 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-path Neural Networks for On-device Multi-domain Visual Classification
Oct 10, 2020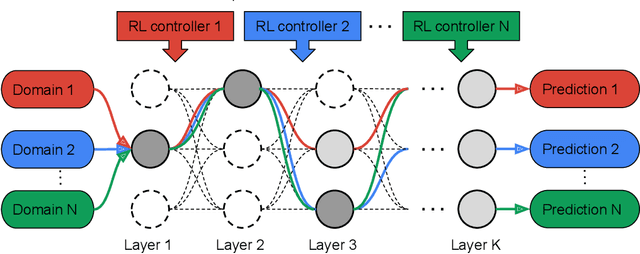
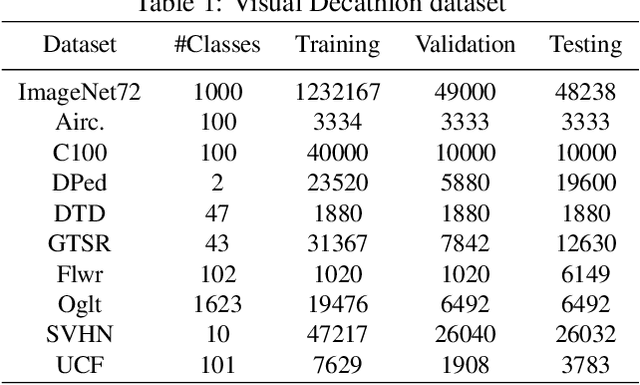
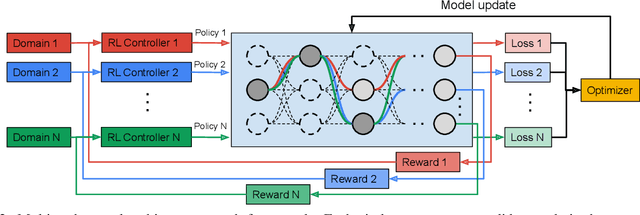
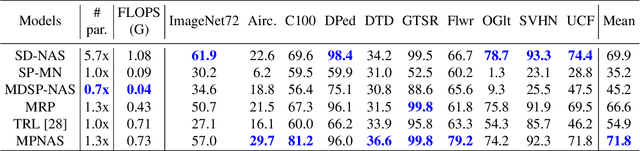
Learning multiple domains/tasks with a single model is important for improving data efficiency and lowering inference cost for numerous vision tasks, especially on resource-constrained mobile devices. However, hand-crafting a multi-domain/task model can be both tedious and challenging. This paper proposes a novel approach to automatically learn a multi-path network for multi-domain visual classification on mobile devices. The proposed multi-path network is learned from neural architecture search by applying one reinforcement learning controller for each domain to select the best path in the super-network created from a MobileNetV3-like search space. An adaptive balanced domain prioritization algorithm is proposed to balance optimizing the joint model on multiple domains simultaneously. The determined multi-path model selectively shares parameters across domains in shared nodes while keeping domain-specific parameters within non-shared nodes in individual domain paths. This approach effectively reduces the total number of parameters and FLOPS, encouraging positive knowledge transfer while mitigating negative interference across domains. Extensive evaluations on the Visual Decathlon dataset demonstrate that the proposed multi-path model achieves state-of-the-art performance in terms of accuracy, model size, and FLOPS against other approaches using MobileNetV3-like architectures. Furthermore, the proposed method improves average accuracy over learning single-domain models individually, and reduces the total number of parameters and FLOPS by 78% and 32% respectively, compared to the approach that simply bundles single-domain models for multi-domain learning.
