 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld of Workflows: a Benchmark for Bringing World Models to Enterprise Systems
Jan 29, 2026Frontier large language models (LLMs) excel as autonomous agents in many domains, yet they remain untested in complex enterprise systems where hidden workflows create cascading effects across interconnected databases. Existing enterprise benchmarks evaluate surface-level agentic task completion similar to general consumer benchmarks, ignoring true challenges in enterprises, such as limited observability, large database state, and hidden workflows with cascading side effects. We introduce World of Workflows (WoW), a realistic ServiceNow-based environment incorporating 4,000+ business rules and 55 active workflows embedded in the system, alongside WoW-bench, a benchmark of 234 tasks evaluating constrained agentic task completion and enterprise dynamics modeling capabilities. We reveal two major takeaways: (1) Frontier LLMs suffer from dynamics blindness, consistently failing to predict the invisible, cascading side effects of their actions, which leads to silent constraint violations, and (2) reliability in opaque systems requires grounded world modeling, where agents must mentally simulate hidden state transitions to bridge the observability gap when high-fidelity feedback is unavailable. For reliable and useful enterprise agents, WoW motivates a new paradigm to explicitly learn system dynamics. We release our GitHub for setting up and evaluating WoW.
MetaGen: Self-Evolving Roles and Topologies for Multi-Agent LLM Reasoning
Jan 27, 2026Large language models are increasingly deployed as multi-agent systems, where specialized roles communicate and collaborate through structured interactions to solve complex tasks that often exceed the capacity of a single agent. However, most existing systems still rely on a fixed role library and an execution-frozen interaction topology, a rigid design choice that frequently leads to task mismatch, prevents timely adaptation when new evidence emerges during reasoning, and further inflates inference cost. We introduce MetaGen, a training-free framework that adapts both the role space and the collaboration topology at inference time, without updating base model weights. MetaGen generates and rewrites query-conditioned role specifications to maintain a controllable dynamic role pool, then instantiates a constrained execution graph around a minimal backbone. During execution, it iteratively updates role prompts and adjusts structural decisions using lightweight feedback signals. Experiments on code generation and multi-step reasoning benchmarks show that MetaGen improves the accuracy and cost tradeoff over strong multi-agent baselines.
A Unified Framework for Automated Assembly Sequence and Production Line Planning using Graph-based Optimization
Dec 15, 2025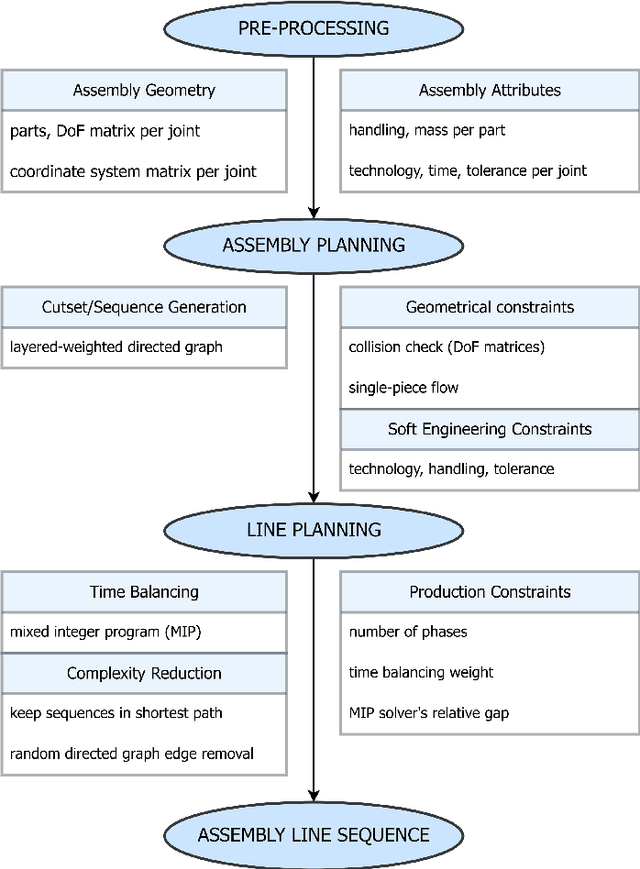
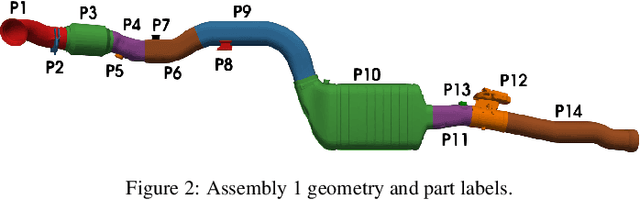
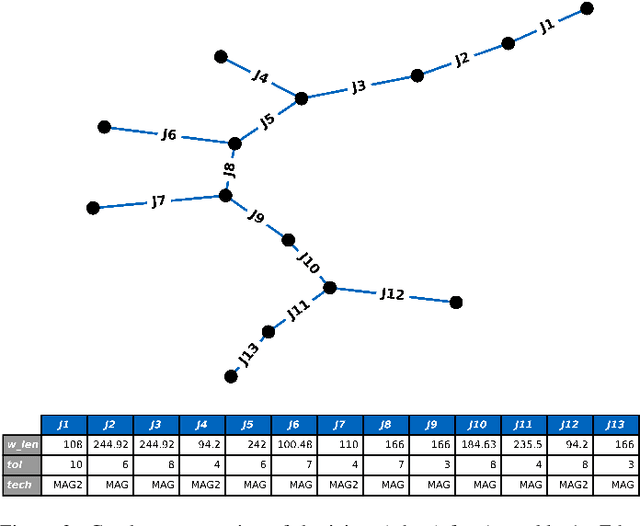
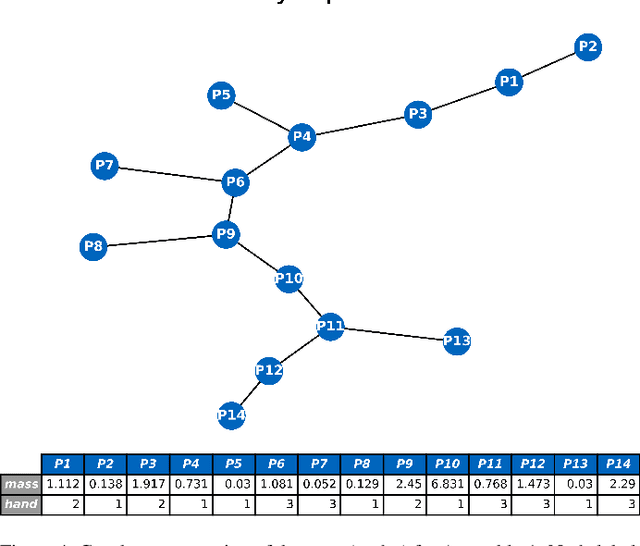
This paper presents PyCAALP (Python-based Computer-Aided Assembly Line Planning), a framework for automated Assembly Sequence Planning (ASP) and Production Line Planning (PLP), employing a graph-based approach to model components and joints within production modules. The framework integrates kinematic boundary conditions, such as potential part collisions, to guarantee the feasibility of automated assembly planning. The developed algorithm computes all feasible production sequences, integrating modules for detecting spatial relationships and formulating geometric constraints. The algorithm incorporates additional