 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime series forecasting with high stakes: A field study of the air cargo industry
Jul 29, 2024



Time series forecasting in the air cargo industry presents unique challenges due to volatile market dynamics and the significant impact of accurate forecasts on generated revenue. This paper explores a comprehensive approach to demand forecasting at the origin-destination (O\&D) level, focusing on the development and implementation of machine learning models in decision-making for the air cargo industry. We leverage a mixture of experts framework, combining statistical and advanced deep learning models to provide reliable forecasts for cargo demand over a six-month horizon. The results demonstrate that our approach outperforms industry benchmarks, offering actionable insights for cargo capacity allocation and strategic decision-making in the air cargo industry. While this work is applied in the airline industry, the methodology is broadly applicable to any field where forecast-based decision-making in a volatile environment is crucial.
Data-driven grapheme-to-phoneme representations for a lexicon-free text-to-speech
Jan 19, 2024Grapheme-to-Phoneme (G2P) is an essential first step in any modern, high-quality Text-to-Speech (TTS) system. Most of the current G2P systems rely on carefully hand-crafted lexicons developed by experts. This poses a two-fold problem. Firstly, the lexicons are generated using a fixed phoneme set, usually, ARPABET or IPA, which might not be the most optimal way to represent phonemes for all languages. Secondly, the man-hours required to produce such an expert lexicon are very high. In this paper, we eliminate both of these issues by using recent advances in self-supervised learning to obtain data-driven phoneme representations instead of fixed representations. We compare our lexicon-free approach against strong baselines that utilize a well-crafted lexicon. Furthermore, we show that our data-driven lexicon-free method performs as good or even marginally better than the conventional rule-based or lexicon-based neural G2Ps in terms of Mean Opinion Score (MOS) while using no prior language lexicon or phoneme set, i.e. no linguistic expertise.
Distribution Shift in Airline Customer Behavior during COVID-19
Dec 23, 2021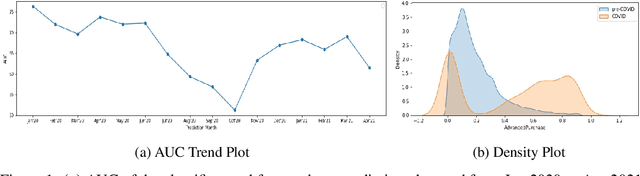

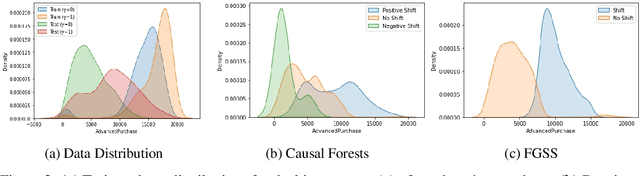
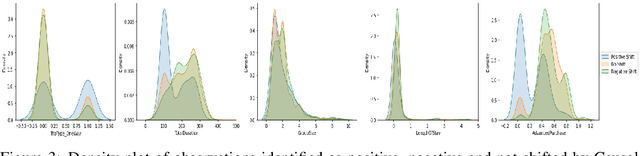
Traditional AI approaches in customized (personalized) contextual pricing applications assume that the data distribution at the time of online pricing is similar to that observed during training. However, this assumption may be violated in practice because of the dynamic nature of customer buying patterns, particularly due to unanticipated system shocks such as COVID-19. We study the changes in customer behavior for a major airline during the COVID-19 pandemic by framing it as a covariate shift and concept drift detection problem. We identify which customers changed their travel and purchase behavior and the attributes affecting that change using (i) Fast Generalized Subset Scanning and (ii) Causal Forests. In our experiments with simulated and real-world data, we present how these two techniques can be used through qualitative analysis.
