 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE-Next: Teaching Large Language Models to Detect, Classify, and Reason about Laughter
May 27, 2026Laughter is a complex social signal that conveys communicative intent beyond amusement. While prior work has focused on isolated laughter analysis tasks, a comprehensive understanding of laughter in real-world scenarios remains underexplored. Therefore, we introduce SMILE-Next, a dataset for real-world laughter understanding with multimodal textual representations and question-answer annotations across three tasks: laughter detection, laughter type classification, and laughter reasoning. Building upon SMILE-Next, we aim to develop a laughter-specialized large language model capable of nuanced understanding of laughter in real-world contexts. To this end, we propose two key components: laughter-specific Self-Instruct and the Mixture-of-Laugh-Experts (MoLE) framework. Laughter-specific Self-Instruct enhances generalization across tasks and domains by automatically synthesizing diverse laughter-centric instructions. MoLE introduces a task-adaptive expert routing mechanism that dynamically selects specialized experts tailored to each laughter-related task, improving task-specific performance and efficiency. Experimental results show that the combination of our proposed components substantially outperforms multimodal LLM baselines, advancing robust real-world laughter understanding. Project page is at: https://mok0102.github.io/smile-next/.
FacEDiT: Unified Talking Face Editing and Generation via Facial Motion Infilling
Dec 16, 2025



