 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Sliceformer: Make Multi-head Attention as Simple as Sorting in Discriminative Tasks
Oct 26, 2023

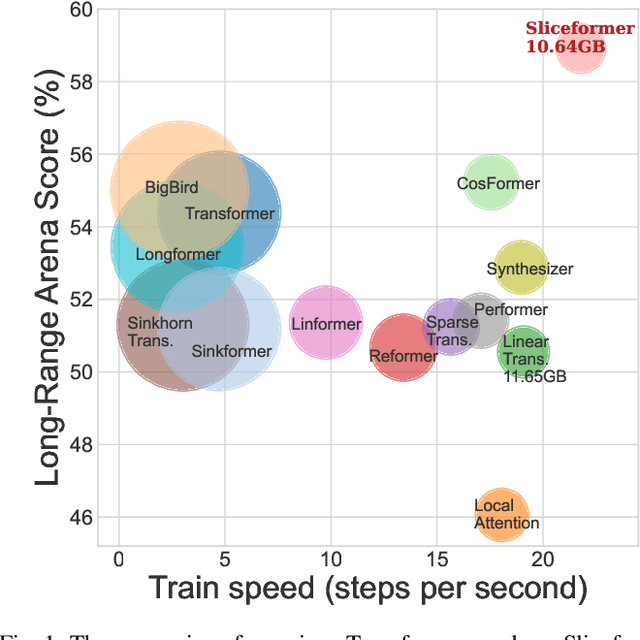
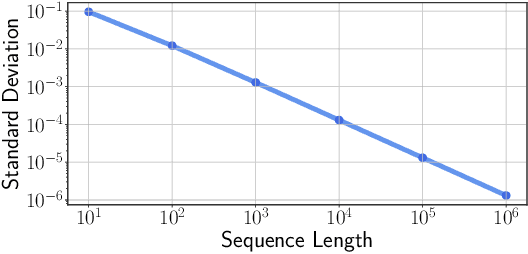
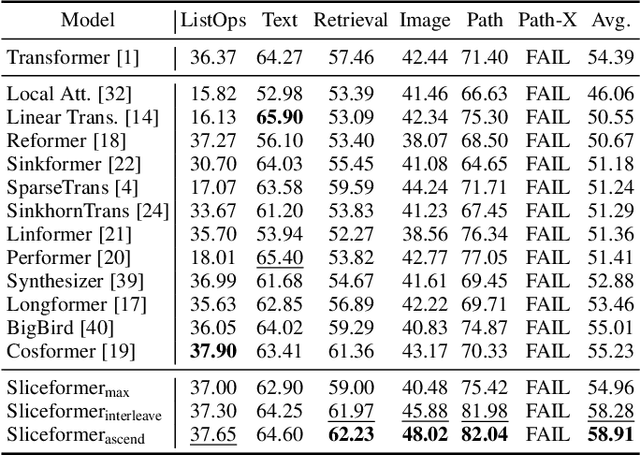
As one of the most popular neural network modules, Transformer plays a central role in many fundamental deep learning models, e.g., the ViT in computer vision and the BERT and GPT in natural language processing. The effectiveness of the Transformer is often attributed to its multi-head attention (MHA) mechanism. In this study, we discuss the limitations of MHA, including the high computational complexity due to its ``query-key-value'' architecture and the numerical issue caused by its softmax operation. Considering the above problems and the recent development tendency of the attention layer, we propose an effective and efficient surrogate of the Transformer, called Sliceformer. Our Sliceformer replaces the classic MHA mechanism with an extremely simple ``slicing-sorting'' operation, i.e., projecting inputs linearly to a latent space and sorting them along different feature dimensions (or equivalently, called channels). For each feature dimension, the sorting operation implicitly generates an implicit attention map with sparse, full-rank, and doubly-stochastic structures. We consider different implementations of the slicing-sorting operation and analyze their impacts on the Sliceformer. We test the Sliceformer in the Long-Range Arena benchmark, image classification, text classification, and molecular property prediction, demonstrating its advantage in computational complexity and universal effectiveness in discriminative tasks. Our Sliceformer achieves comparable or better performance with lower memory cost and faster speed than the Transformer and its variants. Moreover, the experimental results reveal that applying our Sliceformer can empirically suppress the risk of mode collapse when representing data. The code is available at \url{https://github.com/SDS-Lab/sliceformer}.