Semi-supervised transfer learning for language expansion of end-to-end speech recognition models to low-resource languages
Nov 19, 2021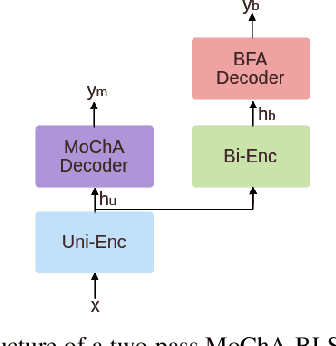
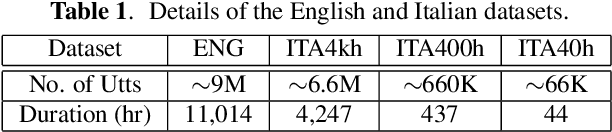
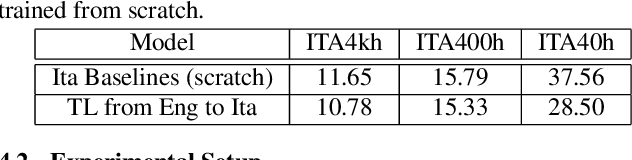
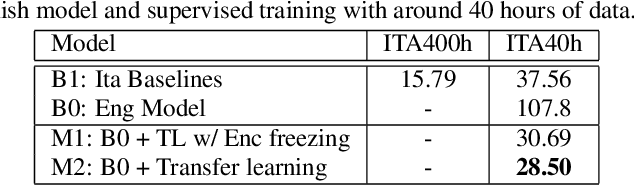
In this paper, we propose a three-stage training methodology to improve the speech recognition accuracy of low-resource languages. We explore and propose an effective combination of techniques such as transfer learning, encoder freezing, data augmentation using Text-To-Speech (TTS), and Semi-Supervised Learning (SSL). To improve the accuracy of a low-resource Italian ASR, we leverage a well-trained English model, unlabeled text corpus, and unlabeled audio corpus using transfer learning, TTS augmentation, and SSL respectively. In the first stage, we use transfer learning from a well-trained English model. This primarily helps in learning the acoustic information from a resource-rich language. This stage achieves around 24% relative Word Error Rate (WER) reduction over the baseline. In stage two, We utilize unlabeled text data via TTS data-augmentation to incorporate language information into the model. We also explore freezing the acoustic encoder at this stage. TTS data augmentation helps us further reduce the WER by ~ 21% relatively. Finally, In stage three we reduce the WER by another 4% relative by using SSL from unlabeled audio data. Overall, our two-pass speech recognition system with a Monotonic Chunkwise Attention (MoChA) in the first pass and a full-attention in the second pass achieves a WER reduction of ~ 42% relative to the baseline.
