 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Minimal Effective Theory for Phonotactic Memory: Capturing Local Correlations due to Errors in Speech
Sep 04, 2023
Spoken language evolves constrained by the economy of speech, which depends on factors such as the structure of the human mouth. This gives rise to local phonetic correlations in spoken words. Here we demonstrate that these local correlations facilitate the learning of spoken words by reducing their information content. We do this by constructing a locally-connected tensor-network model, inspired by similar variational models used for many-body physics, which exploits these local phonetic correlations to facilitate the learning of spoken words. The model is therefore a minimal model of phonetic memory, where "learning to pronounce" and "learning a word" are one and the same. A consequence of which is the learned ability to produce new words which are phonetically reasonable for the target language; as well as providing a hierarchy of the most likely errors that could be produced during the action of speech. We test our model against Latin and Turkish words. (The code is available on GitHub.)
USA: Universal Sentiment Analysis Model & Construction of Japanese Sentiment Text Classification and Part of Speech Dataset
Sep 07, 2023

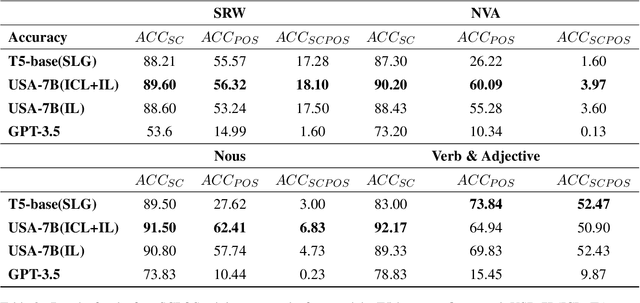
Sentiment analysis is a pivotal task in the domain of natural language processing. It encompasses both text-level sentiment polarity classification and word-level Part of Speech(POS) sentiment polarity determination. Such analysis challenges models to understand text holistically while also extracting nuanced information. With the rise of Large Language Models(LLMs), new avenues for sentiment analysis have opened. This paper proposes enhancing performance by leveraging the Mutual Reinforcement Effect(MRE) between individual words and the overall text. It delves into how word polarity influences the overarching sentiment of a passage. To support our research, we annotated four novel Sentiment Text Classification and Part of Speech(SCPOS) datasets, building upon existing sentiment classification datasets. Furthermore, we developed a Universal Sentiment Analysis(USA) model, with a 7-billion parameter size. Experimental results revealed that our model surpassed the performance of gpt-3.5-turbo across all four datasets, underscoring the significance of MRE in sentiment analysis.
LaughTalk: Expressive 3D Talking Head Generation with Laughter
Nov 02, 2023
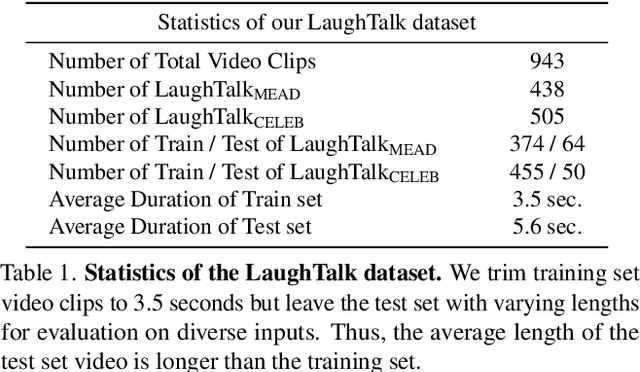

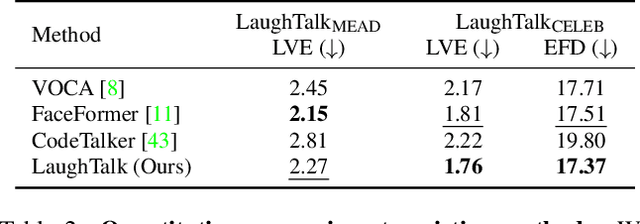
Laughter is a unique expression, essential to affirmative social interactions of humans. Although current 3D talking head generation methods produce convincing verbal articulations, they often fail to capture the vitality and subtleties of laughter and smiles despite their importance in social context. In this paper, we introduce a novel task to generate 3D talking heads capable of both articulate speech and authentic laughter. Our newly curated dataset comprises 2D laughing videos paired with pseudo-annotated and human-validated 3D FLAME parameters and vertices. Given our proposed dataset, we present a strong baseline with a two-stage training scheme: the model first learns to talk and then acquires the ability to express laughter. Extensive experiments demonstrate that our method performs favorably compared to existing approaches in both talking head generation and expressing laughter signals. We further explore potential applications on top of our proposed method for rigging realistic avatars.
