 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo OWL-ViT: Temporally-consistent open-world localization in video
Aug 22, 2023We present an architecture and a training recipe that adapts pre-trained open-world image models to localization in videos. Understanding the open visual world (without being constrained by fixed label spaces) is crucial for many real-world vision tasks. Contrastive pre-training on large image-text datasets has recently led to significant improvements for image-level tasks. For more structured tasks involving object localization applying pre-trained models is more challenging. This is particularly true for video tasks, where task-specific data is limited. We show successful transfer of open-world models by building on the OWL-ViT open-vocabulary detection model and adapting it to video by adding a transformer decoder. The decoder propagates object representations recurrently through time by using the output tokens for one frame as the object queries for the next. Our model is end-to-end trainable on video data and enjoys improved temporal consistency compared to tracking-by-detection baselines, while retaining the open-world capabilities of the backbone detector. We evaluate our model on the challenging TAO-OW benchmark and demonstrate that open-world capabilities, learned from large-scale image-text pre-training, can be transferred successfully to open-world localization across diverse videos.
Agile Catching with Whole-Body MPC and Blackbox Policy Learning
Jun 14, 2023


We address a benchmark task in agile robotics: catching objects thrown at high-speed. This is a challenging task that involves tracking, intercepting, and cradling a thrown object with access only to visual observations of the object and the proprioceptive state of the robot, all within a fraction of a second. We present the relative merits of two fundamentally different solution strategies: (i) Model Predictive Control using accelerated constrained trajectory optimization, and (ii) Reinforcement Learning using zeroth-order optimization. We provide insights into various performance trade-offs including sample efficiency, sim-to-real transfer, robustness to distribution shifts, and whole-body multimodality via extensive on-hardware experiments. We conclude with proposals on fusing "classical" and "learning-based" techniques for agile robot control. Videos of our experiments may be found at https://sites.google.com/view/agile-catching
i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops
Jul 14, 2022
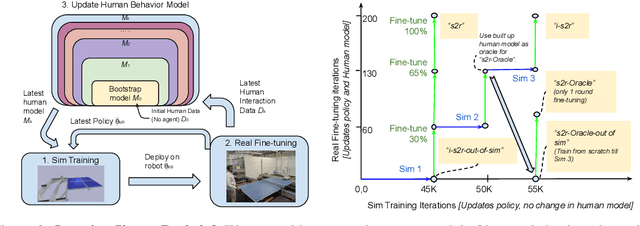
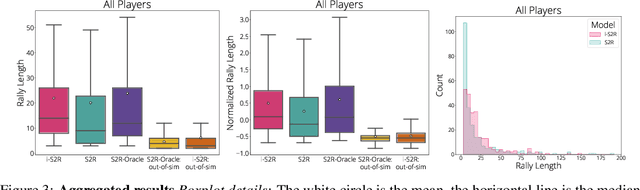
Sim-to-real transfer is a powerful paradigm for robotic reinforcement learning. The ability to train policies in simulation enables safe exploration and large-scale data collection quickly at low cost. However, prior works in sim-to-real transfer of robotic policies typically do not involve any human-robot interaction because accurately simulating human behavior is an open problem. In this work, our goal is to leverage the power of simulation to train robotic policies that are proficient at interacting with humans upon deployment. But there is a chicken and egg problem -- how do we gather examples of a human interacting with a physical robot so as to model human behavior in simulation without already having a robot that is able to interact with a human? Our proposed method, Iterative-Sim-to-Real (i-S2R), attempts to address this. i-S2R bootstraps from a simple model of human behavior and alternates between training in simulation and deploying in the real world. In each iteration, both the human behavior model and the policy are refined. We evaluate our method on a real world robotic table tennis setting, where the objective for the robot is to play cooperatively with a human player for as long as possible. Table tennis is a high-speed, dynamic task that requires the two players to react quickly to each other's moves, making a challenging test bed for research on human-robot interaction. We present results on an industrial robotic arm that is able to cooperatively play table tennis with human players, achieving rallies of 22 successive hits on average and 150 at best. Further, for 80% of players, rally lengths are 70% to 175% longer compared to the sim-to-real (S2R) baseline. For videos of our system in action, please see https://sites.google.com/view/is2r.
RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection
Jun 25, 2021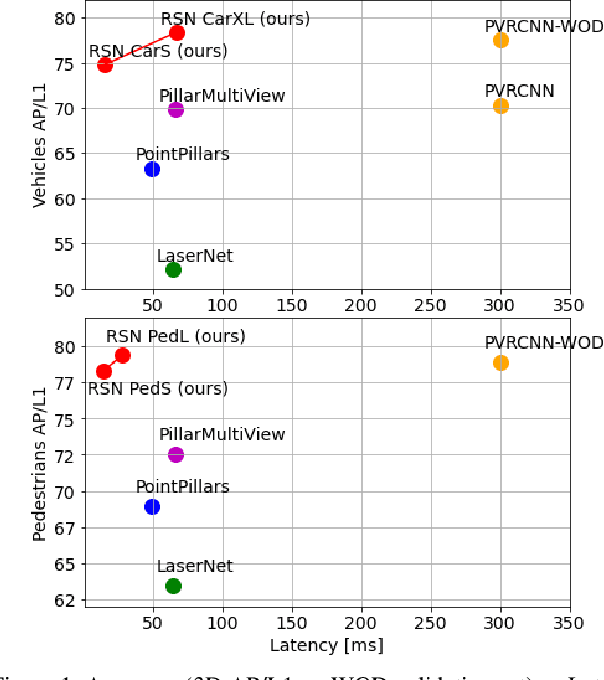
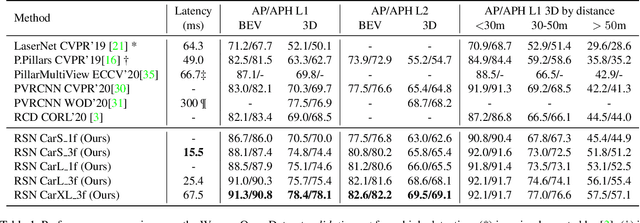
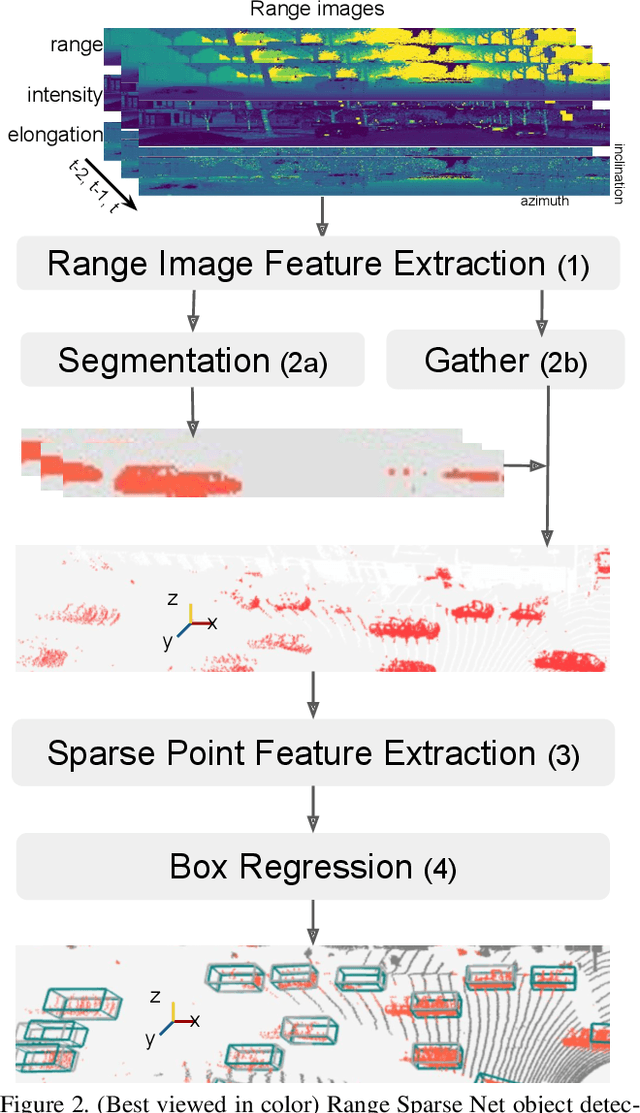
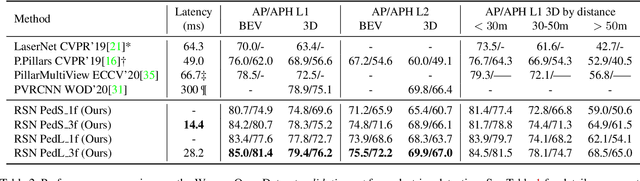
The detection of 3D objects from LiDAR data is a critical component in most autonomous driving systems. Safe, high speed driving needs larger detection ranges, which are enabled by new LiDARs. These larger detection ranges require more efficient and accurate detection models. Towards this goal, we propose Range Sparse Net (RSN), a simple, efficient, and accurate 3D object detector in order to tackle real time 3D object detection in this extended detection regime. RSN predicts foreground points from range images and applies sparse convolutions on the selected foreground points to detect objects. The lightweight 2D convolutions on dense range images results in significantly fewer selected foreground points, thus enabling the later sparse