 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Appearance Prediction for 3D Gaussian Avatars
Apr 01, 2026A photorealistic and immersive human avatar experience demands capturing fine, person-specific details such as cloth and hair dynamics, subtle facial expressions, and characteristic motion patterns. Achieving this requires large, high-quality datasets, which often introduce ambiguities and spurious correlations when very similar poses correspond to different appearances. Models that fit these details during training can overfit and produce unstable, abrupt appearance changes for novel poses. We propose a 3D Gaussian Splatting avatar model with a spatial MLP backbone that is conditioned on both pose and an appearance latent. The latent is learned during training by an encoder, yielding a compact representation that improves reconstruction quality and helps disambiguate pose-driven renderings. At driving time, our predictor autoregressively infers the latent, producing temporally smooth appearance evolution and improved stability. Overall, our method delivers a robust and practical path to high-fidelity, stable avatar driving.
Combining Microscopy Data and Metadata for Reconstruction of Cellular Traction Forces Using a Hybrid Vision Transformer-U-Net
Mar 11, 2026Traction force microscopy (TFM) is a widely used technique for quantifying the forces that cells exert on their surrounding extracellular matrix. Although deep learning methods have recently been applied to TFM data analysis, several challenges remain-particularly achieving reliable inference across multiple spatial scales and integrating additional contextual information such as cell type to improve accuracy. In this study, we propose ViT+UNet, a robust deep learning architecture that integrates a U-Net with a Vision Transformer. Our results demonstrate that this hybrid model outperforms both standalone U-Net and Vision Transformer architectures in predicting traction force fields. Furthermore, ViT+UNet exhibits superior generalization across diverse spatial scales and varying noise levels, enabling its application to TFM datasets obtained from different experimental setups and imaging systems. By appropriately structuring the input data, our approach also allows the inclusion of metadata, in our case cell-type information, to enhance prediction specificity and accuracy.
DuoMo: Dual Motion Diffusion for World-Space Human Reconstruction
Mar 03, 2026We present DuoMo, a generative method that recovers human motion in world-space coordinates from unconstrained videos with noisy or incomplete observations. Reconstructing such motion requires solving a fundamental trade-off: generalizing from diverse and noisy video inputs while maintaining global motion consistency. Our approach addresses this problem by factorizing motion learning into two diffusion models. The camera-space model first estimates motion from videos in camera coordinates. The world-space model then lifts this initial estimate into world coordinates and refines it to be globally consistent. Together, the two models can reconstruct motion across diverse scenes and trajectories, even from highly noisy or incomplete observations. Moreover, our formulation is general, generating the motion of mesh vertices directly and bypassing parametric models. DuoMo achieves state-of-the-art performance. On EMDB, our method obtains a 16% reduction in world-space reconstruction error while maintaining low foot skating. On RICH, it obtains a 30% reduction in world-space error. Project page: https://yufu-wang.github.io/duomo/
BinauralFlow: A Causal and Streamable Approach for High-Quality Binaural Speech Synthesis with Flow Matching Models
May 28, 2025



Binaural rendering aims to synthesize binaural audio that mimics natural hearing based on a mono audio and the locations of the speaker and listener. Although many methods have been proposed to solve this problem, they struggle with rendering quality and streamable inference. Synthesizing high-quality binaural audio that is indistinguishable from real-world recordings requires precise modeling of binaural cues, room reverb, and ambient sounds. Additionally, real-world applications demand streaming inference. To address these challenges, we propose a flow matching based streaming binaural speech synthesis framework called BinauralFlow. We consider binaural rendering to be a generation problem rather than a regression problem and design a conditional flow matching model to render high-quality audio. Moreover, we design a causal U-Net architecture that estimates the current audio frame solely based on past information to tailor generative models for streaming inference. Finally, we introduce a continuous inference pipeline incorporating streaming STFT/ISTFT operations, a buffer bank, a midpoint solver, and an early skip schedule to improve rendering continuity and speed. Quantitative and qualitative evaluations demonstrate the superiority of our method over SOTA approaches. A perceptual study further reveals that our model is nearly indistinguishable from real-world recordings, with a $42\%$ confusion rate.
REWIND: Real-Time Egocentric Whole-Body Motion Diffusion with Exemplar-Based Identity Conditioning
Apr 08, 2025We present REWIND (Real-Time Egocentric Whole-Body Motion Diffusion), a one-step diffusion model for real-time, high-fidelity human motion estimation from egocentric image inputs. While an existing method for egocentric whole-body (i.e., body and hands) motion estimation is non-real-time and acausal due to diffusion-based iterative motion refinement to capture correlations between body and hand poses, REWIND operates in a fully causal and real-time manner. To enable real-time inference, we introduce (1) cascaded body-hand denoising diffusion, which effectively models the correlation between egocentric body and hand motions in a fast, feed-forward manner, and (2) diffusion distillation, which enables high-quality motion estimation with a single denoising step. Our denoising diffusion model is based on a modified Transformer architecture, designed to causally model output motions while enhancing generalizability to unseen motion lengths. Additionally, REWIND optionally supports identity-conditioned motion estimation when identity prior is available. To this end, we propose a novel identity conditioning method based on a small set of pose exemplars of the target identity, which further enhances motion estimation quality. Through extensive experiments, we demonstrate that REWIND significantly outperforms the existing baselines both with and without exemplar-based identity conditioning.
SoundVista: Novel-View Ambient Sound Synthesis via Visual-Acoustic Binding
Apr 08, 2025



