 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021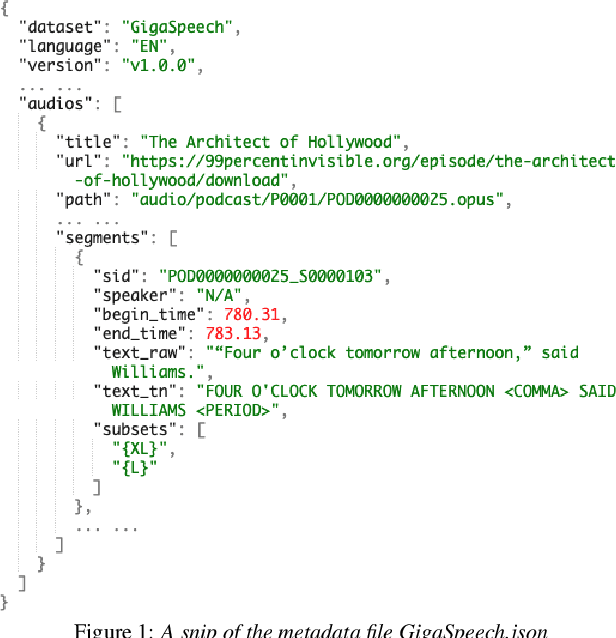
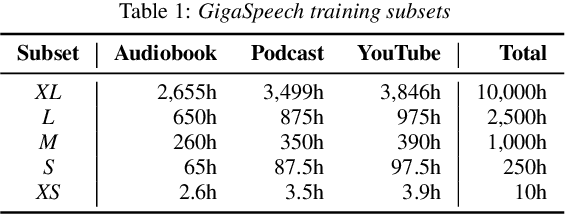
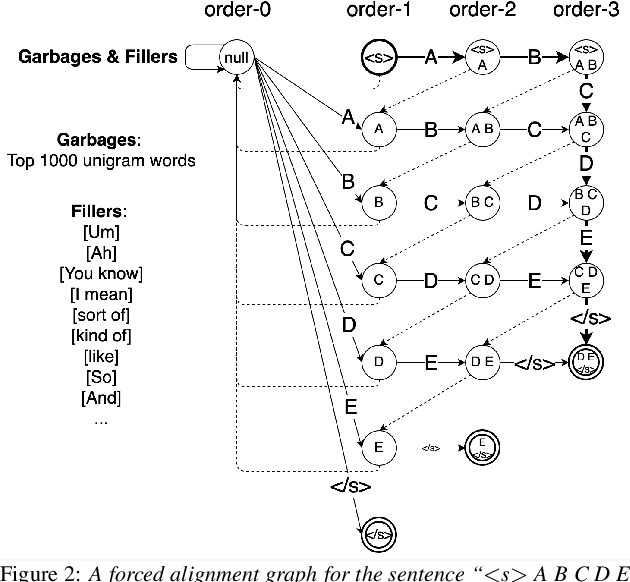
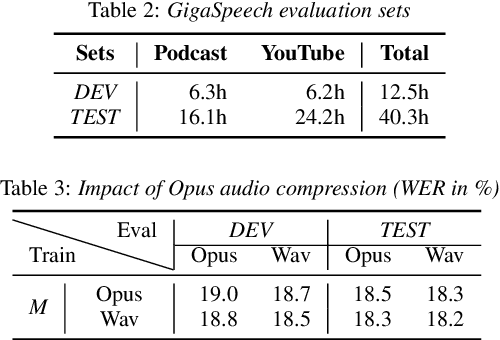
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Adversarial Attacks and Defenses for Speech Recognition Systems
Mar 31, 2021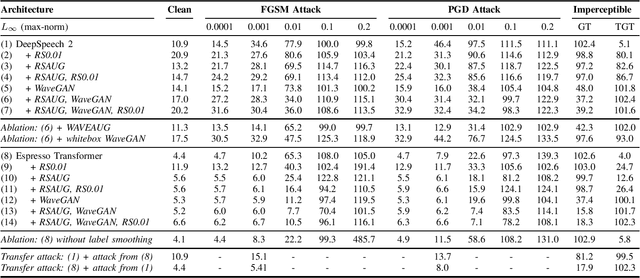
The ubiquitous presence of machine learning systems in our lives necessitates research into their vulnerabilities and appropriate countermeasures. In particular, we investigate the effectiveness of adversarial attacks and defenses against automatic speech recognition (ASR) systems. We select two ASR models - a thoroughly studied DeepSpeech model and a more recent Espresso framework Transformer encoder-decoder model. We investigate two threat models: a denial-of-service scenario where fast gradient-sign method (FGSM) or weak projected gradient descent (PGD) attacks are used to degrade the model's word error rate (WER); and a targeted scenario where a more potent imperceptible attack forces the system to recognize a specific phrase. We find that the attack transferability across the investigated ASR systems is limited. To defend the model, we use two preprocessing defenses: randomized smoothing and WaveGAN-based vocoder, and find that they significantly improve the model's adversarial robustness. We show that a WaveGAN vocoder can be a useful countermeasure to adversarial attacks on ASR systems - even when it is jointly attacked with the ASR, the target phrases' word error rate is high.