Retrieval-augmented Multi-label Text Classification
May 22, 2023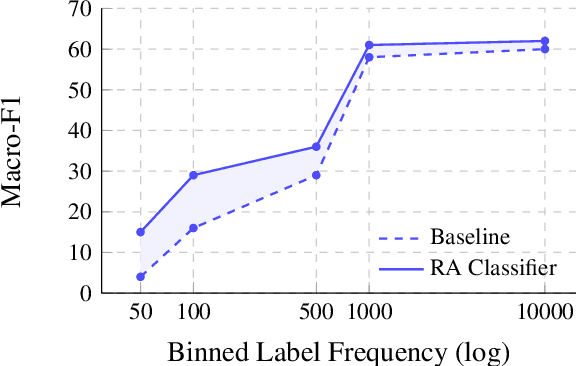

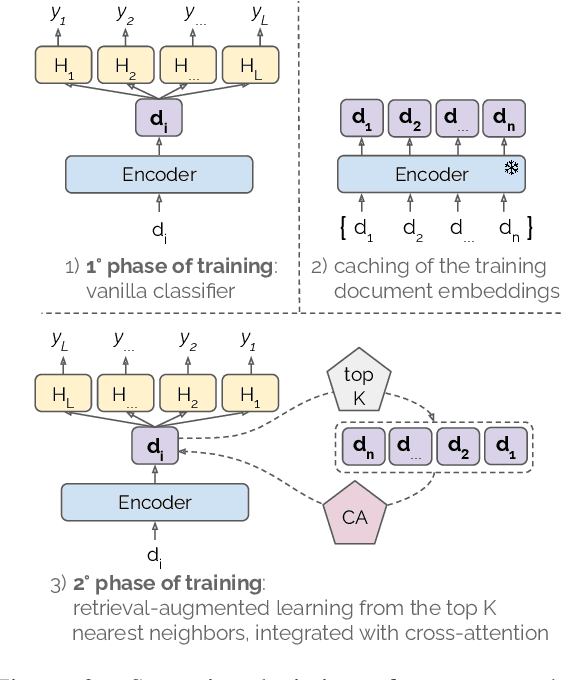
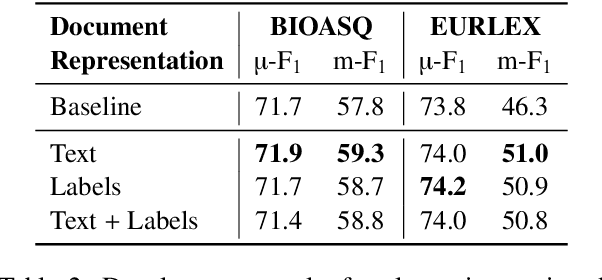
Multi-label text classification (MLC) is a challenging task in settings of large label sets, where label support follows a Zipfian distribution. In this paper, we address this problem through retrieval augmentation, aiming to improve the sample efficiency of classification models. Our approach closely follows the standard MLC architecture of a Transformer-based encoder paired with a set of classification heads. In our case, however, the input document representation is augmented through cross-attention to similar documents retrieved from the training set and represented in a task-specific manner. We evaluate this approach on four datasets from the legal and biomedical domains, all of which feature highly skewed label distributions. Our experiments show that retrieval augmentation substantially improves model performance on the long tail of infrequent labels especially so for lower-resource training scenarios and more challenging long-document data scenarios.
