 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNISON: A Unified Sound Generation and Editing Framework via Deep LLM Fusion
May 29, 2026We present UNISON, a latent diffusion framework that unifies speech generation, sound generation, and audio editing within a single model. A single model handles text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition, all of which share a single set of weights. Our architecture features two core designs: (1) Layer-wise deep LLM fusion, which injects hidden states from uniformly sampled layers of a frozen MLLM into corresponding MM-DiT blocks via learned projections, providing depth-matched semantic conditioning that improves instruction following over single-layer baselines; and (2) a unified multi-task architecture where task identity is encoded solely by a channel-wise mask and source audio is provided through VAE-encoded channel concatenation. Training is stabilized by an online GPU-side multi-task data synthesis pipeline with task-homogeneous batching and a two-stage curriculum. With 621M--732M trainable parameters, UNISON achieves results competitive with or exceeding task-specialist models across evaluated domains, while being roughly $4\times$ smaller than comparable unified systems.
ACAVCaps: Enabling large-scale training for fine-grained and diverse audio understanding
Mar 25, 2026General audio understanding is a fundamental goal for large audio-language models, with audio captioning serving as a cornerstone task for their development. However, progress in this domain is hindered by existing datasets, which lack the scale and descriptive granularity required to train truly versatile models. To address this gap, we introduce ACAVCaps, a new large-scale, fine-grained, and multi-faceted audio captioning dataset. Derived from the ACAV100M collection, ACAVCaps is constructed using a multi-expert pipeline that analyzes audio from diverse perspectives-including speech, music, and acoustic properties-which are then synthesized into rich, detailed descriptions by a large language model. Experimental results demonstrate that models pre-trained on ACAVCaps exhibit substantially stronger generalization capabilities on various downstream tasks compared to those trained on other leading captioning datasets. The dataset is available at https://github.com/xiaomi-research/acavcaps.
MiDashengLM: Efficient Audio Understanding with General Audio Captions
Aug 06, 2025



Current approaches for large audio language models (LALMs) often rely on closed data sources or proprietary models, limiting their generalization and accessibility. This paper introduces MiDashengLM, a novel open audio-language model designed for efficient and comprehensive audio understanding through the use of general audio captions using our novel ACAVCaps training dataset. MiDashengLM exclusively relies on publicly available pretraining and supervised fine-tuning (SFT) datasets, ensuring full transparency and reproducibility. At its core, MiDashengLM integrates Dasheng, an open-source audio encoder, specifically engineered to process diverse auditory information effectively. Unlike previous works primarily focused on Automatic Speech Recognition (ASR) based audio-text alignment, our strategy centers on general audio captions, fusing speech, sound and music information into one textual representation, enabling a holistic textual representation of complex audio scenes. Lastly, MiDashengLM provides an up to 4x speedup in terms of time-to-first-token (TTFT) and up to 20x higher throughput than comparable models. Checkpoints are available online at https://huggingface.co/mispeech/midashenglm-7b and https://github.com/xiaomi-research/dasheng-lm.
GLAP: General contrastive audio-text pretraining across domains and languages
Jun 12, 2025



Contrastive Language Audio Pretraining (CLAP) is a widely-used method to bridge the gap between audio and text domains. Current CLAP methods enable sound and music retrieval in English, ignoring multilingual spoken content. To address this, we introduce general language audio pretraining (GLAP), which expands CLAP with multilingual and multi-domain abilities. GLAP demonstrates its versatility by achieving competitive performance on standard audio-text retrieval benchmarks like Clotho and AudioCaps, while significantly surpassing existing methods in speech retrieval and classification tasks. Additionally, GLAP achieves strong results on widely used sound-event zero-shot benchmarks, while simultaneously outperforming previous methods on speech content benchmarks. Further keyword spotting evaluations across 50 languages emphasize GLAP's advanced multilingual capabilities. Finally, multilingual sound and music understanding is evaluated across four languages. Checkpoints and Source: https://github.com/xiaomi-research/dasheng-glap.