Talking face editing and face generation have often been studied as distinct problems. In this work, we propose viewing both not as separate tasks but as subtasks of a unifying formulation, speech-conditional facial motion infilling. We explore facial motion infilling as a self-supervised pretext task that also serves as a unifying formulation of dynamic talking face synthesis. To instantiate this idea, we propose FacEDiT, a speech-conditional Diffusion Transformer trained with flow matching. Inspired by masked autoencoders, FacEDiT learns to synthesize masked facial motions conditioned on surrounding motions and speech. This formulation enables both localized generation and edits, such as substitution, insertion, and deletion, while ensuring seamless transitions with unedited regions. In addition, biased attention and temporal smoothness constraints enhance boundary continuity and lip synchronization. To address the lack of a standard editing benchmark, we introduce FacEDiTBench, the first dataset for talking face editing, featuring diverse edit types and lengths, along with new evaluation metrics. Extensive experiments validate that talking face editing and generation emerge as subtasks of speech-conditional motion infilling; FacEDiT produces accurate, speech-aligned facial edits with strong identity preservation and smooth visual continuity while generalizing effectively to talking face generation.
AlignDiT: Multimodal Aligned Diffusion Transformer for Synchronized Speech Generation
Apr 29, 2025In this paper, we address the task of multimodal-to-speech generation, which aims to synthesize high-quality speech from multiple input modalities: text, video, and reference audio. This task has gained increasing attention due to its wide range of applications, such as film production, dubbing, and virtual avatars. Despite recent progress, existing methods still suffer from limitations in speech intelligibility, audio-video synchronization, speech naturalness, and voice similarity to the reference speaker. To address these challenges, we propose AlignDiT, a multimodal Aligned Diffusion Transformer that generates accurate, synchronized, and natural-sounding speech from aligned multimodal inputs. Built upon the in-context learning capability of the DiT architecture, AlignDiT explores three effective strategies to align multimodal representations. Furthermore, we introduce a novel multimodal classifier-free guidance mechanism that allows the model to adaptively balance information from each modality during speech synthesis. Extensive experiments demonstrate that AlignDiT significantly outperforms existing methods across multiple benchmarks in terms of quality, synchronization, and speaker similarity. Moreover, AlignDiT exhibits strong generalization capability across various multimodal tasks, such as video-to-speech synthesis and visual forced alignment, consistently achieving state-of-the-art performance. The demo page is available at https://mm.kaist.ac.kr/projects/AlignDiT .
VoiceCraft-Dub: Automated Video Dubbing with Neural Codec Language Models
Apr 03, 2025We present VoiceCraft-Dub, a novel approach for automated video dubbing that synthesizes high-quality speech from text and facial cues. This task has broad applications in filmmaking, multimedia creation, and assisting voice-impaired individuals. Building on the success of Neural Codec Language Models (NCLMs) for speech synthesis, our method extends their capabilities by incorporating video features, ensuring that synthesized speech is time-synchronized and expressively aligned with facial movements while preserving natural prosody. To inject visual cues, we design adapters to align facial features with the NCLM token space and introduce audio-visual fusion layers to merge audio-visual information within the NCLM framework. Additionally, we curate CelebV-Dub, a new dataset of expressive, real-world videos specifically designed for automated video dubbing. Extensive experiments show that our model achieves high-quality, intelligible, and natural speech synthesis with accurate lip synchronization, outperforming existing methods in human perception and performing favorably in objective evaluations. We also adapt VoiceCraft-Dub for the video-to-speech task, demonstrating its versatility for various applications.
Perceptually Accurate 3D Talking Head Generation: New Definitions, Speech-Mesh Representation, and Evaluation Metrics
Mar 27, 2025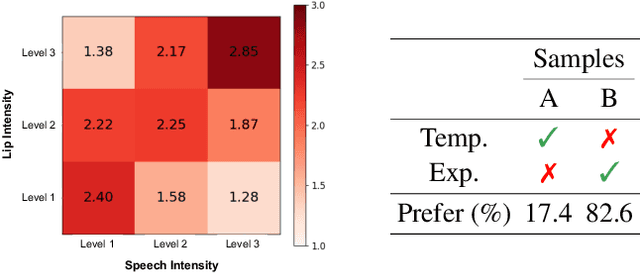
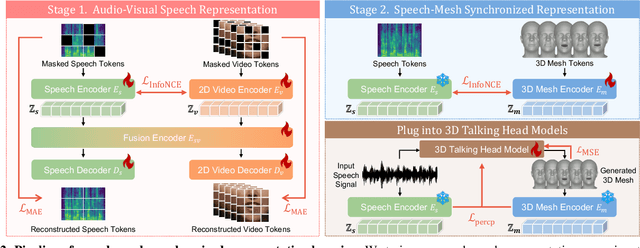
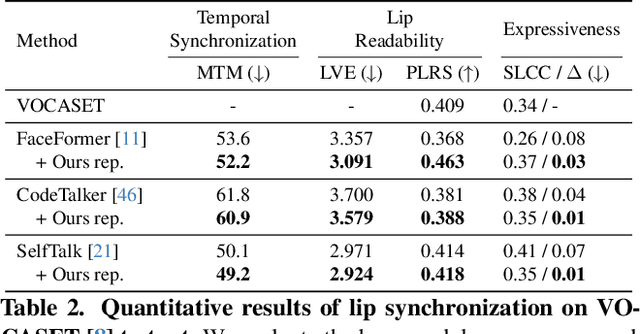
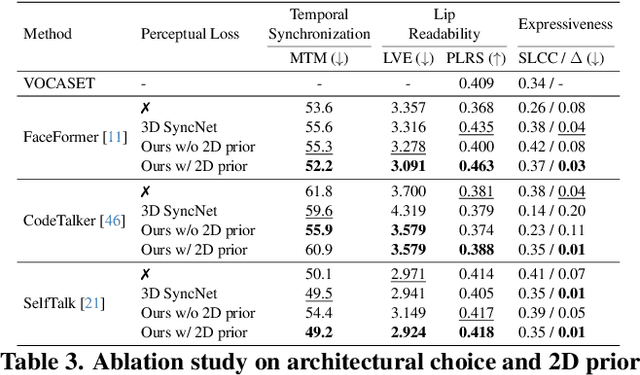
Recent advancements in speech-driven 3D talking head generation have made significant progress in lip synchronization. However, existing models still struggle to capture the perceptual alignment between varying speech characteristics and corresponding lip movements. In this work, we claim that three criteria -- Temporal Synchronization, Lip Readability, and Expressiveness -- are crucial for achieving perceptually accurate lip movements. Motivated by our hypothesis that a desirable representation space exists to meet these three criteria, we introduce a speech-mesh synchronized representation that captures intricate correspondences between speech signals and 3D face meshes. We found that our learned representation exhibits desirable characteristics, and we plug it into existing models as a perceptual loss to better align lip movements to the given speech. In addition, we utilize this representation as a perceptual metric and introduce two other physically grounded lip synchronization metrics to assess how well the generated 3D talking heads align with these three criteria. Experiments show that training 3D talking head generation models with our perceptual loss significantly improve all three aspects of perceptually accurate lip synchronization. Codes and datasets are available at https://perceptual-3d-talking-head.github.io/.
SoundBrush: Sound as a Brush for Visual Scene Editing
Dec 31, 2024



