 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEARL: Entropy-Aware RL Alignment of LLMs for Reliable RTL Code Generation
Nov 15, 2025Recent advances in large language models (LLMs) have demonstrated significant potential in hardware design automation, particularly in using natural language to synthesize Register-Transfer Level (RTL) code. Despite this progress, a gap remains between model capability and the demands of real-world RTL design, including syntax errors, functional hallucinations, and weak alignment to designer intent. Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising approach to bridge this gap, as hardware provides executable and formally checkable signals that can be used to further align model outputs with design intent. However, in long, structured RTL code sequences, not all tokens contribute equally to functional correctness, and naïvely spreading gradients across all tokens dilutes learning signals. A key insight from our entropy analysis in RTL generation is that only a small fraction of tokens (e.g., always, if, assign, posedge) exhibit high uncertainty and largely influence control flow and module structure. To address these challenges, we present EARL, an Entropy-Aware Reinforcement Learning framework for Verilog generation. EARL performs policy optimization using verifiable reward signals and introduces entropy-guided selective updates that gate policy gradients to high-entropy tokens. This approach preserves training stability and concentrates gradient updates on functionally important regions of code. Our experiments on VerilogEval and RTLLM show that EARL improves functional pass rates over prior LLM baselines by up to 14.7%, while reducing unnecessary updates and improving training stability. These results indicate that focusing RL on critical, high-uncertainty tokens enables more reliable and targeted policy improvement for structured RTL code generation.
SP2RINT: Spatially-Decoupled Physics-Inspired Progressive Inverse Optimization for Scalable, PDE-Constrained Meta-Optical Neural Network Training
May 23, 2025DONNs harness the physics of light propagation for efficient analog computation, with applications in AI and signal processing. Advances in nanophotonic fabrication and metasurface-based wavefront engineering have opened new pathways to realize high-capacity DONNs across various spectral regimes. Training such DONN systems to determine the metasurface structures remains challenging. Heuristic methods are fast but oversimplify metasurfaces modulation, often resulting in physically unrealizable designs and significant performance degradation. Simulation-in-the-loop training methods directly optimize a physically implementable metasurface using adjoint methods during end-to-end DONN training, but are inherently computationally prohibitive and unscalable.To address these limitations, we propose SP2RINT, a spatially decoupled, progressive training framework that formulates DONN training as a PDE-constrained learning problem. Metasurface responses are first relaxed into freely trainable transfer matrices with a banded structure. We then progressively enforce physical constraints by alternating between transfer matrix training and adjoint-based inverse design, avoiding per-iteration PDE solves while ensuring final physical realizability. To further reduce runtime, we introduce a physics-inspired, spatially decoupled inverse design strategy based on the natural locality of field interactions. This approach partitions the metasurface into independently solvable patches, enabling scalable and parallel inverse design with system-level calibration. Evaluated across diverse DONN training tasks, SP2RINT achieves digital-comparable accuracy while being 1825 times faster than simulation-in-the-loop approaches. By bridging the gap between abstract DONN models and implementable photonic hardware, SP2RINT enables scalable, high-performance training of physically realizable meta-optical neural systems.
RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning
May 21, 2025Reinforcement learning (RL) has recently emerged as a compelling approach for enhancing the reasoning capabilities of large language models (LLMs), where an LLM generator serves as a policy guided by a verifier (reward model). However, current RL post-training methods for LLMs typically use verifiers that are fixed (rule-based or frozen pretrained) or trained discriminatively via supervised fine-tuning (SFT). Such designs are susceptible to reward hacking and generalize poorly beyond their training distributions. To overcome these limitations, we propose Tango, a novel framework that uses RL to concurrently train both an LLM generator and a verifier in an interleaved manner. A central innovation of Tango is its generative, process-level LLM verifier, which is trained via RL and co-evolves with the generator. Importantly, the verifier is trained solely based on outcome-level verification correctness rewards without requiring explicit process-level annotations. This generative RL-trained verifier exhibits improved robustness and superior generalization compared to deterministic or SFT-trained verifiers, fostering effective mutual reinforcement with the generator. Extensive experiments demonstrate that both components of Tango achieve state-of-the-art results among 7B/8B-scale models: the generator attains best-in-class performance across five competition-level math benchmarks and four challenging out-of-domain reasoning tasks, while the verifier leads on the ProcessBench dataset. Remarkably, both components exhibit particularly substantial improvements on the most difficult mathematical reasoning problems. Code is at: https://github.com/kaiwenzha/rl-tango.
