 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
Cascading and Direct Approaches to Unsupervised Constituency Parsing on Spoken Sentences
Mar 15, 2023



Past work on unsupervised parsing is constrained to written form. In this paper, we present the first study on unsupervised spoken constituency parsing given unlabeled spoken sentences and unpaired textual data. The goal is to determine the spoken sentences' hierarchical syntactic structure in the form of constituency parse trees, such that each node is a span of audio that corresponds to a constituent. We compare two approaches: (1) cascading an unsupervised automatic speech recognition (ASR) model and an unsupervised parser to obtain parse trees on ASR transcripts, and (2) direct training an unsupervised parser on continuous word-level speech representations. This is done by first splitting utterances into sequences of word-level segments, and aggregating self-supervised speech representations within segments to obtain segment embeddings. We find that separately training a parser on the unpaired text and directly applying it on ASR transcripts for inference produces better results for unsupervised parsing. Additionally, our results suggest that accurate segmentation alone may be sufficient to parse spoken sentences accurately. Finally, we show the direct approach may learn head-directionality correctly for both head-initial and head-final languages without any explicit inductive bias.
Losses Can Be Blessings: Routing Self-Supervised Speech Representations Towards Efficient Multilingual and Multitask Speech Processing
Nov 02, 2022



Self-supervised learning (SSL) for rich speech representations has achieved empirical success in low-resource Automatic Speech Recognition (ASR) and other speech processing tasks, which can mitigate the necessity of a large amount of transcribed speech and thus has driven a growing demand for on-device ASR and other speech processing. However, advanced speech SSL models have become increasingly large, which contradicts the limited on-device resources. This gap could be more severe in multilingual/multitask scenarios requiring simultaneously recognizing multiple languages or executing multiple speech processing tasks. Additionally, strongly overparameterized speech SSL models tend to suffer from overfitting when being finetuned on low-resource speech corpus. This work aims to enhance the practical usage of speech SSL models towards a win-win in both enhanced efficiency and alleviated overfitting via our proposed S$^3$-Router framework, which for the first time discovers that simply discarding no more than 10\% of model weights via only finetuning model connections of speech SSL models can achieve better accuracy over standard weight finetuning on downstream speech processing tasks. More importantly, S$^3$-Router can serve as an all-in-one technique to enable (1) a new finetuning scheme, (2) an efficient multilingual/multitask solution, (3) a state-of-the-art ASR pruning technique, and (4) a new tool to quantitatively analyze the learned speech representation. We believe S$^3$-Router has provided a new perspective for practical deployment of speech SSL models. Our codes are available at: https://github.com/GATECH-EIC/S3-Router.
Improving Self-Supervised Speech Representations by Disentangling Speakers
Apr 20, 2022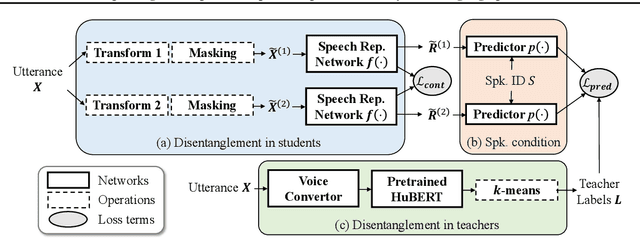

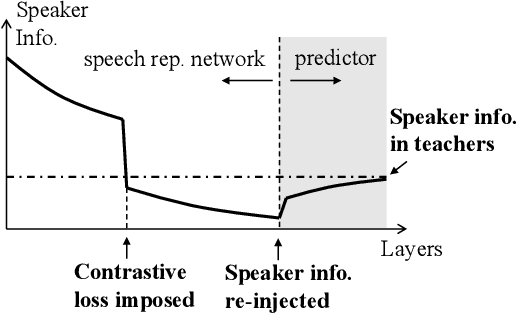
Self-supervised learning in speech involves training a speech representation network on a large-scale unannotated speech corpus, and then applying the learned representations to downstream tasks. Since the majority of the downstream tasks of SSL learning in speech largely focus on the content information in speech, the most desirable speech representations should be able to disentangle unwanted variations, such as speaker variations, from the content. However, disentangling speakers is very challenging, because removing the speaker information could easily result in a loss of content as well, and the damage of the latter usually far outweighs the benefit of the former. In this paper, we propose a new SSL method that can achieve speaker disentanglement without severe loss of content. Our approach is adapted from the HuBERT framework, and incorporates disentangling mechanisms to regularize both the teacher labels and the learned representations. We evaluate the benefit of speaker disentanglement on a set of content-related downstream tasks, and observe a consistent and notable performance advantage of our speaker-disentangled representations.