A comparison of streaming models and data augmentation methods for robust speech recognition
Nov 19, 2021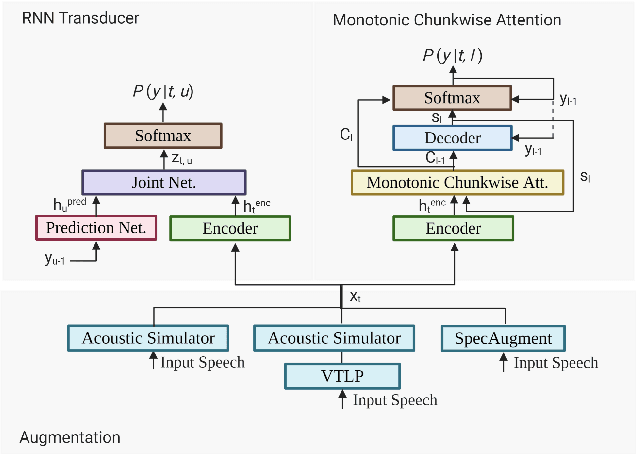

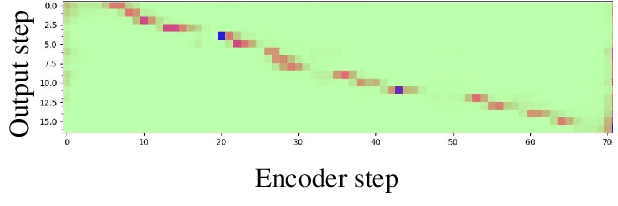

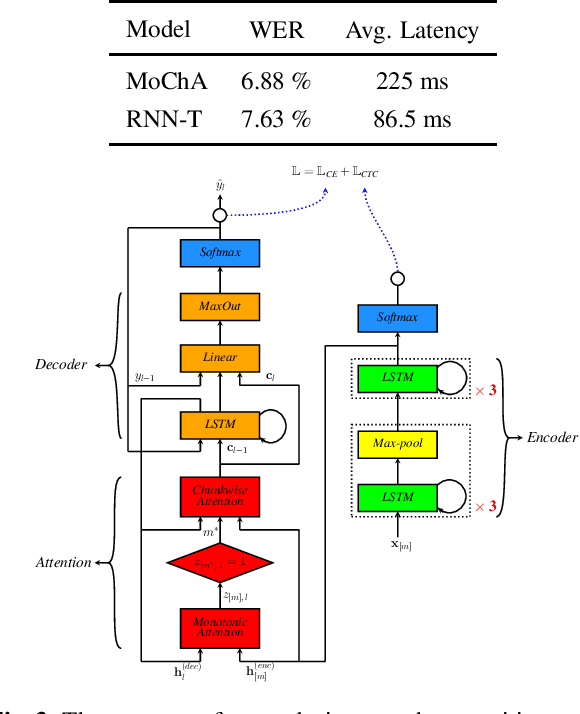
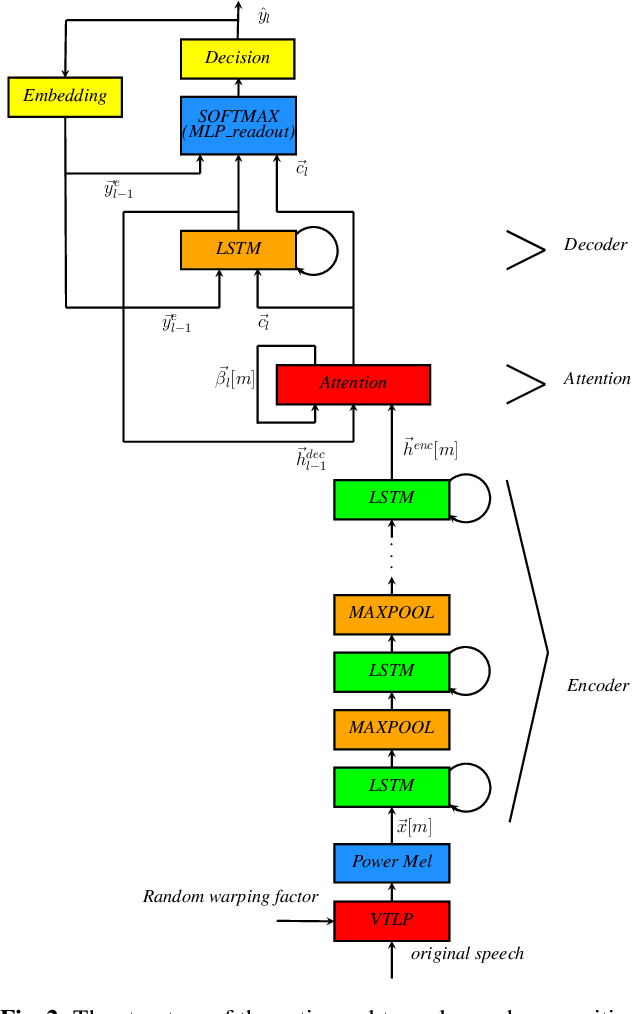
In this paper, we present a comparative study on the robustness of two different online streaming speech recognition models: Monotonic Chunkwise Attention (MoChA) and Recurrent Neural Network-Transducer (RNN-T). We explore three recently proposed data augmentation techniques, namely, multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment. Experimental results show that unidirectional models are in general more sensitive to noisy examples in the training set. It is observed that the final performance of the model depends on the proportion of training examples processed by data augmentation techniques. MoChA models generally perform better than RNN-T models. However, we observe that training of MoChA models seems to be more sensitive to various factors such as the characteristics of training sets and the incorporation of additional augmentations techniques. On the other hand, RNN-T models perform better than MoChA models in terms of latency, inference time, and the stability of training. Additionally, RNN-T models are generally more robust against noise and reverberation. All these advantages make RNN-T models a better choice for streaming on-device speech recognition compared to MoChA models.
