 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A comparison of streaming models and data augmentation methods for robust speech recognition
Nov 19, 2021
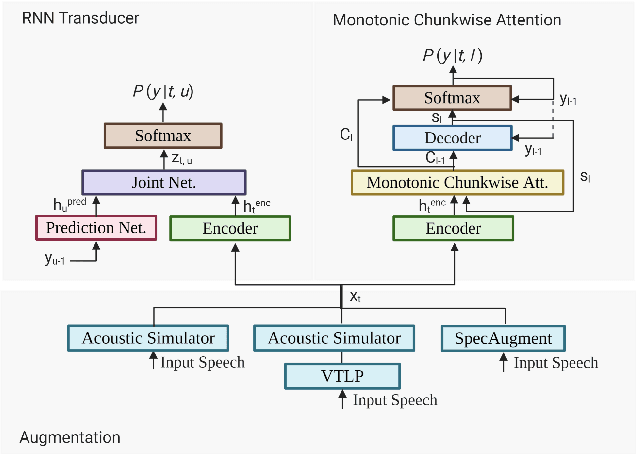

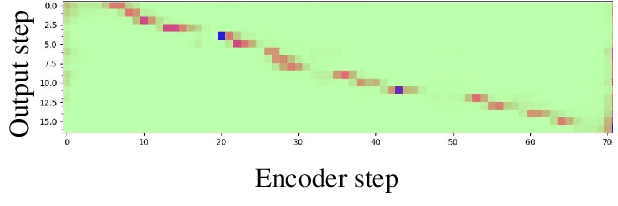

In this paper, we present a comparative study on the robustness of two different online streaming speech recognition models: Monotonic Chunkwise Attention (MoChA) and Recurrent Neural Network-Transducer (RNN-T). We explore three recently proposed data augmentation techniques, namely, multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment. Experimental results show that unidirectional models are in general more sensitive to noisy examples in the training set. It is observed that the final performance of the model depends on the proportion of training examples processed by data augmentation techniques. MoChA models generally perform better than RNN-T models. However, we observe that training of MoChA models seems to be more sensitive to various factors such as the characteristics of training sets and the incorporation of additional augmentations techniques. On the other hand, RNN-T models perform better than MoChA models in terms of latency, inference time, and the stability of training. Additionally, RNN-T models are generally more robust against noise and reverberation. All these advantages make RNN-T models a better choice for streaming on-device speech recognition compared to MoChA models.
Improving Massively Multilingual ASR With Auxiliary CTC Objectives
Feb 27, 2023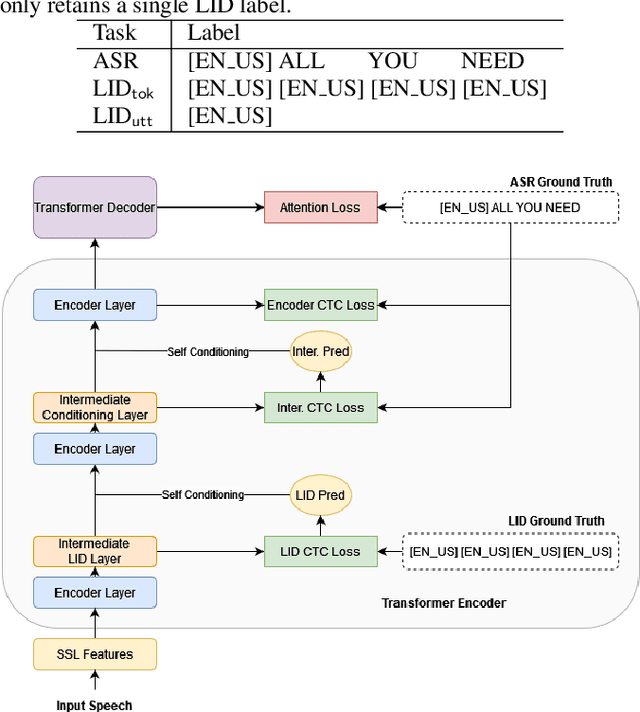
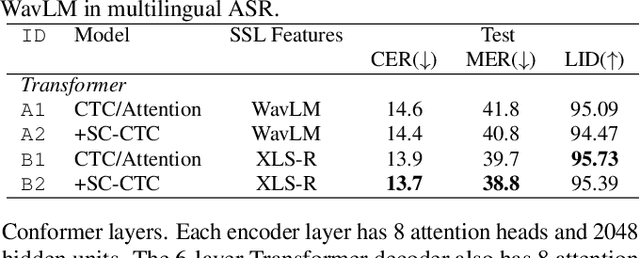
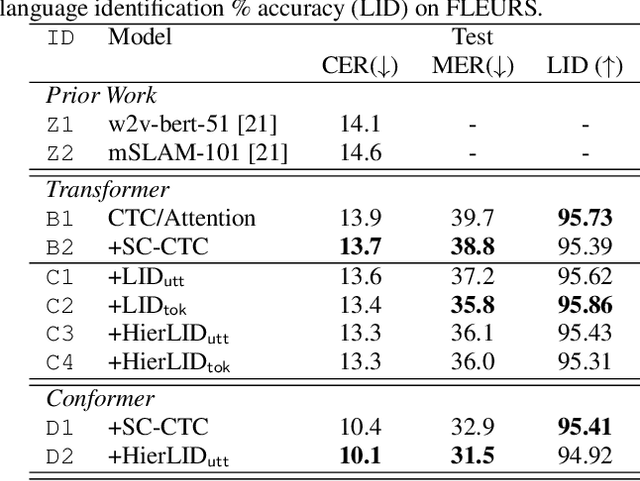
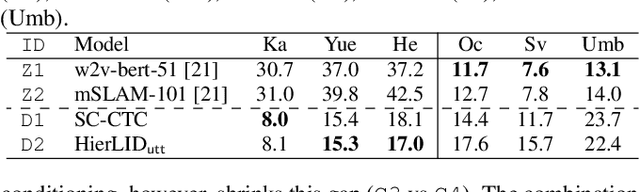
Multilingual Automatic Speech Recognition (ASR) models have extended the usability of speech technologies to a wide variety of languages. With how many languages these models have to handle, however, a key to understanding their imbalanced performance across different languages is to examine if the model actually knows which language it should transcribe. In