Discovering Multi-Hardware Mobile Models via Architecture Search
Aug 18, 2020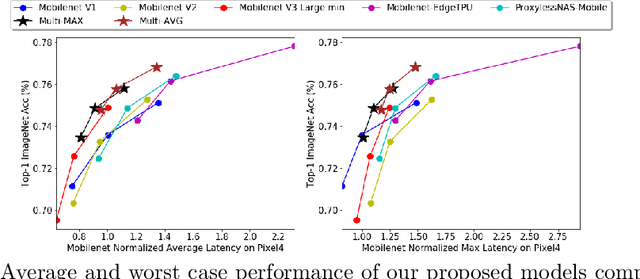

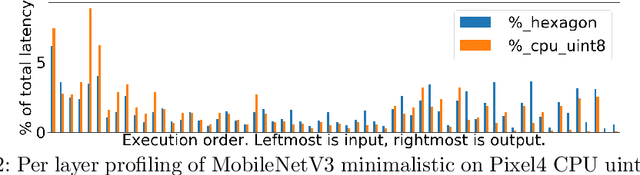
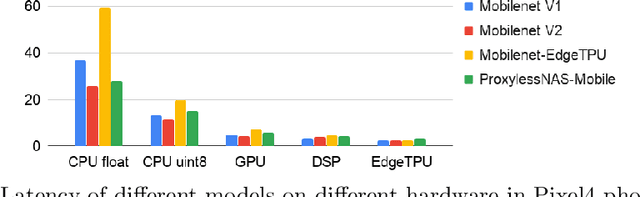
Developing efficient models for mobile phones or other on-device deployments has been a popular topic in both industry and academia. In such scenarios, it is often convenient to deploy the same model on a diverse set of hardware devices owned by different end users to minimize the costs of development, deployment and maintenance. Despite the importance, designing a single neural network that can perform well on multiple devices is difficult as each device has its own specialty and restrictions: A model optimized for one device may not perform well on another. While most existing work proposes different models optimized for each single hardware, this paper is the first which explores the problem of finding a single model that performs well on multiple hardware. Specifically, we leverage architecture search to help us find the best model, where given a set of diverse hardware to optimize for, we first introduce a multi-hardware search space that is compatible with all examined hardware. Then, to measure the performance of a neural network over multiple hardware, we propose metrics that can characterize the overall latency performance in an average case and worst case scenario. With the multi-hardware search space and new metrics applied to Pixel4 CPU, GPU, DSP and EdgeTPU, we found models that perform on par or better than state-of-the-art (SOTA) models on each of our target accelerators and generalize well on many un-targeted hardware. Comparing with single-hardware searches, multi-hardware search gives a better trade-off between computation cost and model performance.
Non-discriminative data or weak model? On the relative importance of data and model resolution
Oct 17, 2019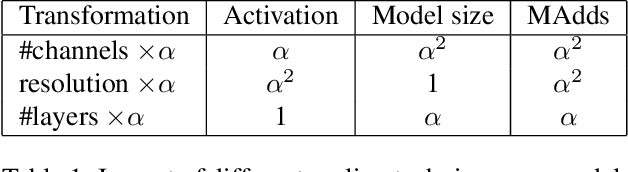
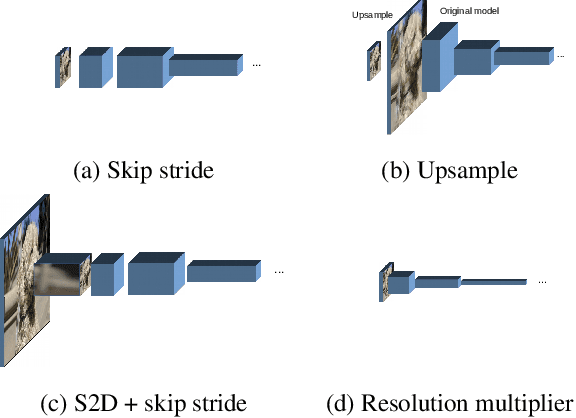
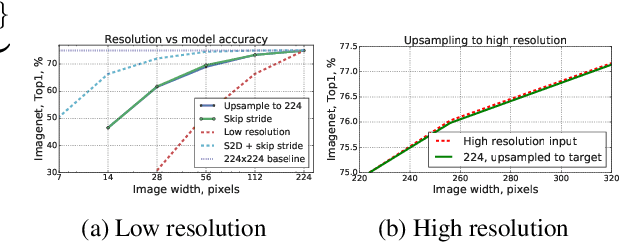

We explore the question of how the resolution of the input image ("input resolution") affects the performance of a neural network when compared to the resolution of the hidden layers ("internal resolution"). Adjusting these characteristics is frequently used as a hyperparameter providing a trade-off between model performance and accuracy. An intuitive interpretation is that the reduced information content in the low-resolution input causes decay in the accuracy. In this paper, we show that up to a point, the input resolution alone plays little role in the network performance, and it is the internal resolution that is the critical driver of model quality. We then build on these insights to develop novel neural network architectures that we call \emph{Isometric Neural Networks}. These models maintain a fixed internal resolution throughout their entire depth. We demonstrate that they lead to high accuracy models with low activation footprint and parameter count.
