 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
Jan 10, 2023

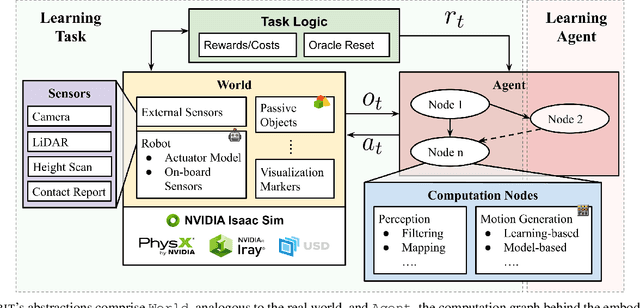

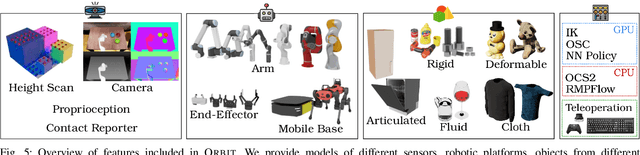
We present ORBIT, a unified and modular framework for robot learning powered by NVIDIA Isaac Sim. It offers a modular design to easily and efficiently create robotic environments with photo-realistic scenes and fast and accurate rigid and deformable body simulation. With ORBIT, we provide a suite of benchmark tasks of varying difficulty -- from single-stage cabinet opening and cloth folding to multi-stage tasks such as room reorganization. To support working with diverse observations and action spaces, we include fixed-arm and mobile manipulators with different physically-based sensors and motion generators. ORBIT allows training reinforcement learning policies and collecting large demonstration datasets from hand-crafted or expert solutions in a matter of minutes by leveraging GPU-based parallelization. In summary, we offer an open-sourced framework that readily comes with 16 robotic platforms, 4 sensor modalities, 10 motion generators, more than 20 benchmark tasks, and wrappers to 4 learning libraries. With this framework, we aim to support various research areas, including representation learning, reinforcement learning, imitation learning, and task and motion planning. We hope it helps establish interdisciplinary collaborations in these communities, and its modularity makes it easily extensible for more tasks and applications in the future. For videos, documentation, and code: https://isaac-orbit.github.io/.
Scale-free Photo-realistic Adversarial Pattern Attack
Aug 12, 2022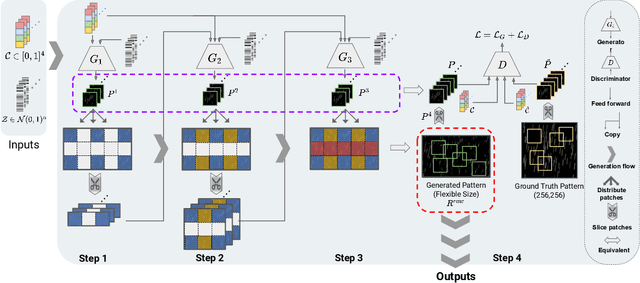
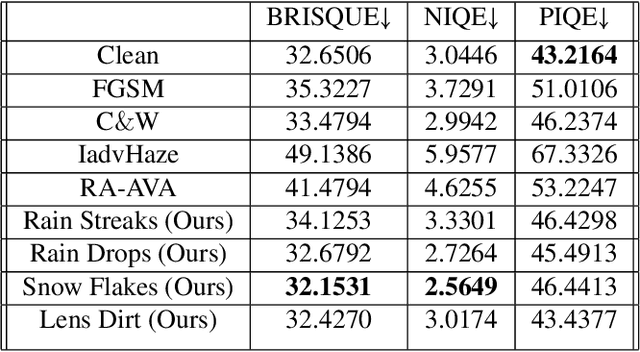
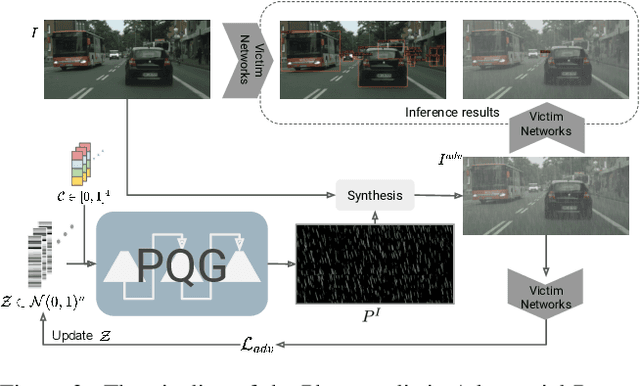
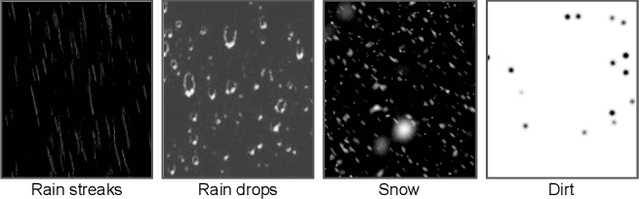