Ontology Learning Using Formal Concept Analysis and WordNet
Nov 10, 2023Manual ontology construction takes time, resources, and domain specialists. Supporting a component of this process for automation or semi-automation would be good. This project and dissertation provide a Formal Concept Analysis and WordNet framework for learning concept hierarchies from free texts. The process has steps. First, the document is Part-Of-Speech labeled, then parsed to produce sentence parse trees. Verb/noun dependencies are derived from parse trees next. After lemmatizing, pruning, and filtering the word pairings, the formal context is created. The formal context may contain some erroneous and uninteresting pairs because the parser output may be erroneous, not all derived pairs are interesting, and it may be large due to constructing it from a large free text corpus. Deriving lattice from the formal context may take longer, depending on the size and complexity of the data. Thus, decreasing formal context may eliminate erroneous and uninteresting pairs and speed up idea lattice derivation. WordNet-based and Frequency-based approaches are tested. Finally, we compute formal idea lattice and create a classical concept hierarchy. The reduced concept lattice is compared to the original to evaluate the outcomes. Despite several system constraints and component discrepancies that may prevent logical conclusion, the following data imply idea hierarchies in this project and dissertation are promising. First, the reduced idea lattice and original concept have commonalities. Second, alternative language or statistical methods can reduce formal context size. Finally, WordNet-based and Frequency-based approaches reduce formal context differently, and the order of applying them is examined to reduce context efficiently.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023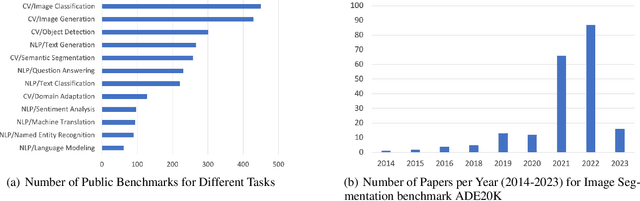
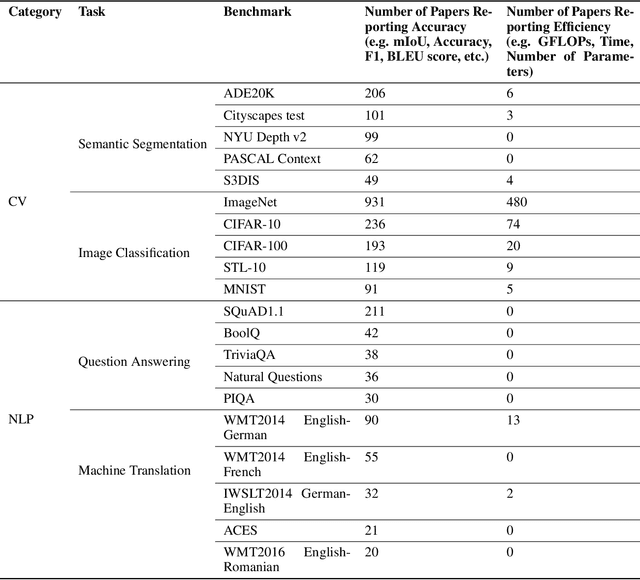
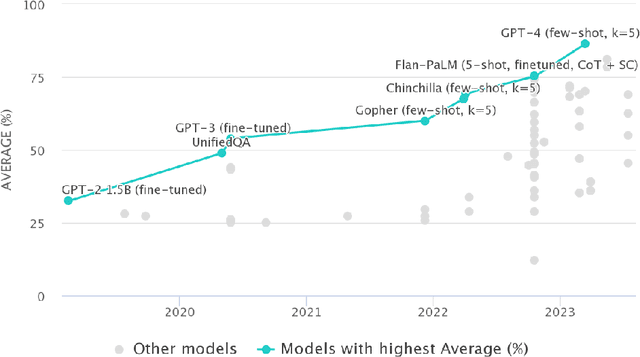
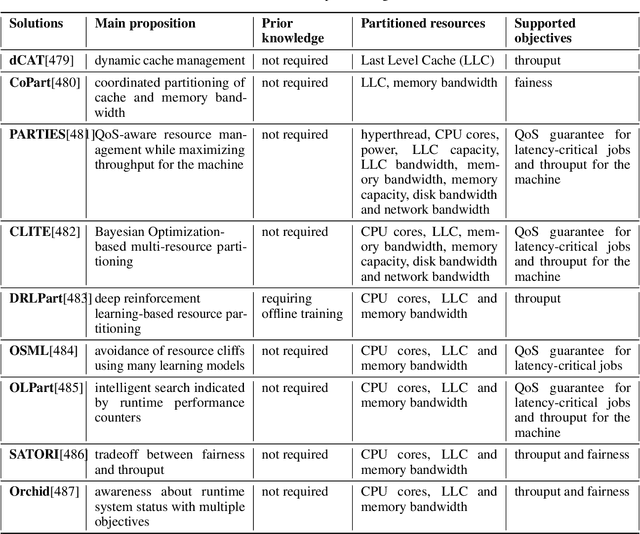
Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Acoustic-to-articulatory inversion for dysarthric speech: Are pre-trained self-supervised representations favorable?
