 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaViT: Aligning Latent Visual Thoughts for Multi-modal Reasoning
Jan 15, 2026Current multimodal latent reasoning often relies on external supervision (e.g., auxiliary images), ignoring intrinsic visual attention dynamics. In this work, we identify a critical Perception Gap in distillation: student models frequently mimic a teacher's textual output while attending to fundamentally divergent visual regions, effectively relying on language priors rather than grounded perception. To bridge this, we propose LaViT, a framework that aligns latent visual thoughts rather than static embeddings. LaViT compels the student to autoregressively reconstruct the teacher's visual semantics and attention trajectories prior to text generation, employing a curriculum sensory gating mechanism to prevent shortcut learning. Extensive experiments show that LaViT significantly enhances visual grounding, achieving up to +16.9% gains on complex reasoning tasks and enabling a compact 3B model to outperform larger open-source variants and proprietary models like GPT-4o.
FedLAD: A Modular and Adaptive Testbed for Federated Log Anomaly Detection
Dec 09, 2025Log-based anomaly detection (LAD) is critical for ensuring the reliability of large-scale distributed systems. However, most existing LAD approaches assume centralized training, which is often impractical due to privacy constraints and the decentralized nature of system logs. While federated learning (FL) offers a promising alternative, there is a lack of dedicated testbeds tailored to the needs of LAD in federated settings. To address this, we present FedLAD, a unified platform for training and evaluating LAD models under FL constraints. FedLAD supports plug-and-play integration of diverse LAD models, benchmark datasets, and aggregation strategies, while offering runtime support for validation logging (self-monitoring), parameter tuning (self-configuration), and adaptive strategy control (self-adaptation). By enabling reproducible and scalable experimentation, FedLAD bridges the gap between FL frameworks and LAD requirements, providing a solid foundation for future research. Project code is publicly available at: https://github.com/AA-cityu/FedLAD.
Advancing Autonomous Driving System Testing: Demands, Challenges, and Future Directions
Dec 09, 2025Autonomous driving systems (ADSs) promise improved transportation efficiency and safety, yet ensuring their reliability in complex real-world environments remains a critical challenge. Effective testing is essential to validate ADS performance and reduce deployment risks. This study investigates current ADS testing practices for both modular and end-to-end systems, identifies key demands from industry practitioners and academic researchers, and analyzes the gaps between existing research and real-world requirements. We review major testing techniques and further consider emerging factors such as Vehicle-to-Everything (V2X) communication and foundation models, including large language models and vision foundation models, to understand their roles in enhancing ADS testing. We conducted a large-scale survey with 100 participants from both industry and academia. Survey questions were refined through expert discussions, followed by quantitative and qualitative analyses to reveal key trends, challenges, and unmet needs. Our results show that existing ADS testing techniques struggle to comprehensively evaluate real-world performance, particularly regarding corner case diversity, the simulation to reality gap, the lack of systematic testing criteria, exposure to potential attacks, practical challenges in V2X deployment, and the high computational cost of foundation model-based testing. By further analyzing participant responses together with 105 representative studies, we summarize the current research landscape and highlight major limitations. This study consolidates critical research gaps in ADS testing and outlines key future research directions, including comprehensive testing criteria, cross-model collaboration in V2X systems, cross-modality adaptation for foundation model-based testing, and scalable validation frameworks for large-scale ADS evaluation.
