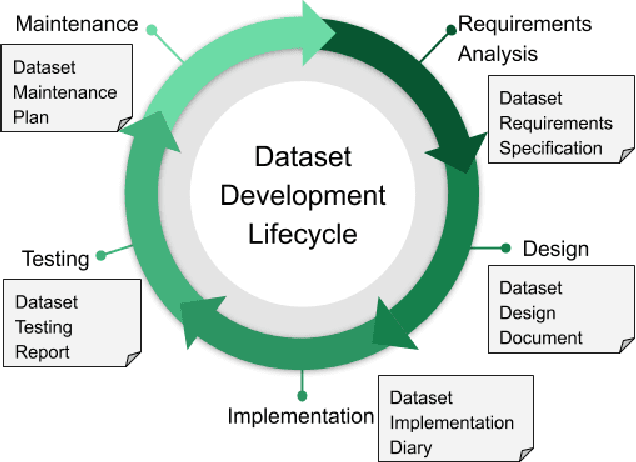

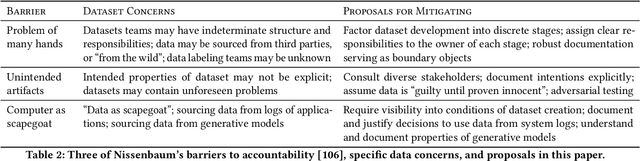
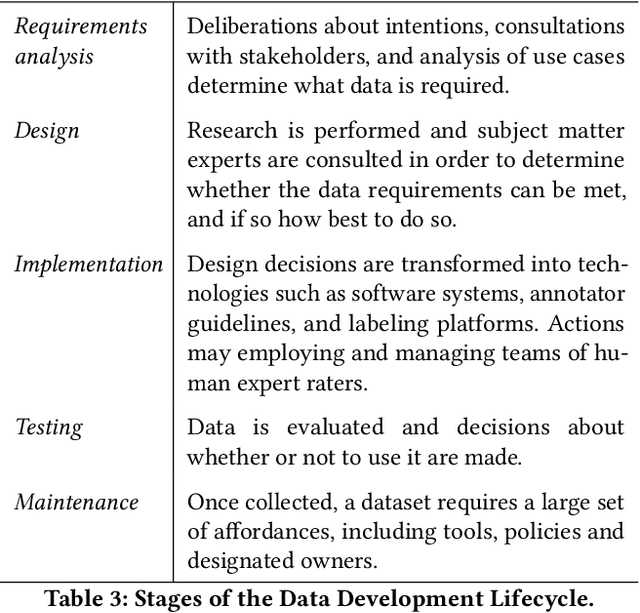
Rising concern for the societal implications of artificial intelligence systems has inspired demands for greater transparency and accountability. However the datasets which empower machine learning are often used, shared and re-used with little visibility into the processes of deliberation which led to their creation. Which stakeholder groups had their perspectives included when the dataset was conceived? Which domain experts were consulted regarding how to model subgroups and other phenomena? How were questions of representational biases measured and addressed? Who labeled the data? In this paper, we introduce a rigorous framework for dataset development transparency which supports decision-making and accountability. The framework uses the cyclical, infrastructural and engineering nature of dataset development to draw on best practices from the software development lifecycle. Each stage of the data development lifecycle yields a set of documents that facilitate improved communication and decision-making, as well as drawing attention the value and necessity of careful data work. The proposed framework is intended to contribute to closing the accountability gap in artificial intelligence systems, by making visible the often overlooked work that goes into dataset creation.