Traditional pixel-wise image attack algorithms suffer from poor robustness to defense algorithms, i.e., the attack strength degrades dramatically when defense algorithms are applied. Although Generative Adversarial Networks (GAN) can partially address this problem by synthesizing a more semantically meaningful texture pattern, the main limitation is that existing generators can only generate images of a specific scale. In this paper, we propose a scale-free generation-based attack algorithm that synthesizes semantically meaningful adversarial patterns globally to images with arbitrary scales. Our generative attack approach consistently outperforms the state-of-the-art methods on a wide range of attack settings, i.e. the proposed approach largely degraded the performance of various image classification, object detection, and instance segmentation algorithms under different advanced defense methods.
A Photo-Based Mobile Crowdsourcing Framework for Event Reporting
May 03, 2020
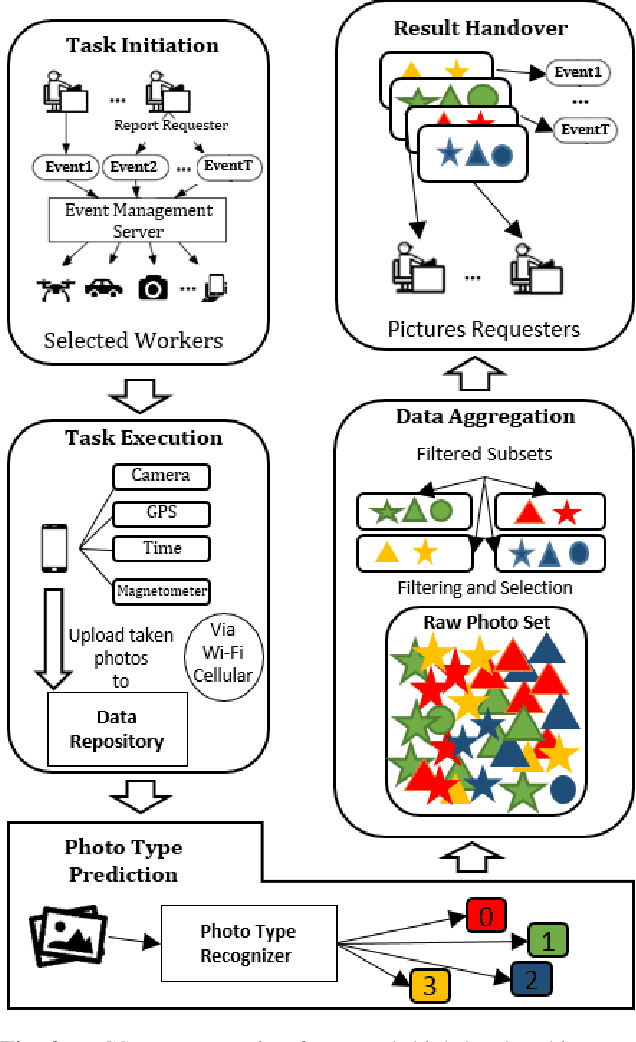
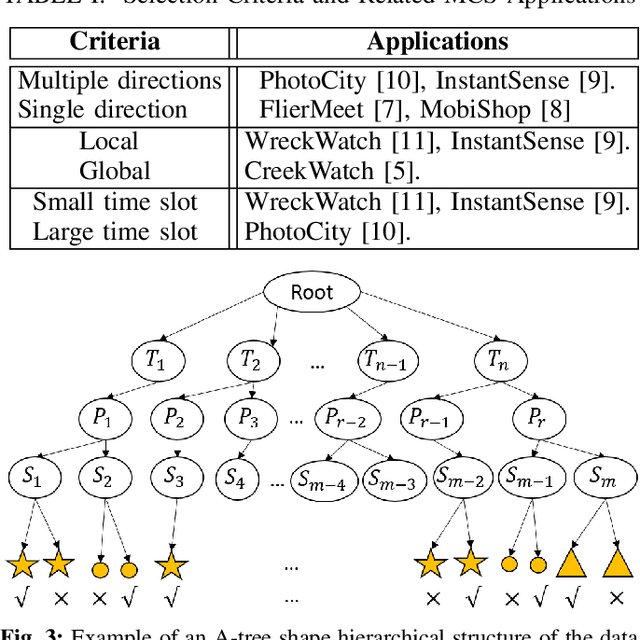
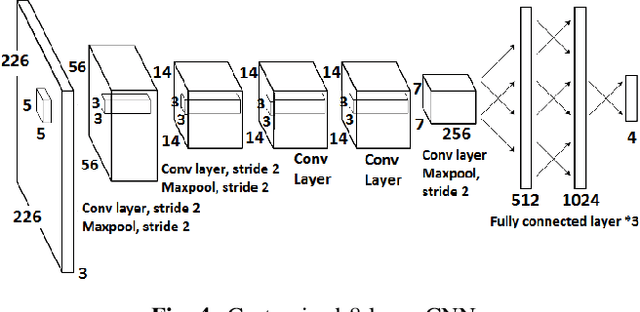
Mobile Crowdsourcing (MCS) photo-based is an arising field of interest and a trending topic in the domain of ubiquitous computing. It has recently drawn substantial attention of the smart cities and urban computing communities. In fact, the built-in cameras of mobile devices are becoming the most common way for visual logging techniques in our daily lives. MCS photo-based frameworks collect photos in a distributed way in which a large number of contributors upload photos whenever and wherever it is suitable. This inevitably leads to evolving picture streams which possibly contain misleading and redundant information that affects the task result. In order to overcome these issues, we develop, in this paper, a solution for selecting highly relevant data from