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020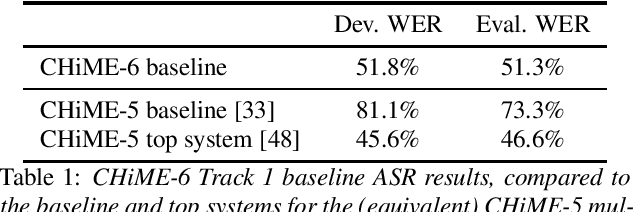

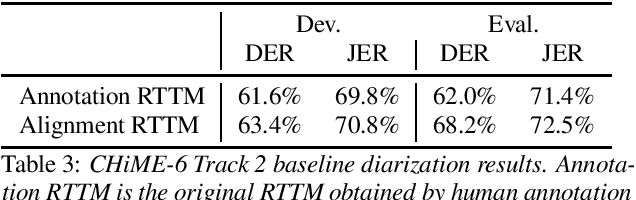

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
Multi-task self-supervised learning for Robust Speech Recognition
Jan 25, 2020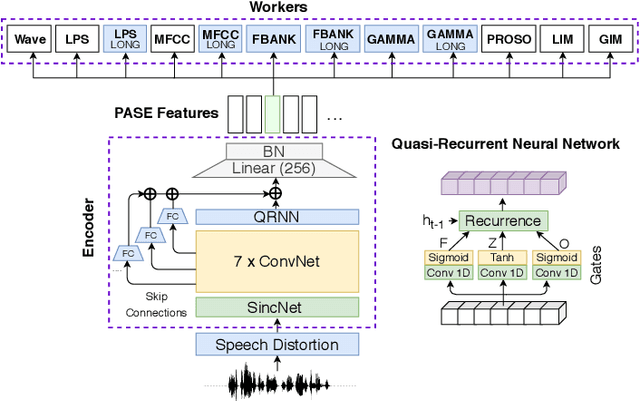
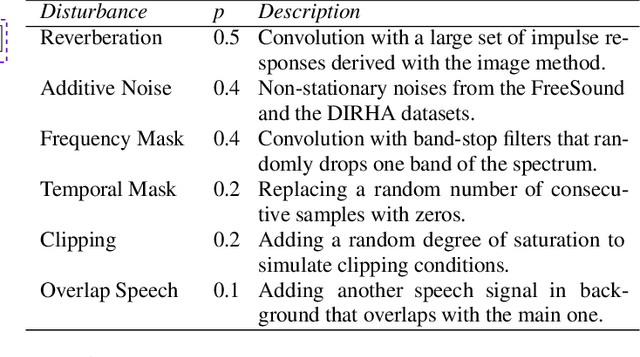
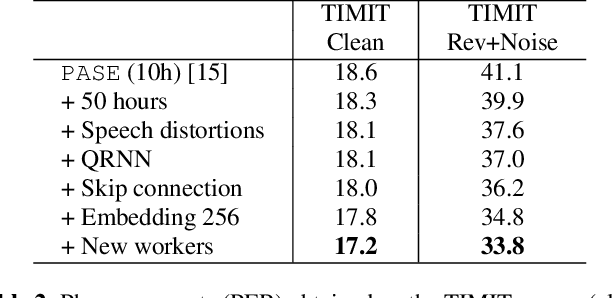
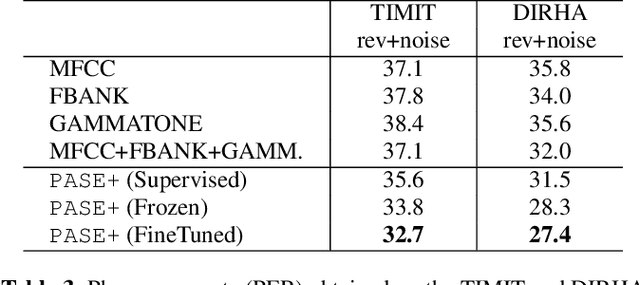
Despite the growing interest in unsupervised learning, extracting meaningful knowledge from unlabelled audio remains an open challenge. To take a step in this direction, we recently proposed a problem-agnostic speech encoder (PASE), that combines a convolutional encoder followed by multiple neural networks, called workers, tasked to solve self-supervised problems (i.e., ones that do not require manual annotations as ground truth). PASE was shown to capture relevant speech information, including speaker voice-print and phonemes. This paper proposes PASE+, an improved version of PASE for robust speech recognition in noisy and reverberant environments. To this end, we employ an online speech distortion module, that contaminates the input signals with a variety of