Conditioned Natural Language Generation using only Unconditioned Language Model: An Exploration
Nov 14, 2020

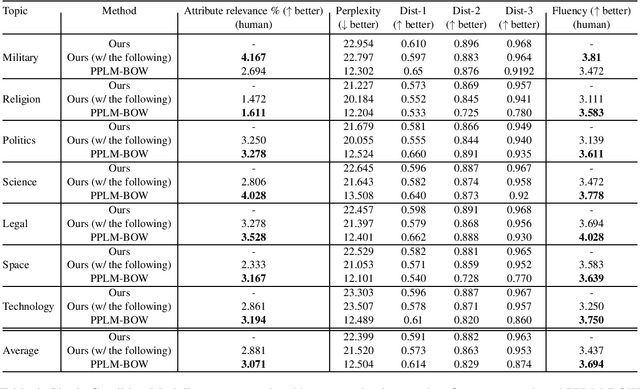
Transformer-based language models have shown to be very powerful for natural language generation (NLG). However, text generation conditioned on some user inputs, such as topics or attributes, is non-trivial. Past approach relies on either modifying the original LM architecture, re-training the LM on corpora with attribute labels, or having separately trained `guidance models' to guide text generation in decoding. We argued that the above approaches are not necessary, and the original unconditioned LM is sufficient for conditioned NLG. We evaluated our approaches by the samples' fluency and diversity with automated and human evaluation.
Towards Semi-Supervised Semantics Understanding from Speech
Nov 11, 2020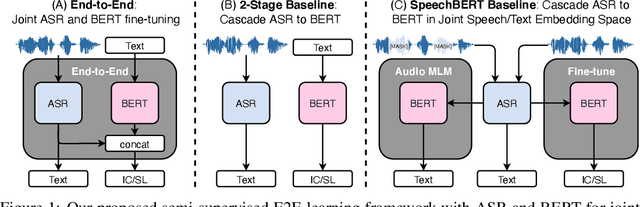
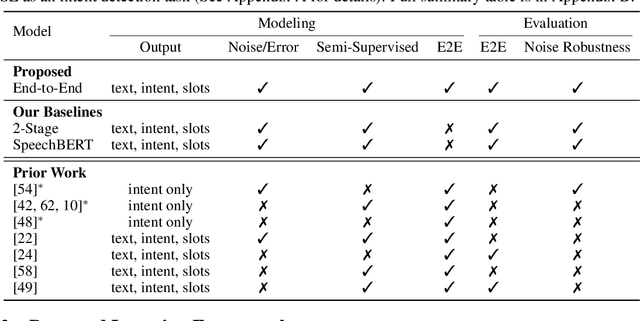
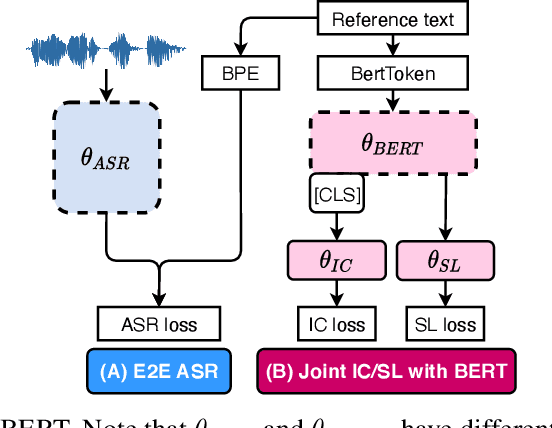
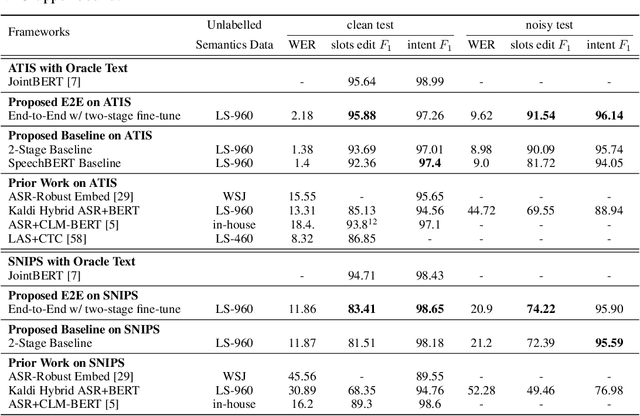
Much recent work on Spoken Language Understanding (SLU) falls short in at least one of three ways: models were trained on oracle text input and neglected the Automatics Speech Recognition (ASR) outputs, models were trained to predict only intents without the slot values, or models were trained on a large amount of in-house data. We proposed a clean and general framework to learn semantics directly from speech with semi-supervision from transcribed speech to address these. Our framework is built upon pretrained end-to-end (E2E) ASR and self-supervised language models, such as BERT, and fine-tuned on a limited amount of target SLU corpus. In parallel, we identified two inadequate settings under which SLU models have been tested: noise-robustness and E2E semantics evaluation. We tested the proposed framework under realistic environmental noises and with a new metric, the slots edit F1 score, on two public SLU corpora. Experiments show that our SLU framework with speech as input can perform on par with those with oracle text as input in semantics understanding, while environmental noises are present, and a limited amount of labeled semantics data is available.
