 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEMP: Keyframe-Based Hierarchical End-to-End Deep Model for Long-Term Trajectory Prediction
May 10, 2022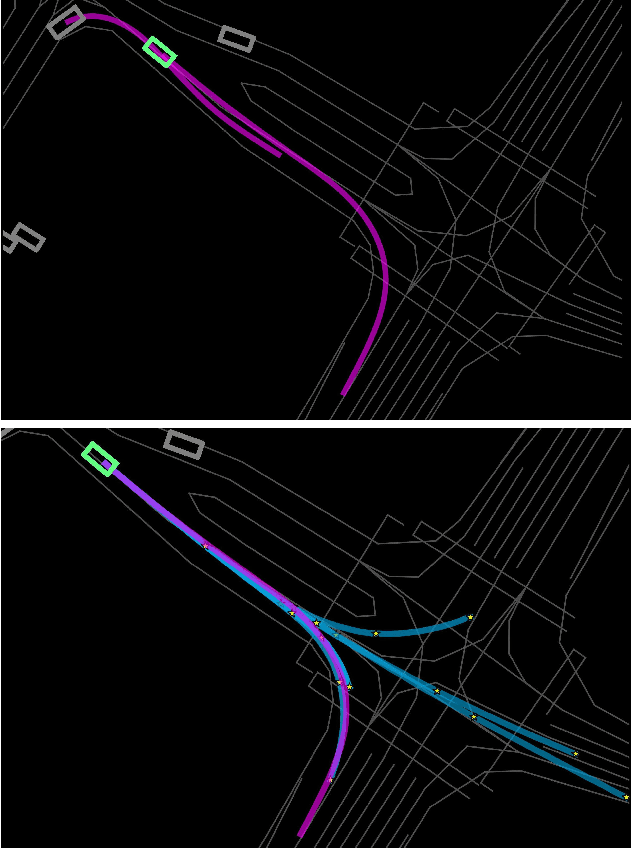
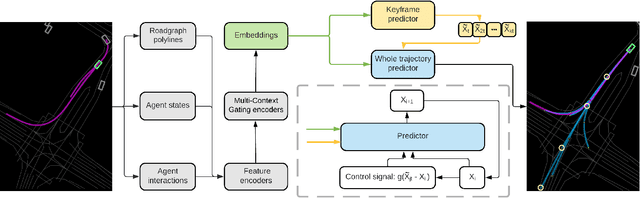
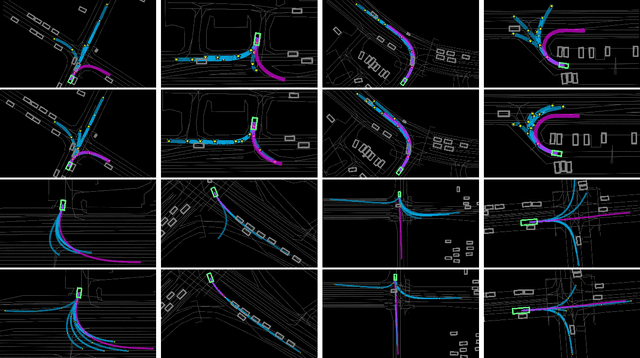
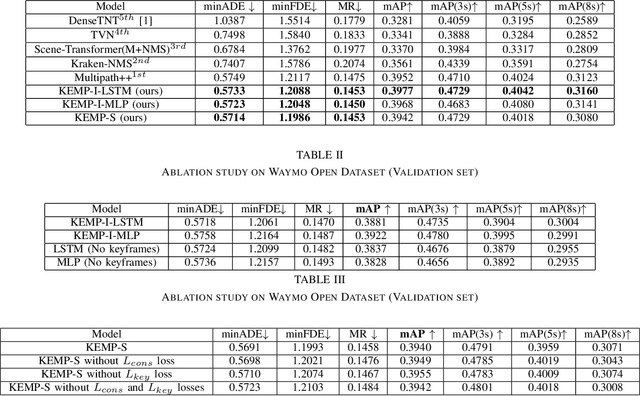
Predicting future trajectories of road agents is a critical task for autonomous driving. Recent goal-based trajectory prediction methods, such as DenseTNT and PECNet, have shown good performance on prediction tasks on public datasets. However, they usually require complicated goal-selection algorithms and optimization. In this work, we propose KEMP, a hierarchical end-to-end deep learning framework for trajectory prediction. At the core of our framework is keyframe-based trajectory prediction, where keyframes are representative states that trace out the general direction of the trajectory. KEMP first predicts keyframes conditioned on the road context, and then fills in intermediate states conditioned on the keyframes and the road context. Under our general framework, goal-conditioned methods are special cases in which the number of keyframes equal to one. Unlike goal-conditioned methods, our keyframe predictor is learned automatically and does not require hand-crafted goal-selection algorithms. We evaluate our model on public benchmarks and our model ranked 1st on Waymo Open Motion Dataset Leaderboard (as of September 1, 2021).
