 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven grapheme-to-phoneme representations for a lexicon-free text-to-speech
Jan 19, 2024Grapheme-to-Phoneme (G2P) is an essential first step in any modern, high-quality Text-to-Speech (TTS) system. Most of the current G2P systems rely on carefully hand-crafted lexicons developed by experts. This poses a two-fold problem. Firstly, the lexicons are generated using a fixed phoneme set, usually, ARPABET or IPA, which might not be the most optimal way to represent phonemes for all languages. Secondly, the man-hours required to produce such an expert lexicon are very high. In this paper, we eliminate both of these issues by using recent advances in self-supervised learning to obtain data-driven phoneme representations instead of fixed representations. We compare our lexicon-free approach against strong baselines that utilize a well-crafted lexicon. Furthermore, we show that our data-driven lexicon-free method performs as good or even marginally better than the conventional rule-based or lexicon-based neural G2Ps in terms of Mean Opinion Score (MOS) while using no prior language lexicon or phoneme set, i.e. no linguistic expertise.
On the compression of shallow non-causal ASR models using knowledge distillation and tied-and-reduced decoder for low-latency on-device speech recognition
Dec 15, 2023Recently, the cascaded two-pass architecture has emerged as a strong contender for on-device automatic speech recognition (ASR). A cascade of causal and shallow non-causal encoders coupled with a shared decoder enables operation in both streaming and look-ahead modes. In this paper, we propose shallow cascaded model by combining various model compression techniques such as knowledge distillation, shared decoder, and tied-and-reduced transducer network in order to reduce the model footprint. The shared decoder is changed into a tied-and-reduced network. The cascaded two-pass model is further compressed using knowledge distillation using a Kullback-Leibler divergence loss on the model posteriors. We demonstrate a 50% reduction in the size of a 41 M parameter cascaded teacher model with no noticeable degradation in ASR accuracy and a 30% reduction in latency
Time-Varying Quasi-Closed-Phase Analysis for Accurate Formant Tracking in Speech Signals
Aug 31, 2023



In this paper, we propose a new method for the accurate estimation and tracking of formants in speech signals using time-varying quasi-closed-phase (TVQCP) analysis. Conventional formant tracking methods typically adopt a two-stage estimate-and-track strategy wherein an initial set of formant candidates are estimated using short-time analysis (e.g., 10--50 ms), followed by a tracking stage based on dynamic programming or a linear state-space model. One of the main disadvantages of these approaches is that the tracking stage, however good it may be, cannot improve upon the formant estimation accuracy of the first stage. The proposed TVQCP method provides a single-stage formant tracking that combines the estimation and tracking stages into one. TVQCP analysis combines three approaches to improve formant estimation and tracking: (1) it uses temporally weighted quasi-closed-phase analysis to derive closed-phase estimates of the vocal tract with reduced interference from the excitation source, (2) it increases the residual sparsity by using the $L_1$ optimization and (3) it uses time-varying linear prediction analysis over long time windows (e.g., 100--200 ms) to impose a continuity constraint on the vocal tract model and hence on the formant trajectories. Formant tracking experiments with a wide variety of synthetic and natural speech signals show that the proposed TVQCP method performs better than conventional and popular formant tracking tools, such as Wavesurfer and Praat (based on dynamic programming), the KARMA algorithm (based on Kalman filtering), and DeepFormants (based on deep neural networks trained in a supervised manner). Matlab scripts for the proposed method can be found at: https://github.com/njaygowda/ftrack
Refining a Deep Learning-based Formant Tracker using Linear Prediction Methods
Aug 17, 2023



In this study, formant tracking is investigated by refining the formants tracked by an existing data-driven tracker, DeepFormants, using the formants estimated in a model-driven manner by linear prediction (LP)-based methods. As LP-based formant estimation methods, conventional covariance analysis (LP-COV) and the recently proposed quasi-closed phase forward-backward (QCP-FB) analysis are used. In the proposed refinement approach, the contours of the three lowest formants are first predicted by the data-driven DeepFormants tracker, and the predicted formants are replaced frame-wise with local spectral peaks shown by the model-driven LP-based methods. The refinement procedure can be plugged into the DeepFormants tracker with no need for any new data learning. Two refined DeepFormants trackers were compared with the original DeepFormants and with five known traditional trackers using the popular vocal tract resonance (VTR) corpus. The results indicated that the data-driven DeepFormants trackers outperformed the conventional trackers and that the best performance was obtained by refining the formants predicted by DeepFormants using QCP-FB analysis. In addition, by tracking formants using VTR speech that was corrupted by additive noise, the study showed that the refined DeepFormants trackers were more resilient to noise than the reference trackers. In general, these results suggest that LP-based model-driven approaches, which have traditionally been used in formant estimation, can be combined with a modern data-driven tracker easily with no further training to improve the tracker's performance.