an evolving picture stream and ensuring correct submission. The proposed photo-based MCS framework for event reporting incorporates (i) a deep learning model to eliminate false submissions and ensure photos credibility and (ii) an A-Tree shape data structure model for clustering streaming pictures to reduce information redundancy and provide maximum event coverage. Simulation results indicate that the implemented framework can effectively reduce false submissions and select a subset with high utility coverage with low redundancy ratio from the streaming data.
* Published in 2019 IEEE 62nd International Midwest Symposium on Circuits and Systems (MWSCAS)
OpenD: A Benchmark for Language-Driven Door and Drawer Opening
Dec 10, 2022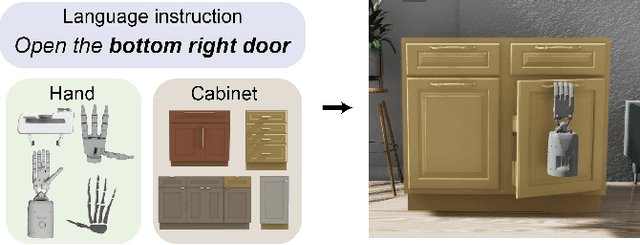
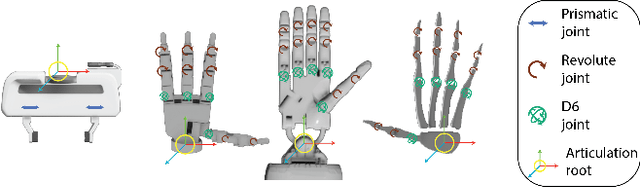
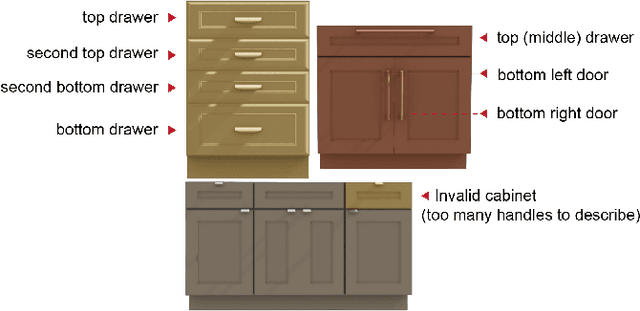

We introduce OPEND, a benchmark for learning how to use a hand to open cabinet doors or drawers in a photo-realistic and physics-reliable simulation environment driven by language instruction. To solve the task, we propose a multi-step planner composed of a deep neural network and rule-base controllers. The network is utilized to capture spatial relationships from images and understand semantic meaning from language instructions. Controllers efficiently execute the plan based on the spatial and semantic understanding. We evaluate our system by measuring its zero-shot performance in test data set. Experimental results demonstrate the effectiveness of decision planning by our multi-step planner for different hands, while suggesting that there is significant room for developing better models to address the challenge brought by language understanding, spatial reasoning, and long-term manipulation. We will release OPEND and host challenges to promote future research in this area.
