 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Carbon Capture and Storage Modeling using Fourier Neural Operators
Oct 31, 2022Carbon capture and storage (CCS) is an important strategy for reducing carbon dioxide emissions and mitigating climate change. We consider the storage aspect of CCS, which involves injecting carbon dioxide into underground reservoirs. This requires accurate and high-resolution predictions of carbon dioxide plume migration and reservoir pressure buildup. However, such modeling is challenging at scale due to the high computational costs of existing numerical methods. We introduce a novel machine learning approach for four-dimensional spatial-temporal modeling, which speeds up predictions nearly 700,000 times compared to existing methods. It provides highly accurate predictions under diverse reservoir conditions, geological heterogeneity, and injection schemes. Our framework, Nested Fourier Neural Operator (FNO), learns the solution operator for the family of partial differential equations governing the carbon dioxide-water multiphase flow. It uses a hierarchy of FNO models to produce outputs at different refinement levels. Thus, our approach enables unprecedented real-time high-resolution modeling for carbon dioxide storage.
An Adversarial Active Sampling-based Data Augmentation Framework for Manufacturable Chip Design
Oct 27, 2022Lithography modeling is a crucial problem in chip design to ensure a chip design mask is manufacturable. It requires rigorous simulations of optical and chemical models that are computationally expensive. Recent developments in machine learning have provided alternative solutions in replacing the time-consuming lithography simulations with deep neural networks. However, the considerable accuracy drop still impedes its industrial adoption. Most importantly, the quality and quantity of the training dataset directly affect the model performance. To tackle this problem, we propose a litho-aware data augmentation (LADA) framework to resolve the dilemma of limited data and improve the machine learning model performance. First, we pretrain the neural networks for lithography modeling and a gradient-friendly StyleGAN2 generator. We then perform adversarial active sampling to generate informative and synthetic in-distribution mask designs. These synthetic mask images will augment the original limited training dataset used to finetune the lithography model for improved performance. Experimental results demonstrate that LADA can successfully exploits the neural network capacity by narrowing down the performance gap between the training and testing data instances.