Mitigating the Exposure Bias in Sentence-Level Grapheme-to-Phoneme (G2P) Transduction
Aug 16, 2023



Text-to-Text Transfer Transformer (T5) has recently been considered for the Grapheme-to-Phoneme (G2P) transduction. As a follow-up, a tokenizer-free byte-level model based on T5 referred to as ByT5, recently gave promising results on word-level G2P conversion by representing each input character with its corresponding UTF-8 encoding. Although it is generally understood that sentence-level or paragraph-level G2P can improve usability in real-world applications as it is better suited to perform on heteronyms and linking sounds between words, we find that using ByT5 for these scenarios is nontrivial. Since ByT5 operates on the character level, it requires longer decoding steps, which deteriorates the performance due to the exposure bias commonly observed in auto-regressive generation models. This paper shows that the performance of sentence-level and paragraph-level G2P can be improved by mitigating such exposure bias using our proposed loss-based sampling method.
Multi-stage Progressive Compression of Conformer Transducer for On-device Speech Recognition
Oct 01, 2022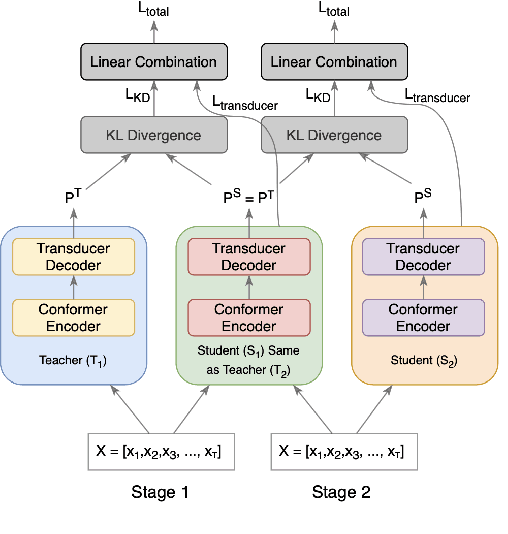
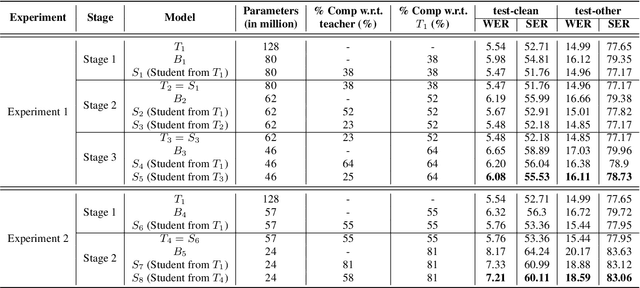
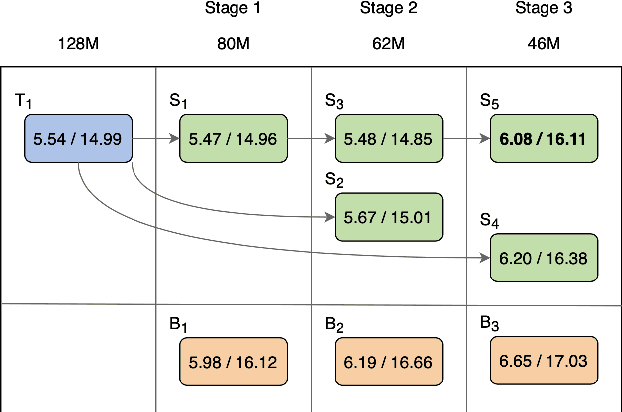
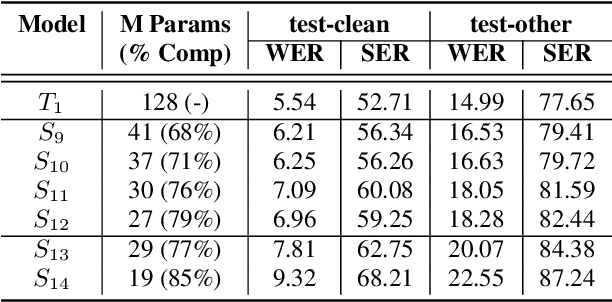
The smaller memory bandwidth in smart devices prompts development of smaller Automatic Speech Recognition (ASR) models. To obtain a smaller model, one can employ the model compression techniques. Knowledge distillation (KD) is a popular model compression approach that has shown to achieve smaller model size with relatively lesser degradation in the model performance. In this approach, knowledge is distilled from a trained large size teacher model to a smaller size student model. Also, the transducer based models have recently shown to perform well for on-device streaming ASR task, while the conformer models are efficient in handling long