this paper, we introduce our work on improving performance on FLEURS, a 102-language open ASR benchmark, by conditioning the entire model on language identity (LID). We investigate techniques inspired from recent Connectionist Temporal Classification (CTC) studies to help the model handle the large number of languages, conditioning on the LID predictions of auxiliary tasks. Our experimental results demonstrate the effectiveness of our technique over standard CTC/Attention-based hybrid models. Furthermore, our state-of-the-art systems using self-supervised models with the Conformer architecture improve over the results of prior work on FLEURS by a relative 28.4% CER. Trained models and reproducible recipes are available at https://github.com/espnet/espnet/tree/master/egs2/fleurs/asr1 .
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020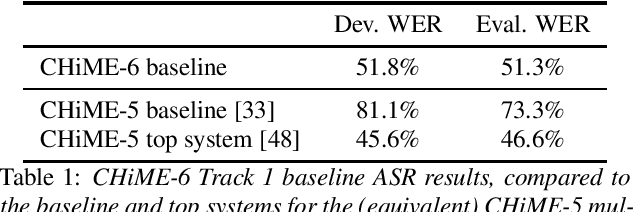

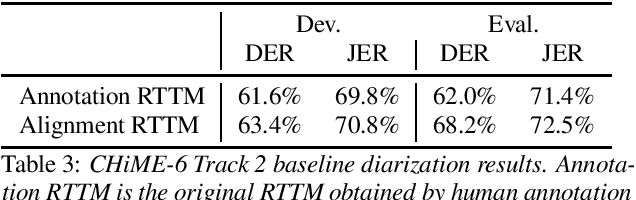

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition
Oct 18, 2021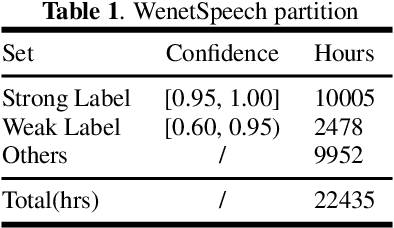

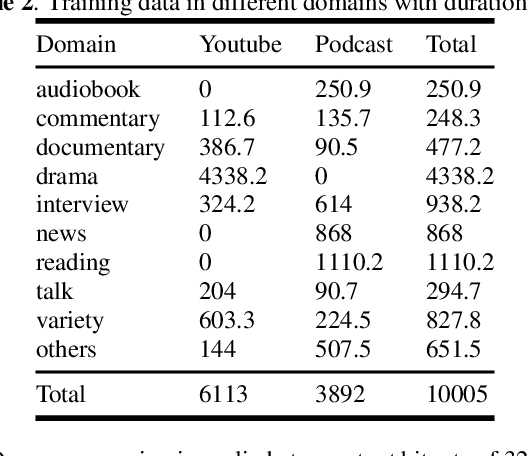
In this paper, we present WenetSpeech, a multi-domain Mandarin corpus consisting of 10000+ hours high-quality labeled speech, 2400+ hours weakly labeled speech, and about 10000 hours unlabeled speech, with 22400+ hours in total. We collect the data from YouTube and Podcast, which covers a variety of speaking styles, scenarios, domains, topics, and noisy conditions. An optical character recognition (OCR) based method is introduced to generate the audio/text segmentation candidates for the YouTube data on its corresponding video captions, while a high-quality ASR transcription system is used to generate audio/text pair candidates for the Podcast data. Then we propose a novel end-to-end label error detection approach to further validate and filter the candidates. We also provide three manually labelled high-quality test sets along with WenetSpeech for evaluation -- Dev for cross-validation purpose in training, Test_Net, collected from Internet for matched