Sep 07, 2023$ $Acoustic-to-articulatory inversion (AAI) involves mapping from the acoustic space to the articulatory space. Signal-processing features like the MFCCs, have been widely used for the AAI task. For subjects with dysarthric speech, AAI is challenging because of an imprecise and indistinct pronunciation. In this work, we perform AAI for dysarthric speech using representations from pre-trained self-supervised learning (SSL) models. We demonstrate the impact of different pre-trained features on this challenging AAI task, at low-resource conditions. In addition, we also condition x-vectors to the extracted SSL features to train a BLSTM network. In the seen case, we experiment with three AAI training schemes (subject-specific, pooled, and fine-tuned). The results, consistent across training schemes, reveal that DeCoAR, in the fine-tuned scheme, achieves a relative improvement of the Pearson Correlation Coefficient (CC) by ${\sim}$1.81\% and ${\sim}$4.56\% for healthy controls and patients, respectively, over MFCCs. In the unseen case, we observe similar average trends for different SSL features. Overall, SSL networks like wav2vec, APC, and DeCoAR, which are trained with feature reconstruction or future timestep prediction tasks, perform well in predicting dysarthric articulatory trajectories.
Sounding Bodies: Modeling 3D Spatial Sound of Humans Using Body Pose and Audio
Nov 01, 2023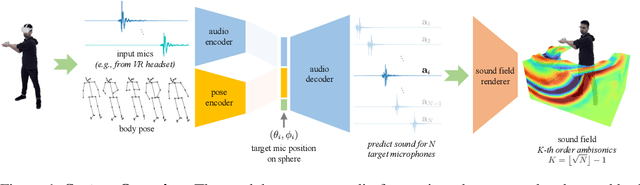

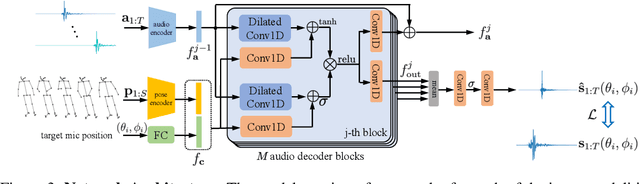
While 3D human body modeling has received much attention in computer vision, modeling the acoustic equivalent, i.e. modeling 3D spatial audio produced by body motion and speech, has fallen short in the community. To close this gap, we present a model that can generate accurate 3D spatial audio for full human bodies. The system consumes, as input, audio signals from headset microphones and body pose, and produces, as output, a 3D sound field surrounding the transmitter's body, from which spatial audio can be rendered at any arbitrary position in the 3D space. We collect a first-of-its-kind multimodal dataset of human bodies, recorded with multiple cameras and a spherical array of 345 microphones. In an empirical evaluation, we demonstrate that our model can produce accurate body-induced sound fields when trained with a suitable loss. Dataset and code are available online.
Leveraging Data Collection and Unsupervised Learning for Code-switched Tunisian Arabic Automatic Speech Recognition
Sep 20, 2023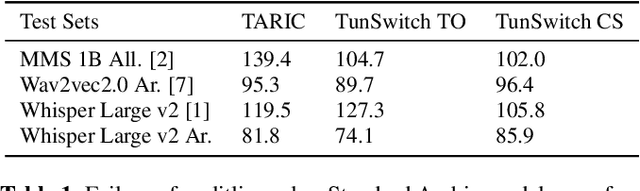
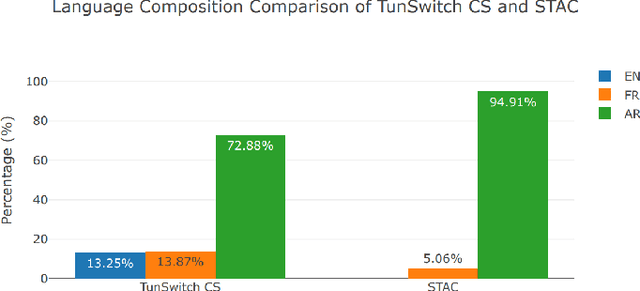

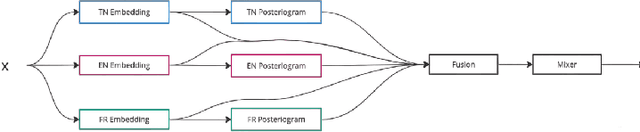
Crafting an effective Automatic Speech Recognition (ASR) solution for dialects demands innovative approaches that not only address the data scarcity issue but also navigate the intricacies of linguistic diversity. In this paper, we address the aforementioned ASR challenge, focusing on the Tunisian dialect. First, textual and audio data is collected and in some cases annotated. Second, we explore self-supervision, semi-supervision and few-shot code-switching approaches to push the state-of-the-art on different Tunisian test sets; covering different acoustic, linguistic and prosodic conditions. Finally, and given the absence of conventional spelling, we produce a human evaluation of our transcripts to avoid the noise coming from spelling inadequacies in our testing references. Our models, allowing to transcribe audio samples in a linguistic mix involving Tunisian Arabic, English and French, and all the data used during training and testing are released for public use and further improvements.