Dr.3D: Adapting 3D GANs to Artistic Drawings
Nov 30, 2022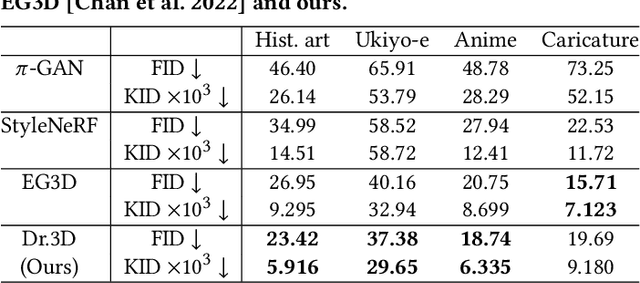
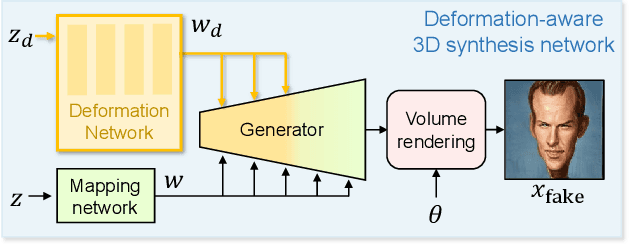
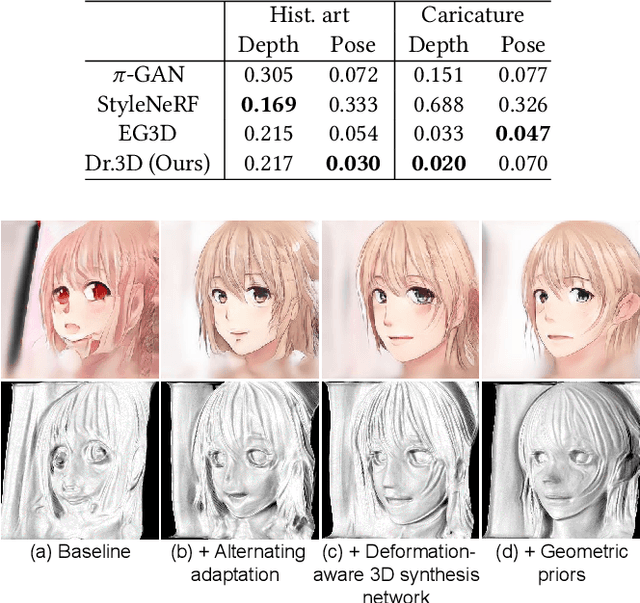
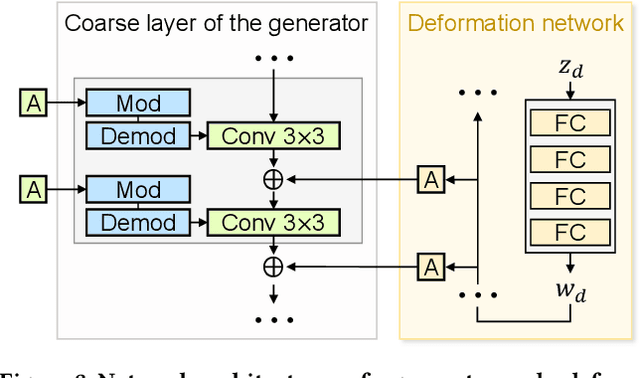
While 3D GANs have recently demonstrated the high-quality synthesis of multi-view consistent images and 3D shapes, they are mainly restricted to photo-realistic human portraits. This paper aims to extend 3D GANs to a different, but meaningful visual form: artistic portrait drawings. However, extending existing 3D GANs to drawings is challenging due to the inevitable geometric ambiguity present in drawings. To tackle this, we present Dr.3D, a novel adaptation approach that adapts an existing 3D GAN to artistic drawings. Dr.3D is equipped with three novel components to handle the geometric ambiguity: a deformation-aware 3D synthesis network, an alternating adaptation of pose estimation and image synthesis, and geometric priors. Experiments show that our approach can successfully adapt 3D GANs to drawings and enable multi-view consistent semantic editing of drawings.