Context Generation Improves Open Domain Question Answering
Oct 12, 2022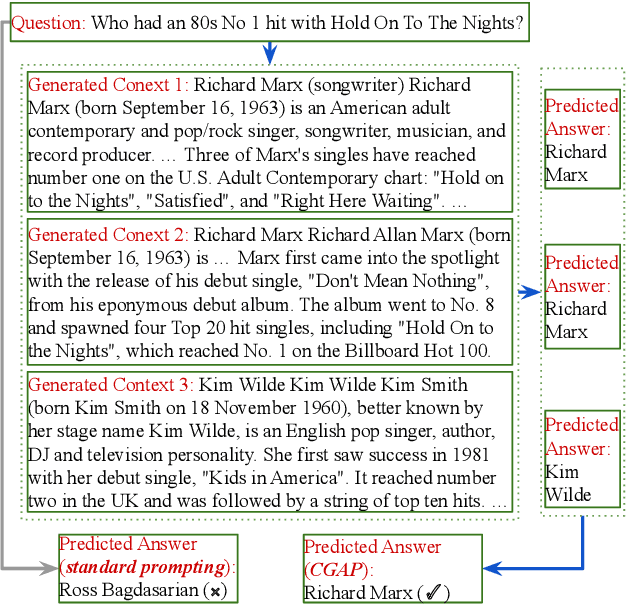

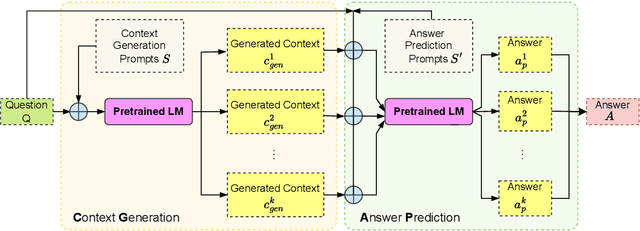
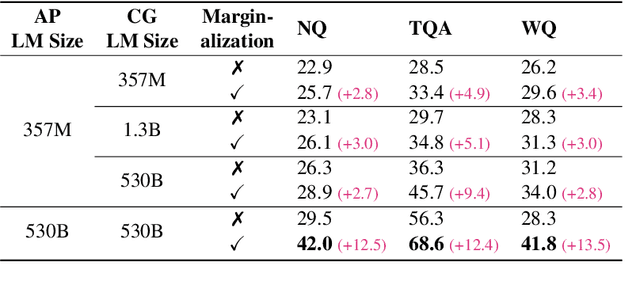
Closed-book question answering (QA) requires a model to directly answer an open-domain question without access to any external knowledge. Prior work on closed-book QA either directly finetunes or prompts a pretrained language model (LM) to leverage the stored knowledge. However, they do not fully exploit the parameterized knowledge. To address this issue, we propose a two-stage, closed-book QA framework which employs a coarse-to-fine approach to extract relevant knowledge and answer a question. Our approach first generates a related context for a given question by prompting a pretrained LM. We then prompt the same LM for answer prediction using the generated context and the question. Additionally, to eliminate failure caused by context uncertainty, we marginalize over generated contexts. Experimental results on three QA benchmarks show that our method significantly outperforms previous closed-book QA methods (e.g. exact matching 68.6% vs. 55.3%), and is on par with open-book methods that exploit external knowledge sources (e.g. 68.6% vs. 68.0%). Our method is able to better exploit the stored knowledge in pretrained LMs without adding extra learnable parameters or needing finetuning, and paves the way for hybrid models that integrate pretrained LMs with external knowledge.
VIMA: General Robot Manipulation with Multimodal Prompts
Oct 06, 2022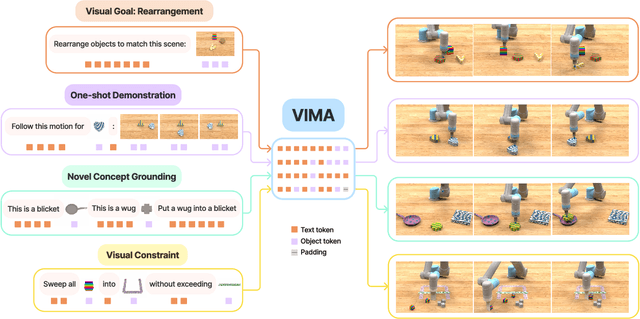
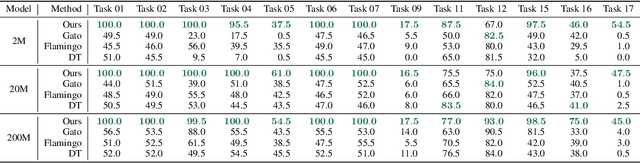
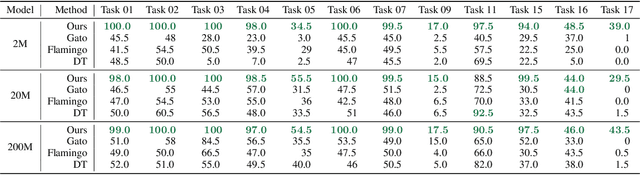
Prompt-based learning has emerged as a successful paradigm in natural language processing, where a single general-purpose language model can be instructed to perform any task specified by input prompts. Yet task specification in robotics comes in various forms, such as imitating one-shot demonstrations, following language instructions, and reaching visual goals. They are often considered different tasks and tackled by specialized models. This work shows that we can express a wide spectrum of robot manipulation tasks with multimodal prompts, interleaving textual and visual tokens. We design a transformer-based generalist robot agent, VIMA, that processes these prompts and outputs motor actions autoregressively. To train and evaluate VIMA, we develop