Visual Wake Words Dataset
Jun 12, 2019

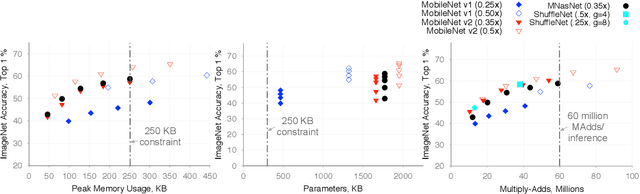
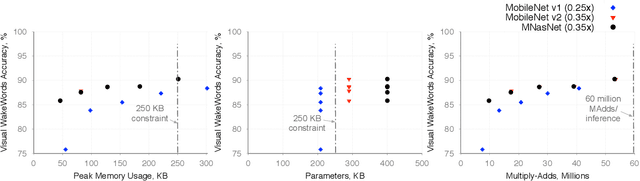
The emergence of Internet of Things (IoT) applications requires intelligence on the edge. Microcontrollers provide a low-cost compute platform to deploy intelligent IoT applications using machine learning at scale, but have extremely limited on-chip memory and compute capability. To deploy computer vision on such devices, we need tiny vision models that fit within a few hundred kilobytes of memory footprint in terms of peak usage and model size on device storage. To facilitate the development of microcontroller friendly models, we present a new dataset, Visual Wake Words, that represents a common microcontroller vision use-case of identifying whether a person is present in the image or not, and provides a realistic benchmark for tiny vision models. Within a limited memory footprint of 250 KB, several state-of-the-art mobile models achieve accuracy of 85-90% on the Visual Wake Words dataset. We anticipate the proposed dataset will advance the research on tiny vision models that can push the pareto-optimal boundary in terms of accuracy versus memory usage for microcontroller applications.
Geo-Aware Networks for Fine Grained Recognition
Jun 04, 2019
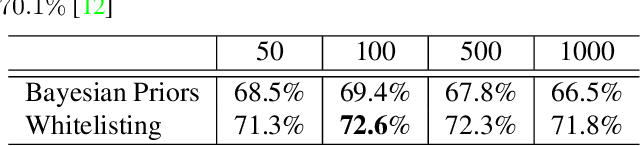
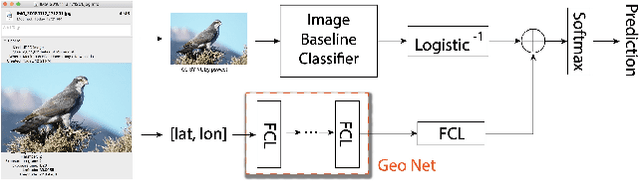
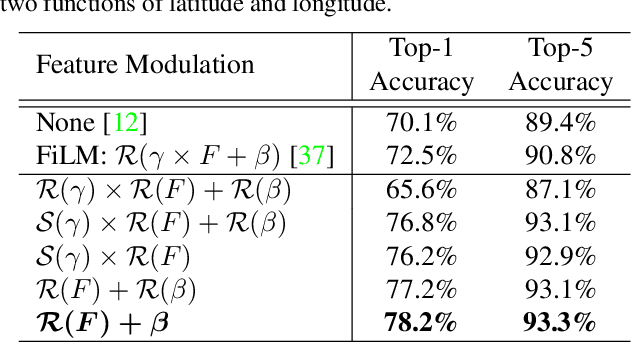
Fine grained recognition distinguishes among categories with subtle visual differences. To help identify fine grained categories, other information besides images has been used. However, there has been little effort on using geolocation information to improve fine grained classification accuracy. Our contributions to this field are twofold. First, to the best of our knowledge, this is the first paper which systematically examined various ways of incorporating geolocation information to fine grained images classification - from geolocation priors, to post-processing, to feature modulation. Secondly, to overcome the situation where no fine grained dataset has complete geolocation information, we introduce, and will make public, two fine grained datasets with geolocation by providing complementary information to existing popular datasets - iNaturalist and YFCC100M. Results on these datasets show that, the best geo-aware network can achieve 8.9% top-1 accuracy increase on iNaturalist and 5.9% increase on YFCC100M, compared with image only models' results. In addition, for small image baseline models like Mobilenet V2, the best geo-aware network gives 12.6% higher top-1 accuracy than image only model, achieving even higher performance than Inception V3 models without geolocation. Our work gives incentives to use geolocation information to improve fine grained recognition for both server and on-device models.