Joint Beamforming and PD Orientation Design for Mobile Visible Light Communications
Dec 21, 2022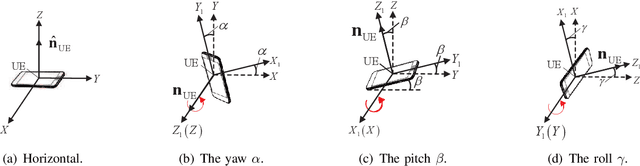
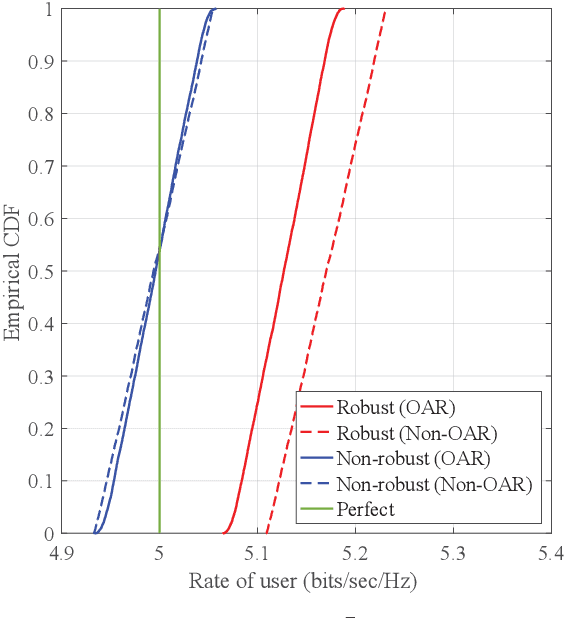
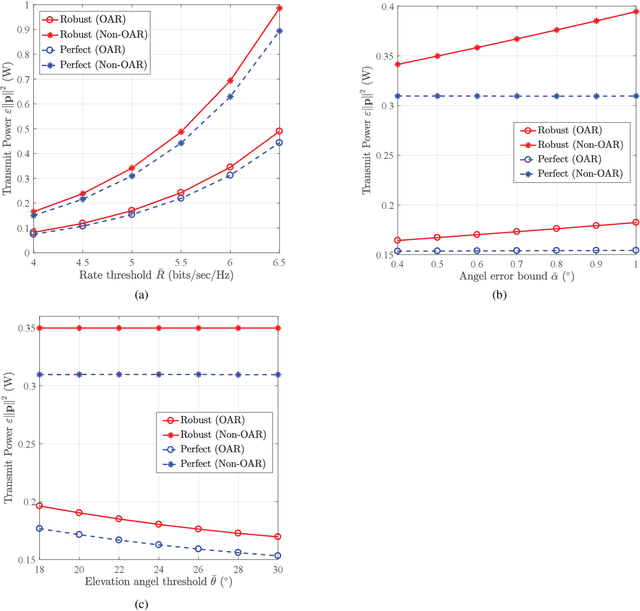
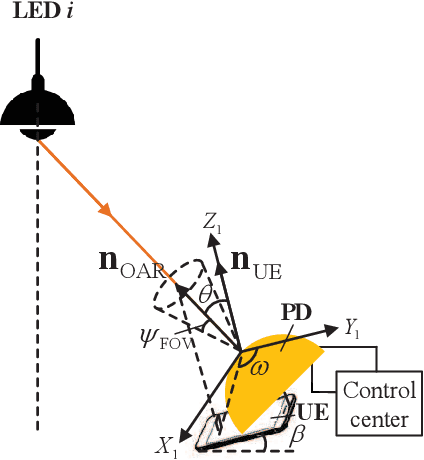
In this paper, we propose joint beamforming and photo-detector (PD) orientation (BO) optimization schemes for mobile visible light communication (VLC) with the orientation adjustable receiver (OAR). Since VLC is sensitive to line-of-sight propagation, we first establish the OAR model and the human body blockage model for mobile VLC user equipment (UE). To guarantee the quality of service (QoS) of mobile VLC, we jointly optimize BO with minimal UE the power consumption for both fixed and random UE orientation cases. For the fixed UE orientation case, since the {transmit} beamforming and the PD orientation are mutually coupled, the joint BO optimization problem is nonconvex and intractable. To address this challenge, we propose an alternating optimization algorithm to obtain the transmit beamforming and the PD orientation. For the random UE orientation case, we further propose a robust alternating BO optimization algorithm to ensure the worst-case QoS requirement of the mobile UE. Finally, the performance of joint BO optimization design schemes are evaluated for mobile VLC through numerical experiments.
NeuralLift-360: Lifting An In-the-wild 2D Photo to A 3D Object with 360° Views
Nov 29, 2022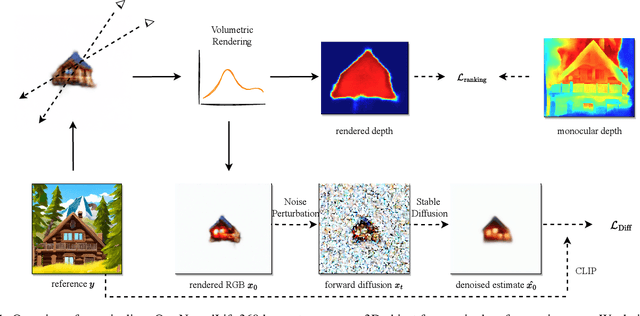