a new simulation benchmark with thousands of procedurally-generated tabletop tasks with multimodal prompts, 600K+ expert trajectories for imitation learning, and four levels of evaluation protocol for systematic generalization. VIMA achieves strong scalability in both model capacity and data size. It outperforms prior SOTA methods in the hardest zero-shot generalization setting by up to $2.9\times$ task success rate given the same training data. With $10\times$ less training data, VIMA still performs $2.7\times$ better than the top competing approach. We open-source all code, pretrained models, dataset, and simulation benchmark at https://vimalabs.github.io
Dynamic-Backbone Protein-Ligand Structure Prediction with Multiscale Generative Diffusion Models
Sep 30, 2022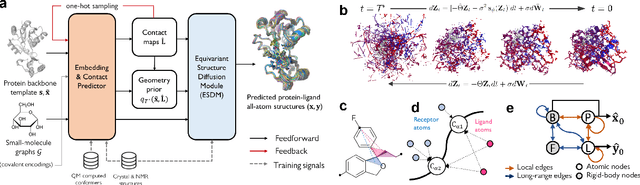
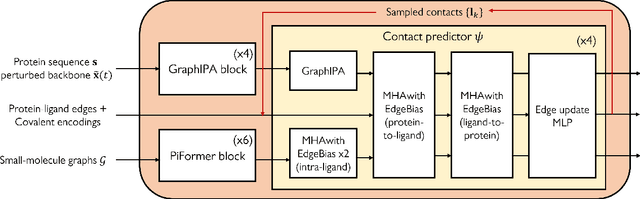
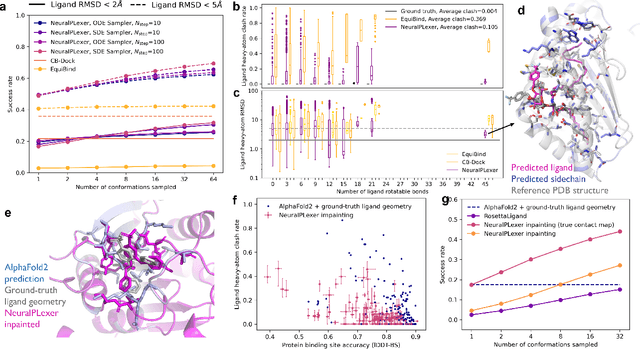
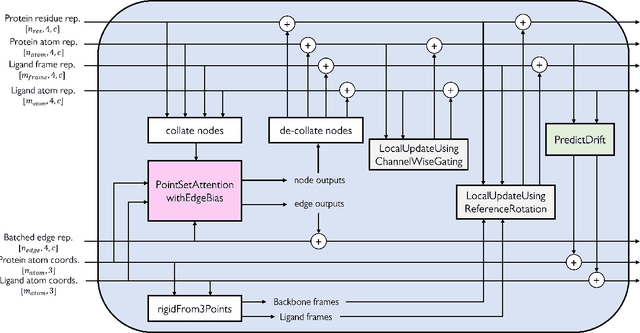
Molecular complexes formed by proteins and small-molecule ligands are ubiquitous, and predicting their 3D structures can facilitate both biological discoveries and the design of novel enzymes or drug molecules. Here we propose NeuralPLexer, a deep generative model framework to rapidly predict protein-ligand complex structures and their fluctuations using protein backbone template and molecular graph inputs. NeuralPLexer jointly samples protein and small-molecule 3D coordinates at an atomistic resolution through a generative model that incorporates biophysical constraints and inferred proximity information into a time-truncated diffusion process. The reverse-time generative diffusion process is learned by a novel stereochemistry-aware equivariant graph transformer that enables efficient, concurrent gradient field prediction for all heavy atoms in the protein-ligand complex. NeuralPLexer outperforms existing physics-based and learning-based methods on benchmarking problems including fixed-backbone blind protein-ligand docking and ligand-coupled binding site repacking. Moreover, we identify preliminary evidence that NeuralPLexer enriches bound-state-like protein structures when applied to systems where protein folding landscapes are significantly altered by the presence of ligands. Our results reveal that a data-driven approach can capture the structural cooperativity among protein and small-molecule entities, showing promise for the computational identification of novel drug targets and the end-to-end differentiable design of functional small-molecules and ligand-binding proteins.
