 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Incremental Learning For Sound Source Localization With Imbalance Rectification
Jan 26, 2026Sound source localization (SSL) demonstrates remarkable results in controlled settings but struggles in real-world deployment due to dual imbalance challenges: intra-task imbalance arising from long-tailed direction-of-arrival (DoA) distributions, and inter-task imbalance induced by cross-task skews and overlaps. These often lead to catastrophic forgetting, significantly degrading the localization accuracy. To mitigate these issues, we propose a unified framework with two key innovations. Specifically, we design a GCC-PHAT-based data augmentation (GDA) method that leverages peak characteristics to alleviate intra-task distribution skews. We also propose an Analytic dynamic imbalance rectifier (ADIR) with task-adaption regularization, which enables analytic updates that adapt to inter-task dynamics. On the SSLR benchmark, our proposal achieves state-of-the-art (SoTA) results of 89.0% accuracy, 5.3° mean absolute error, and 1.6 backward transfer, demonstrating robustness to evolving imbalances without exemplar storage.
VP-SelDoA: Visual-prompted Selective DoA Estimation of Target Sound via Semantic-Spatial Matching
Jul 10, 2025Audio-visual sound source localization (AV-SSL) identifies the position of a sound source by exploiting the complementary strengths of auditory and visual signals. However, existing AV-SSL methods encounter three major challenges: 1) inability to selectively isolate the target sound source in multi-source scenarios, 2) misalignment between semantic visual features and spatial acoustic features, and 3) overreliance on paired audio-visual data. To overcome these limitations, we introduce Cross-Instance Audio-Visual Localization (CI-AVL), a novel task that leverages images from different instances of the same sound event category to localize target sound sources, thereby reducing dependence on paired data while enhancing generalization capabilities. Our proposed VP-SelDoA tackles this challenging task through a semantic-level modality fusion and employs a Frequency-Temporal ConMamba architecture to generate target-selective masks for sound isolation. We further develop a Semantic-Spatial Matching mechanism that aligns the heterogeneous semantic and spatial features via integrated cross- and self-attention mechanisms. To facilitate the CI-AVL research, we construct a large-scale dataset named VGG-SSL, comprising 13,981 spatial audio clips across 296 sound event categories. Extensive experiments show that our proposed method outperforms state-of-the-art audio-visual localization methods, achieving a mean absolute error (MAE) of 12.04 and an accuracy (ACC) of 78.23%.
LocSelect: Target Speaker Localization with an Auditory Selective Hearing Mechanism
Oct 17, 2023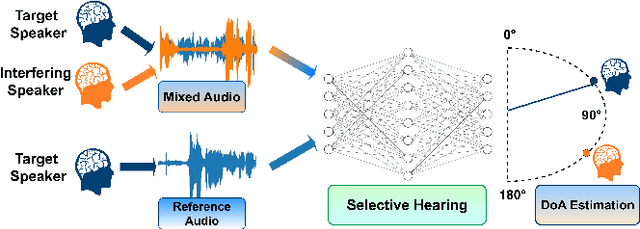
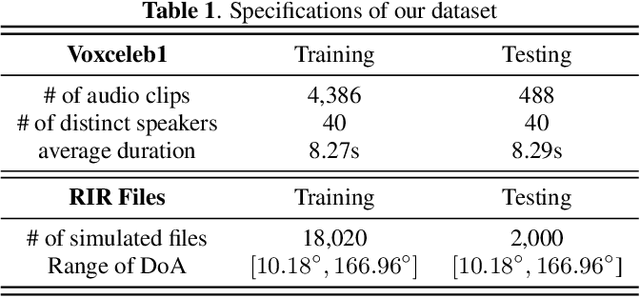
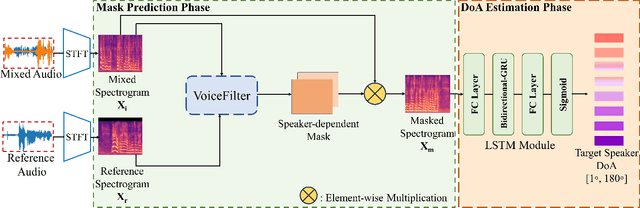
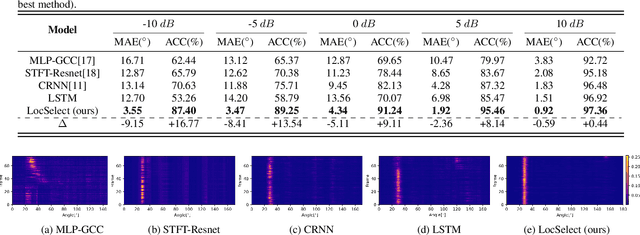
The prevailing noise-resistant and reverberation-resistant localization algorithms primarily emphasize separating and providing directional output for each speaker in multi-speaker scenarios, without association with the identity of speakers. In this paper, we present a target speaker localization algorithm with a selective hearing mechanism. Given a reference speech of the target speaker, we first produce a speaker-dependent spectrogram mask to eliminate interfering speakers' speech. Subsequently, a Long short-term memory (LSTM) network is employed to extract the target speaker's location from the filtered spectrogram. Experiments validate the superiority of our proposed method over the existing algorithms for different scale invariant signal-to-noise ratios (SNR) conditions. Specifically, at SNR = -10 dB, our proposed network LocSelect achieves a mean absolute error (MAE) of 3.55 and an accuracy (ACC) of 87.40%.