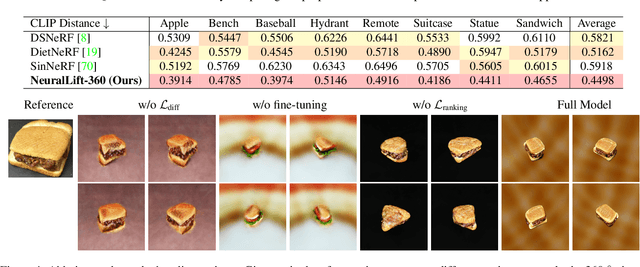
Virtual reality and augmented reality (XR) bring increasing demand for 3D content. However, creating high-quality 3D content requires tedious work that a human expert must do. In this work, we study the challenging task of lifting a single image to a 3D object and, for the first time, demonstrate the ability to generate a plausible 3D object with 360{\deg} views that correspond well with the given reference image. By conditioning on the reference image, our model can fulfill the everlasting curiosity for synthesizing novel views of objects from images. Our technique sheds light on a promising direction of easing the workflows for 3D artists and XR designers. We propose a novel framework, dubbed NeuralLift-360, that utilizes a depth-aware neural radiance representation (NeRF) and learns to craft the scene guided by denoising diffusion models. By introducing a ranking loss, our NeuralLift-360 can be guided with rough depth estimation in the wild. We also adopt a CLIP-guided sampling strategy for the diffusion prior to provide coherent guidance. Extensive experiments demonstrate that our NeuralLift-360 significantly outperforms existing state-of-the-art baselines. Project page: https://vita-group.github.io/NeuralLift-360/
The Eyecandies Dataset for Unsupervised Multimodal Anomaly Detection and Localization
Oct 10, 2022
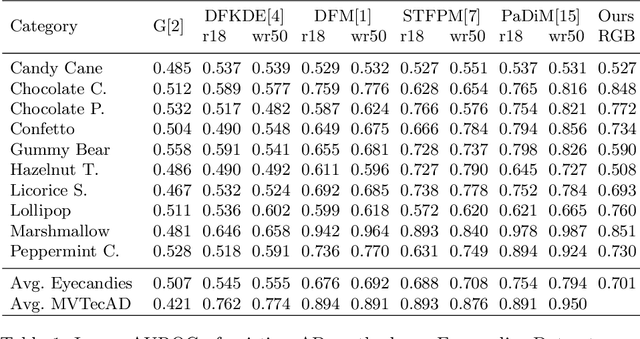
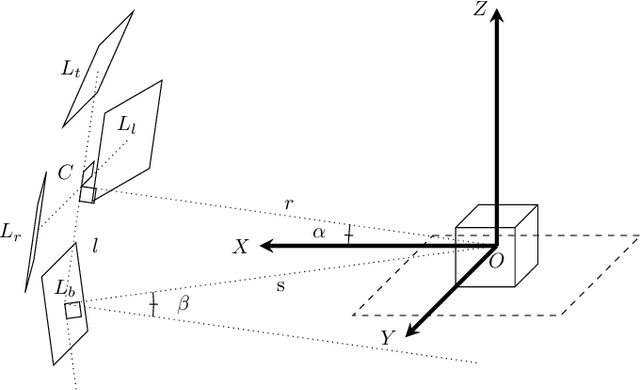
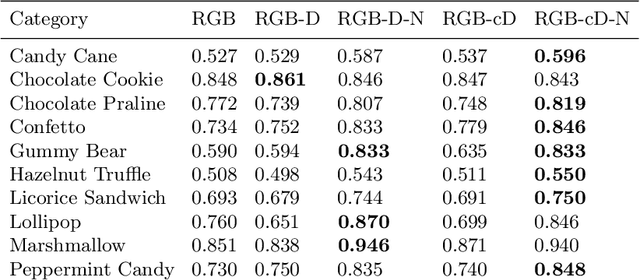
We present Eyecandies, a novel synthetic dataset for unsupervised anomaly detection and localization. Photo-realistic images of procedurally generated candies are rendered in a controlled environment under multiple lightning conditions, also providing depth and normal maps in an industrial conveyor scenario. We make available anomaly-free samples for model training and validation, while anomalous instances with precise ground-truth annotations are provided only in the test set. The dataset comprises ten classes of candies, each showing different challenges, such as complex textures, self-occlusions and specularities. Furthermore, we achieve large intra-class variation by randomly drawing key parameters of a procedural rendering pipeline, which enables the creation of an arbitrary number of instances with photo-realistic appearance. Likewise, anomalies are injected into the rendering graph and pixel-wise annotations are automatically generated, overcoming human-biases and possible inconsistencies. We believe this dataset may encourage the exploration of original approaches to solve the anomaly detection task, e.g. by combining color, depth and normal maps, as they are not provided by most of the existing datasets. Indeed, in order to demonstrate how exploiting additional information may actually lead to higher detection performance, we show the results obtained by training a deep convolutional autoencoder to reconstruct different combinations of inputs.