Streaming end-to-end speech recognition with jointly trained neural feature enhancement
May 04, 2021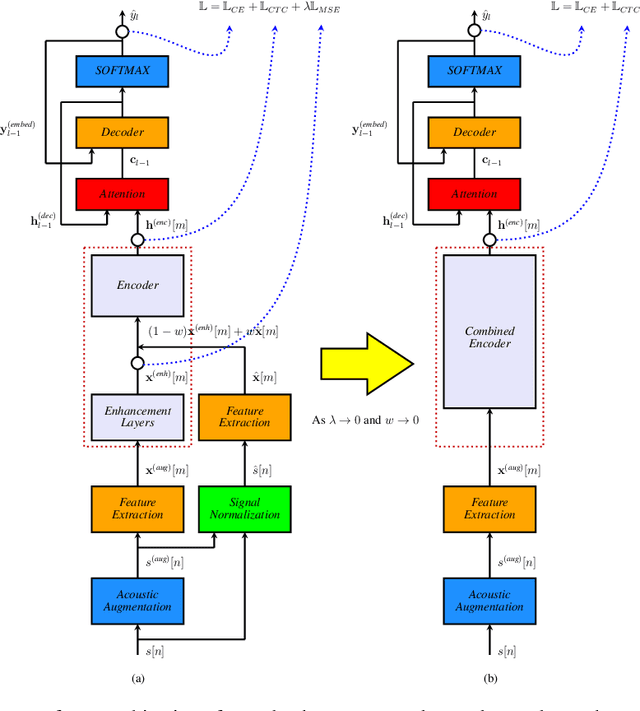
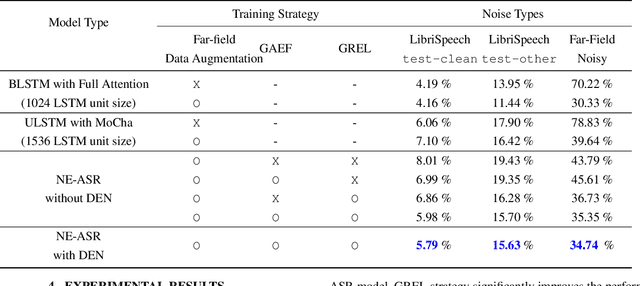
In this paper, we present a streaming end-to-end speech recognition model based on Monotonic Chunkwise Attention (MoCha) jointly trained with enhancement layers. Even though the MoCha attention enables streaming speech recognition with recognition accuracy comparable to a full attention-based approach, training this model is sensitive to various factors such as the difficulty of training examples, hyper-parameters, and so on. Because of these issues, speech recognition accuracy of a MoCha-based model for clean speech drops significantly when a multi-style training approach is applied. Inspired by Curriculum Learning [1], we introduce two training strategies: Gradual Application of Enhanced Features (GAEF) and Gradual Reduction of Enhanced Loss (GREL). With GAEF, the model is initially trained using clean features. Subsequently, the portion of outputs from the enhancement layers gradually increases. With GREL, the portion of the Mean Squared Error (MSE) loss for the enhanced output gradually reduces as training proceeds. In experimental results on the LibriSpeech corpus and noisy far-field test sets, the proposed model with GAEF-GREL training strategies shows significantly better results than the conventional multi-style training approach.