Semi-Supervised Spoken Language Understanding via Self-Supervised Speech and Language Model Pretraining
Oct 26, 2020
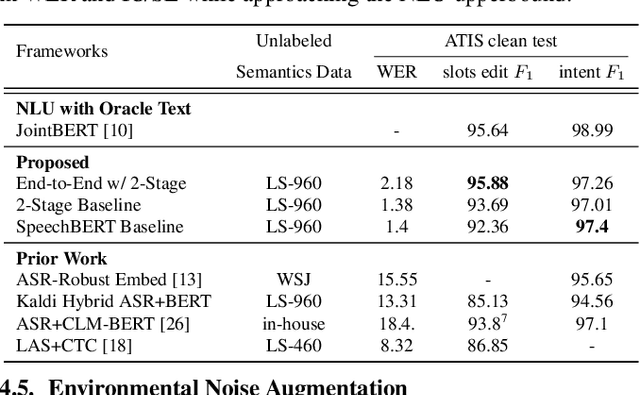
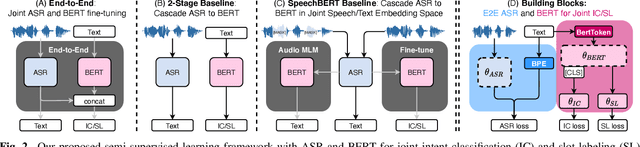
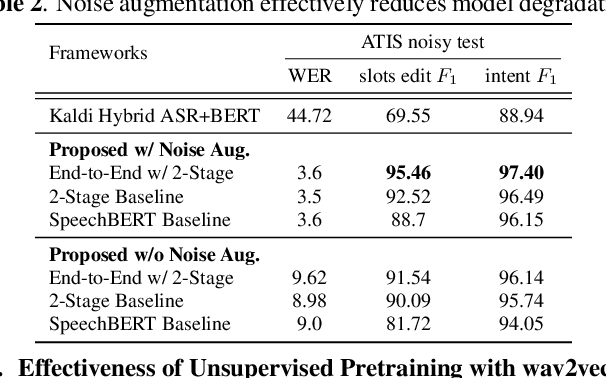
Much recent work on Spoken Language Understanding (SLU) is limited in at least one of three ways: models were trained on oracle text input and neglected ASR errors, models were trained to predict only intents without the slot values, or models were trained on a large amount of in-house data. In this paper, we propose a clean and general framework to learn semantics directly from speech with semi-supervision from transcribed or untranscribed speech to address these issues. Our framework is built upon pretrained end-to-end (E2E) ASR and self-supervised language models, such as BERT, and fine-tuned on a limited amount of target SLU data. We study two semi-supervised settings for the ASR component: supervised pretraining on transcribed speech, and unsupervised pretraining by replacing the ASR encoder with self-supervised speech representations, such as wav2vec. In parallel, we identify two essential criteria for evaluating SLU models: environmental noise-robustness and E2E semantics evaluation. Experiments on ATIS show that our SLU framework with speech as input can perform on par with those using oracle text as input in semantics understanding, even though environmental noise is present and a limited amount of labeled semantics data is available for training.