On-the-fly Routing for Zero-shot MoE Speaker Adaptation of Speech Foundation Models for Dysarthric Speech Recognition
May 28, 2025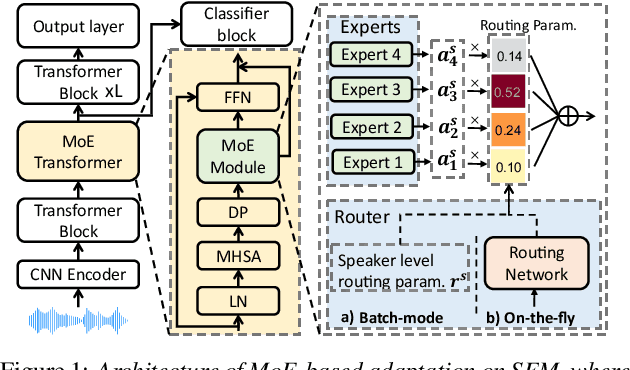
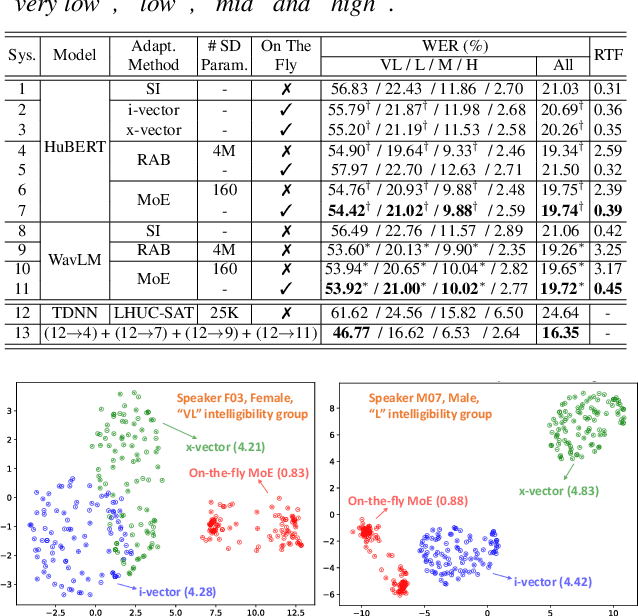
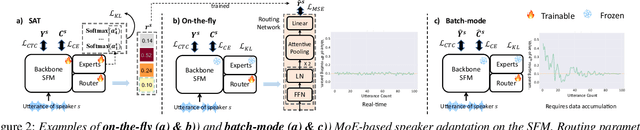

This paper proposes a novel MoE-based speaker adaptation framework for foundation models based dysarthric speech recognition. This approach enables zero-shot adaptation and real-time processing while incorporating domain knowledge. Speech impairment severity and gender conditioned adapter experts are dynamically combined using on-the-fly predicted speaker-dependent routing parameters. KL-divergence is used to further enforce diversity among experts and their generalization to unseen speakers. Experimental results on the UASpeech corpus suggest that on-the-fly MoE-based adaptation produces statistically significant WER reductions of up to 1.34% absolute (6.36% relative) over the unadapted baseline HuBERT/WavLM models. Consistent WER reductions of up to 2.55% absolute (11.44% relative) and RTF speedups of up to 7 times are obtained over batch-mode adaptation across varying speaker-level data quantities. The lowest published WER of 16.35% (46.77% on very low intelligibility) is obtained.
