 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyX: Does Your Model Have the "Wits" for Physical Reasoning?
May 21, 2025



Existing benchmarks fail to capture a crucial aspect of intelligence: physical reasoning, the integrated ability to combine domain knowledge, symbolic reasoning, and understanding of real-world constraints. To address this gap, we introduce PhyX: the first large-scale benchmark designed to assess models capacity for physics-grounded reasoning in visual scenarios. PhyX includes 3K meticulously curated multimodal questions spanning 6 reasoning types across 25 sub-domains and 6 core physics domains: thermodynamics, electromagnetism, mechanics, modern physics, optics, and wave\&acoustics. In our comprehensive evaluation, even state-of-the-art models struggle significantly with physical reasoning. GPT-4o, Claude3.7-Sonnet, and GPT-o4-mini achieve only 32.5\%, 42.2\%, and 45.8\% accuracy respectively-performance gaps exceeding 29\% compared to human experts. Our analysis exposes critical limitations in current models: over-reliance on memorized disciplinary knowledge, excessive dependence on mathematical formulations, and surface-level visual pattern matching rather than genuine physical understanding. We provide in-depth analysis through fine-grained statistics, detailed case studies, and multiple evaluation paradigms to thoroughly examine physical reasoning capabilities. To ensure reproducibility, we implement a compatible evaluation protocol based on widely-used toolkits such as VLMEvalKit, enabling one-click evaluation.
AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs
Oct 14, 2024



In this paper, we propose AutoDAN-Turbo, a black-box jailbreak method that can automatically discover as many jailbreak strategies as possible from scratch, without any human intervention or predefined scopes (e.g., specified candidate strategies), and use them for red-teaming. As a result, AutoDAN-Turbo can significantly outperform baseline methods, achieving a 74.3% higher average attack success rate on public benchmarks. Notably, AutoDAN-Turbo achieves an 88.5 attack success rate on GPT-4-1106-turbo. In addition, AutoDAN-Turbo is a unified framework that can incorporate existing human-designed jailbreak strategies in a plug-and-play manner. By integrating human-designed strategies, AutoDAN-Turbo can even achieve a higher attack success rate of 93.4 on GPT-4-1106-turbo.
Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation
Oct 11, 2023



Given a real-world dataset, data condensation (DC) aims to synthesize a significantly smaller dataset that captures the knowledge of this dataset for model training with high performance. Recent works propose to enhance DC with data parameterization, which condenses data into parameterized data containers rather than pixel space. The intuition behind data parameterization is to encode shared features of images to avoid additional storage costs. In this paper, we recognize that images share common features in a hierarchical way due to the inherent hierarchical structure of the classification system, which is overlooked by current data parameterization methods. To better align DC with this hierarchical nature and encourage more efficient information sharing inside data containers, we propose a novel data parameterization architecture, Hierarchical Memory Network (HMN). HMN stores condensed data in a three-tier structure, representing the dataset-level, class-level, and instance-level features. Another helpful property of the hierarchical architecture is that HMN naturally ensures good independence among images despite achieving information sharing. This enables instance-level pruning for HMN to reduce redundant information, thereby further minimizing redundancy and enhancing performance. We evaluate HMN on four public datasets (SVHN, CIFAR10, CIFAR100, and Tiny-ImageNet) and compare HMN with eight DC baselines. The evaluation results show that our proposed method outperforms all baselines, even when trained with a batch-based loss consuming less GPU memory.
Robust Trajectory Prediction against Adversarial Attacks
Jul 29, 2022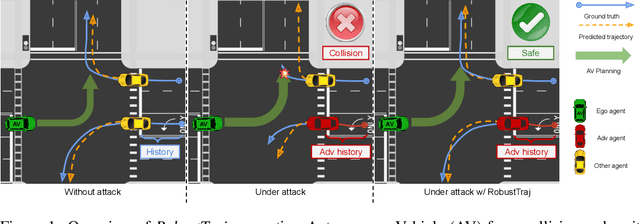
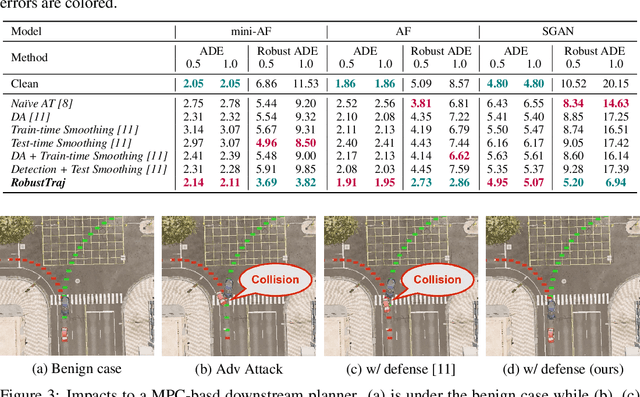

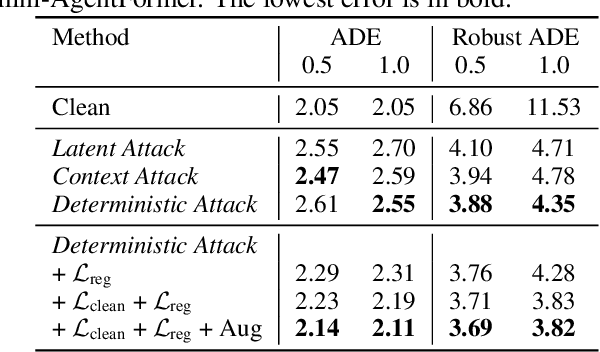
Trajectory prediction using deep neural networks (DNNs) is an essential component of autonomous driving (AD) systems. However, these methods are vulnerable to adversarial attacks, leading to serious consequences such as collisions. In this work, we identify two key ingredients to defend trajectory prediction models against adversarial attacks including (1) designing effective adversarial training methods and (2) adding domain-specific data augmentation to mitigate the performance degradation on clean data. We demonstrate that our method is able to improve the performance by 46% on adversarial data and at the cost of only 3% performance degradation on clean data, compared to the model trained with clean data. Additionally, compared to existing robust methods, our method can improve performance by 21% on adversarial examples and 9% on clean data. Our robust model is evaluated with a planner to study its downstream impacts. We demonstrate that our model can significantly reduce the severe accident rates (e.g., collisions and off-road driving).