term dependencies. Hence in this work we employ a streaming transducer architecture with conformer as the encoder. We propose a multi-stage progressive approach to compress the conformer transducer model using KD. We progressively update our teacher model with the distilled student model in a multi-stage setup. On standard LibriSpeech dataset, our experimental results have successfully achieved compression rates greater than 60% without significant degradation in the performance compared to the larger teacher model.
* Published in INTERSPEECH 2022
Two-Pass End-to-End ASR Model Compression
Jan 08, 2022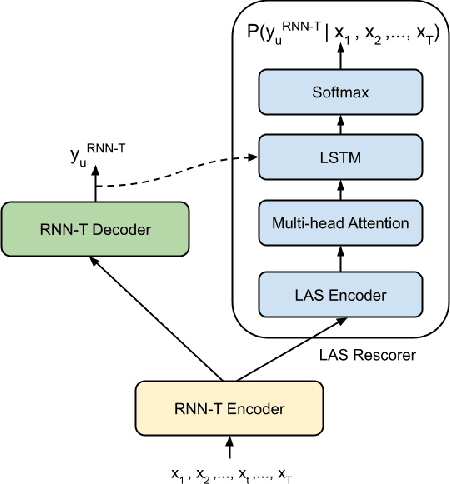

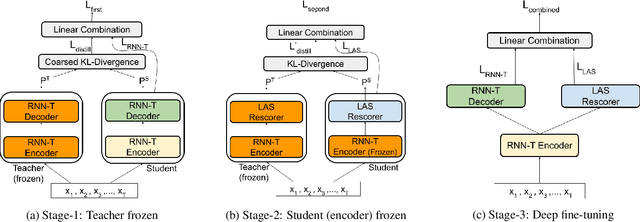
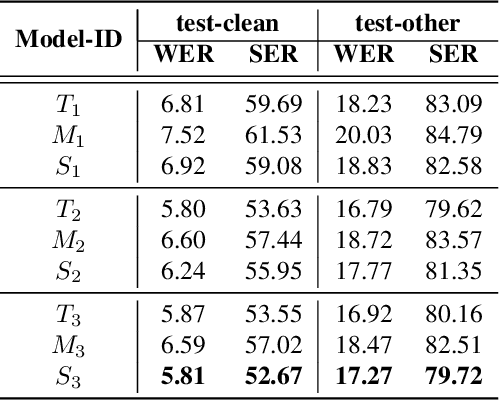
Speech recognition on smart devices is challenging owing to the small memory footprint. Hence small size ASR models are desirable. With the use of popular transducer-based models, it has become possible to practically deploy streaming speech recognition models on small devices [1]. Recently, the two-pass model [2] combining RNN-T and LAS modules has shown exceptional performance for streaming on-device speech recognition. In this work, we propose a simple and effective approach to reduce the size of the two-pass model for memory-constrained devices. We employ a popular knowledge distillation approach in three stages using the Teacher-Student training technique. In the first stage, we use a trained RNN-T model as a teacher model and perform knowledge distillation to train the student RNN-T model. The second stage uses the shared encoder and trains a LAS rescorer for student model using the trained RNN-T+LAS teacher model. Finally, we perform deep-finetuning for the student model with a shared RNN-T encoder, RNN-T decoder, and LAS rescorer. Our experimental results on standard LibriSpeech dataset show that our system can achieve a high compression rate of 55% without significant degradation in the WER compared to the two-pass teacher model.