Searching for MobileNetV3
May 14, 2019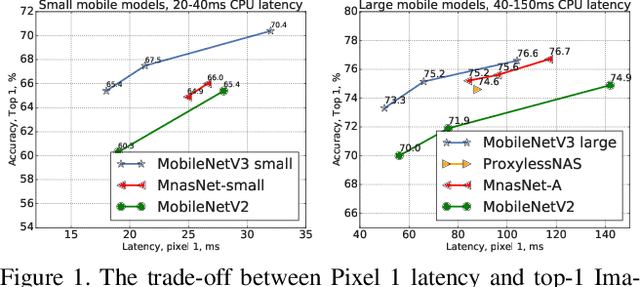
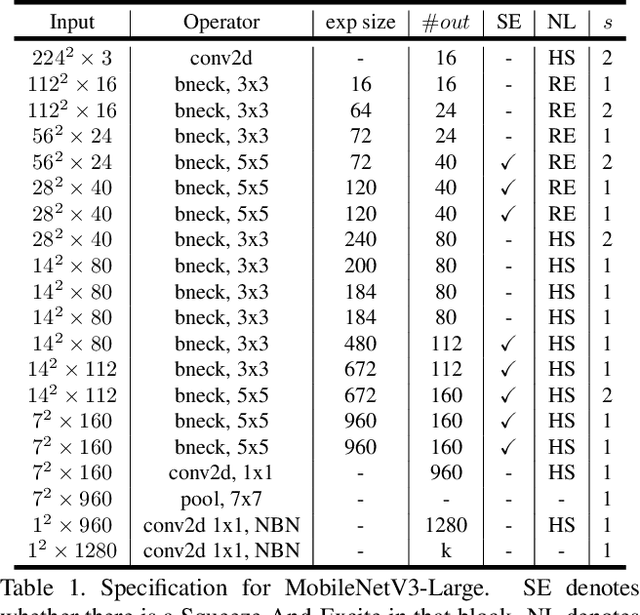
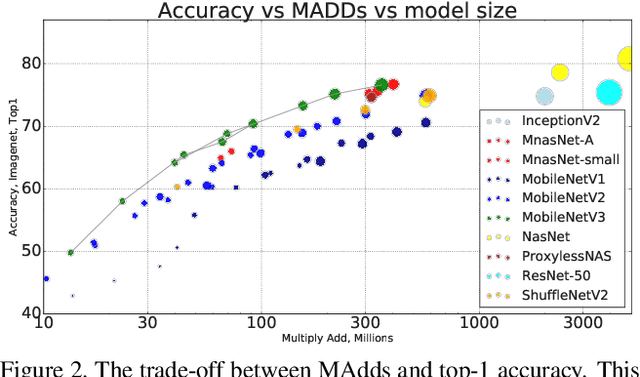
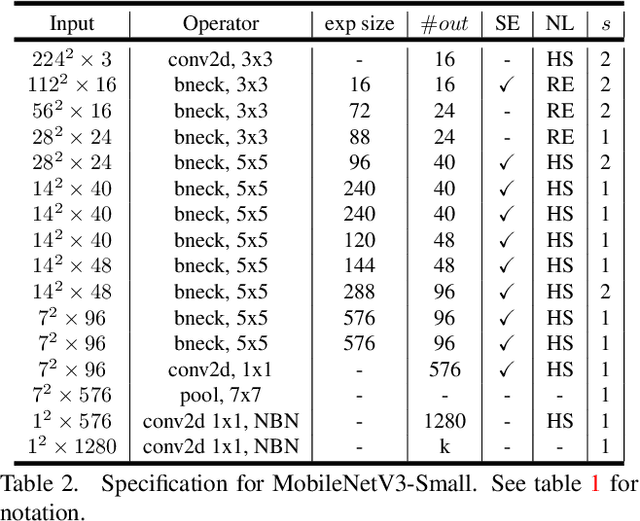
We present the next generation of MobileNets based on a combination of complementary search techniques as well as a novel architecture design. MobileNetV3 is tuned to mobile phone CPUs through a combination of hardware aware network architecture search (NAS) complemented by the NetAdapt algorithm and then subsequently improved through novel architecture advances. This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation. MobileNetV3-Large is 3.2% more accurate on ImageNet classification while reducing latency by 15% compared to MobileNetV2. MobileNetV2-Small is 4.6% more accurate while reducing latency by 5% compared to MobileNetV2. MobileNetV3-Large detection is 25% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LR-ASPP is 30% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019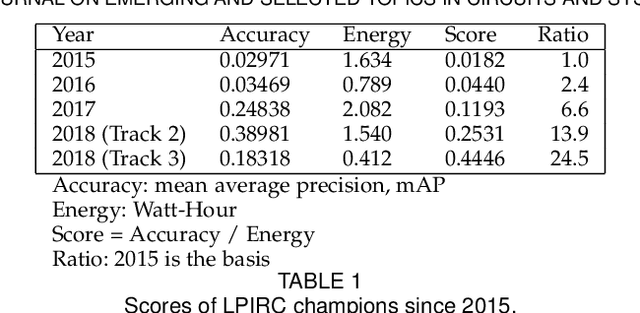
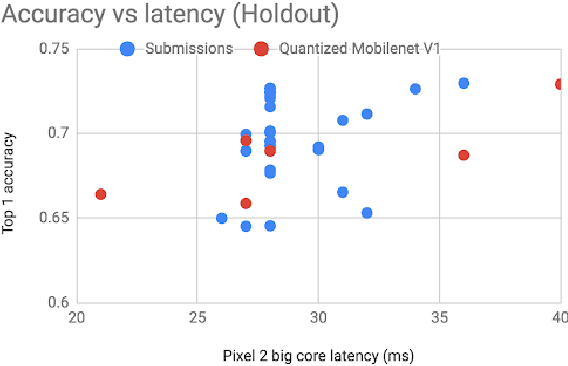
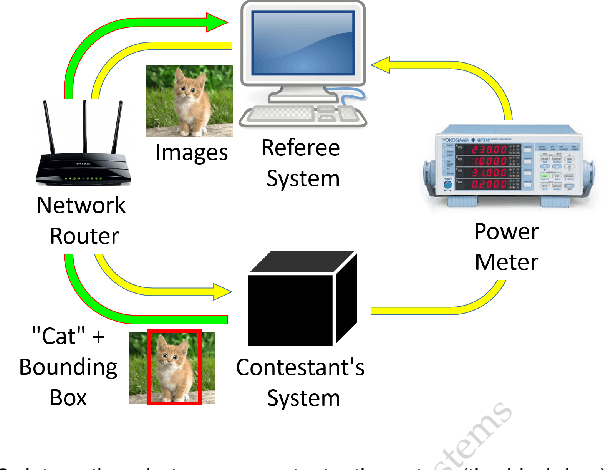
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.
