 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Flip: Synthetic OOD Generation for Robust Refusal in Embodied Question Answering and Spatial Localization
Jun 15, 2026Detecting unanswerable user queries remains essential for the reliable deployment of real-world embodied agents. However, modern vision-language models (VLMs) often generate overly confident answers even when the available visual memory cannot support the query. Such overconfidence poses various task-dependent risks. The agent may provide misleading information to the user in Embodied Question Answering and select an arbitrary coordinate and physically guide the user there in spatial reasoning for navigation. Despite these high stakes, only a few prior studies directly address when and how an embodied VLM should respond with "I do not know." This work proposes Semantic Flip, a simple yet effective framework that synthesizes auxiliary out-of-distribution (OOD) samples for embodied refusal without requiring external OOD annotations. The key idea is to independently transform the query and video memory to construct auxiliary OOD pairs that lack sufficient visual grounding. These synthesized pairs enable training a lightweight rejection module on top of a frozen pretrained VLM. The module attaches to any existing VLM-based pipeline without retraining the underlying model. Across two complementary benchmarks, Semantic Flip consistently outperforms strong prompting baselines. This work also introduces SpaceReject, a new refusal benchmark for spatial localization with deliberately unanswerable queries over long video memory, where Semantic Flip achieves an $F_1$ score of 0.9559. The source codes and datasets are publicly available at https://github.com/ndb796/SemanticFlip.
Binary Tracking for Spatial QA and Navigation with Open Vision-Language Models
Jun 15, 2026This work addresses spatial question answering for service robots traversing long egocentric routes. Given a query such as "where can I find a dry cleaner on the way back home?", the system returns a metric coordinate that downstream navigation components can act on. Prior Spatial Question Answering approaches leverage retrieval-augmented agents built on closed-source models such as GPT-4o for path exploration. However, robots operating in the real world often cannot reliably depend on online closed-source models due to network instability, communication latency, and deployment cost. It creates a need for open-source based Spatial Question Answering approaches that can run onboard the robot, yet prior research in this direction remains limited. This work proposes BinTrack, a simple yet effective, fully open-source spatial-localization agent that leverages the temporal ordering of a robot's trajectory. BinTrack performs a binary search over the trajectory segments between two anchor landmarks identified from a query. It improves overall accuracy by up to 22.8% over other open-source implementations and even matches the reported closed-source model result on the global category of the SpaceLocQA benchmark, the most challenging setting that has so far required strong reasoning agents such as GPT-4o. Furthermore, its optimized inference strategy consistently yields more than a 1.5x inference speedup over previous approaches. Finally, this work releases GangnamLoop, a novel and practical multi-trip outdoor benchmark collected by deploying a real quadruped robot on public streets with the anonymization policy. It revisits the same locations under different outdoor conditions and pairs the robot's low viewpoint with the human owner's. The source codes and datasets are publicly available at https://github.com/ndb796/BinaryTracking
Natural Functional Gradients for Smooth Trajectory Optimization
May 27, 2026Generating collision-free and smooth motions remains a central challenge in robotic manipulation, particularly in cluttered environments and narrow passages where feasible regions are highly constrained and fragmented. We propose a trajectory optimization framework that performs geometry-aware updates directly in function space using natural functional gradients. The method optimizes a Gaussian-smoothed surrogate objective that regularizes the optimization landscape through smooth trajectory perturbations while preserving trajectory-level structure. Because the updates are defined intrinsically in function space, trajectory regularity can be controlled independently of a particular time discretization. We derive a practical Monte-Carlo estimator of the natural functional gradient that requires only black-box trajectory evaluations, making the method applicable when analytic gradients are unavailable or unreliable due to collision checking and contact-rich simulation. Experiments on constrained robotic manipulation tasks demonstrate that the proposed method improves trajectory feasibility and produces smoother motions than representative planning and trajectory optimization baselines in environments with narrow geometric clearances. Additional results, videos, and implementation details are available at the project page: https://kisangpark.github.io/natural-functional-gradient/
LEGO: Latent-space Exploration for Geometry-aware Optimization of Humanoid Kinematic Design
Apr 09, 2026Designing robot morphologies and kinematics has traditionally relied on human intuition, with little systematic foundation. Motion-design co-optimization offers a promising path toward automation, but two major challenges remain: (i) the vast, unstructured design space and (ii) the difficulty of constructing task-specific loss functions. We propose a new paradigm that minimizes human involvement by (i) learning the design search space from existing mechanical designs, rather than hand-crafting it, and (ii) defining the loss directly from human motion data via motion retargeting and Procrustes analysis. Using screw-theory-based joint axis representation and isometric manifold learning, we construct a compact, geometry-preserving latent space of humanoid upper body designs in which optimization is tractable. We then solve design optimization in this latent space using gradient-free optimization. Our approach establishes a principled framework for data-driven robot design and demonstrates that leveraging existing designs and human motion can effectively guide the automated discovery of novel robot design.