random disturbances. We then propose a revised encoder that better learns short- and long-term speech dynamics with an efficient combination of recurrent and convolutional networks. Finally, we refine the set of workers used in self-supervision to encourage better cooperation. Results on TIMIT, DIRHA and CHiME-5 show that PASE+ significantly outperforms both the previous version of PASE as well as common acoustic features. Interestingly, PASE+ learns transferable representations suitable for highly mismatched acoustic conditions.
Induced Inflection-Set Keyword Search in Speech
Oct 27, 2019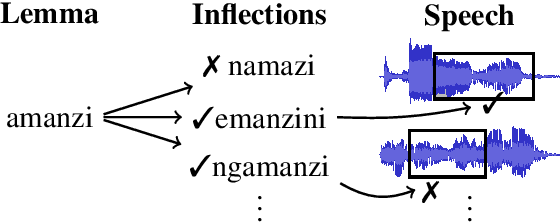
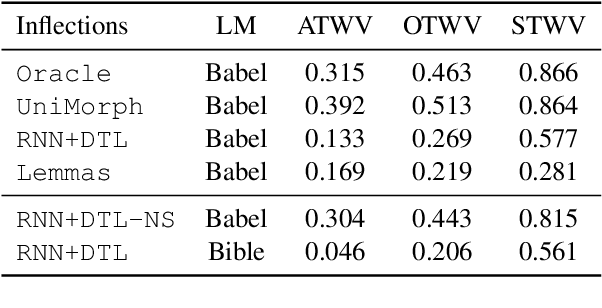
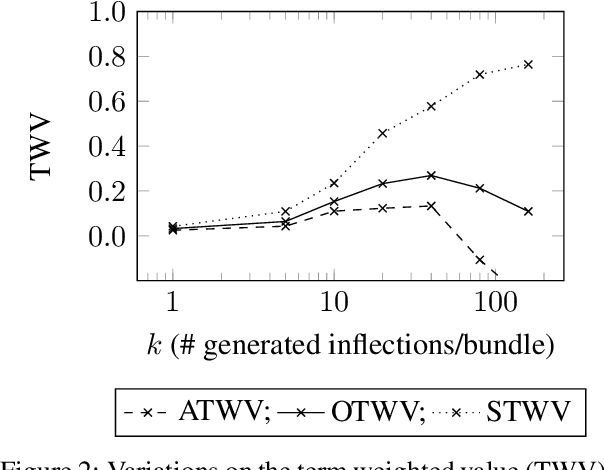
We investigate the problem of searching for a lexeme-set in speech by searching for its inflectional variants. Experimental results indicate how lexeme-set search performance changes with the number of hypothesized inflections, while ablation experiments highlight the relative importance of different components in the lexeme-set search pipeline. We provide a recipe and evaluation set for the community to use as an extrinsic measure of the performance of inflection generation approaches.