K For The Price Of 1: Parameter Efficient Multi-task And Transfer Learning
Oct 25, 2018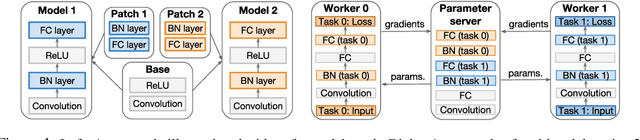

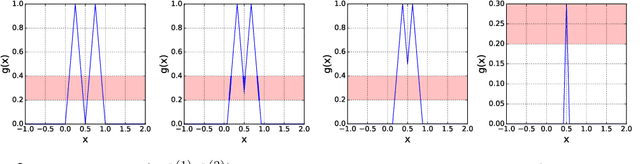
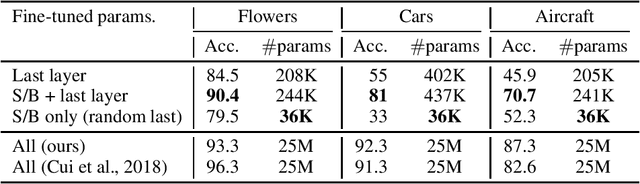
We introduce a novel method that enables parameter-efficient transfer and multitask learning. The basic approach is to allow a model patch - a small set of parameters - to specialize to each task, instead of fine-tuning the last layer or the entire network. For instance, we show that learning a set of scales and biases allows a network to learn a completely different embedding that could be used for different tasks (such as converting an SSD detection model into a 1000-class classification model while reusing 98% of parameters of the feature extractor). Similarly, we show that re-learning the existing low-parameter layers (such as depth-wise convolutions) also improves accuracy significantly. Our approach allows both simultaneous (multi-task) learning as well as sequential transfer learning wherein we adapt pretrained networks to solve new problems. For multi-task learning, despite using much fewer parameters than traditional logits-only fine-tuning, we match single-task-based performance.