Self-Evolution Learning for Mixup: Enhance Data Augmentation on Few-Shot Text Classification Tasks
May 22, 2023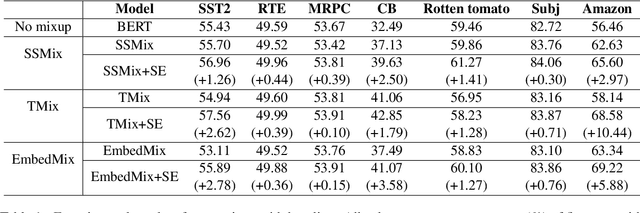
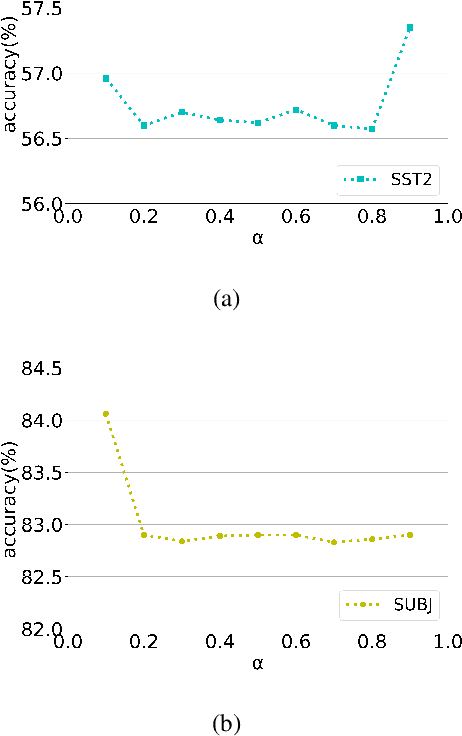
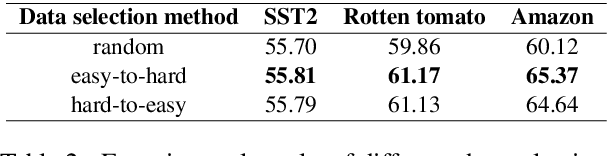
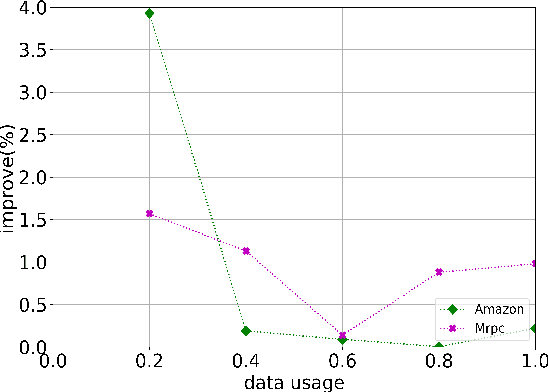
Text classification tasks often encounter few shot scenarios with limited labeled data, and addressing data scarcity is crucial. Data augmentation with mixup has shown to be effective on various text classification tasks. However, most of the mixup methods do not consider the varying degree of learning difficulty in different stages of training and generate new samples with one hot labels, resulting in the model over confidence. In this paper, we propose a self evolution learning (SE) based mixup approach for data augmentation in text classification, which can generate more adaptive and model friendly pesudo samples for the model training. SE focuses on the variation of the model's learning ability. To alleviate the model confidence, we introduce a novel instance specific label smoothing approach, which linearly interpolates the model's output and one hot labels of the original samples to generate new soft for label mixing up. Through experimental analysis, in addition to improving classification accuracy, we demonstrate that SE also enhances the model's generalize ability.