We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
FlowDec: A flow-based full-band general audio codec with high perceptual quality
Mar 03, 2025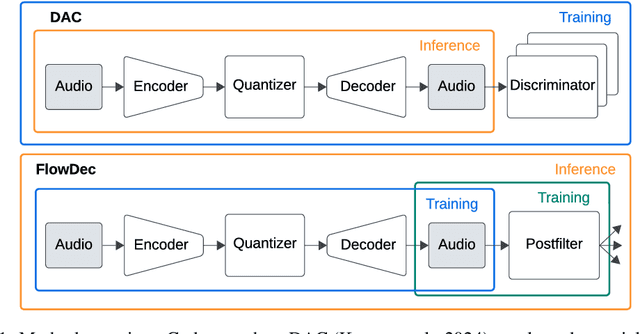
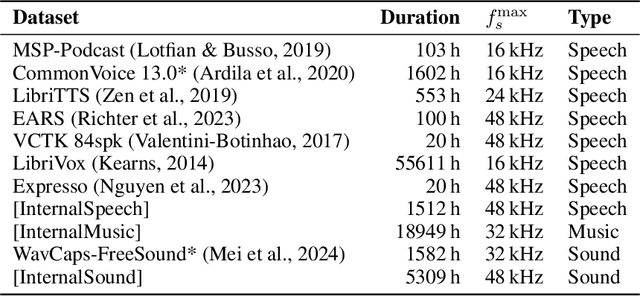

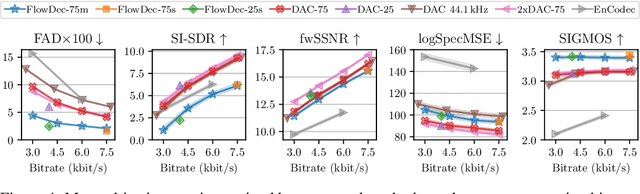
We propose FlowDec, a neural full-band audio codec for general audio sampled at 48 kHz that combines non-adversarial codec training with a stochastic postfilter based on a novel conditional flow matching method. Compared to the prior work ScoreDec which is based on score matching, we generalize from speech to general audio and move from 24 kbit/s to as low as 4 kbit/s, while improving output quality and reducing the required postfilter DNN evaluations from 60 to 6 without any fine-tuning or distillation techniques. We provide theoretical insights and geometric intuitions for our approach in comparison to ScoreDec as well as another recent work that uses flow matching, and conduct ablation studies on our proposed components. We show that FlowDec is a competitive alternative to the recent GAN-dominated stream of neural codecs, achieving FAD scores better than those of the established GAN-based codec DAC and listening test scores that are on par, and producing qualitatively more natural reconstructions for speech and harmonic structures in music.
AV-Flow: Transforming Text to Audio-Visual Human-like Interactions
Feb 18, 2025We introduce AV-Flow, an audio-visual generative model that animates photo-realistic 4D talking avatars given only text input. In contrast to prior work that assumes an existing speech signal, we synthesize speech and vision jointly. We demonstrate human-like speech synthesis, synchronized lip motion, lively facial expressions and head pose; all generated from just text characters. The core premise of our approach lies in the architecture of our two parallel diffusion transformers. Intermediate highway connections ensure communication between the audio and visual modalities, and thus, synchronized speech intonation and facial dynamics (e.g., eyebrow motion). Our model is trained with flow matching, leading to expressive results and fast inference. In case of dyadic conversations, AV-Flow produces an always-on avatar, that actively listens and reacts to the audio-visual input of a user. Through extensive experiments, we show that our method outperforms prior work, synthesizing natural-looking 4D talking avatars. Project page: https://aggelinacha.github.io/AV-Flow/
ComplexDec: A Domain-robust High-fidelity Neural Audio Codec with Complex Spectrum Modeling
Feb 04, 2025



Neural audio codecs have been widely adopted in audio-generative tasks because their compact and discrete representations are suitable for both large-language-model-style and regression-based generative models. However, most neural codecs struggle to model out-of-domain audio, resulting in error propagations to downstream generative tasks. In this paper, we first argue that information loss from codec compression degrades out-of-domain robustness. Then, we propose full-band 48~kHz ComplexDec with complex spectral input and output to ease the information loss while adopting the same 24~kbps bitrate as the baseline AuidoDec and ScoreDec. Objective and subjective evaluations demonstrate the out-of-domain robustness of ComplexDec trained using only the 30-hour VCTK corpus.
Modeling and Driving Human Body Soundfields through Acoustic Primitives
Jul 18, 2024While rendering and animation of photorealistic 3D human body models have matured and reached an impressive quality over the past years, modeling the spatial audio associated with such full body models has been largely ignored so far. In this work, we present a framework that allows for high-quality spatial audio generation, capable of rendering the full 3D soundfield generated by a human body, including speech, footsteps, hand-body interactions, and others. Given a basic audio-visual representation of the body in form of 3D body pose and audio from a head-mounted microphone, we demonstrate that we can render the full acoustic scene at any point in 3D space efficiently and accurately. To enable near-field and realtime rendering of sound, we borrow the idea of volumetric primitives from graphical neural rendering and transfer them into the acoustic domain. Our acoustic primitives result in an order of magnitude smaller soundfield representations and overcome deficiencies in near-field rendering compared to previous approaches.