 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
Oct 04, 2022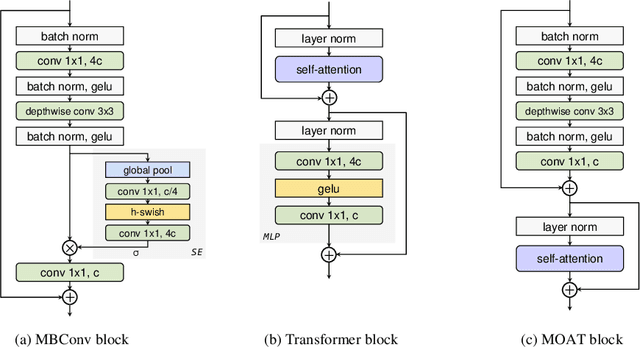

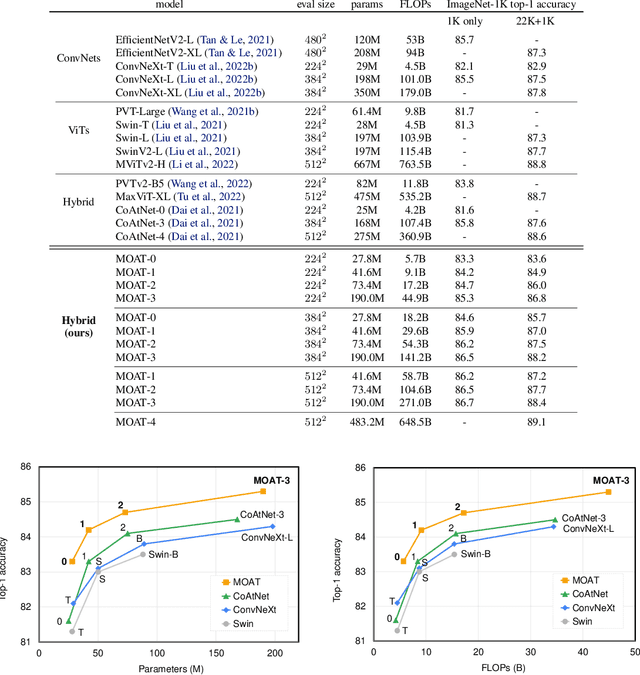
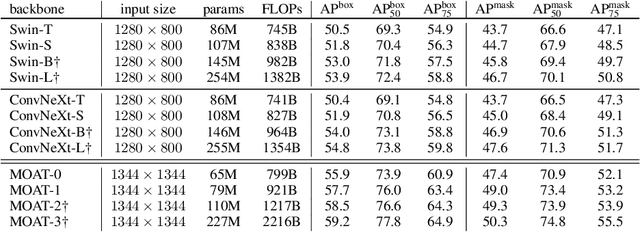
This paper presents MOAT, a family of neural networks that build on top of MObile convolution (i.e., inverted residual blocks) and ATtention. Unlike the current works that stack separate mobile convolution and transformer blocks, we effectively merge them into a MOAT block. Starting with a standard Transformer block, we replace its multi-layer perceptron with a mobile convolution block, and further reorder it before the self-attention operation. The mobile convolution block not only enhances the network representation capacity, but also produces better downsampled features. Our conceptually simple MOAT networks are surprisingly effective, achieving 89.1% top-1 accuracy on ImageNet-1K with ImageNet-22K pretraining. Additionally, MOAT can be seamlessly applied to downstream tasks that require large resolution inputs by simply converting the global attention to window attention. Thanks to the mobile convolution that effectively exchanges local information between pixels (and thus cross-windows), MOAT does not need the extra window-shifting mechanism. As a result, on COCO object detection, MOAT achieves 59.2% box AP with 227M model parameters (single-scale inference, and hard NMS), and on ADE20K semantic segmentation, MOAT attains 57.6% mIoU with 496M model parameters (single-scale inference). Finally, the tiny-MOAT family, obtained by simply reducing the channel sizes, also surprisingly outperforms several mobile-specific transformer-based models on ImageNet. We hope our simple yet effective MOAT will inspire more seamless integration of convolution and self-attention. Code is made publicly available.