Effects of Human Adversarial and Affable Samples on BERT Generalizability
Oct 17, 2023
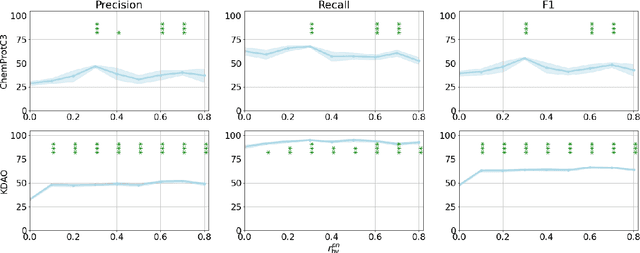

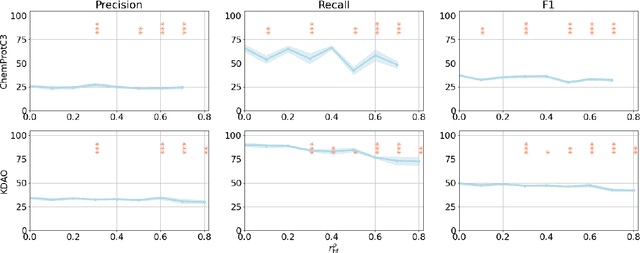
BERT-based models have had strong performance on leaderboards, yet have been demonstrably worse in real-world settings requiring generalization. Limited quantities of training data is considered a key impediment to achieving generalizability in machine learning. In this paper, we examine the impact of training data quality, not quantity, on a model's generalizability. We consider two characteristics of training data: the portion of human-adversarial (h-adversarial), i.e., sample pairs with seemingly minor differences but different ground-truth labels, and human-affable (h-affable) training samples, i.e., sample pairs with minor differences but the same ground-truth label. We find that for a fixed size of training samples, as a rule of thumb, having 10-30% h-adversarial instances improves the precision, and therefore F1, by up to 20 points in the tasks of text classification and relation extraction. Increasing h-adversarials beyond this range can result in performance plateaus or even degradation. In contrast, h-affables may not contribute to a model's generalizability and may even degrade generalization performance.
A Multi-Modal Multilingual Benchmark for Document Image Classification
Oct 25, 2023
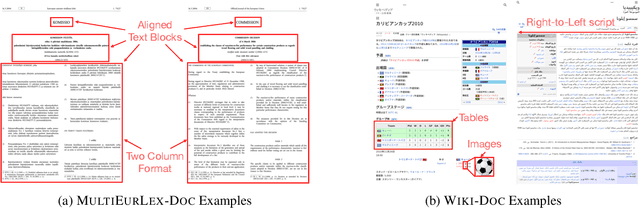

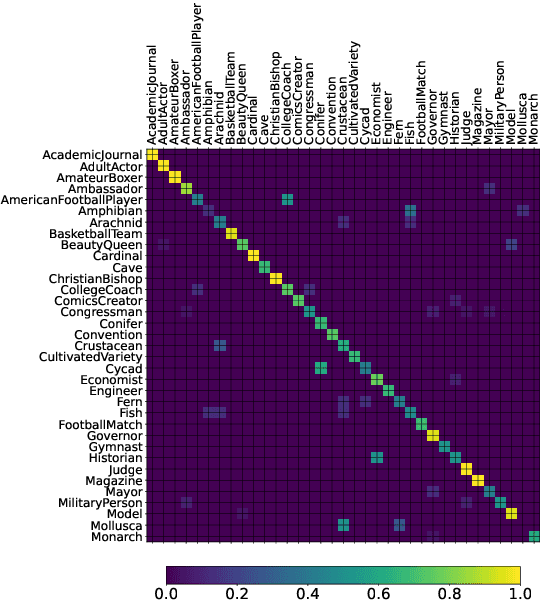
Document image classification is different from plain-text document classification and consists of classifying a document by understanding the content and structure of documents such as forms, emails, and other such documents. We show that the only existing dataset for this task (Lewis et al., 2006) has several limitations and we introduce two newly curated multilingual datasets WIKI-DOC and MULTIEURLEX-DOC that overcome these limitations. We further undertake a comprehensive study of popular visually-rich document understanding or Document AI models in previously untested setting in document image classification such as 1) multi-label classification, and 2) zero-shot cross-lingual transfer setup. Experimental results show limitations of multilingual Document AI models on cross-lingual transfer across typologically distant languages. Our datasets and findings open the door for future research into improving Document AI models.