convolutions in RSN to efficiently operate. Combining features from the range image further enhance detection accuracy. RSN runs at more than 60 frames per second on a 150m x 150m detection region on Waymo Open Dataset (WOD) while being more accurate than previously published detectors. As of 11/2020, RSN is ranked first in the WOD leaderboard based on the APH/LEVEL 1 metrics for LiDAR-based pedestrian and vehicle detection, while being several times faster than alternatives.
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021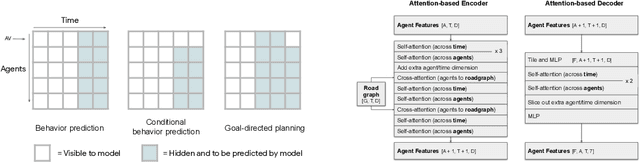
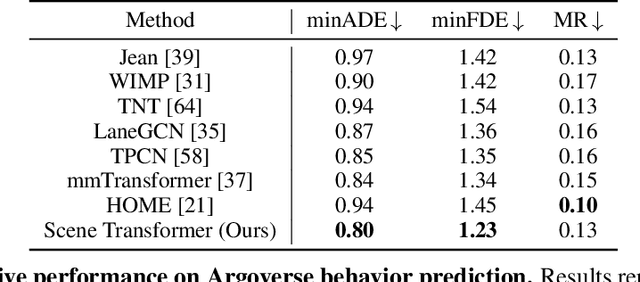
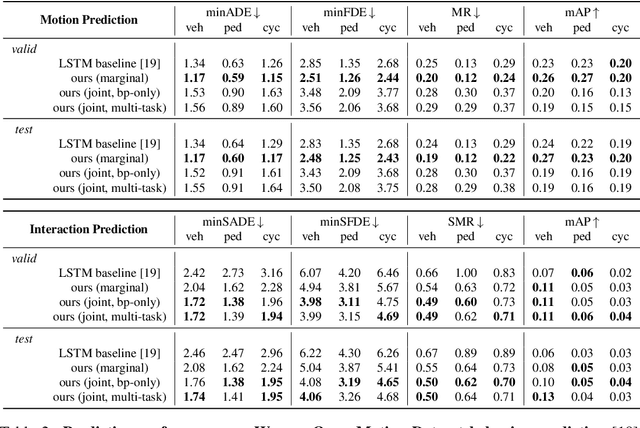
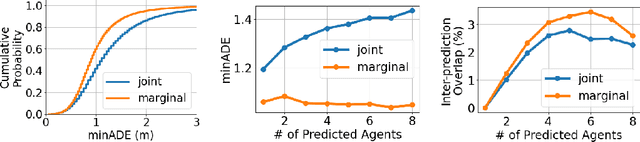
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
Local Metrics for Multi-Object Tracking
Apr 06, 2021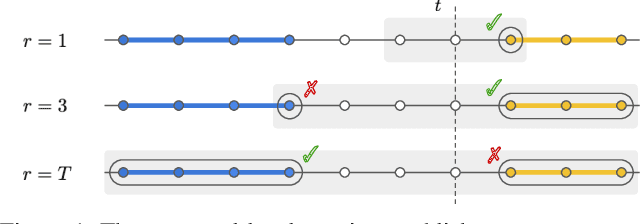
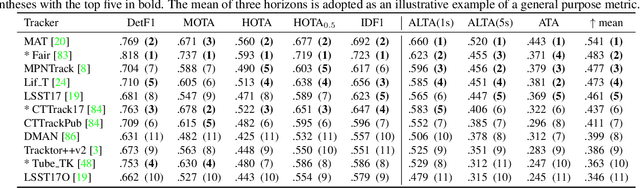
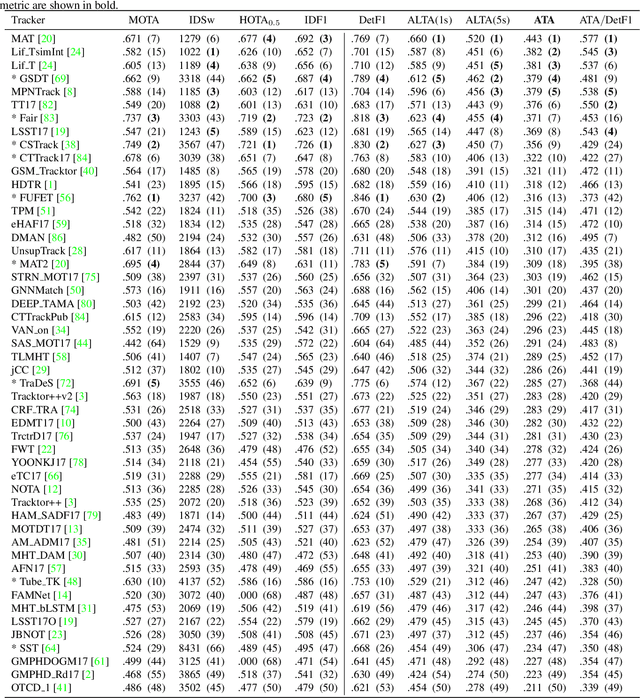
This paper introduces temporally local metrics for Multi-Object Tracking. These metrics are obtained by restricting existing metrics based on track matching to a finite temporal horizon, and provide new insight into the ability of trackers to maintain identity over time. Moreover, the horizon parameter offers a novel, meaningful mechanism by which to define the relative importance of detection and association, a common dilemma in applications where imperfect association is tolerable. It is shown that the historical Average Tracking Accuracy (ATA) metric exhibits superior sensitivity to association, enabling its proposed local variant, ALTA, to capture a wide range of characteristics. In particular, ALTA is better equipped to identify advances in association independent of detection. The paper further presents an error decomposition for ATA that reveals the impact of four distinct error types and is equally applicable to ALTA. The diagnostic capabilities of ALTA are demonstrated on the MOT 2017 and Waymo Open Dataset benchmarks.