Robust Category-Level 6D Pose Estimation with Coarse-to-Fine Rendering of Neural Features
Sep 12, 2022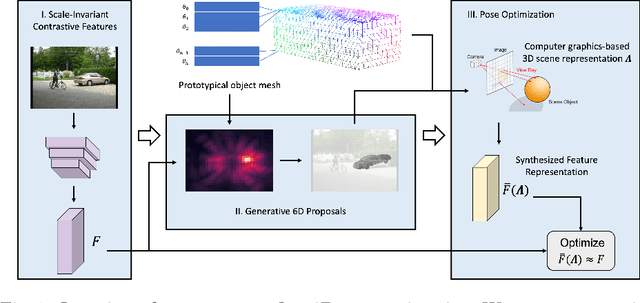
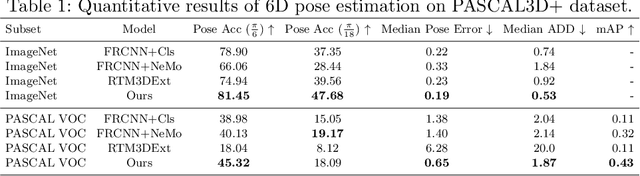


We consider the problem of category-level 6D pose estimation from a single RGB image. Our approach represents an object category as a cuboid mesh and learns a generative model of the neural feature activations at each mesh vertex to perform pose estimation through differentiable rendering. A common problem of rendering-based approaches is that they rely on bounding box proposals, which do not convey information about the 3D rotation of the object and are not reliable when objects are partially occluded. Instead, we introduce a coarse-to-fine optimization strategy that utilizes the rendering process to estimate a sparse set of 6D object proposals, which are subsequently refined with gradient-based optimization. The key to enabling the convergence of our approach is a neural feature representation that is trained to be scale- and rotation-invariant using contrastive learning. Our experiments demonstrate an enhanced category-level 6D pose estimation performance compared to prior work, particularly under strong partial occlusion.
Masked Autoencoders Enable Efficient Knowledge Distillers
Aug 25, 2022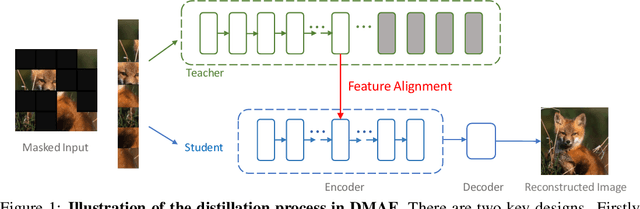

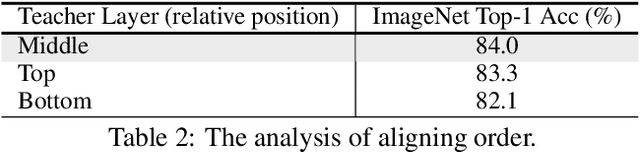
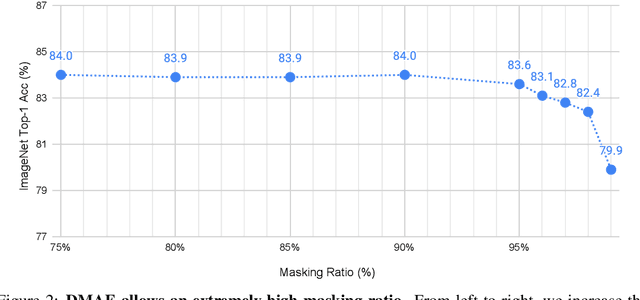
This paper studies the potential of distilling knowledge from pre-trained models, especially Masked Autoencoders. Our approach is simple: in addition to optimizing the pixel reconstruction loss on masked inputs, we minimize the distance between the intermediate feature map of the teacher model and that of the student model. This design leads to a computationally efficient knowledge distillation framework, given 1) only a small visible subset of patches is used, and 2) the (cumbersome) teacher model only needs to be partially executed, \ie, forward propagate inputs through the first few layers, for obtaining intermediate feature maps. Compared to directly distilling fine-tuned models, distilling pre-trained models substantially improves downstream performance. For example, by distilling the knowledge from an MAE pre-trained ViT-L into a ViT-B, our method achieves 84.0% ImageNet top-1 accuracy, outperforming the baseline of directly distilling a fine-tuned ViT-L by 1.2%. More intriguingly, our method can robustly distill knowledge from teacher models even with extremely high masking ratios: e.g., with 95% masking ratio where merely TEN patches are visible during distillation, our ViT-B competitively attains a top-1 ImageNet accuracy of 83.6%; surprisingly, it can still secure 82.4% top-1 ImageNet accuracy by aggressively training with just FOUR visible patches (98% masking ratio). The code and models are publicly available at https://github.com/UCSC-VLAA/DMAE.