Fusing Models with Complementary Expertise
Oct 02, 2023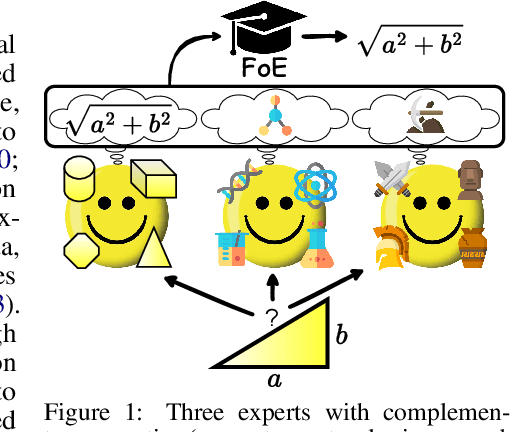
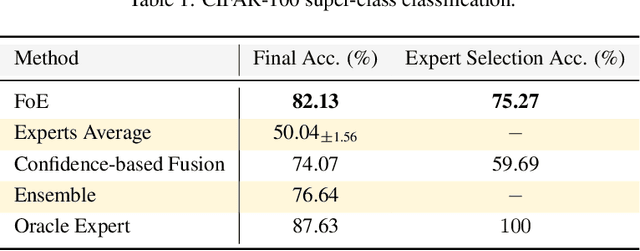
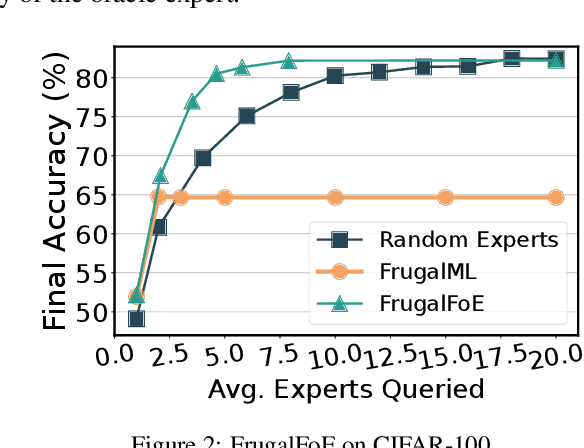
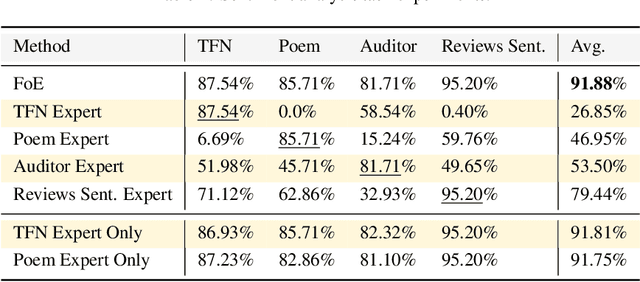
Training AI models that generalize across tasks and domains has long been among the open problems driving AI research. The emergence of Foundation Models made it easier to obtain expert models for a given task, but the heterogeneity of data that may be encountered at test time often means that any single expert is insufficient. We consider the Fusion of Experts (FoE) problem of fusing outputs of expert models with complementary knowledge of the data distribution and formulate it as an instance of supervised learning. Our method is applicable to both discriminative and generative tasks and leads to significant performance improvements in image and text classification, text summarization, multiple-choice QA, and automatic evaluation of generated text. We also extend our method to the "frugal" setting where it is desired to reduce the number of expert model evaluations at test time.