A review of on-device fully neural end-to-end automatic speech recognition algorithms
Dec 19, 2020
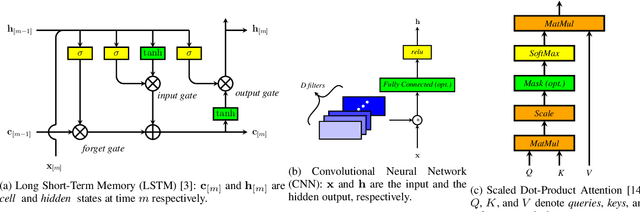
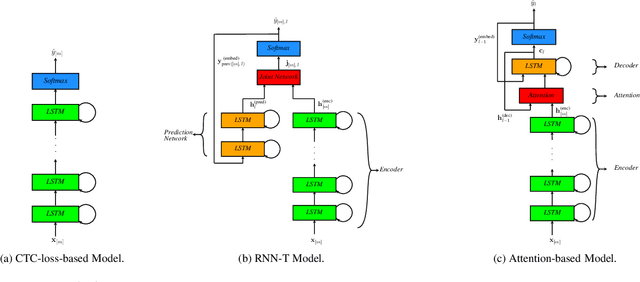
In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.
Improved Multi-Stage Training of Online Attention-based Encoder-Decoder Models
Dec 28, 2019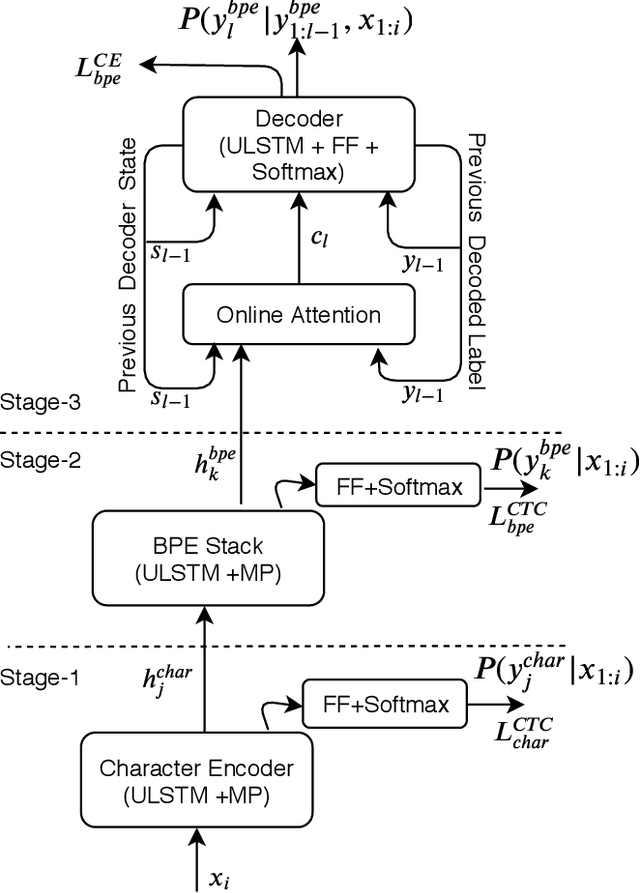

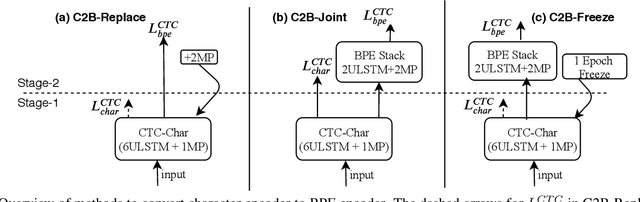
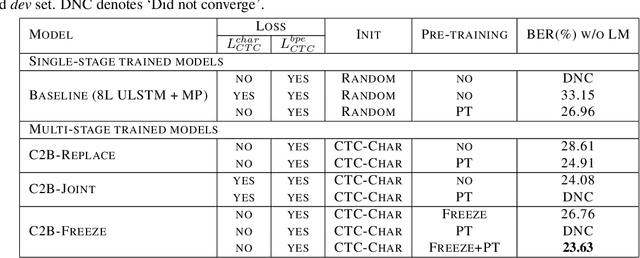
In this paper, we propose a refined multi-stage multi-task training strategy to improve the performance of online attention-based encoder-decoder (AED) models. A three-stage training based on three levels of architectural granularity namely, character encoder, byte pair encoding (BPE) based encoder, and attention decoder, is proposed. Also, multi-task learning based on two-levels of linguistic granularity namely, character and BPE, is used. We explore different pre-training strategies for the encoders including transfer learning from a bidirectional encoder. Our encoder-decoder models with online attention show 35% and 10% relative improvement over their baselines for smaller and bigger models, respectively. Our models achieve a word error rate (WER) of 5.04% and 4.48% on the Librispeech test-clean data for the smaller and bigger models respectively after fusion with long short-term memory (LSTM) based external language model (LM).