DiPCo -- Dinner Party Corpus
Sep 30, 2019
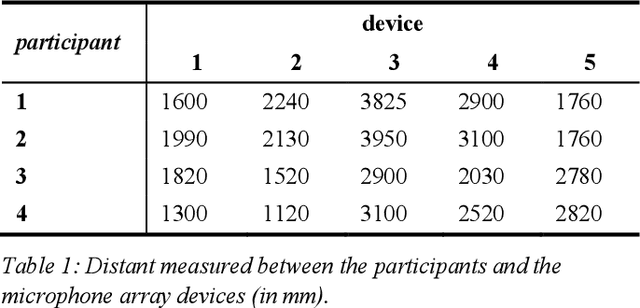

We present a speech data corpus that simulates a "dinner party" scenario taking place in an everyday home environment. The corpus was created by recording multiple groups of four Amazon employee volunteers having a natural conversation in English around a dining table. The participants were recorded by a single-channel close-talk microphone and by five far-field 7-microphone array devices positioned at different locations in the recording room. The dataset contains the audio recordings and human labeled transcripts of a total of 10 sessions with a duration between 15 and 45 minutes. The corpus was created to advance in the field of noise robust and distant speech processing and is intended to serve as a public research and benchmarking data set.
Low-Resource Contextual Topic Identification on Speech
Sep 28, 2018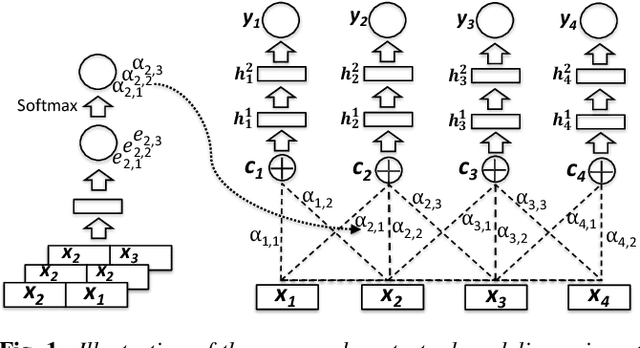

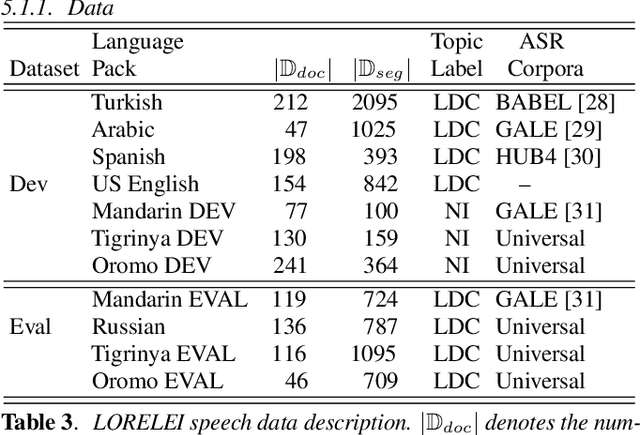
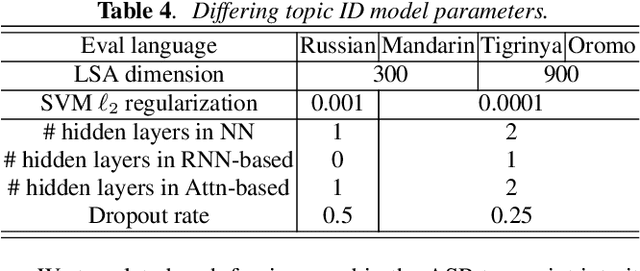
In topic identification (topic ID) on real-world unstructured audio, an audio instance of variable topic shifts is first broken into sequential segments, and each segment is independently classified. We first present a general purpose method for topic ID on spoken segments in low-resource languages, using a cascade of universal acoustic modeling, translation lexicons to English, and English-language topic classification. Next, instead of classifying each segment independently, we demonstrate that exploring the contextual dependencies across sequential segments can provide large improvements. In particular, we propose an attention-based contextual model which is able to leverage the contexts in a selective manner. We test both our contextual and non-contextual models on four LORELEI languages, and on all but one our attention-based contextual model significantly outperforms the context-independent models.