Social Biases in NLP Models as Barriers for Persons with Disabilities
May 02, 2020
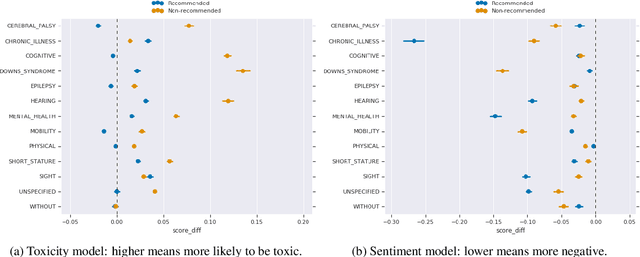
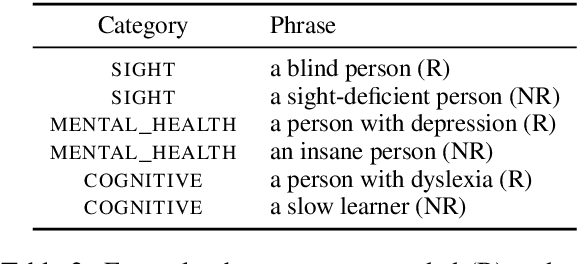
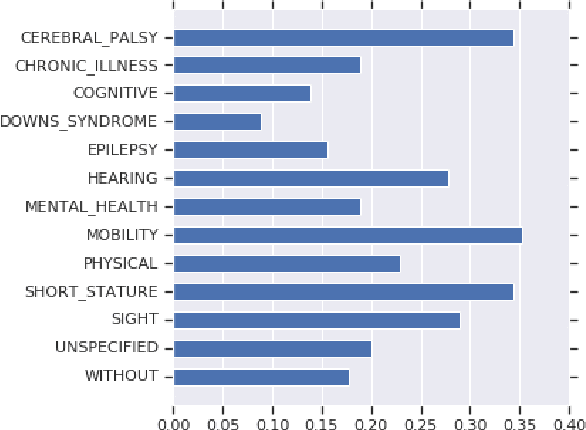
Building equitable and inclusive NLP technologies demands consideration of whether and how social attitudes are represented in ML models. In particular, representations encoded in models often inadvertently perpetuate undesirable social biases from the data on which they are trained. In this paper, we present evidence of such undesirable biases towards mentions of disability in two different English language models: toxicity prediction and sentiment analysis. Next, we demonstrate that the neural embeddings that are the critical first step in most NLP pipelines similarly contain undesirable biases towards mentions of disability. We end by highlighting topical biases in the discourse about disability which may contribute to the observed model biases; for instance, gun violence, homelessness, and drug addiction are over-represented in texts discussing mental illness.
* ACL 2020 short paper. 5 pages
Diversity and Inclusion Metrics in Subset Selection
Feb 09, 2020


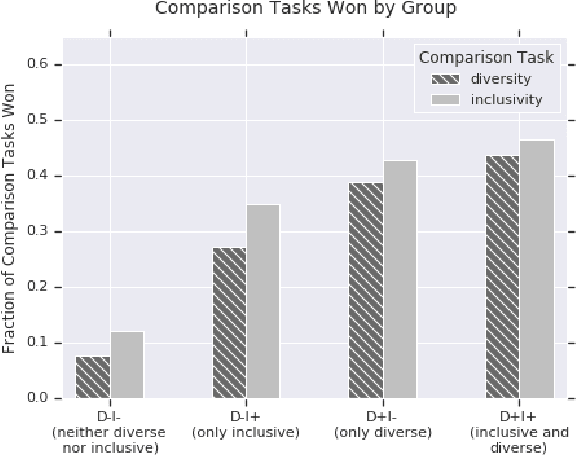
The ethical concept of fairness has recently been applied in machine learning (ML) settings to describe a wide range of constraints and objectives. When considering the relevance of ethical concepts to subset selection problems, the concepts of diversity and inclusion are additionally applicable in order to create outputs that account for social power and access differentials. We introduce metrics based on these concepts, which can be applied together, separately, and in tandem with additional fairness constraints. Results from human subject experiments lend support to the proposed criteria. Social choice methods can additionally be leveraged to aggregate and choose preferable sets, and we detail how these may be applied.