end-to-end training of a large vocabulary end-to-end speech recognition system
Dec 22, 2019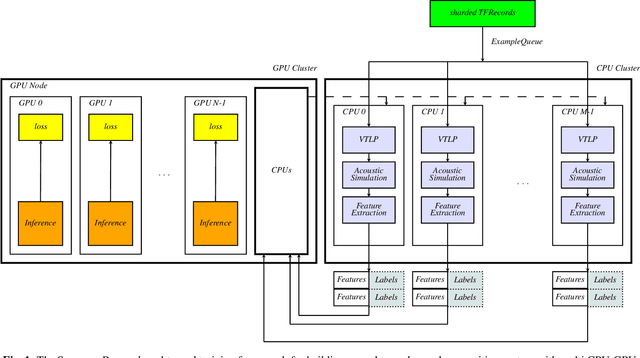
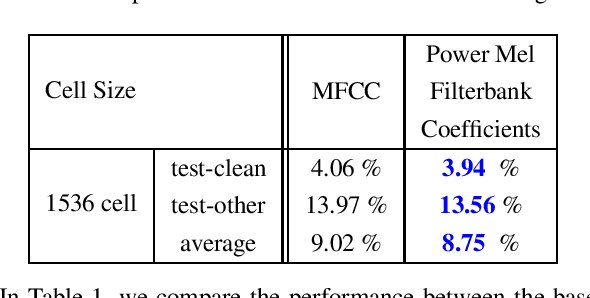
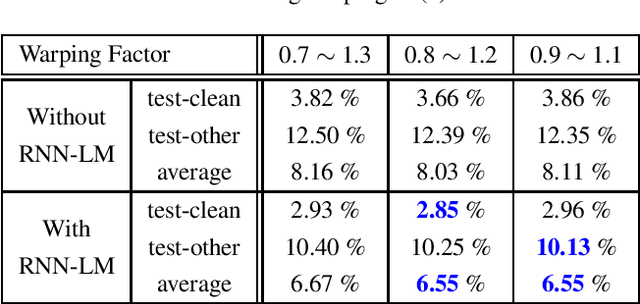
In this paper, we present an end-to-end training framework for building state-of-the-art end-to-end speech recognition systems. Our training system utilizes a cluster of Central Processing Units(CPUs) and Graphics Processing Units (GPUs). The entire data reading, large scale data augmentation, neural network parameter updates are all performed "on-the-fly". We use vocal tract length perturbation [1] and an acoustic simulator [2] for data augmentation. The processed features and labels are sent to the GPU cluster. The Horovod allreduce approach is employed to train neural network parameters. We evaluated the effectiveness of our system on the standard Librispeech corpus [3] and the 10,000-hr anonymized Bixby English dataset. Our end-to-end speech recognition system built using this training infrastructure showed a 2.44 % WER on test-clean of the LibriSpeech test set after applying shallow fusion with a Transformer language model (LM). For the proprietary English Bixby open domain test set, we obtained a WER of 7.92 % using a Bidirectional Full Attention (BFA) end-to-end model after applying shallow fusion with an RNN-LM. When the monotonic chunckwise attention (MoCha) based approach is employed for streaming speech recognition, we obtained a WER of 9.95 % on the same Bixby open domain test set.