Automatic Speech Recognition and Topic Identification for Almost-Zero-Resource Languages
Jun 18, 2018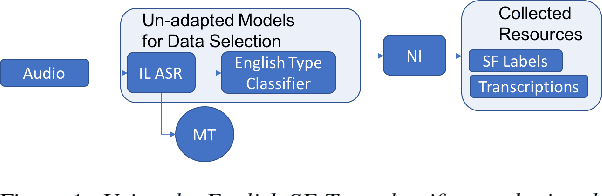
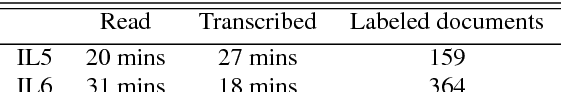
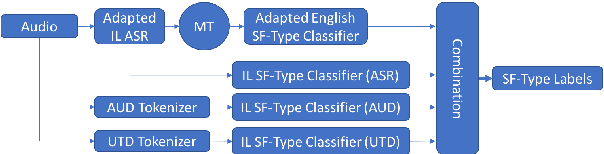
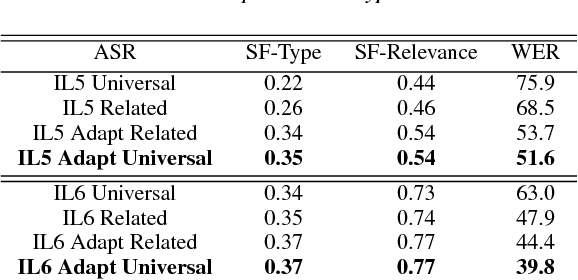
Automatic speech recognition (ASR) systems often need to be developed for extremely low-resource languages to serve end-uses such as audio content categorization and search. While universal phone recognition is natural to consider when no transcribed speech is available to train an ASR system in a language, adapting universal phone models using very small amounts (minutes rather than hours) of transcribed speech also needs to be studied, particularly with state-of-the-art DNN-based acoustic models. The DARPA LORELEI program provides a framework for such very-low-resource ASR studies, and provides an extrinsic metric for evaluating ASR performance in a humanitarian assistance, disaster relief setting. This paper presents our Kaldi-based systems for the program, which employ a universal phone modeling approach to ASR, and describes recipes for very rapid adaptation of this universal ASR system. The results we obtain significantly outperform results obtained by many competing approaches on the NIST LoReHLT 2017 Evaluation datasets.
The fifth 'CHiME' Speech Separation and Recognition Challenge: Dataset, task and baselines
Mar 28, 2018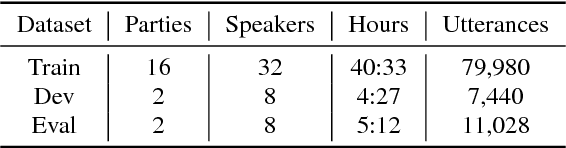

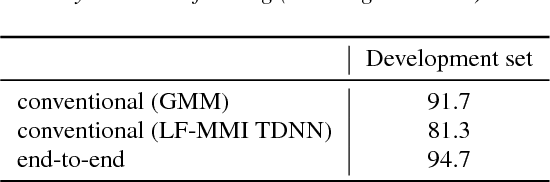
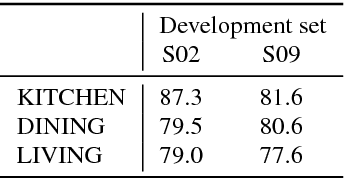
The CHiME challenge series aims to advance robust automatic speech recognition (ASR) technology by promoting research at the interface of speech and language processing, signal processing , and machine learning. This paper introduces the 5th CHiME Challenge, which considers the task of distant multi-microphone conversational ASR in real home environments. Speech material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech and recorded by 6 Kinect microphone arrays and 4 binaural microphone pairs. The challenge features a single-array track and a multiple-array track and, for each track, distinct rankings will be produced for systems focusing on robustness with respect to distant-microphone capture vs. systems attempting to address all aspects of the task including conversational language modeling. We discuss the rationale for the challenge and provide a detailed description of the data collection procedure, the task, and the baseline systems for array synchronization, speech enhancement, and conventional and end-to-end ASR.