Unfolding A Few Structures for The Many: Memory-Efficient Compression of Conformer and Speech Foundation Models
May 27, 2025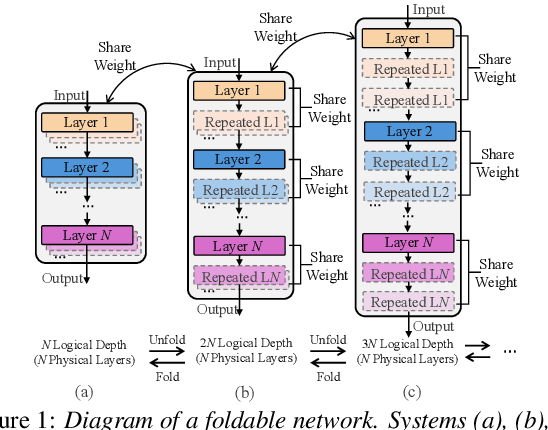
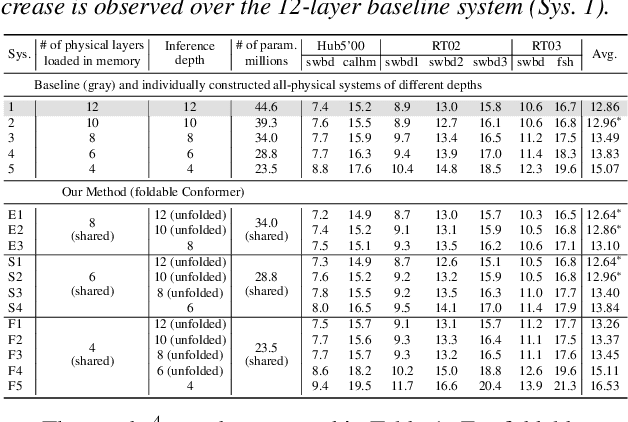
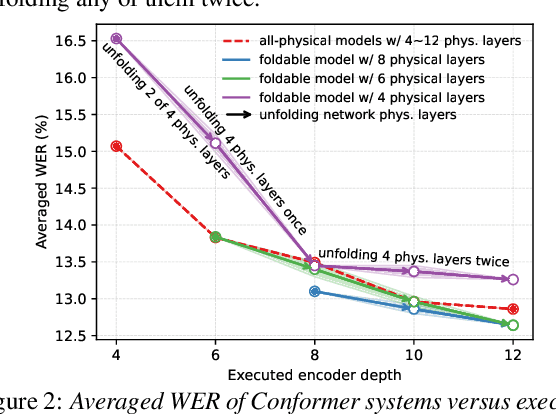
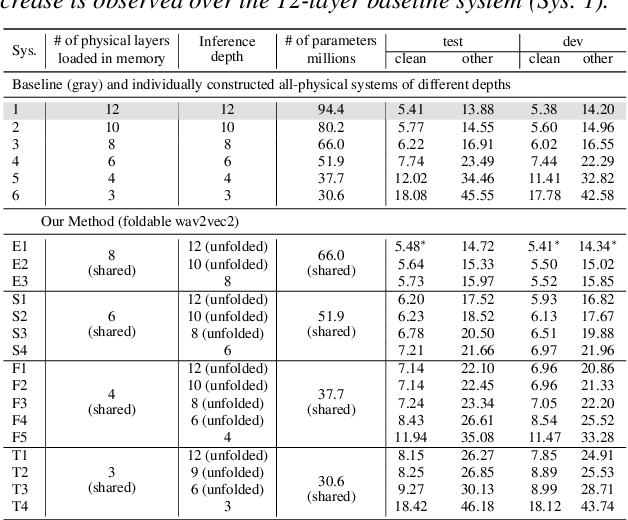
This paper presents a novel memory-efficient model compression approach for Conformer ASR and speech foundation systems. Our approach features a unique "small-to-large" design. A compact "seed" model containing a few Conformer or Transformer blocks is trained and unfolded many times to emulate the performance of larger uncompressed models with different logical depths. The seed model and many unfolded paths are jointly trained within a single unfolding cycle. The KL-divergence between the largest unfolded and smallest seed models is used in a self-distillation process to minimize their performance disparity. Experimental results show that our foldable model produces ASR performance comparable to individually constructed Conformer and wav2vec2/HuBERT speech foundation models under various depth configurations, while requiring only minimal memory and storage. Conformer and wav2vec2 models with a reduction of 35% and 30% parameters are obtained without loss of performance, respectively.
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Precision
May 27, 2025Model compression has become an emerging need as the sizes of modern speech systems rapidly increase. In this paper, we study model weight quantization, which directly reduces the memory footprint to accommodate computationally resource-constrained applications. We propose novel approaches to perform extremely low-bit (i.e., 2-bit and 1-bit) quantization of Conformer automatic speech recognition systems using multiple precision model co-training, stochastic precision, and tensor-wise learnable scaling factors to alleviate quantization incurred performance loss. The proposed methods can achieve performance-lossless 2-bit and 1-bit quantization of Conformer ASR systems trained with the 300-hr Switchboard and 960-hr LibriSpeech corpus. Maximum overall performance-lossless compression ratios of 16.2 and 16.6 times are achieved without a statistically significant increase in the word error rate (WER) over the full precision baseline systems, respectively.