A$^2$Search: Ambiguity-Aware Question Answering with Reinforcement Learning
Oct 09, 2025



Recent advances in Large Language Models (LLMs) and Reinforcement Learning (RL) have led to strong performance in open-domain question answering (QA). However, existing models still struggle with questions that admit multiple valid answers. Standard QA benchmarks, which typically assume a single gold answer, overlook this reality and thus produce inappropriate training signals. Existing attempts to handle ambiguity often rely on costly manual annotation, which is difficult to scale to multi-hop datasets such as HotpotQA and MuSiQue. In this paper, we present A$^2$Search, an annotation-free, end-to-end training framework to recognize and handle ambiguity. At its core is an automated pipeline that detects ambiguous questions and gathers alternative answers via trajectory sampling and evidence verification. The model is then optimized with RL using a carefully designed $\mathrm{AnsF1}$ reward, which naturally accommodates multiple answers. Experiments on eight open-domain QA benchmarks demonstrate that A$^2$Search achieves new state-of-the-art performance. With only a single rollout, A$^2$Search-7B yields an average $\mathrm{AnsF1}@1$ score of $48.4\%$ across four multi-hop benchmarks, outperforming all strong baselines, including the substantially larger ReSearch-32B ($46.2\%$). Extensive analyses further show that A$^2$Search resolves ambiguity and generalizes across benchmarks, highlighting that embracing ambiguity is essential for building more reliable QA systems. Our code, data, and model weights can be found at https://github.com/zfj1998/A2Search
Multi-Strategy Enhanced COA for Path Planning in Autonomous Navigation
Mar 04, 2025



Autonomous navigation is reshaping various domains in people's life by enabling efficient and safe movement in complex environments. Reliable navigation requires algorithmic approaches that compute optimal or near-optimal trajectories while satisfying task-specific constraints and ensuring obstacle avoidance. However, existing methods struggle with slow convergence and suboptimal solutions, particularly in complex environments, limiting their real-world applicability. To address these limitations, this paper presents the Multi-Strategy Enhanced Crayfish Optimization Algorithm (MCOA), a novel approach integrating three key strategies: 1) Refractive Opposition Learning, enhancing population diversity and global exploration, 2) Stochastic Centroid-Guided Exploration, balancing global and local search to prevent premature convergence, and 3) Adaptive Competition-Based Selection, dynamically adjusting selection pressure for faster convergence and improved solution quality. Empirical evaluations underscore the remarkable planning speed and the amazing solution quality of MCOA in both 3D Unmanned Aerial Vehicle (UAV) and 2D mobile robot path planning. Against 11 baseline algorithms, MCOA achieved a 69.2% reduction in computational time and a 16.7% improvement in minimizing overall path cost in 3D UAV scenarios. Furthermore, in 2D path planning, MCOA outperformed baseline approaches by 44% on average, with an impressive 75.6% advantage in the largest 60*60 grid setting. These findings validate MCOA as a powerful tool for optimizing autonomous navigation in complex environments. The source code is available at: https://github.com/coedv-hub/MCOA.
HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks
Oct 16, 2024



Coding tasks have been valuable for evaluating Large Language Models (LLMs), as they demand the comprehension of high-level instructions, complex reasoning, and the implementation of functional programs -- core capabilities for advancing Artificial General Intelligence. Despite the progress in Large Multimodal Models (LMMs), which extend LLMs with visual perception and understanding capabilities, there remains a notable lack of coding benchmarks that rigorously assess these models, particularly in tasks that emphasize visual reasoning. To address this gap, we introduce HumanEval-V, a novel and lightweight benchmark specifically designed to evaluate LMMs' visual understanding and reasoning capabilities through code generation. HumanEval-V includes 108 carefully crafted, entry-level Python coding tasks derived from platforms like CodeForces and Stack Overflow. Each task is adapted by modifying the context and algorithmic patterns of the original problems, with visual elements redrawn to ensure distinction from the source, preventing potential data leakage. LMMs are required to complete the code solution based on the provided visual context and a predefined Python function signature outlining the task requirements. Every task is equipped with meticulously handcrafted test cases to ensure a thorough and reliable evaluation of model-generated solutions. We evaluate 19 state-of-the-art LMMs using HumanEval-V, uncovering significant challenges. Proprietary models like GPT-4o achieve only 13% pass@1 and 36.4% pass@10, while open-weight models with 70B parameters score below 4% pass@1. Ablation studies further reveal the limitations of current LMMs in vision reasoning and coding capabilities. These results underscore key areas for future research to enhance LMMs' capabilities. We have open-sourced our code and benchmark at https://github.com/HumanEval-V/HumanEval-V-Benchmark.