Formant Tracking Using Quasi-Closed Phase Forward-Backward Linear Prediction Analysis and Deep Neural Networks
Jan 05, 2022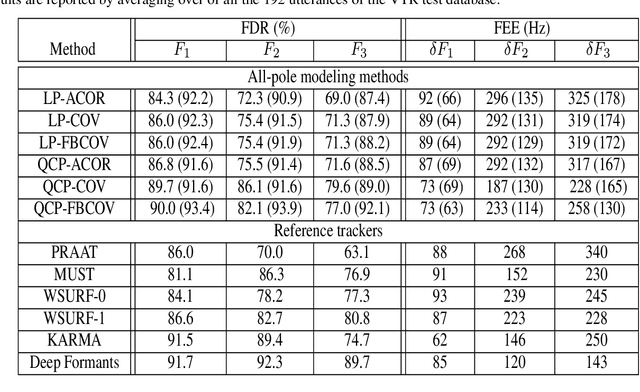
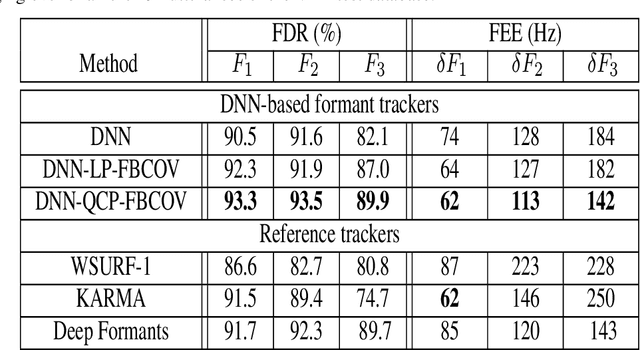
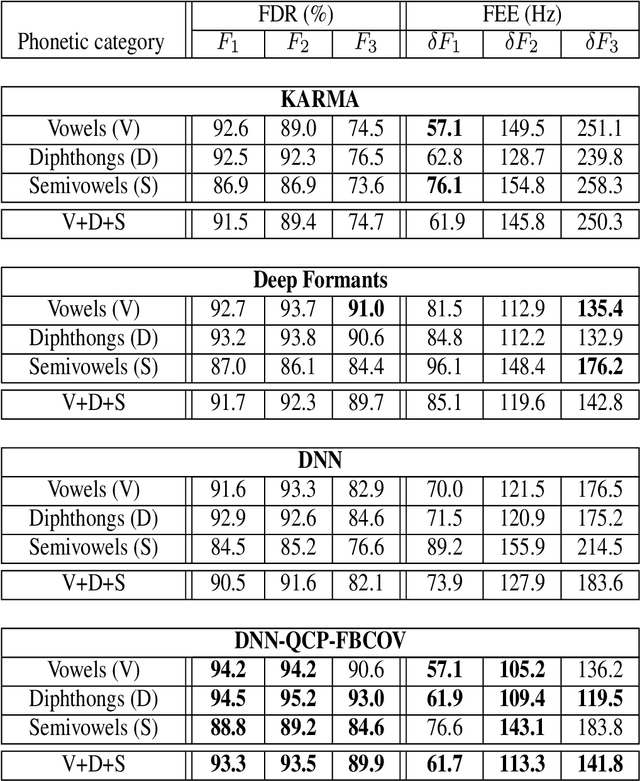
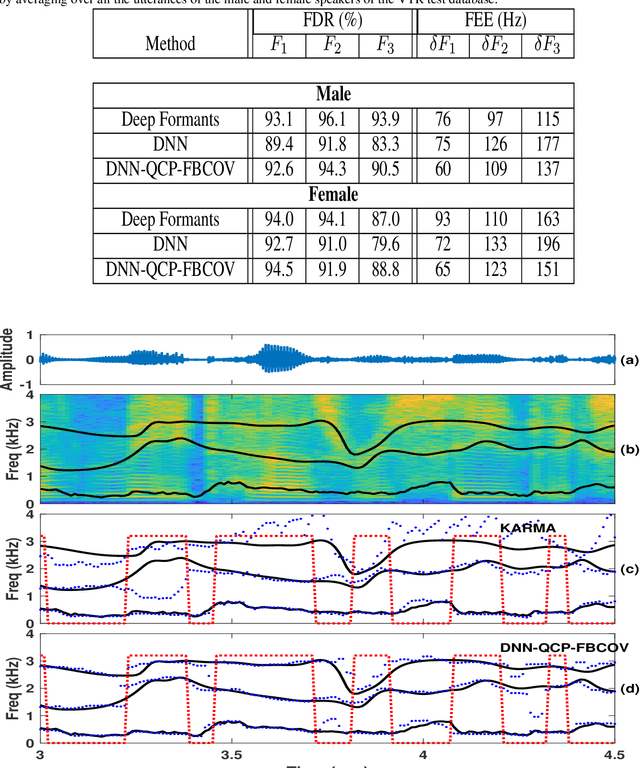
Formant tracking is investigated in this study by using trackers based on dynamic programming (DP) and deep neural nets (DNNs). Using the DP approach, six formant estimation methods were first compared. The six methods include linear prediction (LP) algorithms, weighted LP algorithms and the recently developed quasi-closed phase forward-backward (QCP-FB) method. QCP-FB gave the best performance in the comparison. Therefore, a novel formant tracking approach, which combines benefits of deep learning and signal processing based on QCP-FB, was proposed. In this approach, the formants predicted by a DNN-based tracker from a speech frame are refined using the peaks of the all-pole spectrum computed by QCP-FB from the same frame. Results show that the proposed DNN-based tracker performed better both in detection rate and estimation error for the lowest three formants compared to reference formant trackers. Compared to the popular Wavesurfer, for example, the proposed tracker gave a reduction of 29%, 48% and 35% in the estimation error for the lowest three formants, respectively.