Explicit Occlusion Reasoning for Multi-person 3D Human Pose Estimation
Jul 29, 2022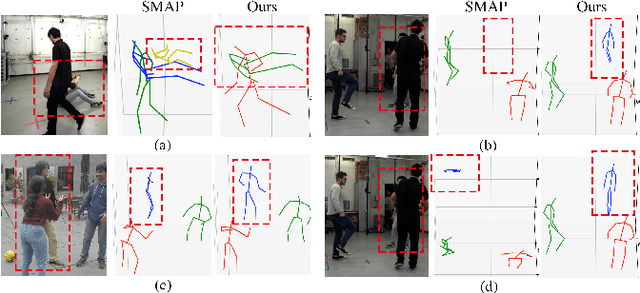
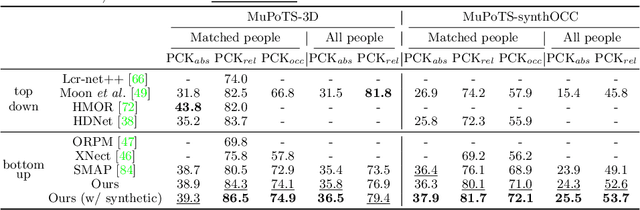
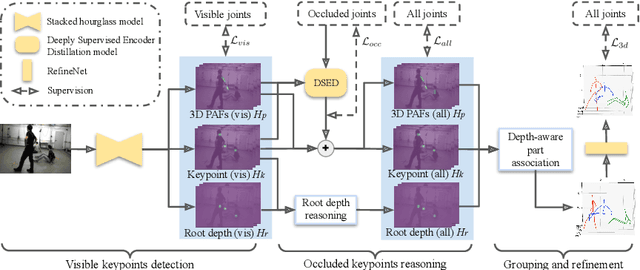

Occlusion poses a great threat to monocular multi-person 3D human pose estimation due to large variability in terms of the shape, appearance, and position of occluders. While existing methods try to handle occlusion with pose priors/constraints, data augmentation, or implicit reasoning, they still fail to generalize to unseen poses or occlusion cases and may make large mistakes when multiple people are present. Inspired by the remarkable ability of humans to infer occluded joints from visible cues, we develop a method to explicitly model this process that significantly improves bottom-up multi-person human pose estimation with or without occlusions. First, we split the task into two subtasks: visible keypoints detection and occluded keypoints reasoning, and propose a Deeply Supervised Encoder Distillation (DSED) network to solve the second one. To train our model, we propose a Skeleton-guided human Shape Fitting (SSF) approach to generate pseudo occlusion labels on the existing datasets, enabling explicit occlusion reasoning. Experiments show that explicitly learning from occlusions improves human pose estimation. In addition, exploiting feature-level information of visible joints allows us to reason about occluded joints more accurately. Our method outperforms both the state-of-the-art top-down and bottom-up methods on several benchmarks.