AdvDO: Realistic Adversarial Attacks for Trajectory Prediction
Sep 19, 2022
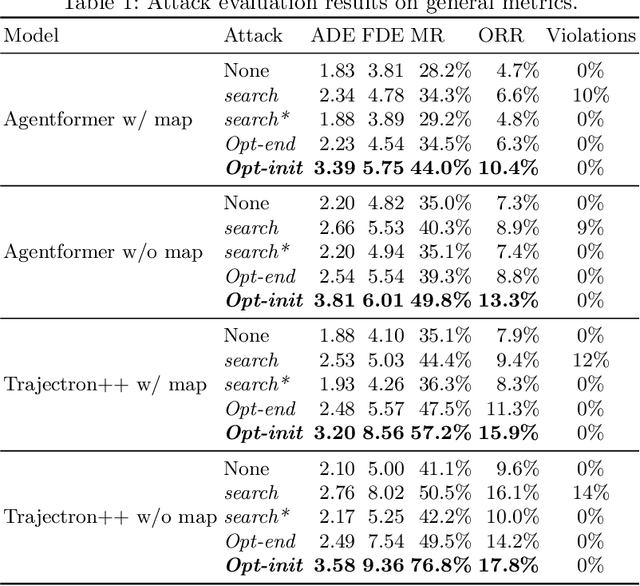
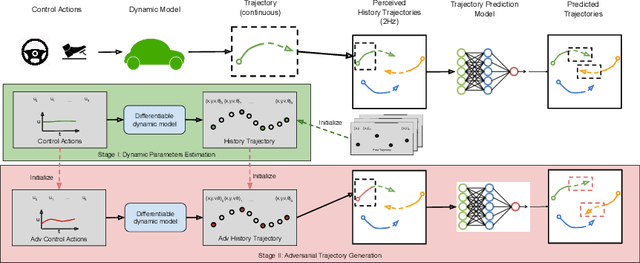
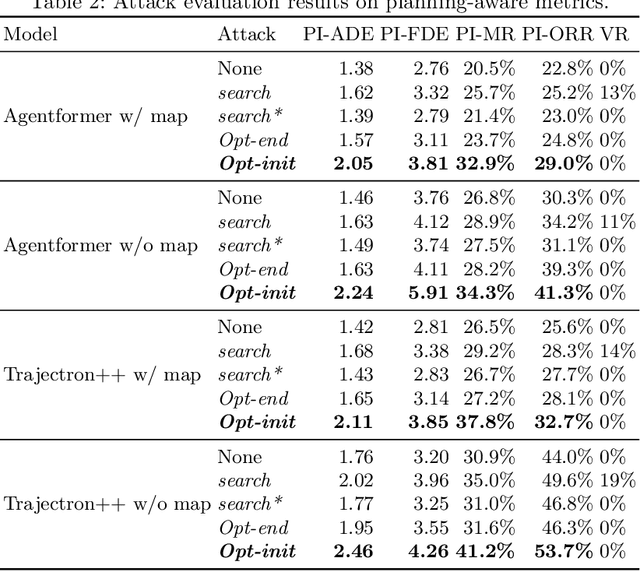
Trajectory prediction is essential for autonomous vehicles (AVs) to plan correct and safe driving behaviors. While many prior works aim to achieve higher prediction accuracy, few study the adversarial robustness of their methods. To bridge this gap, we propose to study the adversarial robustness of data-driven trajectory prediction systems. We devise an optimization-based adversarial attack framework that leverages a carefully-designed differentiable dynamic model to generate realistic adversarial trajectories. Empirically, we benchmark the adversarial robustness of state-of-the-art prediction models and show that our attack increases the prediction error for both general metrics and planning-aware metrics by more than 50% and 37%. We also show that our attack can lead an AV to drive off road or collide into other vehicles in simulation. Finally, we demonstrate how to mitigate the adversarial attacks using an adversarial training scheme.
Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models
Sep 15, 2022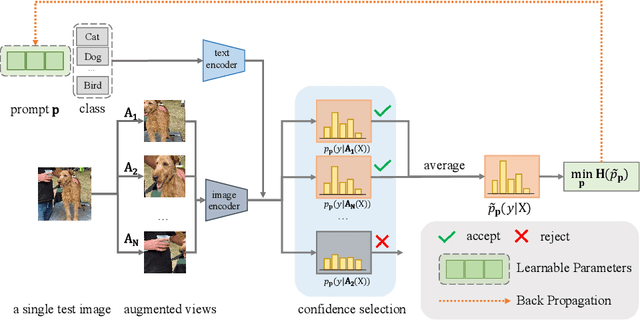
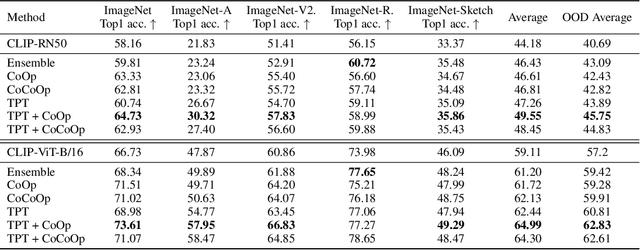
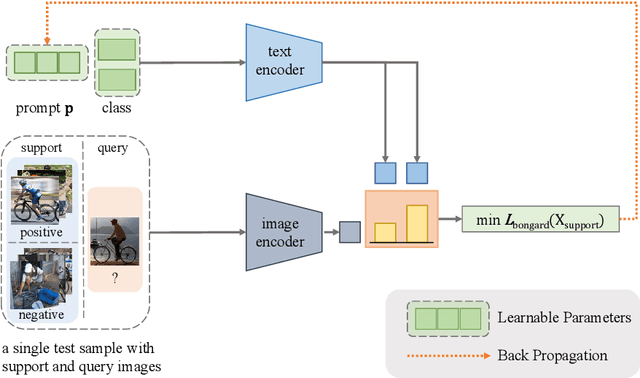
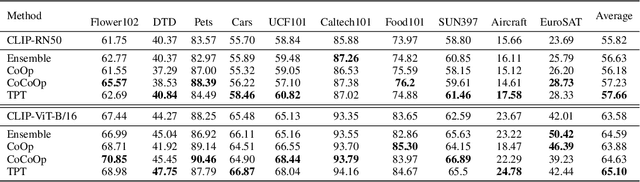
Pre-trained vision-language models (e.g., CLIP) have shown promising zero-shot generalization in many downstream tasks with properly designed text prompts. Instead of relying on hand-engineered prompts, recent works learn prompts using the training data from downstream tasks. While effective, training on domain-specific data reduces a model's generalization capability to unseen new domains. In this work, we propose test-time prompt tuning (TPT), a method that can learn adaptive prompts on the fly with a single test sample. For image classification, TPT optimizes the prompt by minimizing the entropy with confidence selection so that the model has consistent predictions across different augmented views of each test sample. In evaluating generalization to natural distribution shifts, TPT improves the zero-shot top-1 accuracy of CLIP by 3.6% on average, surpassing previous prompt tuning approaches that require additional task-specific training data. In evaluating cross-dataset generalization with unseen categories, TPT performs on par with the state-of-the-art approaches that use additional training data. Project page: https://azshue.github.io/TPT.