Enhancing Document-Level Machine Translation via Filtered Synthetic Corpora and Two-Stage LLM Adaptation
Mar 23, 2026In Machine Translation, Large Language Models (LLMs) have generally underperformed compared to conventional encoder-decoder systems and thus see limited adoption. However, LLMs excel at modeling contextual information, making them a natural fit for document-level translation tasks where coherence across sentences is crucial. Despite this potential, document-level MT with LLMs faces two key challenges: (1) the scarcity of large-scale, high-quality document-level parallel data; and (2) the propensity of LLMs to introduce hallucinations and omissions during generation. To address these challenges, we propose a two-stage fine-tuning strategy leveraging LLM-augmented document-level data. First, we augment data by converting summarization data into document-level parallel data using a LLM, and then filter it using multiple metrics, leveraging sacreBLEU, COMET, and LaBSE-based cosine similarity-to improve data quality. Finally, we employ a two-stage fine-tuning strategy: first fine-tuning on the abundant sentence-level MT resources, and then on the filtered document-level corpus.
SurrogateSHAP: Training-Free Contributor Attribution for Text-to-Image (T2I) Models
Jan 29, 2026As Text-to-Image (T2I) diffusion models are increasingly used in real-world creative workflows, a principled framework for valuing contributors who provide a collection of data is essential for fair compensation and sustainable data marketplaces. While the Shapley value offers a theoretically grounded approach to attribution, it faces a dual computational bottleneck: (i) the prohibitive cost of exhaustive model retraining for each sampled subset of players (i.e., data contributors) and (ii) the combinatorial number of subsets needed to estimate marginal contributions due to contributor interactions. To this end, we propose SurrogateSHAP, a retraining-free framework that approximates the expensive retraining game through inference from a pretrained model. To further improve efficiency, we employ a gradient-boosted tree to approximate the utility function and derive Shapley values analytically from the tree-based model. We evaluate SurrogateSHAP across three diverse attribution tasks: (i) image quality for DDPM-CFG on CIFAR-20, (ii) aesthetics for Stable Diffusion on Post-Impressionist artworks, and (iii) product diversity for FLUX.1 on Fashion-Product data. Across settings, SurrogateSHAP outperforms prior methods while substantially reducing computational overhead, consistently identifying influential contributors across multiple utility metrics. Finally, we demonstrate that SurrogateSHAP effectively localizes data sources responsible for spurious correlations in clinical images, providing a scalable path toward auditing safety-critical generative models.
An Effective Energy Mask-based Adversarial Evasion Attacks against Misclassification in Speaker Recognition Systems
Jan 29, 2026Evasion attacks pose significant threats to AI systems, exploiting vulnerabilities in machine learning models to bypass detection mechanisms. The widespread use of voice data, including deepfakes, in promising future industries is currently hindered by insufficient legal frameworks. Adversarial attack methods have emerged as the most effective countermeasure against the indiscriminate use of such data. This research introduces masked energy perturbation (MEP), a novel approach using power spectrum for energy masking of original voice data. MEP applies masking to small energy regions in the frequency domain before generating adversarial perturbations, targeting areas less noticeable to the human auditory model. The study primarily employs advanced speaker recognition models, including ECAPA-TDNN and ResNet34, which have shown remarkable performance in speaker verification tasks. The proposed MEP method demonstrated strong performance in both audio quality and evasion effectiveness. The energy masking approach effectively minimizes the perceptual evaluation of speech quality (PESQ) degradation, indicating that minimal perceptual distortion occurs to the human listener despite the adversarial perturbations. Specifically, in the PESQ evaluation, the relative performance of the MEP method was 26.68% when compared to the fast gradient sign method (FGSM) and iterative FGSM.
OleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
Sep 04, 2025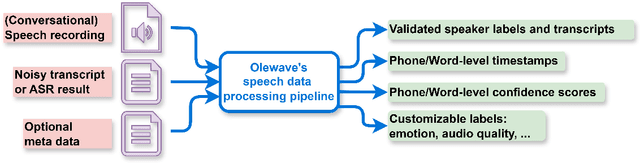
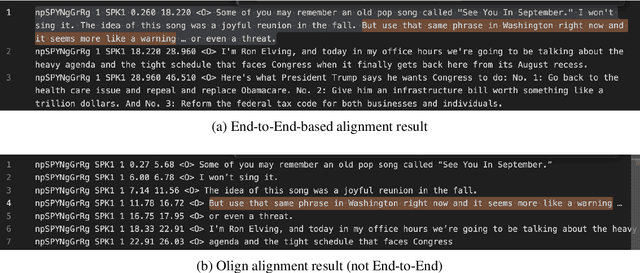
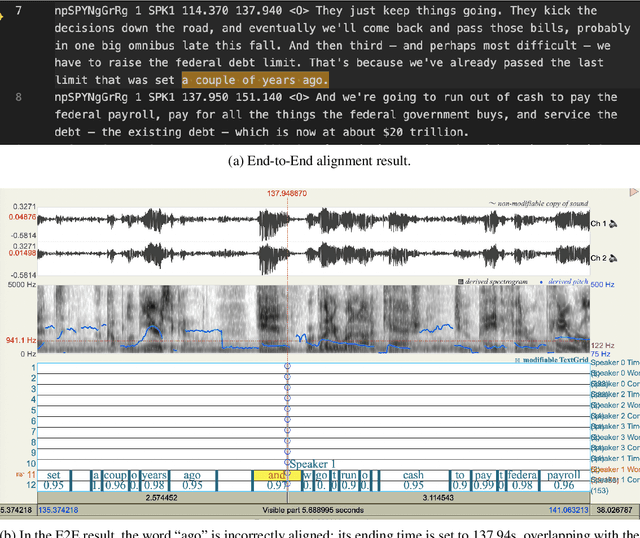
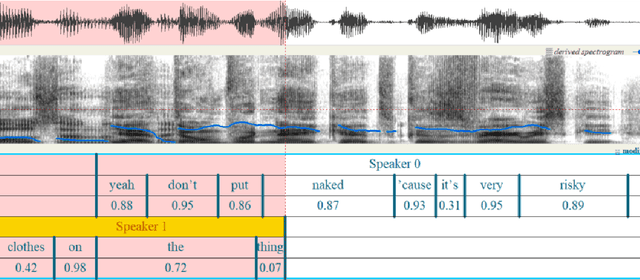
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.
Graph Spectral Filtering with Chebyshev Interpolation for Recommendation
May 01, 2025Graph convolutional networks have recently gained prominence in collaborative filtering (CF) for recommendations. However, we identify potential bottlenecks in two foundational components. First, the embedding layer leads to a latent space with limited capacity, overlooking locally observed but potentially valuable preference patterns. Also, the widely-used neighborhood aggregation is limited in its ability to leverage diverse preference patterns in a fine-grained manner. Building on spectral graph theory, we reveal that these limitations stem from graph filtering with a cut-off in the frequency spectrum and a restricted linear form. To address these issues, we introduce ChebyCF, a CF framework based on graph spectral filtering. Instead of a learned embedding, it takes a user's raw interaction history to utilize the full spectrum of signals contained in it. Also, it adopts Chebyshev interpolation to effectively approximate a flexible non-linear graph filter, and further enhances it by using an additional ideal pass filter and degree-based normalization. Through extensive experiments, we verify that ChebyCF overcomes the aforementioned bottlenecks and achieves state-of-the-art performance across multiple benchmarks and reasonably fast inference. Our code is available at https://github.com/chanwoo0806/ChebyCF.
HyperFlow: Gradient-Free Emulation of Few-Shot Fine-Tuning
Apr 21, 2025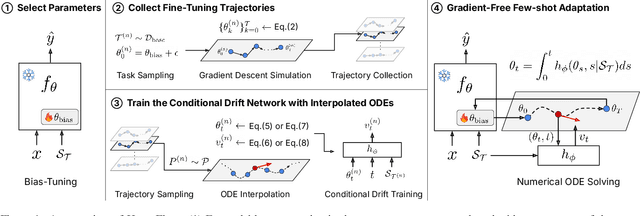



While test-time fine-tuning is beneficial in few-shot learning, the need for multiple backpropagation steps can be prohibitively expensive in real-time or low-resource scenarios. To address this limitation, we propose an approach that emulates gradient descent without computing gradients, enabling efficient test-time adaptation. Specifically, we formulate gradient descent as an Euler discretization of an ordinary differential equation (ODE) and train an auxiliary network to predict the task-conditional drift using only the few-shot support set. The adaptation then reduces to a simple numerical integration (e.g., via the Euler method), which requires only a few forward passes of the auxiliary network -- no gradients or forward passes of the target model are needed. In experiments on cross-domain few-shot classification using the Meta-Dataset and CDFSL benchmarks, our method significantly improves out-of-domain performance over the non-fine-tuned baseline while incurring only 6\% of the memory cost and 0.02\% of the computation time of standard fine-tuning, thus establishing a practical middle ground between direct transfer and fully fine-tuned approaches.