test, and Test\_Meeting, recorded from real meetings for more challenging mismatched test. Baseline systems trained with WenetSpeech are provided for three popular speech recognition toolkits, namely Kaldi, ESPnet, and WeNet, and recognition results on the three test sets are also provided as benchmarks. To the best of our knowledge, WenetSpeech is the current largest open-sourced Mandarin speech corpus with transcriptions, which benefits research on production-level speech recognition.
Cascading and Direct Approaches to Unsupervised Constituency Parsing on Spoken Sentences
Mar 15, 2023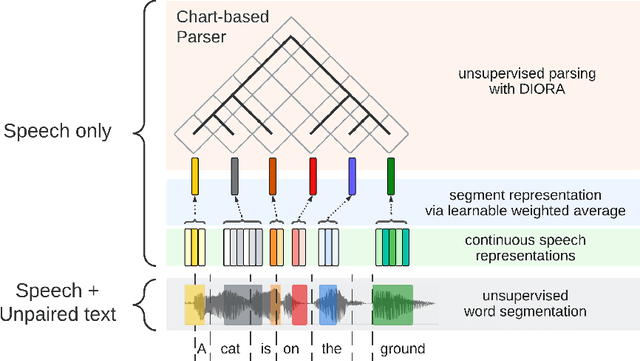
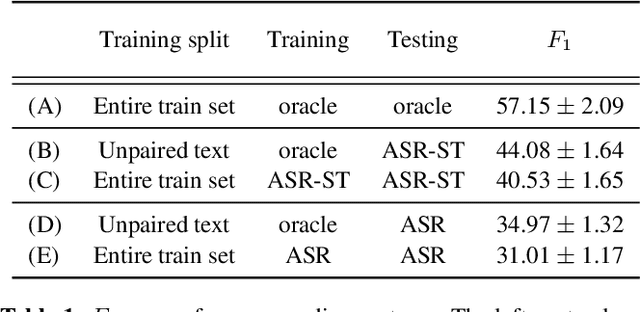
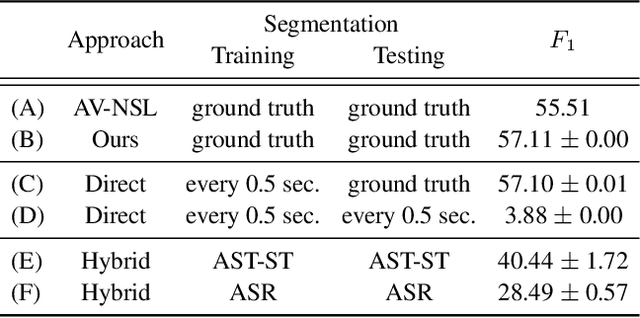
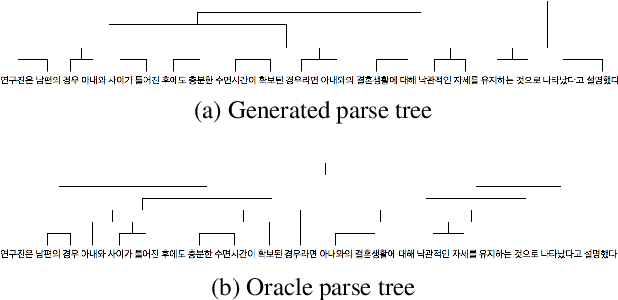
Past work on unsupervised parsing is constrained to written form. In this paper, we present the first study on unsupervised spoken constituency parsing given unlabeled spoken sentences and unpaired textual data. The goal is to determine the spoken sentences' hierarchical syntactic structure in the form of constituency parse trees, such that each node is a span of audio that corresponds to a constituent. We compare two approaches: (1) cascading an unsupervised automatic speech recognition (ASR) model and an unsupervised parser to obtain parse trees on ASR transcripts, and (2) direct training an unsupervised parser on continuous word-level speech representations. This is done by first splitting utterances into sequences of word-level segments, and aggregating self-supervised speech representations within segments to obtain segment embeddings. We find that separately training a parser on the unpaired text and directly applying it on ASR transcripts for inference produces better results for unsupervised parsing. Additionally, our results suggest that accurate segmentation alone may be sufficient to parse spoken sentences accurately. Finally, we show the direct approach may learn head-directionality correctly for both head-initial and head-final languages without any explicit inductive bias.