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Sep 29, 2023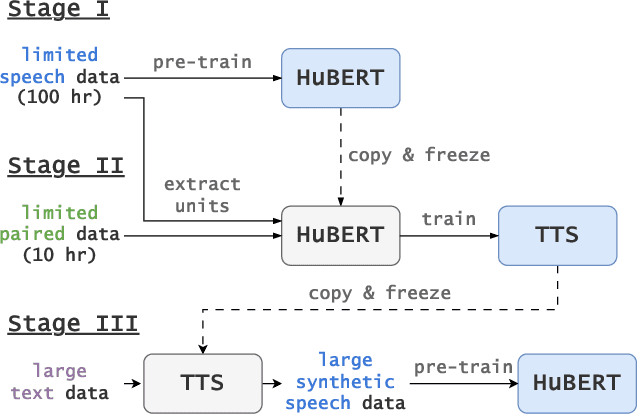

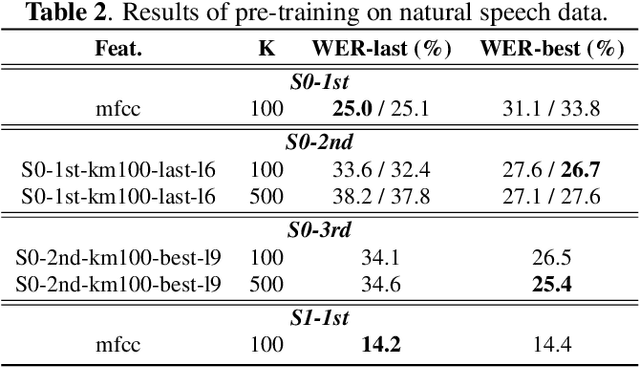
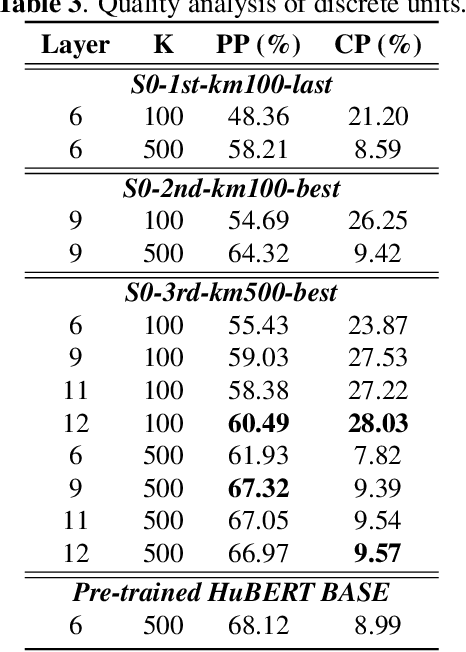
Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90\% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
LocSelect: Target Speaker Localization with an Auditory Selective Hearing Mechanism
Oct 17, 2023The prevailing noise-resistant and reverberation-resistant localization algorithms primarily emphasize separating and providing directional output for each speaker in multi-speaker scenarios, without association with the identity of speakers. In this paper, we present a target speaker localization algorithm with a selective hearing mechanism. Given a reference speech of the target speaker, we first produce a speaker-dependent spectrogram mask to eliminate interfering speakers' speech. Subsequently, a Long short-term memory (LSTM) network is employed to extract the target speaker's location from the filtered spectrogram. Experiments validate the superiority of our proposed method over the existing algorithms for different scale invariant signal-to-noise ratios (SNR) conditions. Specifically, at SNR = -10 dB, our proposed network LocSelect achieves a mean absolute error (MAE) of 3.55 and an accuracy (ACC) of 87.40%.