Range Conditioned Dilated Convolutions for Scale Invariant 3D Object Detection
May 20, 2020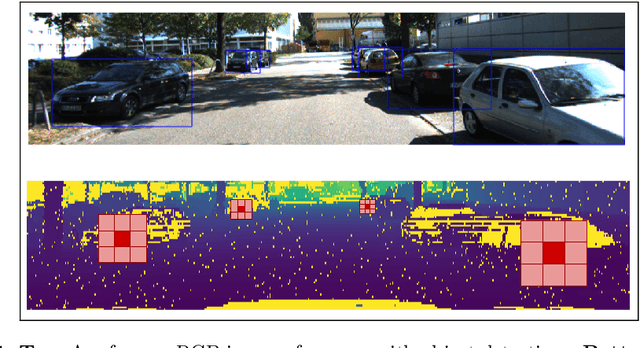

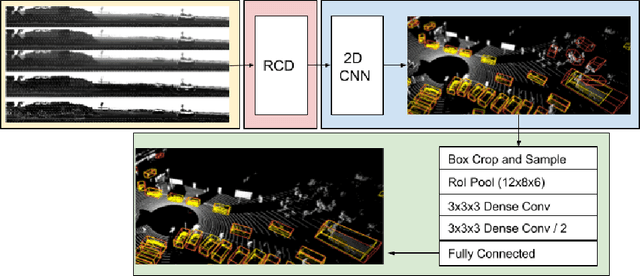
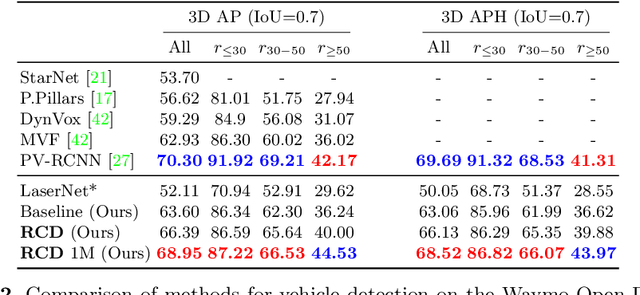
This paper presents a novel 3D object detection framework that processes LiDAR data directly on a representation of the sensor's native range images. When operating in the range image view, one faces learning challenges, including occlusion and considerable scale variation, limiting the obtainable accuracy. To address these challenges, a range-conditioned dilated block (RCD) is proposed to dynamically adjust a continuous dilation rate as a function of the measured range, achieving scale invariance. Furthermore, soft range gating helps mitigate the effect of occlusion. An end-to-end trained box-refinement network brings additional performance improvements in occluded areas, and produces more accurate bounding box predictions. On the challenging Waymo Open Dataset, our improved range-based detector outperforms state of the art at long range detection. Our framework is superior to prior multiview, voxel-based methods over all ranges, setting a new baseline for range-based 3D detection on this large scale public dataset.
Learning to Drive from Simulation without Real World Labels
Dec 13, 2018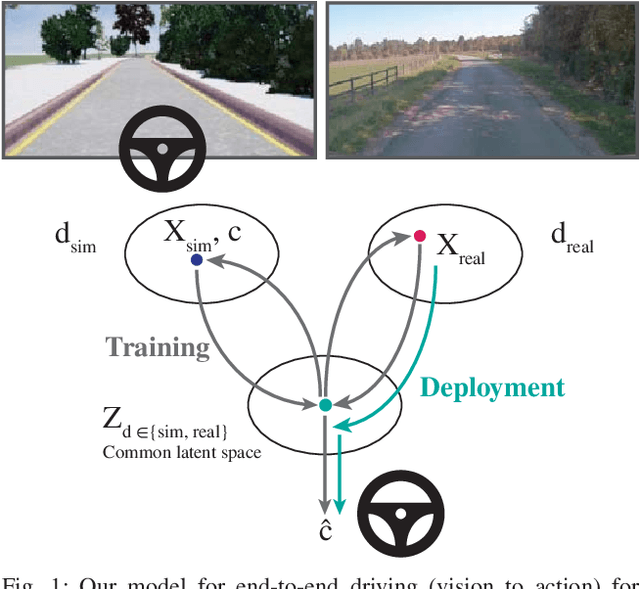
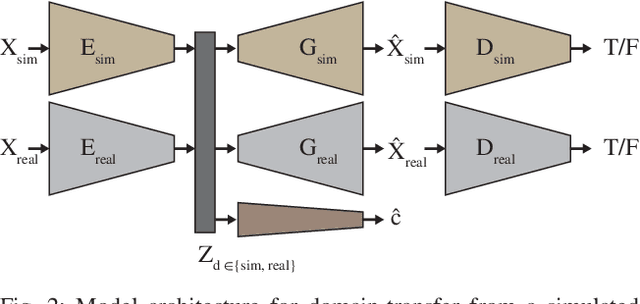
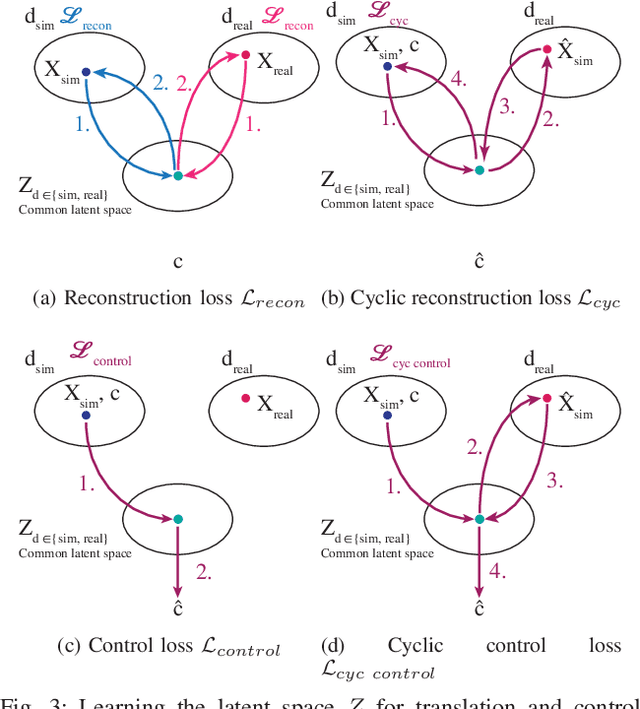

Simulation can be a powerful tool for understanding machine learning systems and designing methods to solve real-world problems. Training and evaluating methods purely in simulation is often "doomed to succeed" at the desired task in a simulated environment, but the resulting