Retrieval-based Controllable Molecule Generation
Aug 23, 2022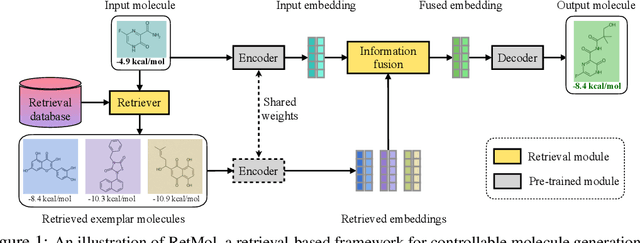

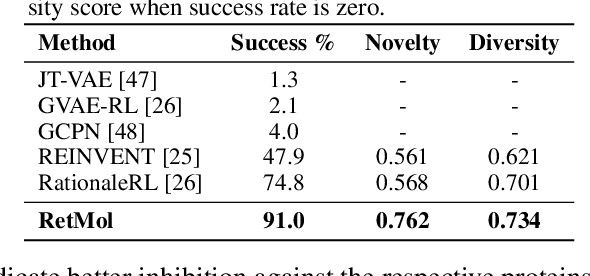
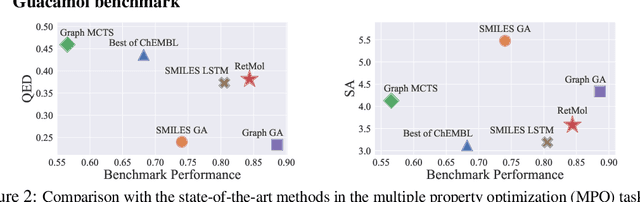
Generating new molecules with specified chemical and biological properties via generative models has emerged as a promising direction for drug discovery. However, existing methods require extensive training/fine-tuning with a large dataset, often unavailable in real-world generation tasks. In this work, we propose a new retrieval-based framework for controllable molecule generation. We use a small set of exemplar molecules, i.e., those that (partially) satisfy the design criteria, to steer the pre-trained generative model towards synthesizing molecules that satisfy the given design criteria. We design a retrieval mechanism that retrieves and fuses the exemplar molecules with the input molecule, which is trained by a new self-supervised objective that predicts the nearest neighbor of the input molecule. We also propose an iterative refinement process to dynamically update the generated molecules and retrieval database for better generalization. Our approach is agnostic to the choice of generative models and requires no task-specific fine-tuning. On various tasks ranging from simple design criteria to a challenging real-world scenario for designing lead compounds that bind to the SARS-CoV-2 main protease, we demonstrate our approach extrapolates well beyond the retrieval database, and achieves better performance and wider applicability than previous methods.
MinVIS: A Minimal Video Instance Segmentation Framework without Video-based Training
Aug 03, 2022
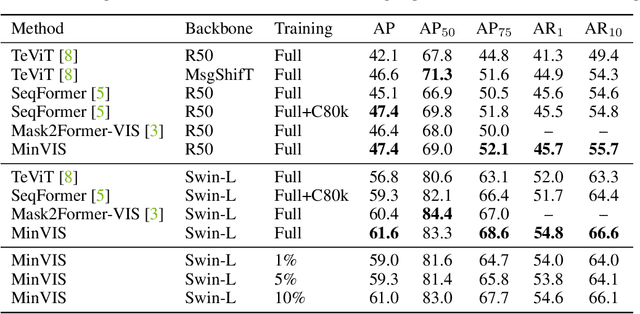
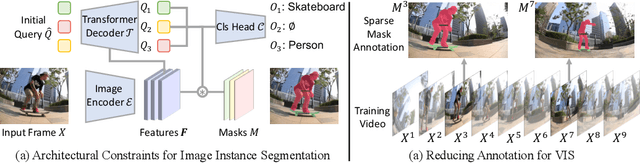
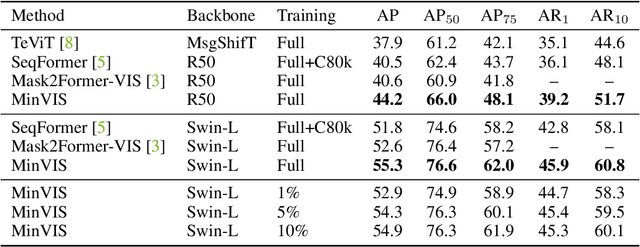
We propose MinVIS, a minimal video instance segmentation (VIS) framework that achieves state-of-the-art VIS performance with neither video-based architectures nor training procedures. By only training a query-based image instance segmentation model, MinVIS outperforms the previous best result on the challenging Occluded VIS dataset by over 10% AP. Since MinVIS treats frames in training videos as independent images, we can drastically