Contrastive Predictive Coding Based Feature for Automatic Speaker Verification
Apr 01, 2019
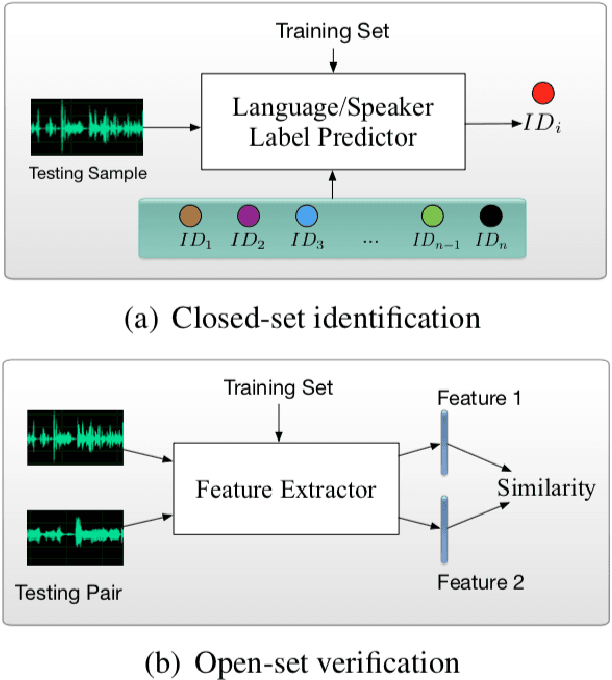
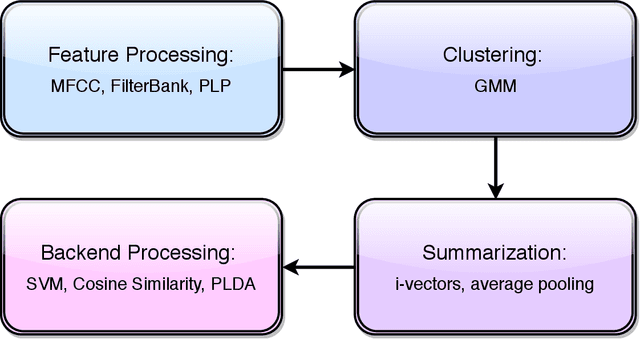
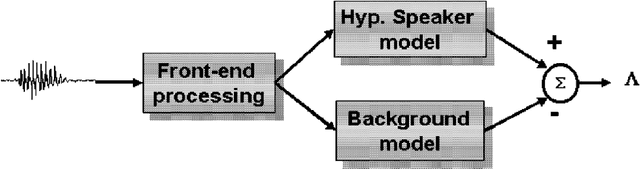
This thesis describes our ongoing work on Contrastive Predictive Coding (CPC) features for speaker verification. CPC is a recently proposed representation learning framework based on predictive coding and noise contrastive estimation. We focus on incorporating CPC features into the standard automatic speaker verification systems, and we present our methods, experiments, and analysis. This thesis also details necessary background knowledge in past and recent work on automatic speaker verification systems, conventional speech features, and the motivation and techniques behind CPC.
ASSERT: Anti-Spoofing with Squeeze-Excitation and Residual neTworks
Apr 01, 2019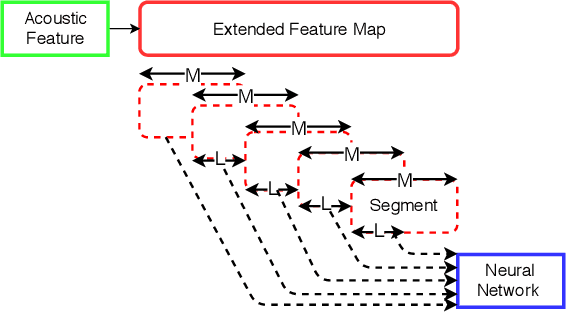
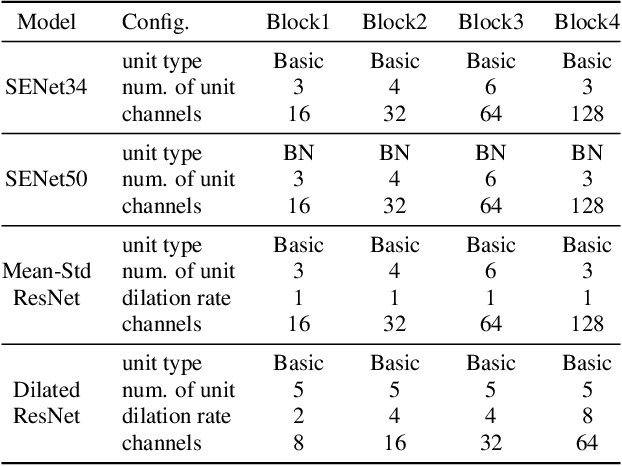
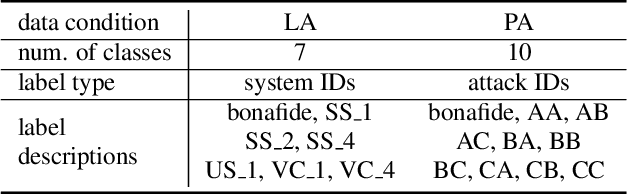