Probing Speech Emotion Recognition Transformers for Linguistic Knowledge
Apr 01, 2022
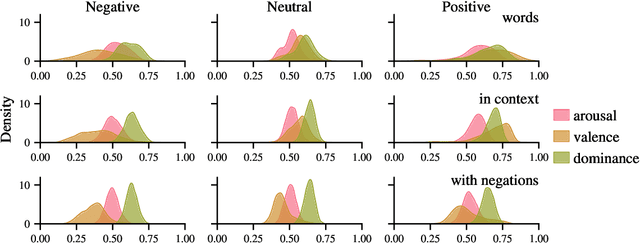
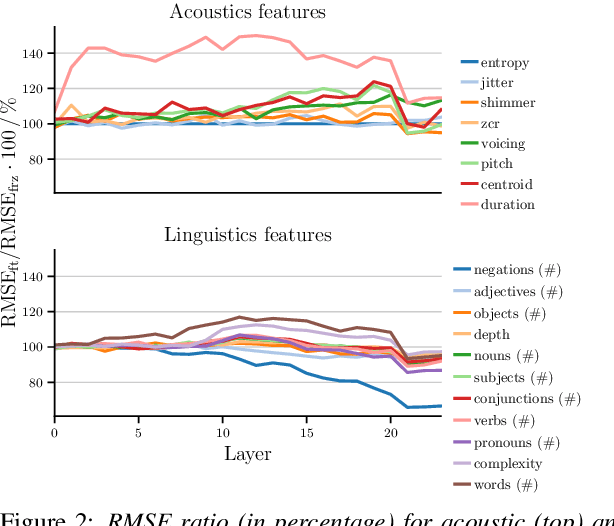
Large, pre-trained neural networks consisting of self-attention layers (transformers) have recently achieved state-of-the-art results on several speech emotion recognition (SER) datasets. These models are typically pre-trained in self-supervised manner with the goal to improve automatic speech recognition performance -- and thus, to understand linguistic information. In this work, we investigate the extent in which this information is exploited during SER fine-tuning. Using a reproducible methodology based on open-source tools, we synthesise prosodically neutral speech utterances while varying the sentiment of the text. Valence predictions of the transformer model are very reactive to positive and negative sentiment content, as well as negations, but not to intensifiers or reducers, while none of those linguistic features impact arousal or dominance. These findings show that transformers can successfully leverage linguistic information to improve their valence predictions, and that linguistic analysis should be included in their testing.