sub-sample the annotated frames in training videos without any modifications. With only 1% of labeled frames, MinVIS outperforms or is comparable to fully-supervised state-of-the-art approaches on YouTube-VIS 2019/2021. Our key observation is that queries trained to be discriminative between intra-frame object instances are temporally consistent and can be used to track instances without any manually designed heuristics. MinVIS thus has the following inference pipeline: we first apply the trained query-based image instance segmentation to video frames independently. The segmented instances are then tracked by bipartite matching of the corresponding queries. This inference is done in an online fashion and does not need to process the whole video at once. MinVIS thus has the practical advantages of reducing both the labeling costs and the memory requirements, while not sacrificing the VIS performance. Code is available at: https://github.com/NVlabs/MinVIS
Robust Trajectory Prediction against Adversarial Attacks
Jul 29, 2022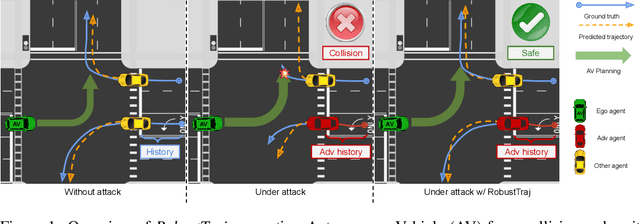
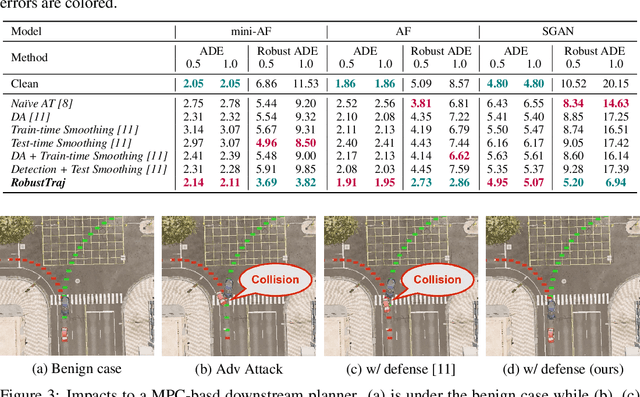

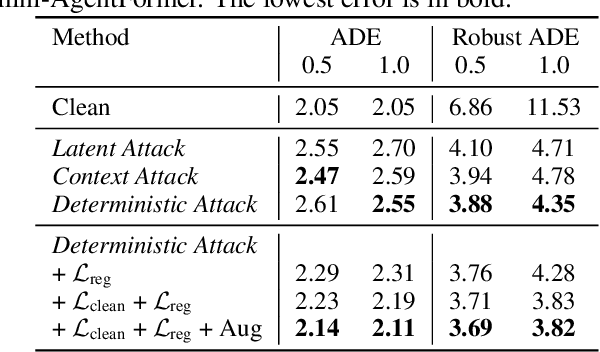
Trajectory prediction using deep neural networks (DNNs) is an essential component of autonomous driving (AD) systems. However, these methods are vulnerable to adversarial attacks, leading to serious consequences such as collisions. In this work, we identify two key ingredients to defend trajectory prediction models against adversarial attacks including (1) designing effective adversarial training methods and (2) adding domain-specific data augmentation to mitigate the performance degradation on clean data. We demonstrate that our method is able to improve the performance by 46% on adversarial data and at the cost of only 3% performance degradation on clean data, compared to the model trained with clean data. Additionally, compared to existing robust methods, our method can improve performance by 21% on adversarial examples and 9% on clean data. Our robust model is evaluated with a planner to study its downstream impacts. We demonstrate that our model can significantly reduce the severe accident rates (e.g., collisions and off-road driving).