We present JHU's system submission to the ASVspoof 2019 Challenge: Anti-Spoofing with Squeeze-Excitation and Residual neTworks (ASSERT). Anti-spoofing has gathered more and more attention since the inauguration of the ASVspoof Challenges, and ASVspoof 2019 dedicates to address attacks from all three major types: text-to-speech, voice conversion, and replay. Built upon previous research work on Deep Neural Network (DNN), ASSERT is a pipeline for DNN-based approach to anti-spoofing. ASSERT has four components: feature engineering, DNN models, network optimization and system combination, where the DNN models are variants of squeeze-excitation and residual networks. We conducted an ablation study of the effectiveness of each component on the ASVspoof 2019 corpus, and experimental results showed that ASSERT obtained more than 93% and 17% relative improvements over the baseline systems in the two sub-challenges in ASVspooof 2019, ranking ASSERT one of the top performing systems. Code and pretrained models will be made publicly available.
Attentive Filtering Networks for Audio Replay Attack Detection
Oct 31, 2018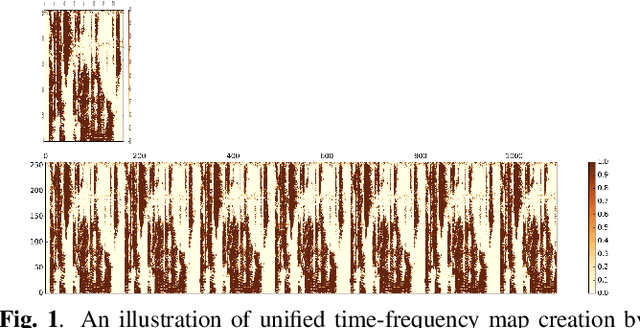
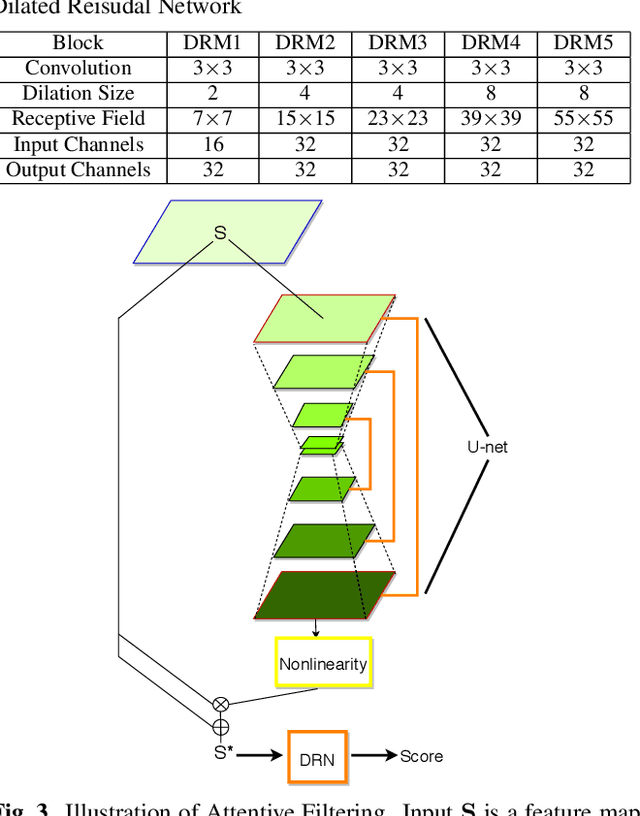
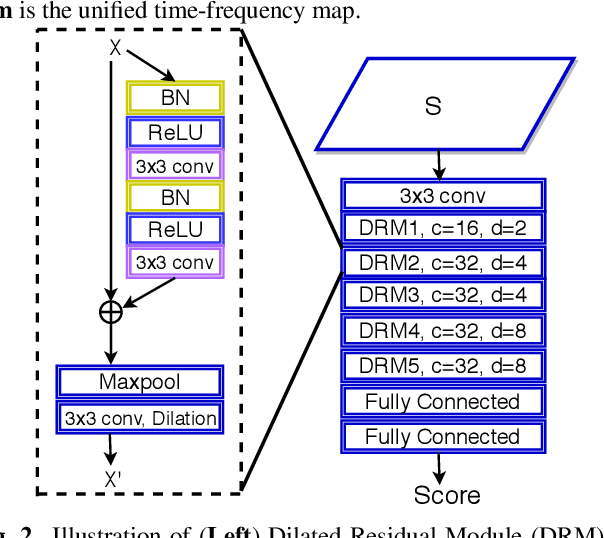