Advances and Open Problems in Federated Learning
Dec 10, 2019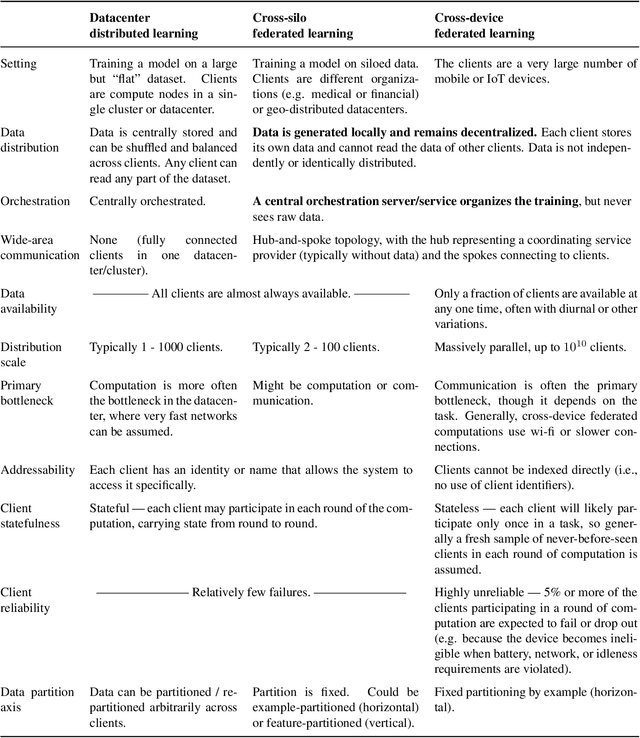
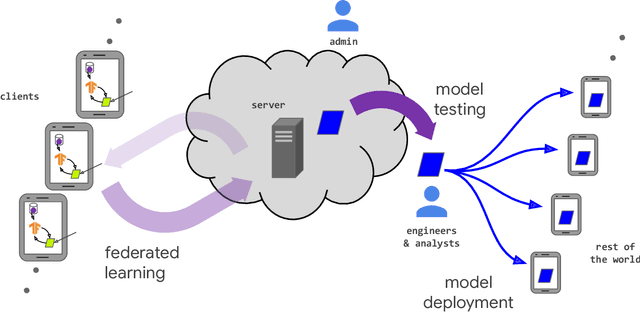
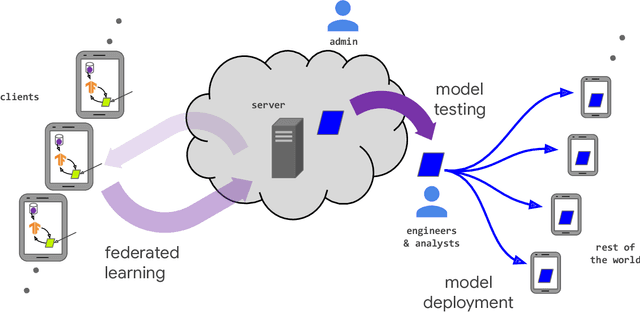

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Perturbation Sensitivity Analysis to Detect Unintended Model Biases
Oct 09, 2019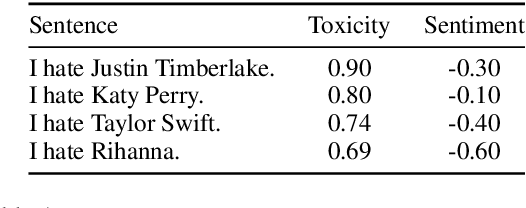
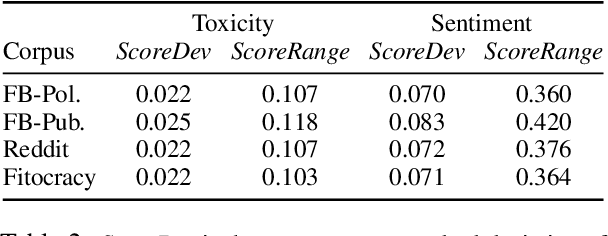
Data-driven statistical Natural Language Processing (NLP) techniques leverage large amounts of language data to build models that can understand language. However, most language data reflect the public discourse at the time the data was produced, and hence NLP models are susceptible to learning incidental associations around named referents at a particular point in time, in addition to general linguistic meaning. An NLP system designed to model notions such as sentiment and toxicity should ideally produce scores that are independent of the identity of such entities mentioned in text and their social associations. For example, in a general purpose sentiment analysis system, a phrase such as I hate Katy Perry should be interpreted as having the same sentiment as I hate Taylor Swift. Based on this idea, we propose a generic evaluation framework, Perturbation Sensitivity Analysis, which detects unintended model biases related to named entities, and requires no new annotations or corpora. We demonstrate the utility of this analysis by employing it on two different NLP models --- a sentiment model and a toxicity model --- applied on online comments in English language from four different genres.