Topic Identification for Speech without ASR
Jul 11, 2017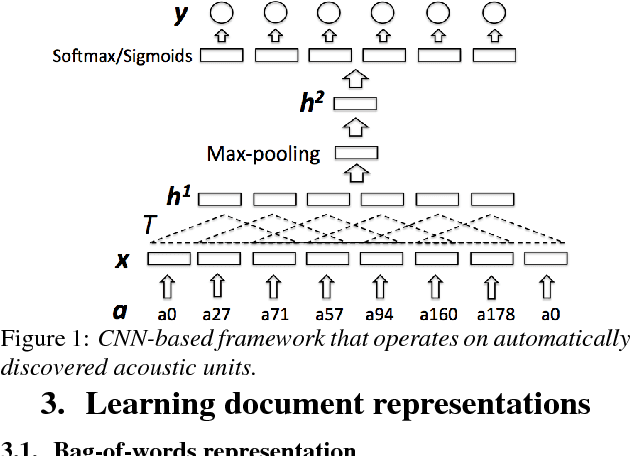
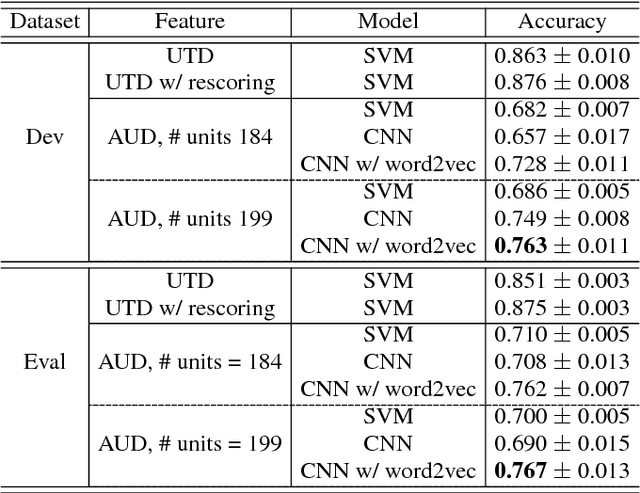
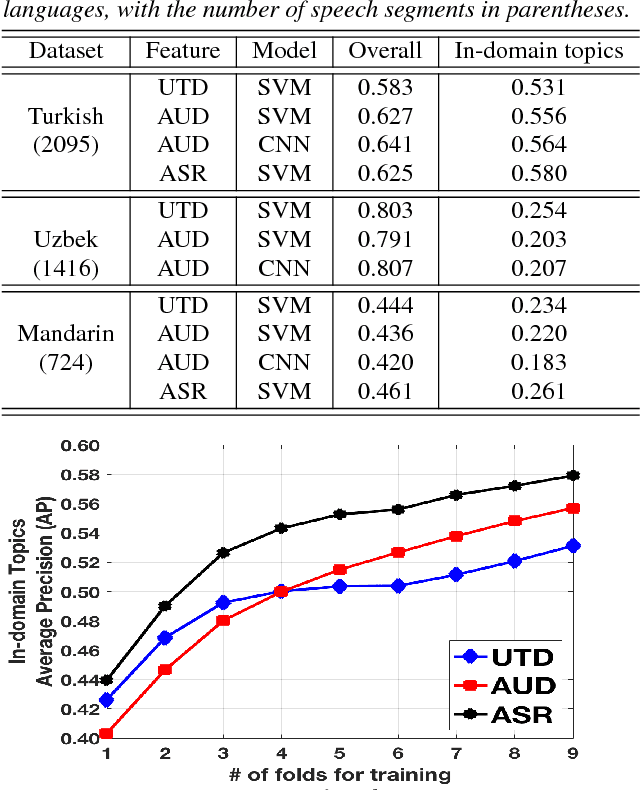
Modern topic identification (topic ID) systems for speech use automatic speech recognition (ASR) to produce speech transcripts, and perform supervised classification on such ASR outputs. However, under resource-limited conditions, the manually transcribed speech required to develop standard ASR systems can be severely limited or unavailable. In this paper, we investigate alternative unsupervised solutions to obtaining tokenizations of speech in terms of a vocabulary of automatically discovered word-like or phoneme-like units, without depending on the supervised training of ASR systems. Moreover, using automatic phoneme-like tokenizations, we demonstrate that a convolutional neural network based framework for learning spoken document representations provides competitive performance compared to a standard bag-of-words representation, as evidenced by comprehensive topic ID evaluations on both single-label and multi-label classification tasks.