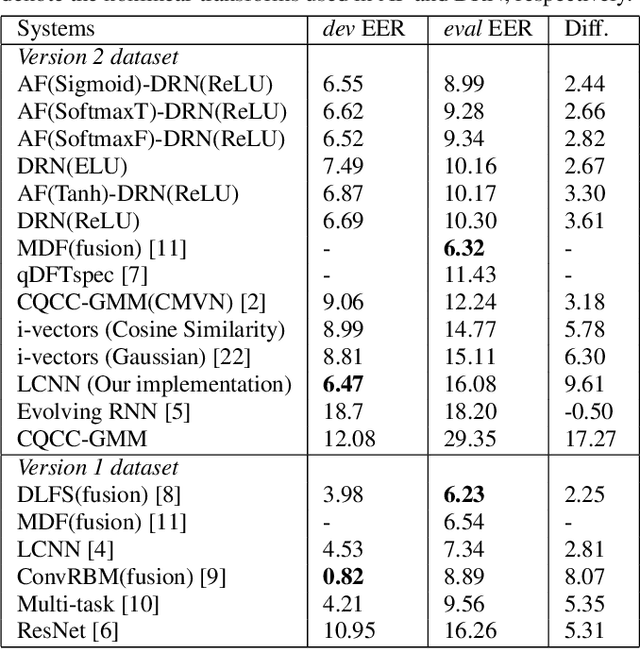
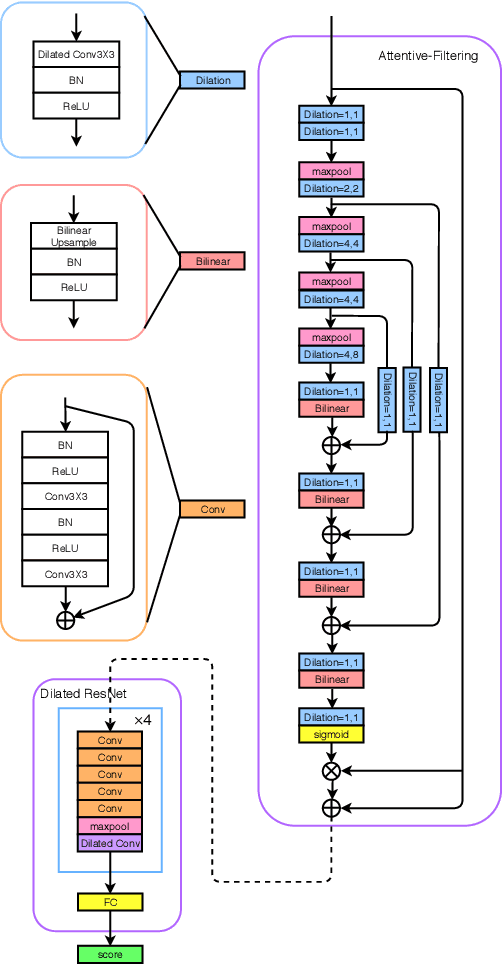
An attacker may use a variety of techniques to fool an automatic speaker verification system into accepting them as a genuine user. Anti-spoofing methods meanwhile aim to make the system robust against such attacks. The ASVspoof 2017 Challenge focused specifically on replay attacks, with the intention of measuring the limits of replay attack detection as well as developing countermeasures against them. In this work, we propose our replay attacks detection system - Attentive Filtering Network, which is composed of an attention-based filtering mechanism that enhances feature representations in both the frequency and time domains, and a ResNet-based classifier. We show that the network enables us to visualize the automatically acquired feature representations that are helpful for spoofing detection. Attentive Filtering Network attains an evaluation EER of 8.99$\%$ on the ASVspoof 2017 Version 2.0 dataset. With system fusion, our best system further obtains a 30$\%$ relative improvement over the ASVspoof 2017 enhanced baseline system.