2018 Low-Power Image Recognition Challenge
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.
NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications
Sep 28, 2018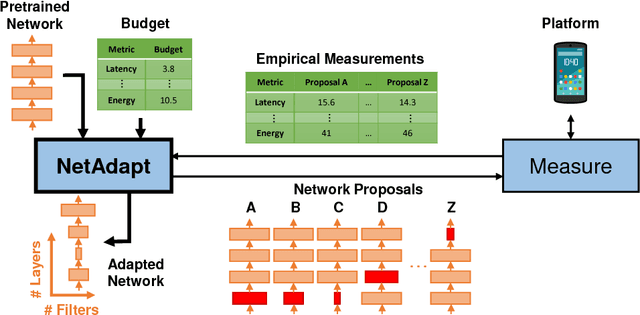
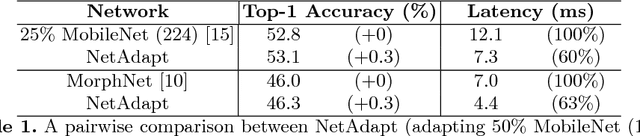
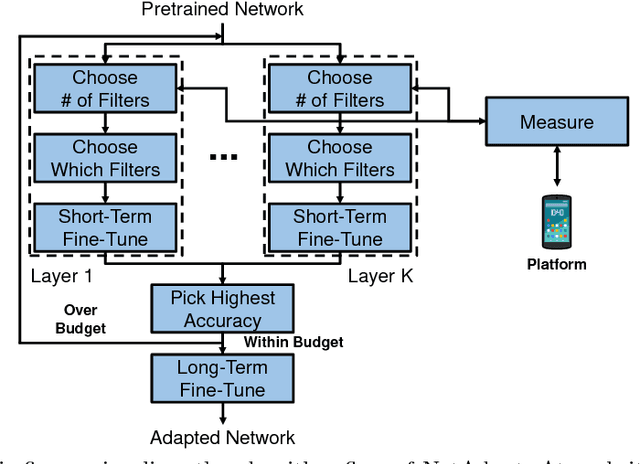
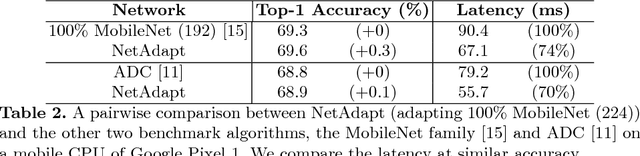
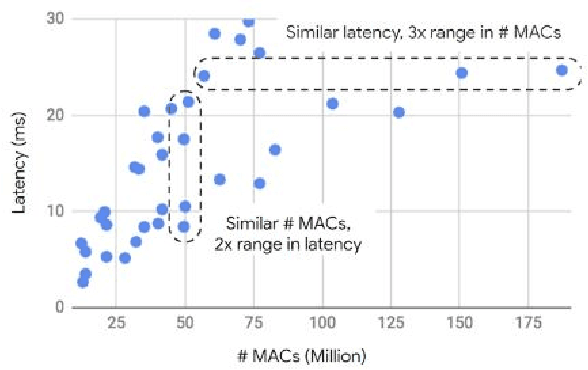
This work proposes an algorithm, called NetAdapt, that automatically adapts a pre-trained deep neural network to a mobile platform given a resource budget. While many existing algorithms simplify networks based on the number of MACs or weights, optimizing those indirect metrics may not necessarily reduce the direct metrics, such as latency and energy consumption. To solve this problem, NetAdapt incorporates direct metrics into its adaptation algorithm. These direct metrics are evaluated using empirical measurements, so that detailed knowledge of the platform and toolchain is not required. NetAdapt automatically and progressively simplifies a pre-trained network until the resource budget is met while maximizing the accuracy. Experiment results show that NetAdapt achieves better accuracy versus latency trade-offs on both mobile CPU and mobile GPU, compared with the state-of-the-art automated network simplification algorithms. For image classification on the ImageNet dataset, NetAdapt achieves up to a 1.7$\times$ speedup in measured inference latency with equal or higher accuracy on MobileNets (V1&V2).