attributes, including handling feasibility, tolerance matching, and joint compatibility, to manage the high combinatorial complexity inherent in assembly sequence generation. Heuristics, such as Single-Piece Flow assembly and geometrical constraint enforcement, are utilized to further refine the solution space, facilitating more efficient planning for complex assemblies. The PLP stage is formulated as a Mixed-Integer Program (MIP), balancing the total times of a fixed number of manufacturing stations. While some complexity reduction techniques may sacrifice optimality, they significantly reduce the MIPs computational time. Furthermore, the framework enables customization of engineering constraints and supports a flexible trade-off between ASP and PLP. The open-source nature of the framework, available at https://github.com/TUM-utg/PyCAALP, promotes further collaboration and adoption in both industrial and production research applications.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Reconstructing In-the-Wild Open-Vocabulary Human-Object Interactions
Mar 20, 2025



Reconstructing human-object interactions (HOI) from single images is fundamental in computer vision. Existing methods are primarily trained and tested on indoor scenes due to the lack of 3D data, particularly constrained by the object variety, making it challenging to generalize to real-world scenes with a wide range of objects. The limitations of previous 3D HOI datasets were primarily due to the difficulty in acquiring 3D object assets. However, with the development of 3D reconstruction from single images, recently it has become possible to reconstruct various objects from 2D HOI images. We therefore propose a pipeline for annotating fine-grained 3D humans, objects, and their interactions from single images. We annotated 2.5k+ 3D HOI assets from existing 2D HOI datasets and built the first open-vocabulary in-the-wild 3D HOI dataset Open3DHOI, to serve as a future test set. Moreover, we design a novel Gaussian-HOI optimizer, which efficiently reconstructs the spatial interactions between humans and objects while learning the contact regions. Besides the 3D HOI reconstruction, we also propose several new tasks for 3D HOI understanding to pave the way for future work. Data and code will be publicly available at https://wenboran2002.github.io/3dhoi.
Learning State Conditioned Linear Mappings for Low-Dimensional Control of Robotic Manipulators
Oct 28, 2024



Identifying an appropriate task space that simplifies control solutions is important for solving robotic manipulation problems. One approach to this problem is learning an appropriate low-dimensional action space. Linear and nonlinear action mapping methods have trade-offs between simplicity on the one hand and the ability to express motor commands outside of a single low-dimensional subspace on the other. We propose that learning local linear action representations that adapt based on the current configuration of the robot achieves both of these benefits. Our state-conditioned linear maps ensure that for any given state, the high-dimensional robotic actuations are linear in the low-dimensional action. As the robot state evolves, so do the action mappings, ensuring the ability to represent motions that are immediately necessary. These local linear representations guarantee desirable theoretical properties by design, and we validate these findings empirically through two user studies. Results suggest state-conditioned linear maps outperform conditional autoencoder and PCA baselines on a pick-and-place task and perform comparably to mode switching in a more complex pouring task.