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 14, 2021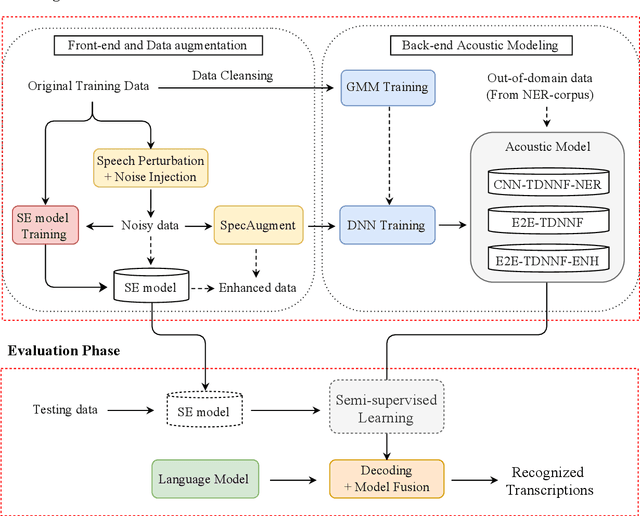
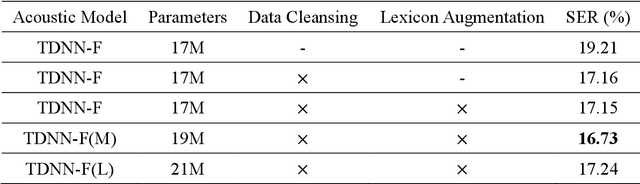
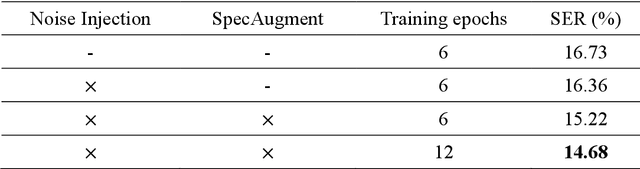
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
Constrained Variational Autoencoder for improving EEG based Speech Recognition Systems
Jun 01, 2020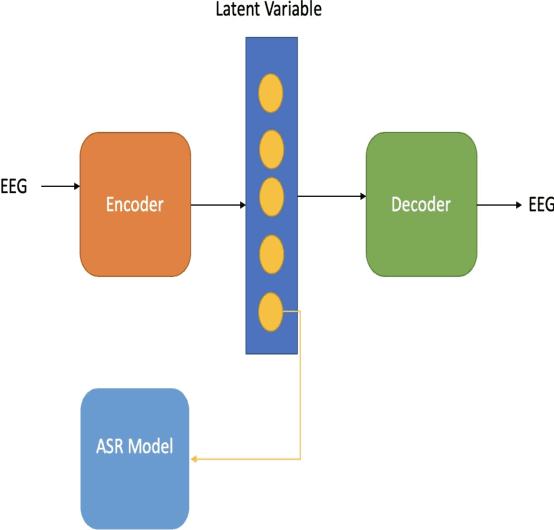

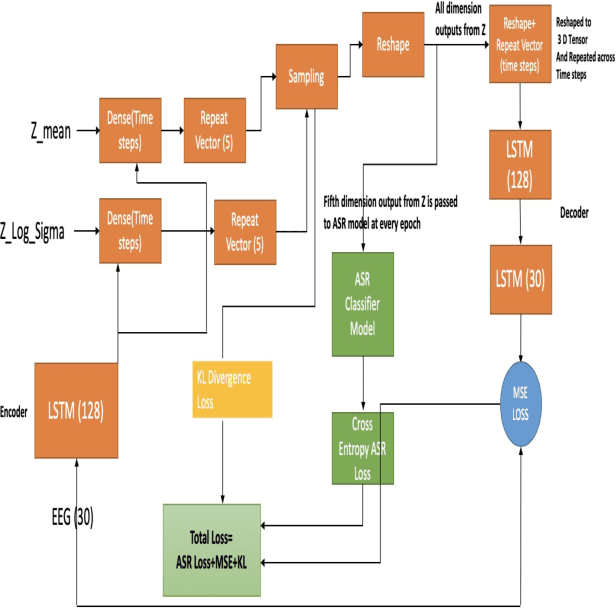
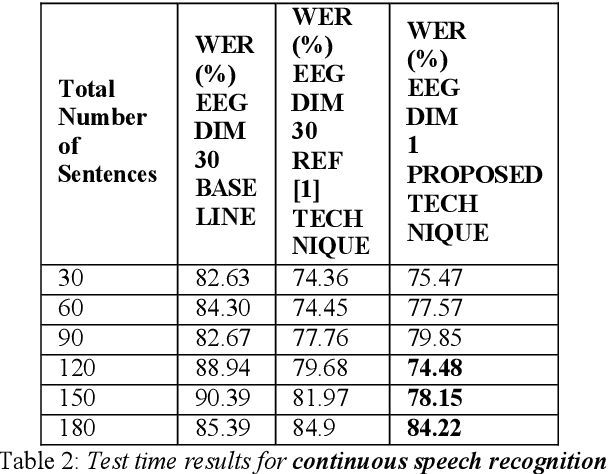
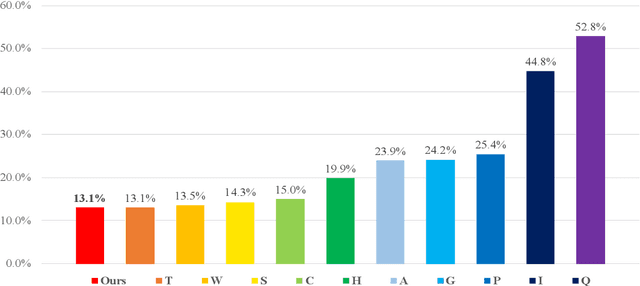
In this paper we introduce a recurrent neural network (RNN) based variational autoencoder (VAE) model with a new constrained loss function that can generate more meaningful electroencephalography (EEG) features from raw EEG features to improve the performance of EEG based speech recognition systems. We demonstrate that both continuous and isolated speech recognition systems trained and tested using EEG features generated from raw EEG features using our VAE model results in improved performance and we demonstrate our results for a limited English vocabulary consisting of 30 unique sentences for continuous speech recognition and for an English vocabulary consisting of 2 unique sentences for isolated speech recognition. We compare our method with another recently introduced method described by authors in [1] to improve the performance of EEG based continuous speech recognition systems and we demonstrate that our method outperforms their method as vocabulary size increases when trained and tested using the same data set. Even though we demonstrate results only for automatic speech recognition (ASR) experiments in this paper, the proposed VAE model with constrained loss function can be extended to a variety of other EEG based brain computer interface (BCI) applications.