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021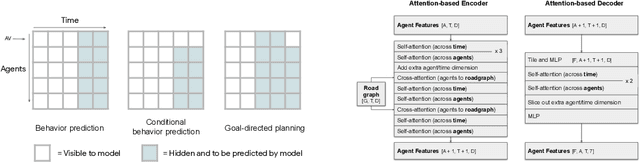
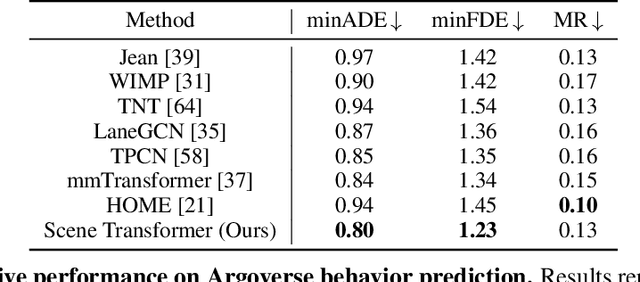
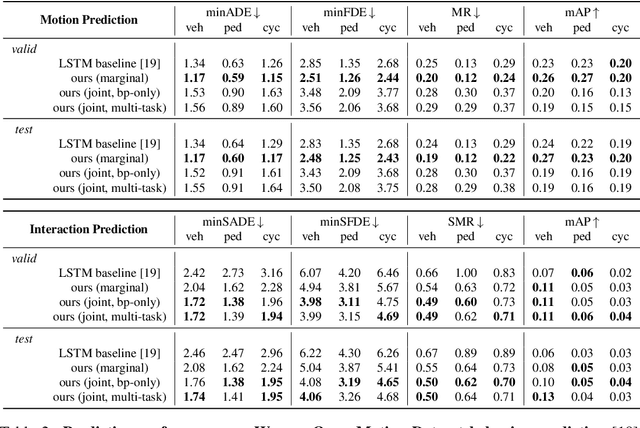
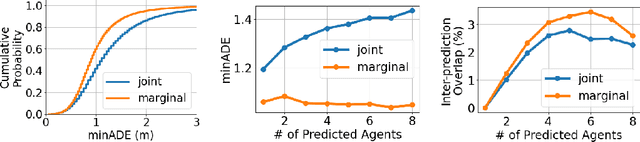
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
Learning Cross-Context Entity Representations from Text
Jan 11, 2020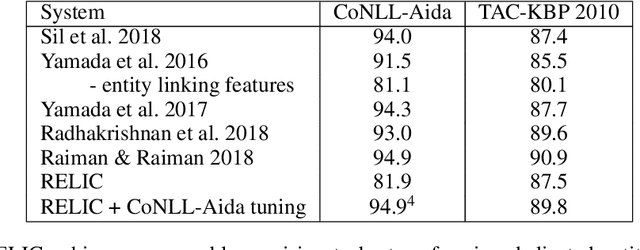
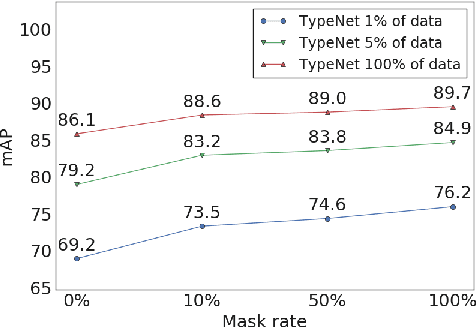

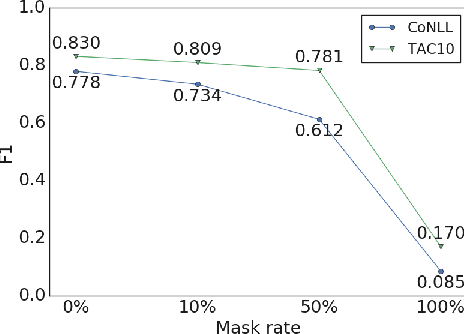
Language modeling tasks, in which words, or word-pieces, are predicted on the basis of a local context, have been very effective for learning word embeddings and context dependent representations of phrases. Motivated by the observation that efforts to code world knowledge into machine readable knowledge bases or human readable encyclopedias tend to be entity-centric, we investigate the use of a fill-in-the-blank task to learn context independent representations of entities from the text contexts in which those entities were mentioned. We show that large scale training of neural models allows us to learn high quality entity representations, and we demonstrate successful results on four domains: (1) existing entity-level typing benchmarks, including a 64% error reduction over previous work on TypeNet (Murty et al., 2018); (2) a novel few-shot category reconstruction task; (3) existing entity linking benchmarks, where we match the state-of-the-art on CoNLL-Aida without linking-specific features and obtain a score of 89.8% on TAC-KBP 2010 without using any alias table, external knowledge base or in domain training data and (4) answering trivia questions, which uniquely identify entities. Our global entity representations encode fine-grained type categories, such as Scottish footballers, and can answer trivia questions such as: Who was the last inmate of Spandau jail in Berlin?