In Defense of Online Models for Video Instance Segmentation
Jul 21, 2022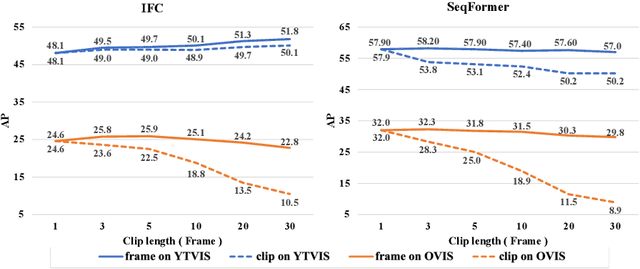

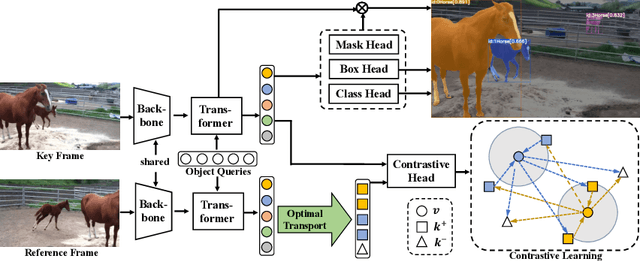
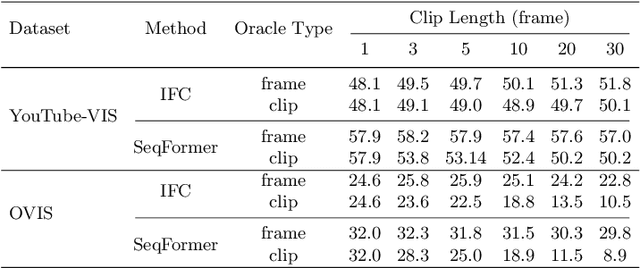
In recent years, video instance segmentation (VIS) has been largely advanced by offline models, while online models gradually attracted less attention possibly due to their inferior performance. However, online methods have their inherent advantage in handling long video sequences and ongoing videos while offline models fail due to the limit of computational resources. Therefore, it would be highly desirable if online models can achieve comparable or even better performance than offline models. By dissecting current online models and offline models, we demonstrate that the main cause of the performance gap is the error-prone association between frames caused by the similar appearance among different instances in the feature space. Observing this, we propose an online framework based on contrastive learning that is able to learn more discriminative instance embeddings for association and fully exploit history information for stability. Despite its simplicity, our method outperforms all online and offline methods on three benchmarks. Specifically, we achieve 49.5 AP on YouTube-VIS 2019, a significant improvement of 13.2 AP and 2.1 AP over the prior online and offline art, respectively. Moreover, we achieve 30.2 AP on OVIS, a more challenging dataset with significant crowding and occlusions, surpassing the prior art by 14.8 AP. The proposed method won first place in the video instance segmentation track of the 4th Large-scale Video Object Segmentation Challenge (CVPR2022). We hope the simplicity and effectiveness of our method, as well as our insight into current methods, could shed light on the exploration of VIS models.
k-means Mask Transformer
Jul 08, 2022
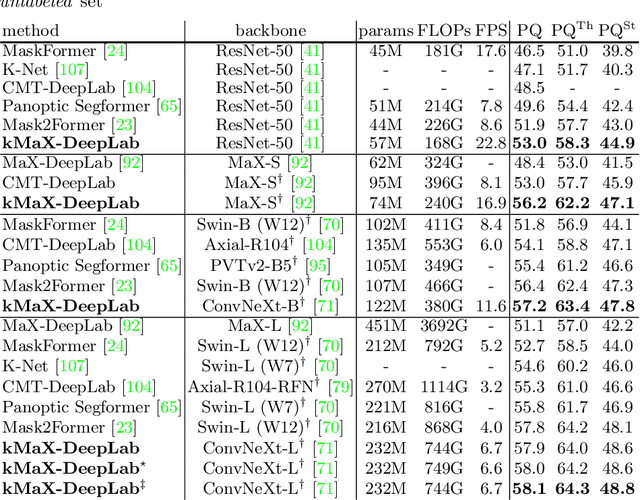
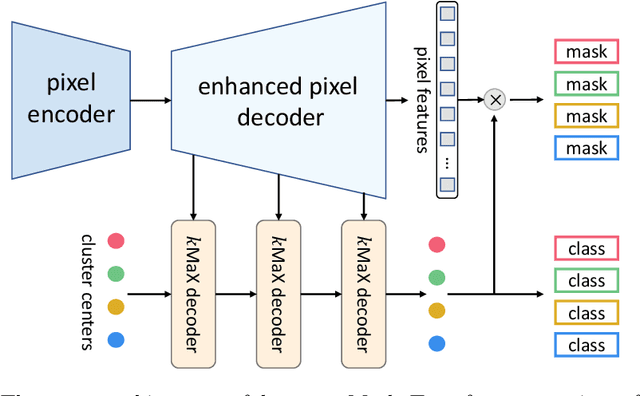
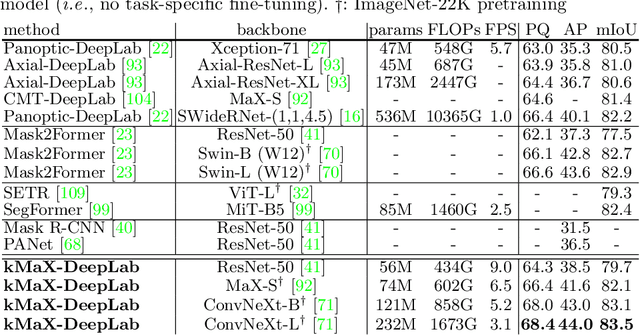
The rise of transformers in vision tasks not only advances network backbone designs, but also starts a brand-new page to achieve end-to-end image recognition (e.g., object detection and panoptic segmentation). Originated from Natural Language Processing (NLP), transformer architectures, consisting of self-attention and cross-attention, effectively learn long-range interactions between elements in a sequence. However, we observe that most existing transformer-based vision models simply borrow the idea from NLP, neglecting the crucial difference between languages and