Adversarial Data Augmentation Using VAE-GAN for Disordered Speech Recognition
Nov 03, 2022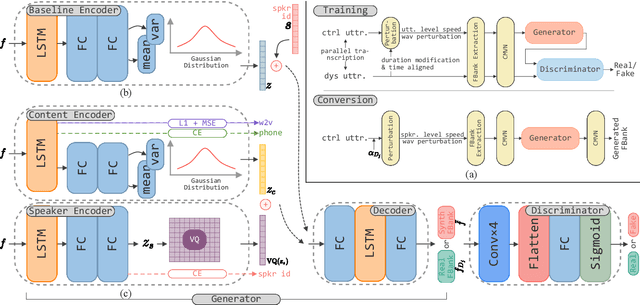
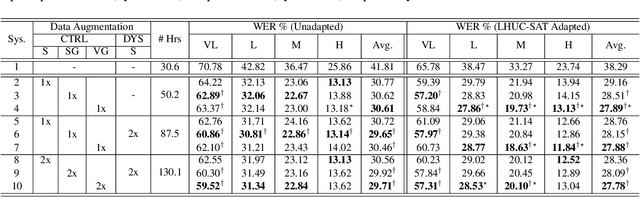
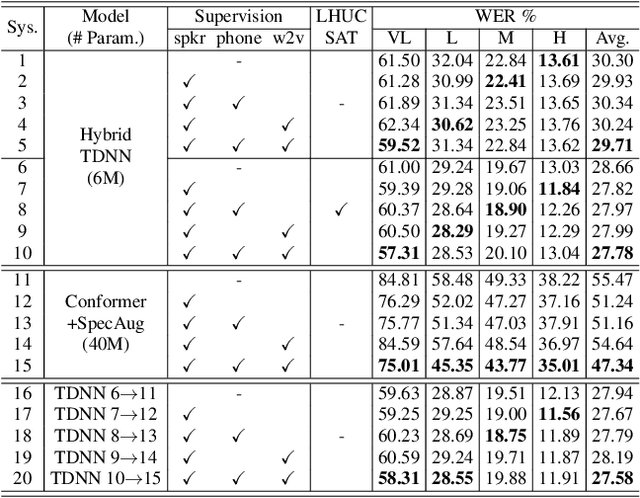

Automatic recognition of disordered speech remains a highly challenging task to date. The underlying neuro-motor conditions, often compounded with co-occurring physical disabilities, lead to the difficulty in collecting large quantities of impaired speech required for ASR system development. This paper presents novel variational auto-encoder generative adversarial network (VAE-GAN) based personalized disordered speech augmentation approaches that simultaneously learn to encode, generate and discriminate synthesized impaired speech. Separate latent features are derived to learn dysarthric speech characteristics and phoneme context representations. Self-supervised pre-trained Wav2vec 2.0 embedding features are also incorporated. Experiments conducted on the UASpeech corpus suggest the proposed adversarial data augmentation approach consistently outperformed the baseline speed perturbation and non-VAE GAN augmentation methods with trained hybrid TDNN and End-to-end Conformer systems. After LHUC speaker adaptation, the best system using VAE-GAN based augmentation produced an overall WER of 27.78% on the UASpeech test set of 16 dysarthric speakers, and the lowest published WER of 57.31% on the subset of speakers with "Very Low" intelligibility.