We propose SoundBrush, a model that uses sound as a brush to edit and manipulate visual scenes. We extend the generative capabilities of the Latent Diffusion Model (LDM) to incorporate audio information for editing visual scenes. Inspired by existing image-editing works, we frame this task as a supervised learning problem and leverage various off-the-shelf models to construct a sound-paired visual scene dataset for training. This richly generated dataset enables SoundBrush to learn to map audio features into the textual space of the LDM, allowing for visual scene editing guided by diverse in-the-wild sound. Unlike existing methods, SoundBrush can accurately manipulate the overall scenery or even insert sounding objects to best match the audio inputs while preserving the original content. Furthermore, by integrating with novel view synthesis techniques, our framework can be extended to edit 3D scenes, facilitating sound-driven 3D scene manipulation. Demos are available at https://soundbrush.github.io/.
Sound2Vision: Generating Diverse Visuals from Audio through Cross-Modal Latent Alignment
Dec 09, 2024



How does audio describe the world around us? In this work, we propose a method for generating images of visual scenes from diverse in-the-wild sounds. This cross-modal generation task is challenging due to the significant information gap between auditory and visual signals. We address this challenge by designing a model that aligns audio-visual modalities by enriching audio features with visual information and translating them into the visual latent space. These features are then fed into the pre-trained image generator to produce images. To enhance image quality, we use sound source localization to select audio-visual pairs with strong cross-modal correlations. Our method achieves substantially better results on the VEGAS and VGGSound datasets compared to previous work and demonstrates control over the generation process through simple manipulations to the input waveform or latent space. Furthermore, we analyze the geometric properties of the learned embedding space and demonstrate that our learning approach effectively aligns audio-visual signals for cross-modal generation. Based on this analysis, we show that our method is agnostic to specific design choices, showing its generalizability by integrating various model architectures and different types of audio-visual data.
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language Models
Oct 23, 2024



Following the success of Large Language Models (LLMs), expanding their boundaries to new modalities represents a significant paradigm shift in multimodal understanding. Human perception is inherently multimodal, relying not only on text but also on auditory and visual cues for a complete understanding of the world. In recognition of this fact, audio-visual LLMs have recently emerged. Despite promising developments, the lack of dedicated benchmarks poses challenges for understanding and evaluating models. In this work, we show that audio-visual LLMs struggle to discern subtle relationships between audio and visual signals, leading to hallucinations, underscoring the need for reliable benchmarks. To address this, we introduce AVHBench, the first comprehensive benchmark specifically designed to evaluate the perception and comprehension capabilities of audio-visual LLMs. Our benchmark includes tests for assessing hallucinations, as well as the cross-modal matching and reasoning abilities of these models. Our results reveal that most existing audio-visual LLMs struggle with hallucinations caused by cross-interactions between modalities, due to their limited capacity to perceive complex multimodal signals and their relationships. Additionally, we demonstrate that simple training with our AVHBench improves robustness of audio-visual LLMs against hallucinations.
Enhancing Speech-Driven 3D Facial Animation with Audio-Visual Guidance from Lip Reading Expert
Jul 01, 2024



Speech-driven 3D facial animation has recently garnered attention due to its cost-effective usability in multimedia production. However, most current advances overlook the intelligibility of lip movements, limiting the realism of facial expressions. In this paper, we introduce a method for speech-driven 3D facial animation to generate accurate lip movements, proposing an audio-visual multimodal perceptual loss. This loss provides guidance to train the speech-driven 3D facial animators to generate plausible lip motions aligned with the spoken transcripts. Furthermore, to incorporate the proposed audio-visual perceptual loss, we devise an audio-visual lip reading expert leveraging its prior knowledge about correlations between speech and lip motions. We validate the effectiveness of our approach through broad experiments, showing noticeable improvements in lip synchronization and lip readability performance. Codes are available at https://3d-talking-head-avguide.github.io/.
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Jun 20, 2024



Recent studies in speech-driven 3D talking head generation have achieved convincing results in verbal articulations. However, generating accurate lip-syncs degrades when applied to input speech in other languages, possibly due to the lack of datasets covering a broad spectrum of facial movements across languages. In this work, we introduce a novel task to generate 3D talking heads from speeches of diverse languages. We collect a new multilingual 2D video dataset comprising over 420 hours of talking videos in 20 languages. With our proposed dataset, we present a multilingually enhanced model that incorporates language-specific style embeddings, enabling it to capture the unique mouth movements associated with each language. Additionally, we present a metric for assessing lip-sync accuracy in multilingual settings. We demonstrate that training a 3D talking head model with our proposed dataset significantly enhances its multilingual performance. Codes and datasets are available at https://multi-talk.github.io/.