Diverse Title Generation for Stack Overflow Posts with Multiple Sampling Enhanced Transformer
Aug 24, 2022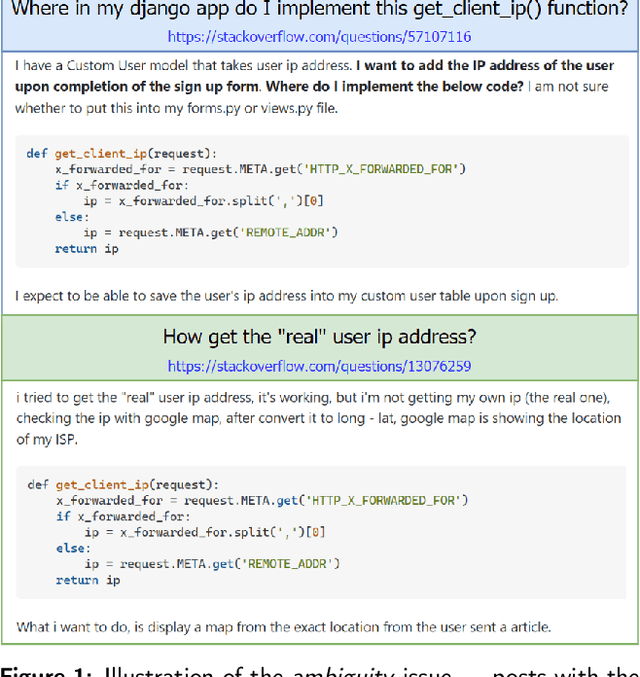
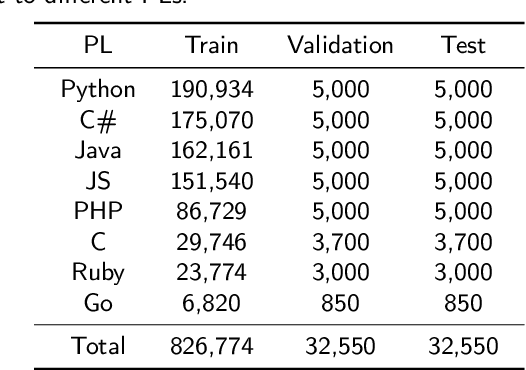
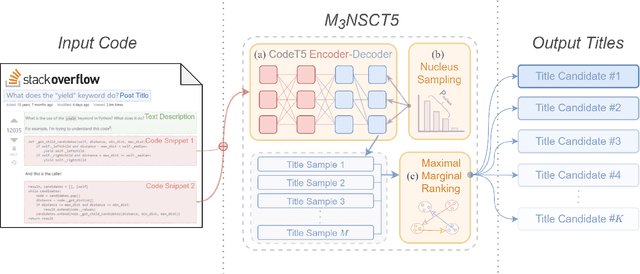

Stack Overflow is one of the most popular programming communities where developers can seek help for their encountered problems. Nevertheless, if inexperienced developers fail to describe their problems clearly, it is hard for them to attract sufficient attention and get the anticipated answers. We propose M$_3$NSCT5, a novel approach to automatically generate multiple post titles from the given code snippets. Developers may use the generated titles to find closely related posts and complete their problem descriptions. M$_3$NSCT5 employs the CodeT5 backbone, which is a pre-trained Transformer model having an excellent language understanding and generation ability. To alleviate the ambiguity issue that the same code snippets could be aligned with different titles under varying contexts, we propose the maximal marginal multiple nucleus sampling strategy to generate multiple high-quality and diverse title candidates at a time for the developers to choose from. We build a large-scale dataset with 890,000 question posts covering eight programming languages to validate the effectiveness of M$_3$NSCT5. The automatic evaluation results on the BLEU and ROUGE metrics demonstrate the superiority of M$_3$NSCT5 over six state-of-the-art baseline models. Moreover, a human evaluation with trustworthy results also demonstrates the great potential of our approach for real-world application.