images, particularly the extremely large sequence length of spatially flattened pixel features. This subsequently impedes the learning in cross-attention between pixel features and object queries. In this paper, we rethink the relationship between pixels and object queries and propose to reformulate the cross-attention learning as a clustering process. Inspired by the traditional k-means clustering algorithm, we develop a k-means Mask Xformer (kMaX-DeepLab) for segmentation tasks, which not only improves the state-of-the-art, but also enjoys a simple and elegant design. As a result, our kMaX-DeepLab achieves a new state-of-the-art performance on COCO val set with 58.0% PQ, and Cityscapes val set with 68.4% PQ, 44.0% AP, and 83.5% mIoU without test-time augmentation or external dataset. We hope our work can shed some light on designing transformers tailored for vision tasks. Code and models are available at https://github.com/google-research/deeplab2
Unsupervised Domain Adaptation through Shape Modeling for Medical Image Segmentation
Jul 06, 2022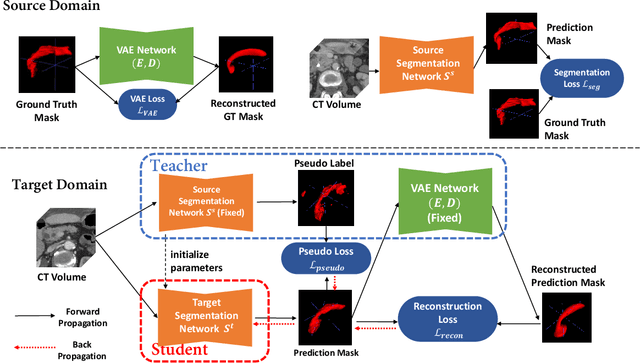
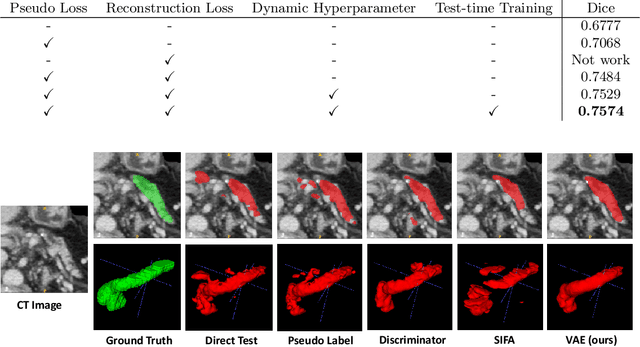
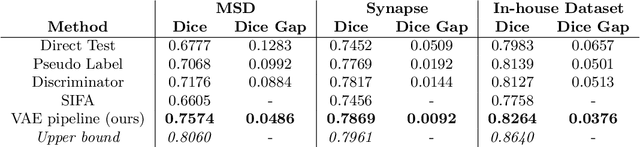
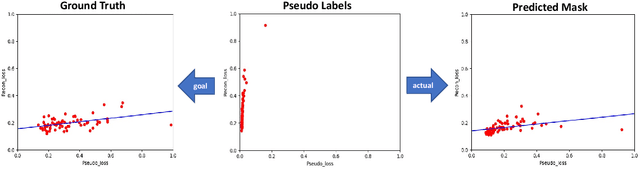
Shape information is a strong and valuable prior in segmenting organs in medical images. However, most current deep learning based segmentation algorithms have not taken shape information into consideration, which can lead to bias towards texture. We aim at modeling shape explicitly and using it to help medical image segmentation. Previous methods proposed Variational Autoencoder (VAE) based models to learn the distribution of shape for a particular organ and used it to automatically evaluate the quality of a segmentation prediction by fitting it into the learned shape distribution. Based on which we aim at incorporating VAE into current segmentation pipelines. Specifically, we propose a new unsupervised domain adaptation pipeline based on a pseudo loss and a VAE reconstruction loss under a teacher-student learning paradigm. Both losses are optimized simultaneously and, in return, boost the segmentation task performance. Extensive experiments on three public Pancreas segmentation datasets as well as two in-house Pancreas segmentation datasets show consistent improvements with at least 2.8 points gain in the Dice score, demonstrating the effectiveness of our method in challenging unsupervised domain adaptation scenarios for medical image segmentation. We hope this work will advance shape analysis and geometric learning in medical imaging.