MAPS: Multi-Fidelity AI-Augmented Photonic Simulation and Inverse Design Infrastructure
Mar 02, 2025



Inverse design has emerged as a transformative approach for photonic device optimization, enabling the exploration of high-dimensional, non-intuitive design spaces to create ultra-compact devices and advance photonic integrated circuits (PICs) in computing and interconnects. However, practical challenges, such as suboptimal device performance, limited manufacturability, high sensitivity to variations, computational inefficiency, and lack of interpretability, have hindered its adoption in commercial hardware. Recent advancements in AI-assisted photonic simulation and design offer transformative potential, accelerating simulations and design generation by orders of magnitude over traditional numerical methods. Despite these breakthroughs, the lack of an open-source, standardized infrastructure and evaluation benchmark limits accessibility and cross-disciplinary collaboration. To address this, we introduce MAPS, a multi-fidelity AI-augmented photonic simulation and inverse design infrastructure designed to bridge this gap. MAPS features three synergistic components: (1) MAPS-Data: A dataset acquisition framework for generating multi-fidelity, richly labeled devices, providing high-quality data for AI-for-optics research. (2) MAPS-Train: A flexible AI-for-photonics training framework offering a hierarchical data loading pipeline, customizable model construction, support for data- and physics-driven losses, and comprehensive evaluations. (3) MAPS-InvDes: An advanced adjoint inverse design toolkit that abstracts complex physics but exposes flexible optimization steps, integrates pre-trained AI models, and incorporates fabrication variation models. This infrastructure MAPS provides a unified, open-source platform for developing, benchmarking, and advancing AI-assisted photonic design workflows, accelerating innovation in photonic hardware optimization and scientific machine learning.
REG: Rectified Gradient Guidance for Conditional Diffusion Models
Jan 31, 2025Guidance techniques are simple yet effective for improving conditional generation in diffusion models. Albeit their empirical success, the practical implementation of guidance diverges significantly from its theoretical motivation. In this paper, we reconcile this discrepancy by replacing the scaled marginal distribution target, which we prove theoretically invalid, with a valid scaled joint distribution objective. Additionally, we show that the established guidance implementations are approximations to the intractable optimal solution under no future foresight constraint. Building on these theoretical insights, we propose rectified gradient guidance (REG), a versatile enhancement designed to boost the performance of existing guidance methods. Experiments on 1D and 2D demonstrate that REG provides a better approximation to the optimal solution than prior guidance techniques, validating the proposed theoretical framework. Extensive experiments on class-conditional ImageNet and text-to-image generation tasks show that incorporating REG consistently improves FID and Inception/CLIP scores across various settings compared to its absence.