Improving Stack Overflow question title generation with copying enhanced CodeBERT model and bi-modal information
Sep 27, 2021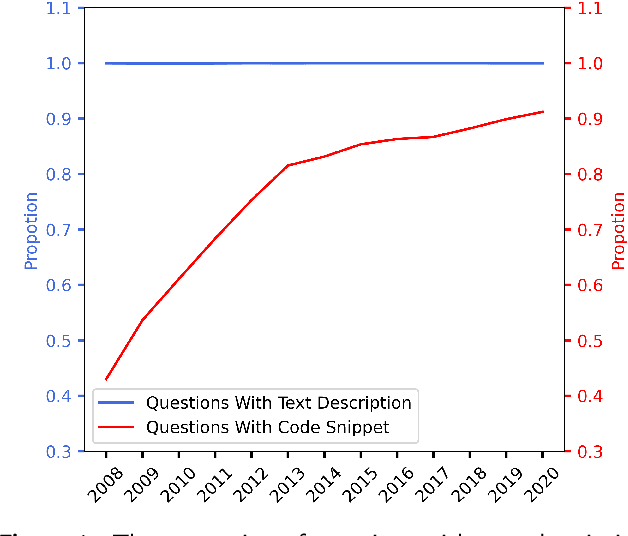
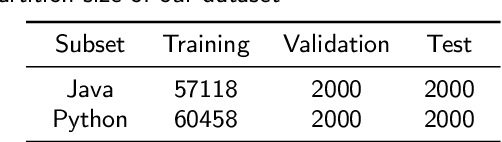
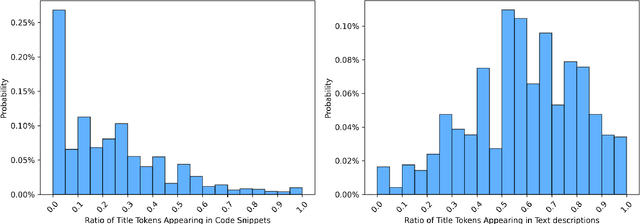
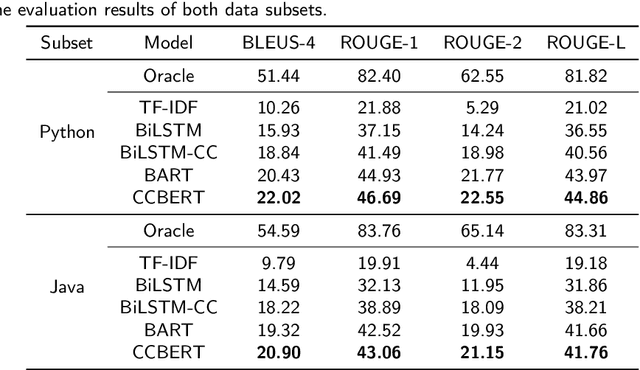
Context: Stack Overflow is very helpful for software developers who are seeking answers to programming problems. Previous studies have shown that a growing number of questions are of low-quality and thus obtain less attention from potential answerers. Gao et al. proposed a LSTM-based model (i.e., BiLSTM-CC) to automatically generate question titles from the code snippets to improve the question quality. However, only using the code snippets in question body cannot provide sufficient information for title generation, and LSTMs cannot capture the long-range dependencies between tokens. Objective: We propose CCBERT, a deep learning based novel model to enhance the performance of question title generation by making full use of the bi-modal information of the entire question body. Methods: CCBERT follows the encoder-decoder paradigm, and uses CodeBERT to encode the question body into hidden representations, a stacked Transformer decoder to generate predicted tokens, and an additional copy attention layer to refine the output distribution. Both the encoder and decoder perform the multi-head self-attention operation to better capture the long-range dependencies. We build a dataset containing more than 120,000 high-quality questions filtered from the data officially published by Stack Overflow to verify the effectiveness of the CCBERT model. Results: CCBERT achieves a better performance on the dataset, and especially outperforms BiLSTM-CC and a multi-purpose pre-trained model (BART) by 14% and 4% on average, respectively. Experiments on both code-only and low-resource datasets also show the superiority of CCBERT with less performance degradation, which are 40% and 13.5% for BiLSTM-CC, while 24% and 5% for CCBERT, respectively.