Seeing a Rose in Five Thousand Ways
Dec 09, 2022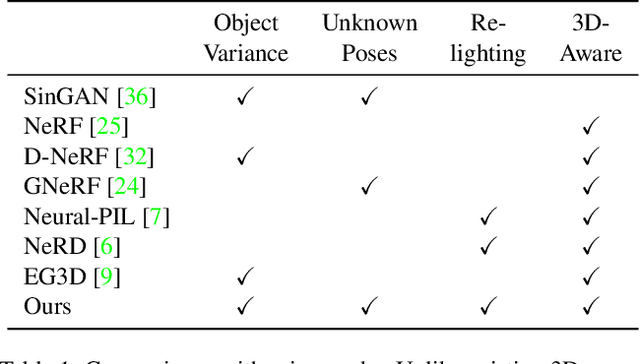
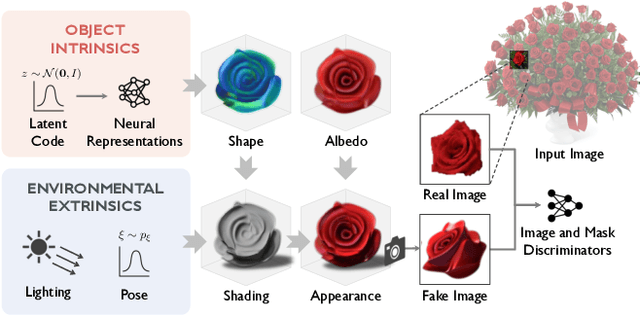

What is a rose, visually? A rose comprises its intrinsics, including the distribution of geometry, texture, and material specific to its object category. With knowledge of these intrinsic properties, we may render roses of different sizes and shapes, in different poses, and under different lighting conditions. In this work, we build a generative model that learns to capture such object intrinsics from a single image, such as a photo of a bouquet. Such an image includes multiple instances of an object type. These instances all share the same intrinsics, but appear different due to a combination of variance within these intrinsics and differences in extrinsic factors, such as pose and illumination. Experiments show that our model successfully learns object intrinsics (distribution of geometry, texture, and material) for a wide range of objects, each from a single Internet image. Our method achieves superior results on multiple downstream tasks, including intrinsic image decomposition, shape and image generation, view synthesis, and relighting.
Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model
Dec 07, 2022
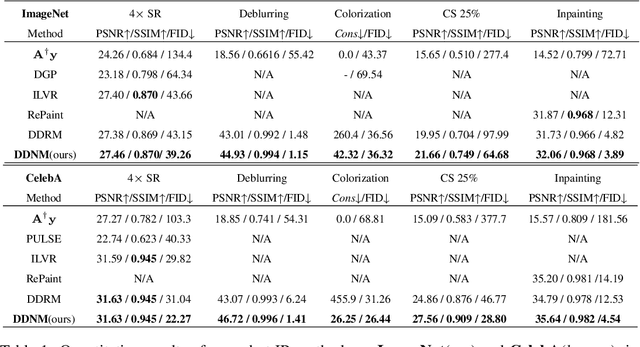
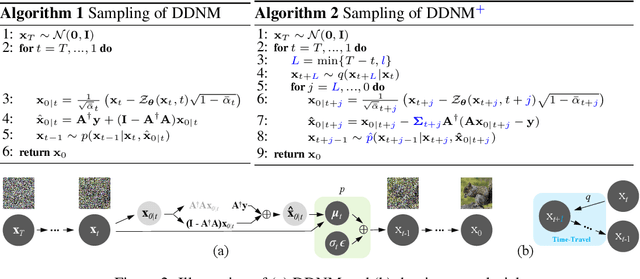

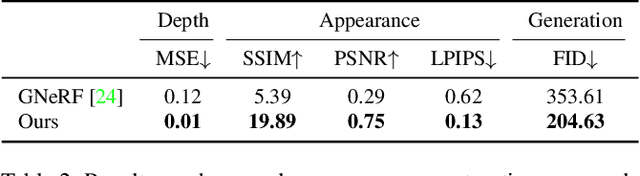
Most existing Image Restoration (IR) models are task-specific, which can not be generalized to different degradation operators. In this work, we propose the Denoising Diffusion Null-Space Model (DDNM), a novel zero-shot framework for arbitrary linear IR problems, including but not limited to image super-resolution, colorization, inpainting, compressed sensing, and deblurring. DDNM only needs a pre-trained off-the-shelf diffusion model as the generative prior, without any extra training or network modifications. By refining only the null-space contents during the reverse diffusion process, we can yield diverse results satisfying both data consistency and realness. We further propose an enhanced and robust version, dubbed DDNM+, to support noisy restoration and improve restoration quality for hard tasks. Our experiments on several IR tasks reveal that DDNM outperforms other state-of-the-art zero-shot IR methods. We also demonstrate that DDNM+ can solve complex real-world applications, e.g., old photo restoration.