PIC2O-Sim: A Physics-Inspired Causality-Aware Dynamic Convolutional Neural Operator for Ultra-Fast Photonic Device FDTD Simulation
Jun 24, 2024



The finite-difference time-domain (FDTD) method, which is important in photonic hardware design flow, is widely adopted to solve time-domain Maxwell equations. However, FDTD is known for its prohibitive runtime cost, taking minutes to hours to simulate a single device. Recently, AI has been applied to realize orders-of-magnitude speedup in partial differential equation (PDE) solving. However, AI-based FDTD solvers for photonic devices have not been clearly formulated. Directly applying off-the-shelf models to predict the optical field dynamics shows unsatisfying fidelity and efficiency since the model primitives are agnostic to the unique physical properties of Maxwell equations and lack algorithmic customization. In this work, we thoroughly investigate the synergy between neural operator designs and the physical property of Maxwell equations and introduce a physics-inspired AI-based FDTD prediction framework PIC2O-Sim which features a causality-aware dynamic convolutional neural operator as its backbone model that honors the space-time causality constraints via careful receptive field configuration and explicitly captures the permittivity-dependent light propagation behavior via an efficient dynamic convolution operator. Meanwhile, we explore the trade-offs among prediction scalability, fidelity, and efficiency via a multi-stage partitioned time-bundling technique in autoregressive prediction. Multiple key techniques have been introduced to mitigate iterative error accumulation while maintaining efficiency advantages during autoregressive field prediction. Extensive evaluations on three challenging photonic device simulation tasks have shown the superiority of our PIC2O-Sim method, showing 51.2% lower roll-out prediction error, 23.5 times fewer parameters than state-of-the-art neural operators, providing 300-600x higher simulation speed than an open-source FDTD numerical solver.
On the Theory of Cross-Modality Distillation with Contrastive Learning
May 06, 2024Cross-modality distillation arises as an important topic for data modalities containing limited knowledge such as depth maps and high-quality sketches. Such techniques are of great importance, especially for memory and privacy-restricted scenarios where labeled training data is generally unavailable. To solve the problem, existing label-free methods leverage a few pairwise unlabeled data to distill the knowledge by aligning features or statistics between the source and target modalities. For instance, one typically aims to minimize the L2 distance or contrastive loss between the learned features of pairs of samples in the source (e.g. image) and the target (e.g. sketch) modalities. However, most algorithms in this domain only focus on the experimental results but lack theoretical insight. To bridge the gap between the theory and practical method of cross-modality distillation, we first formulate a general framework of cross-modality contrastive distillation (CMCD), built upon contrastive learning that leverages both positive and negative correspondence, towards a better distillation of generalizable features. Furthermore, we establish a thorough convergence analysis that reveals that the distance between source and target modalities significantly impacts the test error on downstream tasks within the target modality which is also validated by the empirical results. Extensive experimental results show that our algorithm outperforms existing algorithms consistently by a margin of 2-3\% across diverse modalities and tasks, covering modalities of image, sketch, depth map, and audio and tasks of recognition and segmentation.
Nominality Score Conditioned Time Series Anomaly Detection by Point/Sequential Reconstruction
Oct 24, 2023



Time series anomaly detection is challenging due to the complexity and variety of patterns that can occur. One major difficulty arises from modeling time-dependent relationships to find contextual anomalies while maintaining detection accuracy for point anomalies. In this paper, we propose a framework for unsupervised time series anomaly detection that utilizes point-based and sequence-based reconstruction models. The point-based model attempts to quantify point anomalies, and the sequence-based model attempts to quantify both point and contextual anomalies. Under the formulation that the observed time point is a two-stage deviated value from a nominal time point, we introduce a nominality score calculated from the ratio of a combined value of the reconstruction errors. We derive an induced anomaly score by further integrating the nominality score and anomaly score, then theoretically prove the superiority of the induced anomaly score over the original anomaly score under certain conditions. Extensive studies conducted on several public datasets show that the proposed framework outperforms most state-of-the-art baselines for time series anomaly detection.
KirchhoffNet: A Circuit Bridging Message Passing and Continuous-Depth Models
Oct 24, 2023In this paper, we exploit a fundamental principle of analog electronic circuitry, Kirchhoff's current law, to introduce a unique class of neural network models that we refer to as KirchhoffNet. KirchhoffNet establishes close connections with message passing neural networks and continuous-depth networks. We demonstrate that even in the absence of any traditional layers (such as convolution, pooling, or linear layers), KirchhoffNet attains 98.86% test accuracy on the MNIST dataset, comparable with state of the art (SOTA) results. What makes KirchhoffNet more intriguing is its potential in the realm of hardware. Contemporary deep neural networks are conventionally deployed on GPUs. In contrast, KirchhoffNet can be physically realized by an analog electronic circuit. Moreover, we justify that irrespective of the number of parameters within a KirchhoffNet, its forward calculation can always be completed within 1/f seconds, with f representing the hardware's clock frequency. This characteristic introduces a promising technology for implementing ultra-large-scale neural networks.