Fusion of Detected Objects in Text for Visual Question Answering
Aug 14, 2019

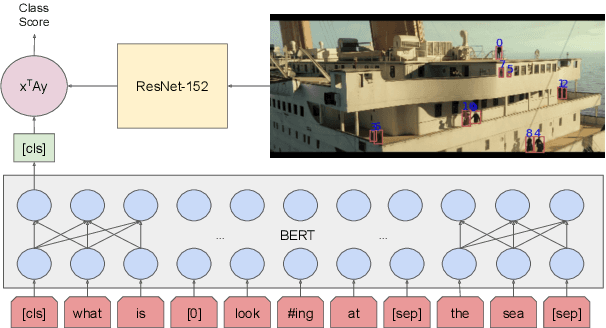
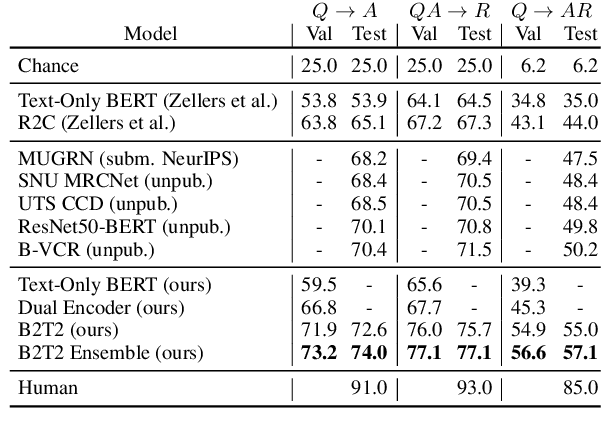
To advance models of multimodal context, we introduce a simple yet powerful neural architecture for data that combines vision and natural language. The "Bounding Boxes in Text Transformer" (B2T2) also leverages referential information binding words to portions of the image in a single unified architecture. B2T2 is highly effective on the Visual Commonsense Reasoning benchmark (visualcommonsense.com), achieving a new state-of-the-art with a 25% relative reduction in error rate compared to published baselines and obtaining the best performance to date on the public leaderboard (as of May 13, 2019). A detailed ablation analysis shows that the early integration of the visual features into the text analysis is key to the effectiveness of the new architecture.
Matching the Blanks: Distributional Similarity for Relation Learning
Jun 07, 2019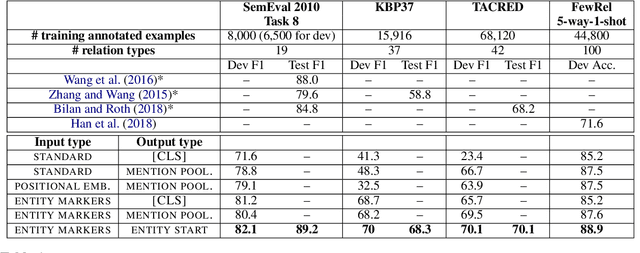
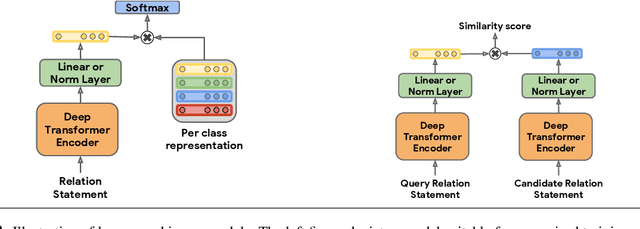

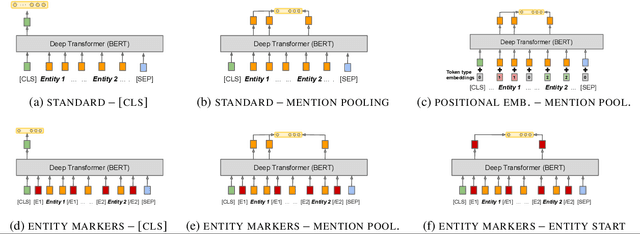
General purpose relation extractors, which can model arbitrary relations, are a core aspiration in information extraction. Efforts have been made to build general purpose extractors that represent relations with their surface forms, or which jointly embed surface forms with relations from an existing knowledge graph. However, both of these approaches are limited in their ability to generalize. In this paper, we build on extensions of Harris' distributional hypothesis to relations, as well as recent advances in learning text representations (specifically, BERT), to build task agnostic relation representations solely from entity-linked text. We show that these representations significantly outperform previous work on exemplar based relation extraction (FewRel) even without using any of that task's training data. We also show that models initialized with our task agnostic representations, and then tuned on supervised relation extraction datasets, significantly outperform the previous methods on SemEval 2010 Task 8, KBP37, and TACRED.