Detecting Bias with Generative Counterfactual Face Attribute Augmentation
Jun 18, 2019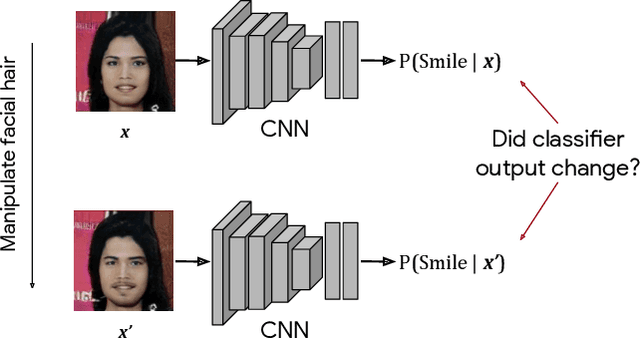

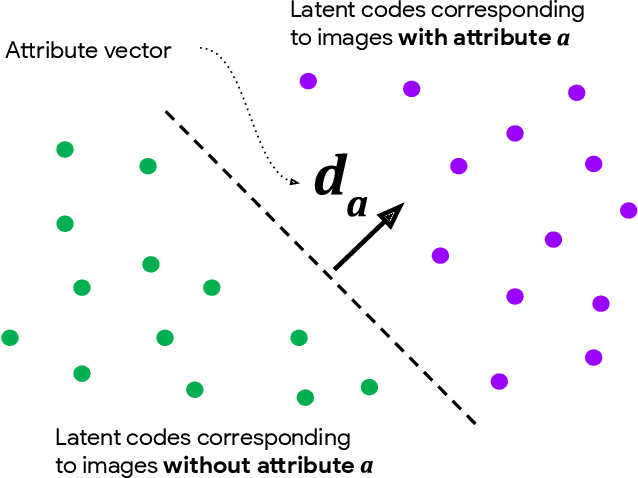
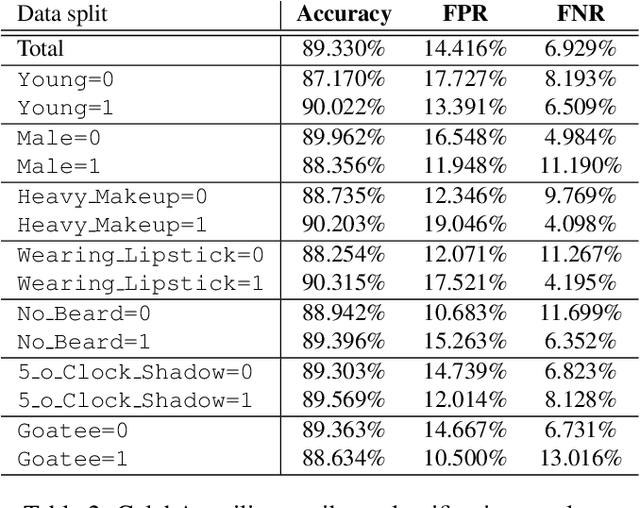
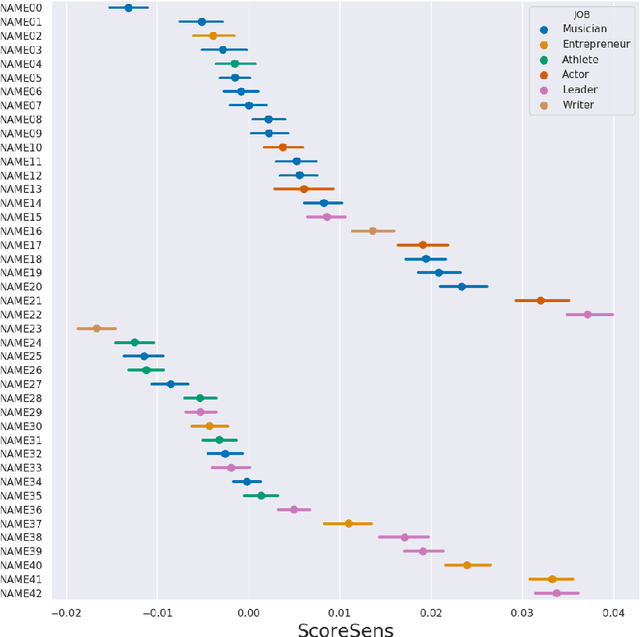
We introduce a simple framework for identifying biases of a smiling attribute classifier. Our method poses counterfactual questions of the form: how would the prediction change if this face characteristic had been different? We leverage recent advances in generative adversarial networks to build a realistic generative model of face images that affords controlled manipulation of specific image characteristics. We introduce a set of metrics that measure the effect of manipulating a specific property of an image on the output of a trained classifier. Empirically, we identify several different factors of variation that affect the predictions of a smiling classifier trained on CelebA.