NeurOLight: A Physics-Agnostic Neural Operator Enabling Parametric Photonic Device Simulation
Sep 19, 2022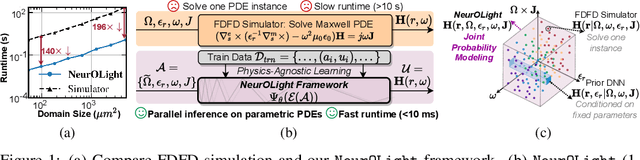
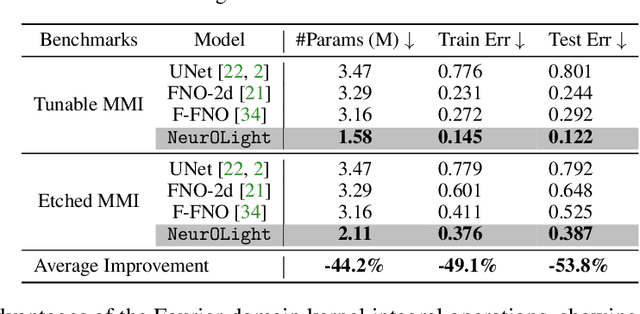
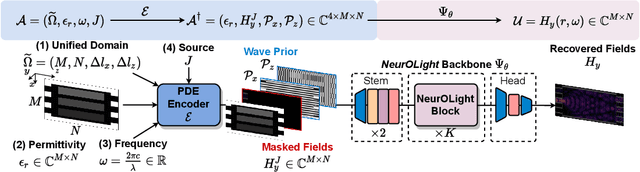
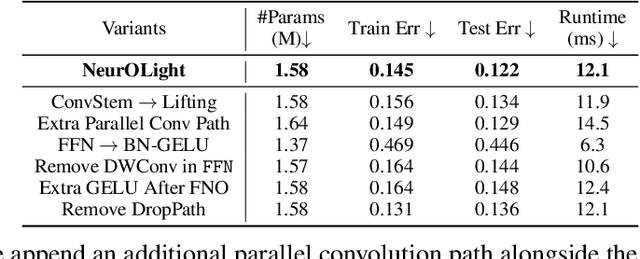
Optical computing is an emerging technology for next-generation efficient artificial intelligence (AI) due to its ultra-high speed and efficiency. Electromagnetic field simulation is critical to the design, optimization, and validation of photonic devices and circuits. However, costly numerical simulation significantly hinders the scalability and turn-around time in the photonic circuit design loop. Recently, physics-informed neural networks have been proposed to predict the optical field solution of a single instance of a partial differential equation (PDE) with predefined parameters. Their complicated PDE formulation and lack of efficient parametrization mechanisms limit their flexibility and generalization in practical simulation scenarios. In this work, for the first time, a physics-agnostic neural operator-based framework, dubbed NeurOLight, is proposed to learn a family of frequency-domain Maxwell PDEs for ultra-fast parametric photonic device simulation. We balance the efficiency and generalization of NeurOLight via several novel techniques. Specifically, we discretize different devices into a unified domain, represent parametric PDEs with a compact wave prior, and encode the incident light via masked source modeling. We design our model with parameter-efficient cross-shaped NeurOLight blocks and adopt superposition-based augmentation for data-efficient learning. With these synergistic approaches, NeurOLight generalizes to a large space of unseen simulation settings, demonstrates 2-orders-of-magnitude faster simulation speed than numerical solvers, and outperforms prior neural network models by ~54% lower prediction error with ~44% fewer parameters. Our code is available at https://github.com/JeremieMelo/NeurOLight.