* 7 Pages, 8 Figures, Presented at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Temporal2Seq: A Unified Framework for Temporal Video Understanding Tasks
Sep 27, 2024With the development of video understanding, there is a proliferation of tasks for clip-level temporal video analysis, including temporal action detection (TAD), temporal action segmentation (TAS), and generic event boundary detection (GEBD). While task-specific video understanding models have exhibited outstanding performance in each task, there remains a dearth of a unified framework capable of simultaneously addressing multiple tasks, which is a promising direction for the next generation of AI. To this end, in this paper, we propose a single unified framework, coined as Temporal2Seq, to formulate the output of these temporal video understanding tasks as a sequence of discrete tokens. With this unified token representation, Temporal2Seq can train a generalist model within a single architecture on different video understanding tasks. In the absence of multi-task learning (MTL) benchmarks, we compile a comprehensive co-training dataset by borrowing the datasets from TAD, TAS, and GEBD tasks. We evaluate our Temporal2Seq generalist model on the corresponding test sets of three tasks, demonstrating that Temporal2Seq can produce reasonable results on various tasks and achieve advantages compared with single-task training on this framework. We also investigate the generalization performance of our generalist model on new datasets from different tasks, which yields superior performance to the specific model.
PEAR: Phrase-Based Hand-Object Interaction Anticipation
Jul 31, 2024First-person hand-object interaction anticipation aims to predict the interaction process over a forthcoming period based on current scenes and prompts. This capability is crucial for embodied intelligence and human-robot collaboration. The complete interaction process involves both pre-contact interaction intention (i.e., hand motion trends and interaction hotspots) and post-contact interaction manipulation (i.e., manipulation trajectories and hand poses with contact). Existing research typically anticipates only interaction intention while neglecting manipulation, resulting in incomplete predictions and an increased likelihood of intention errors due to the lack of manipulation constraints. To address this, we propose a novel model, PEAR (Phrase-Based Hand-Object Interaction Anticipation), which jointly anticipates interaction intention and manipulation. To handle uncertainties in the interaction process, we employ a twofold approach. Firstly, we perform cross-alignment of verbs, nouns, and images to reduce the diversity of hand movement patterns and object functional attributes, thereby mitigating intention uncertainty. Secondly, we establish bidirectional constraints between intention and manipulation using dynamic integration and residual connections, ensuring consistency among elements and thus overcoming manipulation uncertainty. To rigorously evaluate the performance of the proposed model, we collect a new task-relevant dataset, EGO-HOIP, with comprehensive annotations. Extensive experimental results demonstrate the superiority of our method.
SoupLM: Model Integration in Large Language and Multi-Modal Models
Jul 11, 2024

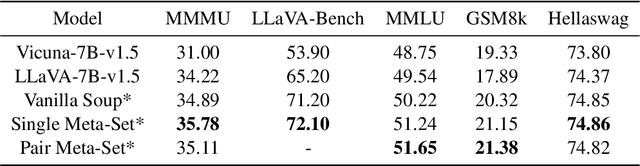
Training large language models (LLMs) and multimodal LLMs necessitates significant computing resources, and existing publicly available LLMs are typically pre-trained on diverse, privately curated datasets spanning various tasks. For instance, LLaMA, Vicuna, and LLaVA are three LLM variants trained with LLaMA base models using very different training recipes, tasks, and data modalities. The training cost and complexity for such LLM variants grow rapidly. In this study, we propose to use a soup strategy to assemble these LLM variants into a single well-generalized multimodal LLM (SoupLM) in a cost-efficient manner. Assembling these LLM variants efficiently brings knowledge and specialities trained from different domains and data modalities into an integrated one (e.g., chatbot speciality from user-shared conversations for Vicuna, and visual capacity from vision-language data for LLaVA), therefore, to avoid computing costs of repetitive training on several different domains. We propose series of soup strategies to systematically benchmark performance gains across various configurations, and probe the soup behavior across base models in the interpolation space.
PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
Jun 28, 2024



We present PoliFormer (Policy Transformer), an RGB-only indoor navigation agent trained end-to-end with reinforcement learning at scale that generalizes to the real-world without adaptation despite being trained purely in simulation. PoliFormer uses a foundational vision transformer encoder with a causal transformer decoder enabling long-term memory and reasoning. It is trained for hundreds of millions of interactions across diverse environments, leveraging parallelized, multi-machine rollouts for efficient training with high throughput. PoliFormer is a masterful navigator, producing state-of-the-art results across two distinct embodiments, the LoCoBot and Stretch RE-1 robots, and four navigation benchmarks. It breaks through the plateaus of previous work, achieving an unprecedented 85.5% success rate in object goal navigation on the CHORES-S benchmark, a 28.5% absolute improvement. PoliFormer can also be trivially extended to a variety of downstream applications such as object tracking, multi-object navigation, and open-vocabulary navigation with no finetuning.