Image-to-Markup Generation with Coarse-to-Fine Attention
Jun 13, 2017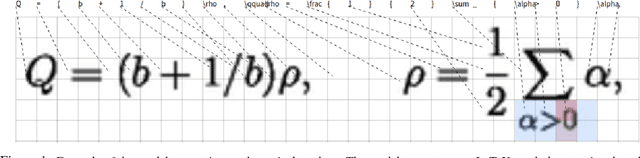
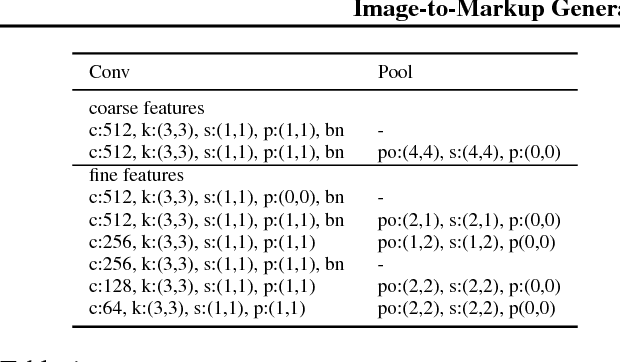
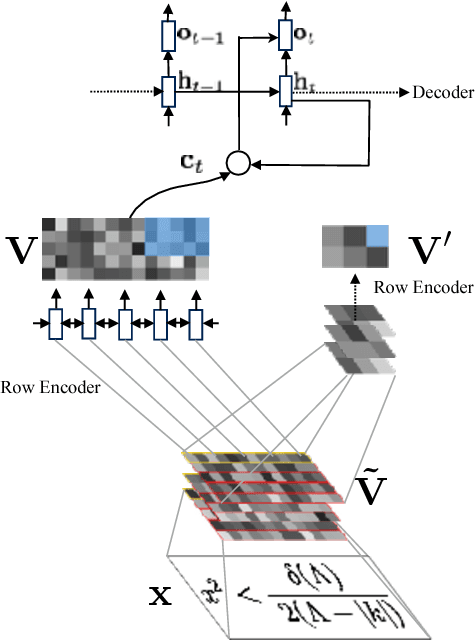
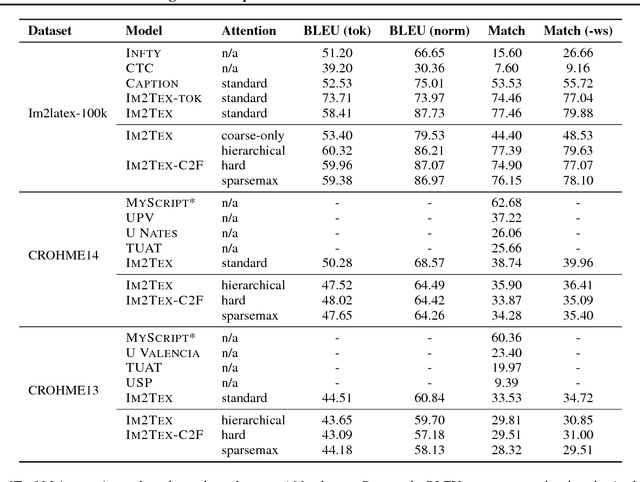
We present a neural encoder-decoder model to convert images into presentational markup based on a scalable coarse-to-fine attention mechanism. Our method is evaluated in the context of image-to-LaTeX generation, and we introduce a new dataset of real-world rendered mathematical expressions paired with LaTeX markup. We show that unlike neural OCR techniques using CTC-based models, attention-based approaches can tackle this non-standard OCR task. Our approach outperforms classical mathematical OCR systems by a large margin on in-domain rendered data, and, with pretraining, also performs well on out-of-domain handwritten data. To reduce the inference complexity associated with the attention-based approaches, we introduce a new coarse-to-fine attention layer that selects a support region before applying attention.