models are incapable of operation in the real world. Here we present and evaluate a method for transferring a vision-based lane following driving policy from simulation to operation on a rural road without any real-world labels. Our approach leverages recent advances in image-to-image translation to achieve domain transfer while jointly learning a single-camera control policy from simulation control labels. We assess the driving performance of this method using both open-loop regression metrics, and closed-loop performance operating an autonomous vehicle on rural and urban roads.
Deep Cosine Metric Learning for Person Re-Identification
Dec 02, 2018
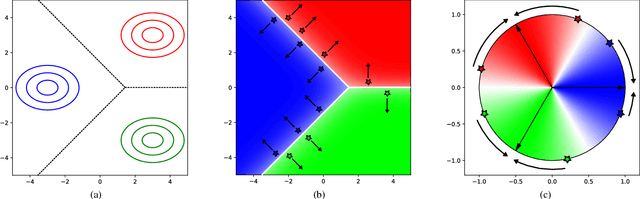
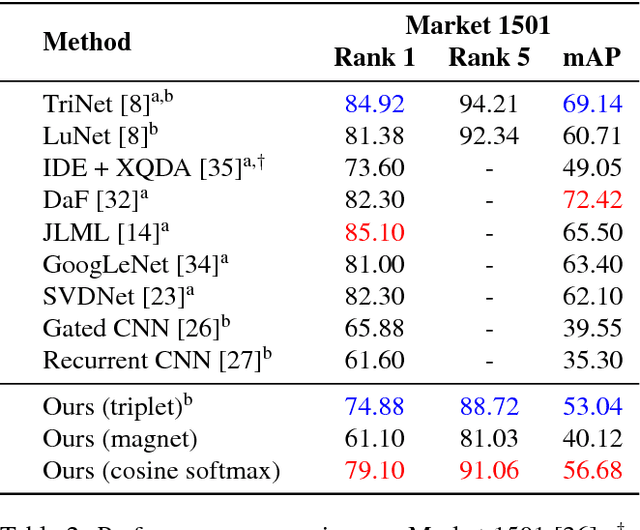
Metric learning aims to construct an embedding where two extracted features corresponding to the same identity are likely to be closer than features from different identities. This paper presents a method for learning such a feature space where the cosine similarity is effectively optimized through a simple re-parametrization of the conventional softmax classification regime. At test time, the final classification layer can be stripped from the network to facilitate nearest neighbor queries on unseen individuals using the cosine similarity metric. This approach presents a simple alternative to direct metric learning objectives such as siamese networks that have required sophisticated pair or triplet sampling strategies in the past. The method is evaluated on two large-scale pedestrian re-identification datasets where competitive results are achieved overall. In particular, we achieve better generalization on the test set compared to a network trained with triplet loss.