Semi-supervised transfer learning for language expansion of end-to-end speech recognition models to low-resource languages
Nov 19, 2021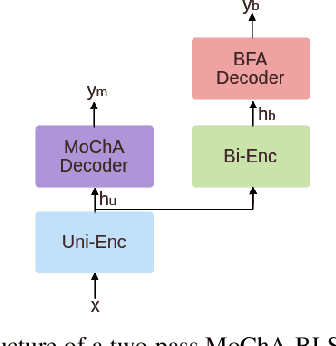
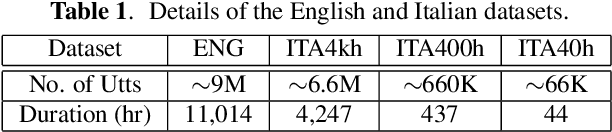
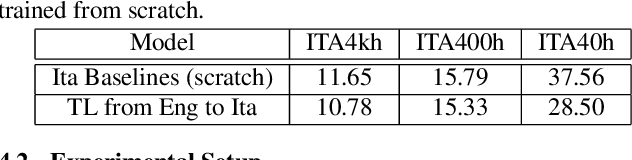
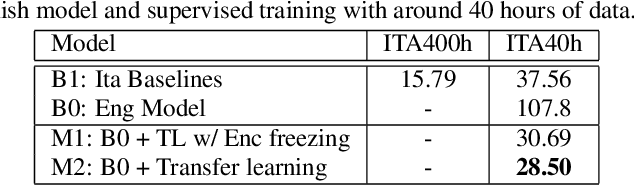
In this paper, we propose a three-stage training methodology to improve the speech recognition accuracy of low-resource languages. We explore and propose an effective combination of techniques such as transfer learning, encoder freezing, data augmentation using Text-To-Speech (TTS), and Semi-Supervised Learning (SSL). To improve the accuracy of a low-resource Italian ASR, we leverage a well-trained English model, unlabeled text corpus, and unlabeled audio corpus using transfer learning, TTS augmentation, and SSL respectively. In the first stage, we use transfer learning from a well-trained English model. This primarily helps in learning the acoustic information from a resource-rich language. This stage achieves around 24% relative Word Error Rate (WER) reduction over the baseline. In stage two, We utilize unlabeled text data via TTS data-augmentation to incorporate language information into the model. We also explore freezing the acoustic encoder at this stage. TTS data augmentation helps us further reduce the WER by ~ 21% relatively. Finally, In stage three we reduce the WER by another 4% relative by using SSL from unlabeled audio data. Overall, our two-pass speech recognition system with a Monotonic Chunkwise Attention (MoChA) in the first pass and a full-attention in the second pass achieves a WER reduction of ~ 42% relative to the baseline.
A comparison of streaming models and data augmentation methods for robust speech recognition
Nov 19, 2021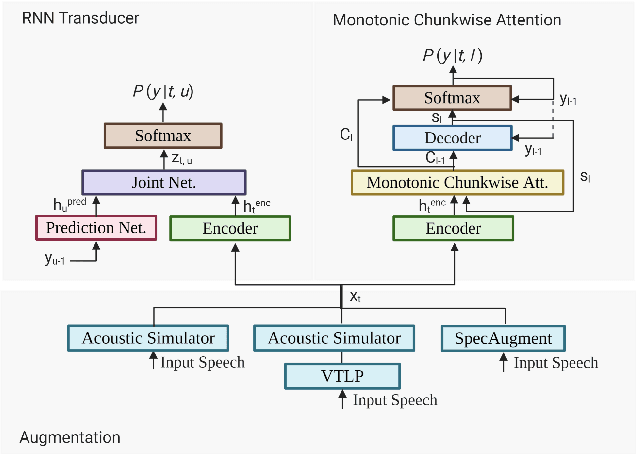

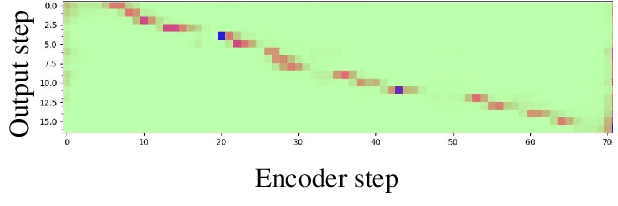

In this paper, we present a comparative study on the robustness of two different online streaming speech recognition models: Monotonic Chunkwise Attention (MoChA) and Recurrent Neural Network-Transducer (RNN-T). We explore three recently proposed data augmentation techniques, namely, multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment. Experimental results show that unidirectional models are in general more sensitive to noisy examples in the training set. It is observed that the final performance of the model depends on the proportion of training examples processed by data augmentation techniques. MoChA models generally perform better than RNN-T models. However, we observe that training of MoChA models seems to be more sensitive to various factors such as the characteristics of training sets and the incorporation of additional augmentations techniques. On the other hand, RNN-T models perform better than MoChA models in terms of latency, inference time, and the stability of training. Additionally, RNN-T models are generally more robust against noise and reverberation. All these advantages make RNN-T models a better choice for streaming on-device speech recognition compared to MoChA models.