Boosting In-Context Learning with Factual Knowledge
Sep 26, 2023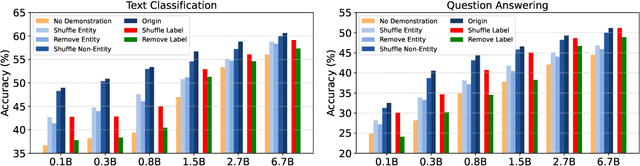
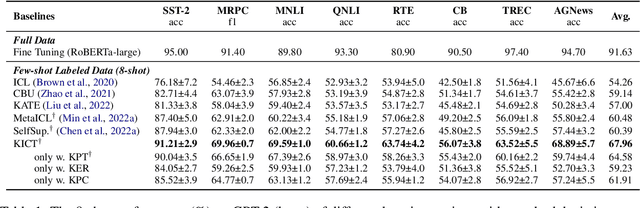
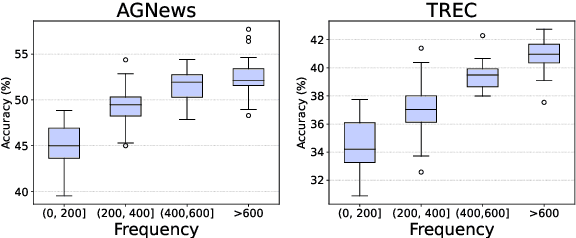
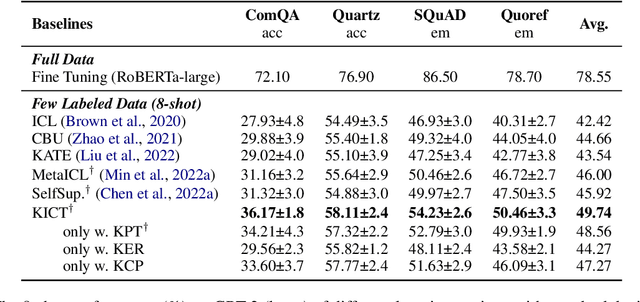
In-Context Learning (ICL) over Large language models (LLMs) aims at solving previously unseen tasks by conditioning on a few training examples, eliminating the need for parameter updates and achieving competitive performance. In this paper, we demonstrate that factual knowledge is imperative for the performance of ICL in three core facets, i.e., the inherent knowledge learned in LLMs, the factual knowledge derived from the selected in-context examples, and the knowledge biases in LLMs for output generation. To unleash the power of LLMs in few-shot learning scenarios, we introduce a novel Knowledgeable In-Context Tuning (KICT) framework to further improve the performance of ICL: 1) injecting factual knowledge to LLMs during continual self-supervised pre-training, 2) judiciously selecting the examples with high knowledge relevance, and 3) calibrating the prediction results based on prior knowledge. We evaluate the proposed approaches on auto-regressive LLMs (e.g., GPT-style models) over multiple text classification and question answering tasks. Experimental results demonstrate that KICT substantially outperforms strong baselines, and improves by more than 13% and 7% of accuracy on text classification and question answering tasks, respectively.
Text Data Augmentation in Low-Resource Settings via Fine-Tuning of Large Language Models
Oct 02, 2023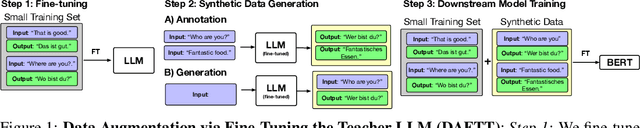
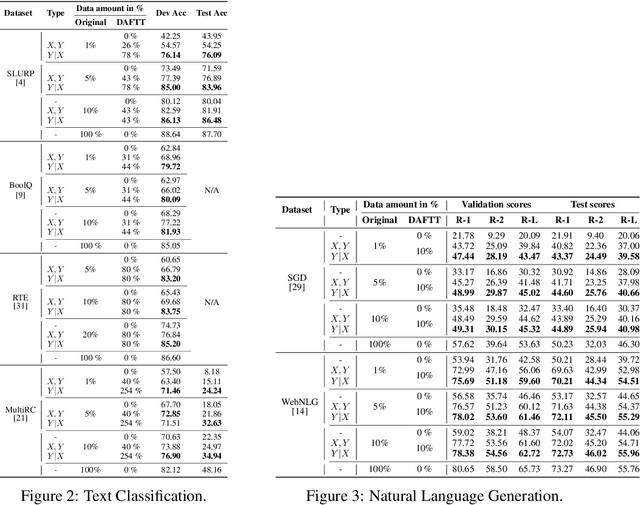

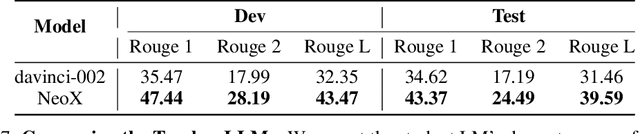
The in-context learning ability of large language models (LLMs) enables them to generalize to novel downstream tasks with relatively few labeled examples. However, they require enormous computational resources to be deployed. Alternatively, smaller models can solve specific tasks if fine-tuned with enough labeled examples. These examples, however, are expensive to obtain. In pursuit of the best of both worlds, we study the annotation and generation of fine-tuning training data via fine-tuned teacher LLMs to improve the downstream performance of much smaller models. In four text classification and two text generation tasks, we find that both data generation and annotation dramatically improve the respective downstream model's performance, occasionally necessitating only a minor fraction of the original training dataset.