Structured Speaker-Deficiency Adaptation of Foundation Models for Dysarthric and Elderly Speech Recognition
Dec 25, 2024



Data-intensive fine-tuning of speech foundation models (SFMs) to scarce and diverse dysarthric and elderly speech leads to data bias and poor generalization to unseen speakers. This paper proposes novel structured speaker-deficiency adaptation approaches for SSL pre-trained SFMs on such data. Speaker and speech deficiency invariant SFMs were constructed in their supervised adaptive fine-tuning stage to reduce undue bias to training data speakers, and serves as a more neutral and robust starting point for test time unsupervised adaptation. Speech variability attributed to speaker identity and speech impairment severity, or aging induced neurocognitive decline, are modelled using separate adapters that can be combined together to model any seen or unseen speaker. Experiments on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest structured speaker-deficiency adaptation of HuBERT and Wav2vec2-conformer models consistently outperforms baseline SFMs using either: a) no adapters; b) global adapters shared among all speakers; or c) single attribute adapters modelling speaker or deficiency labels alone by statistically significant WER reductions up to 3.01% and 1.50% absolute (10.86% and 6.94% relative) on the two tasks respectively. The lowest published WER of 19.45% (49.34% on very low intelligibility, 33.17% on unseen words) is obtained on the UASpeech test set of 16 dysarthric speakers.
Exploring SSL Discrete Speech Features for Zipformer-based Contextual ASR
Sep 13, 2024



Self-supervised learning (SSL) based discrete speech representations are highly compact and domain adaptable. In this paper, SSL discrete speech features extracted from WavLM models are used as additional cross-utterance acoustic context features in Zipformer-Transducer ASR systems. The efficacy of replacing Fbank features with discrete token features for modelling either cross-utterance contexts (from preceding and future segments), or current utterance's internal contexts alone, or both at the same time, are demonstrated thoroughly on the Gigaspeech 1000-hr corpus. The best Zipformer-Transducer system using discrete tokens based cross-utterance context features outperforms the baseline using utterance internal context only with statistically significant word error rate (WER) reductions of 0.32% to 0.41% absolute (2.78% to 3.54% relative) on the dev and test data. The lowest published WER of 11.15% and 11.14% were obtained on the dev and test sets. Our work is open-source and publicly available at https://github.com/open-creator/icefall/tree/master/egs/gigaspeech/Context\_ASR.
Homogeneous Speaker Features for On-the-Fly Dysarthric and Elderly Speaker Adaptation
Jul 08, 2024



The application of data-intensive automatic speech recognition (ASR) technologies to dysarthric and elderly adult speech is confronted by their mismatch against healthy and nonaged voices, data scarcity and large speaker-level variability. To this end, this paper proposes two novel data-efficient methods to learn homogeneous dysarthric and elderly speaker-level features for rapid, on-the-fly test-time adaptation of DNN/TDNN and Conformer ASR models. These include: 1) speaker-level variance-regularized spectral basis embedding (VR-SBE) features that exploit a special regularization term to enforce homogeneity of speaker features in adaptation; and 2) feature-based learning hidden unit contributions (f-LHUC) transforms that are conditioned on VR-SBE features. Experiments are conducted on four tasks across two languages: the English UASpeech and TORGO dysarthric speech datasets, the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora. The proposed on-the-fly speaker adaptation techniques consistently outperform baseline iVector and xVector adaptation by statistically significant word or character error rate reductions up to 5.32% absolute (18.57% relative) and batch-mode LHUC speaker adaptation by 2.24% absolute (9.20% relative), while operating with real-time factors speeding up to 33.6 times against xVectors during adaptation. The efficacy of the proposed adaptation techniques is demonstrated in a comparison against current ASR technologies including SSL pre-trained systems on UASpeech, where our best system produces a state-of-the-art WER of 23.33%. Analyses show VR-SBE features and f-LHUC transforms are insensitive to speaker-level data quantity in testtime adaptation. T-SNE visualization reveals they have stronger speaker-level homogeneity than baseline iVectors, xVectors and batch-mode LHUC transforms.