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
Jun 17, 2022
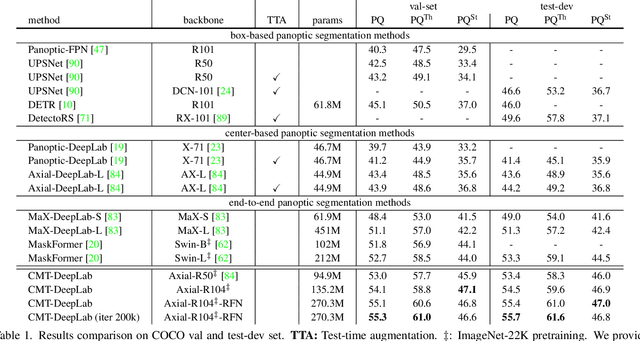
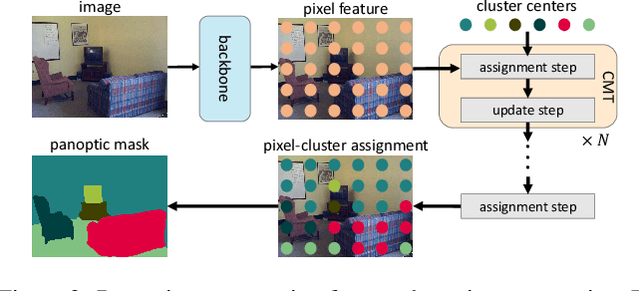

We propose Clustering Mask Transformer (CMT-DeepLab), a transformer-based framework for panoptic segmentation designed around clustering. It rethinks the existing transformer architectures used in segmentation and detection; CMT-DeepLab considers the object queries as cluster centers, which fill the role of grouping the pixels when applied to segmentation. The clustering is computed with an alternating procedure, by first assigning pixels to the clusters by their feature affinity, and then updating the cluster centers and pixel features. Together, these operations comprise the Clustering Mask Transformer (CMT) layer, which produces cross-attention that is denser and more consistent with the final segmentation task. CMT-DeepLab improves the performance over prior art significantly by 4.4% PQ, achieving a new state-of-the-art of 55.7% PQ on the COCO test-dev set.