Dropout Distillation for Efficiently Estimating Model Confidence
Sep 27, 2018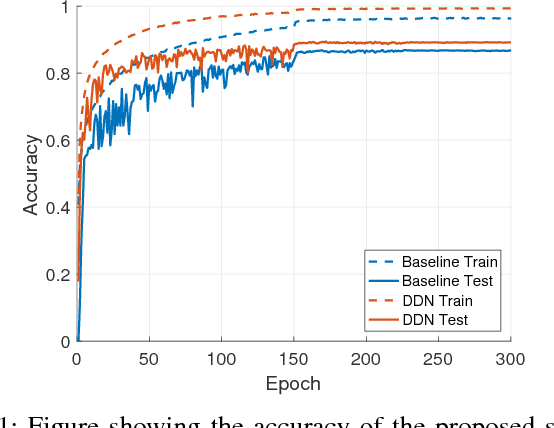
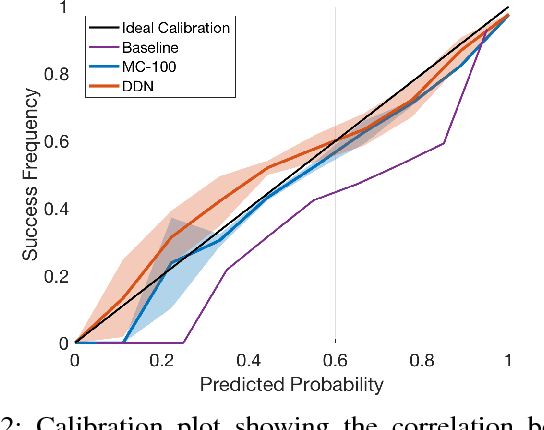
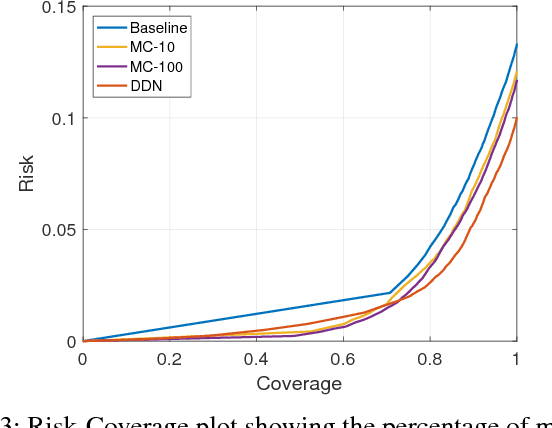
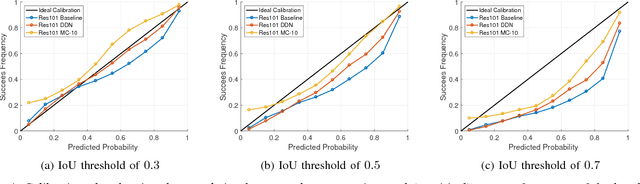
We propose an efficient way to output better calibrated uncertainty scores from neural networks. The Distilled Dropout Network (DDN) makes standard (non-Bayesian) neural networks more introspective by adding a new training loss which prevents them from being overconfident. Our method is more efficient than Bayesian neural networks or model ensembles which, despite providing more reliable uncertainty scores, are more cumbersome to train and slower to test. We evaluate DDN on the the task of image classification on the CIFAR-10 dataset and show that our calibration results are competitive even when compared to 100 Monte Carlo samples from a dropout network while they also increase the classification accuracy. We also propose better calibration within the state of the art Faster R-CNN object detection framework and show, using the COCO dataset, that DDN helps train better calibrated object detectors.