 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
The Cartesian Shortcut: Re-evaluate Vision Reasoning in Polar Coordinate Space
May 11, 2026As current Multimodal Large Language Models rapidly saturate canonical visual reasoning benchmarks, a key question emerges: do these strong scores genuinely reflect robust visual understanding? We identify a pervasive vulnerability, the \textbf{Cartesian Shortcut}: visual reasoning benchmarks prevalently build on orthogonal grid-based layouts that can be readily discretized into explicit textual coordinates. Models systematically exploit this property, heavily leveraging text-based deductive reasoning to assist visual problem-solving. To systematically dismantle this shortcut, we introduce \textbf{Polaris-Bench}, which re-formulates 53 visual reasoning tasks in Polar coordinate space with paired Cartesian counterparts as reference, while preserving consistent logical constraints and task semantics -- thus fundamentally breaking the orthogonal prior that models exploit. Comprehensive evaluation across $14$ state-of-the-art MLLMs reveals that frontier models achieving $70$--$83\%$ on Cartesian layouts collapse to $31$--$39\%$ on Polar equivalents, with degradation persisting even under complete logical equivalence. Moreover, reasoning gains observed on Cartesian layouts are severely diminished on Polar equivalents. These findings expose a critical deficiency in current MLLMs: the lack of topology-invariant visual reasoning.
A Benchmark and Knowledge-Grounded Framework for Advanced Multimodal Personalization Study
Feb 22, 2026The powerful reasoning of modern Vision Language Models open a new frontier for advanced personalization study. However, progress in this area is critically hampered by the lack of suitable benchmarks. To address this gap, we introduce Life-Bench, a comprehensive, synthetically generated multimodal benchmark built on simulated user digital footprints. Life-Bench features over questions evaluating a wide spectrum of capabilities, from persona understanding to complex reasoning over historical data. These capabilities expand far beyond prior benchmarks, reflecting the critical demands essential for real-world applications. Furthermore, we propose LifeGraph, an end-to-end framework that organizes personal context into a knowledge graph to facilitate structured retrieval and reasoning. Our experiments on Life-Bench reveal that existing methods falter significantly on complex personalized tasks, exposing a large performance headroom, especially in relational, temporal and aggregative reasoning. While LifeGraph closes this gap by leveraging structured knowledge and demonstrates a promising direction, these advanced personalization tasks remain a critical open challenge, motivating new research in this area.
Geo-Aware Networks for Fine Grained Recognition
Jun 04, 2019
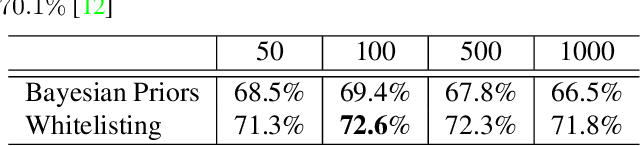
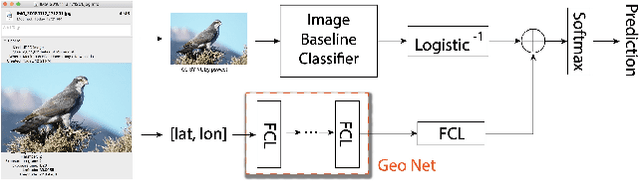
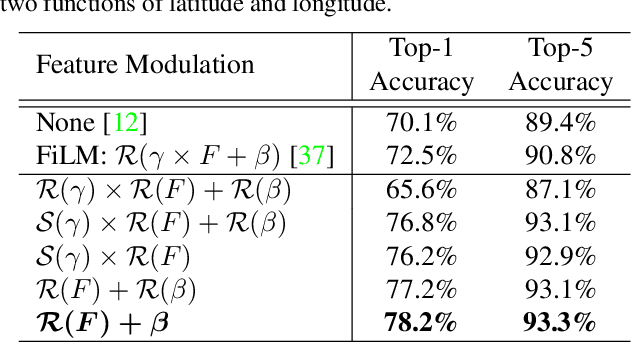
Fine grained recognition distinguishes among categories with subtle visual differences. To help identify fine grained categories, other information besides images has been used. However, there has been little effort on using geolocation information to improve fine grained classification accuracy. Our contributions to this field are twofold. First, to the best of our knowledge, this is the first paper which systematically examined various ways of incorporating geolocation information to fine grained images classification - from geolocation priors, to post-processing, to feature modulation. Secondly, to overcome the situation where no fine grained dataset has complete geolocation information, we introduce, and will make public, two fine grained datasets with geolocation by providing complementary information to existing popular datasets - iNaturalist and YFCC100M. Results on these datasets show that, the best geo-aware network can achieve 8.9% top-1 accuracy increase on iNaturalist and 5.9% increase on YFCC100M, compared with image only models' results. In addition, for small image baseline models like Mobilenet V2, the best geo-aware network gives 12.6% higher top-1 accuracy than image only model, achieving even higher performance than Inception V3 models without geolocation. Our work gives incentives to use geolocation information to improve fine grained recognition for both server and on-device models.