A Simple Data Mixing Prior for Improving Self-Supervised Learning
Jun 15, 2022
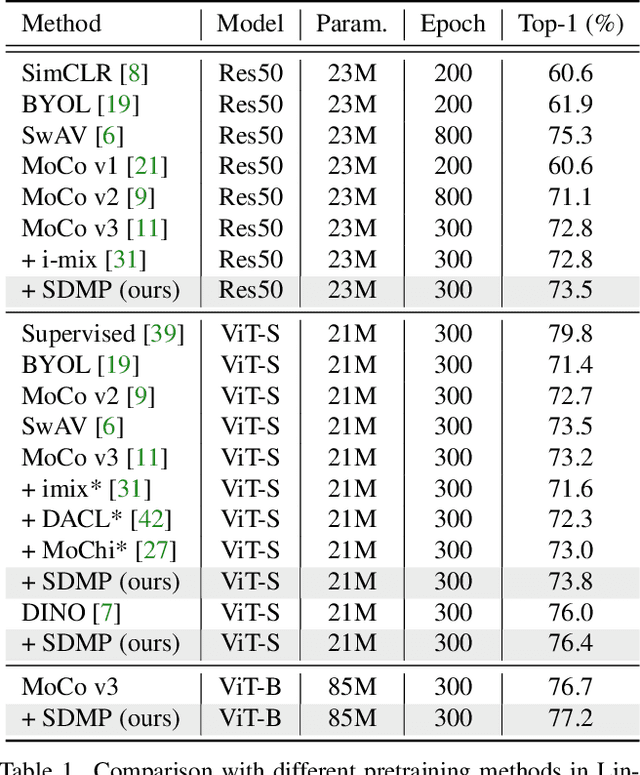

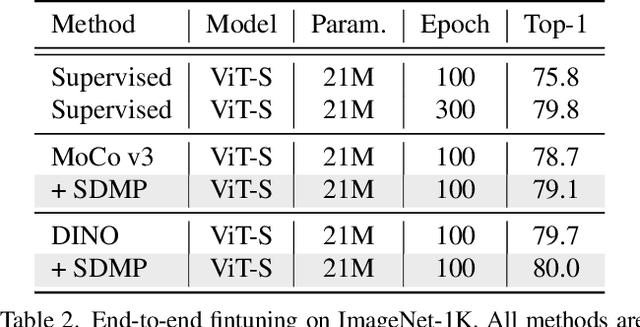
Data mixing (e.g., Mixup, Cutmix, ResizeMix) is an essential component for advancing recognition models. In this paper, we focus on studying its effectiveness in the self-supervised setting. By noticing the mixed images that share the same source images are intrinsically related to each other, we hereby propose SDMP, short for $\textbf{S}$imple $\textbf{D}$ata $\textbf{M}$ixing $\textbf{P}$rior, to capture this straightforward yet essential prior, and position such mixed images as additional $\textbf{positive pairs}$ to facilitate self-supervised representation learning. Our experiments verify that the proposed SDMP enables data mixing to help a set of self-supervised learning frameworks (e.g., MoCo) achieve better accuracy and out-of-distribution robustness. More notably, our SDMP is the first method that successfully leverages data mixing to improve (rather than hurt) the performance of Vision Transformers in the self-supervised setting. Code is publicly available at https://github.com/OliverRensu/SDMP
VoGE: A Differentiable Volume Renderer using Gaussian Ellipsoids for Analysis-by-Synthesis
May 30, 2022

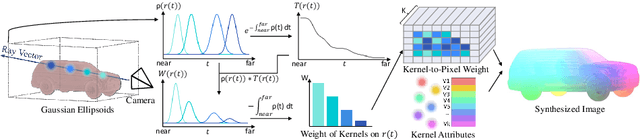
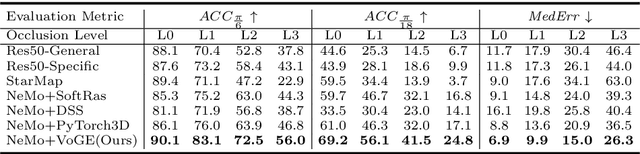
Differentiable rendering allows the application of computer graphics on vision tasks, e.g. object pose and shape fitting, via analysis-by-synthesis, where gradients at occluded regions are important when inverting the rendering process. To obtain those gradients, state-of-the-art (SoTA) differentiable renderers use rasterization to collect a set of nearest components for each pixel and aggregate them based on the viewing distance. In this paper, we propose VoGE, which uses ray tracing to capture nearest components with their volume density distributions on the rays and aggregates via integral of the volume densities based on Gaussian ellipsoids, which brings more efficient and stable gradients. To efficiently render via VoGE, we propose an approximate close-form solution for the volume density aggregation and a coarse-to-fine rendering strategy. Finally, we provide a CUDA implementation of VoGE, which gives a competitive rendering speed in comparison to PyTorch3D. Quantitative and qualitative experiment results show VoGE outperforms SoTA counterparts when applied to various vision tasks,e.g., object pose estimation, shape/texture fitting, and occlusion reasoning. The VoGE library and demos are available at https://github.com/Angtian/VoGE.