Taxi1500: A Multilingual Dataset for Text Classification in 1500 Languages
May 15, 2023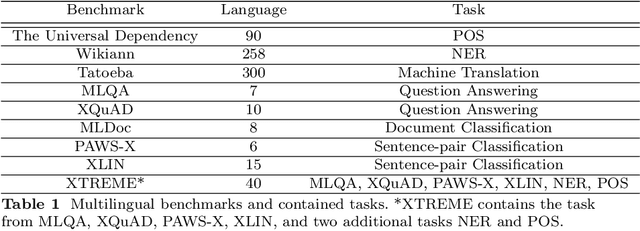
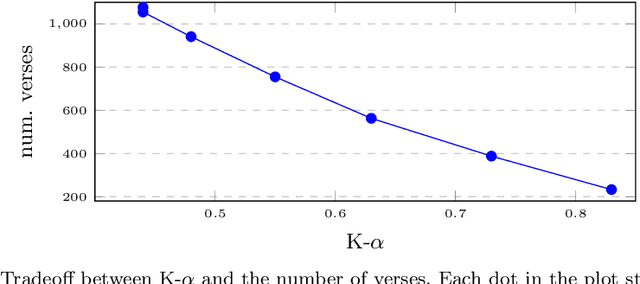
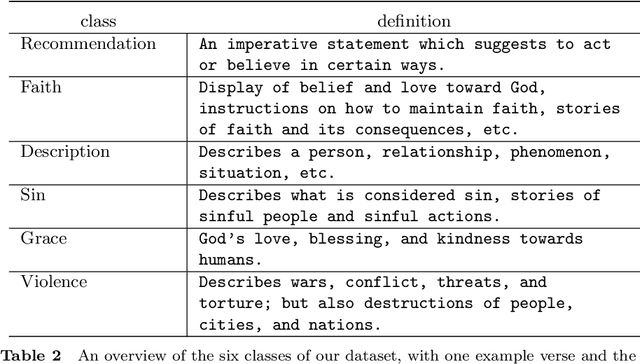
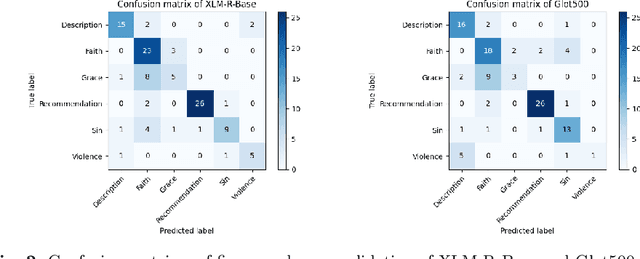
While natural language processing tools have been developed extensively for some of the world's languages, a significant portion of the world's over 7000 languages are still neglected. One reason for this is that evaluation datasets do not yet cover a wide range of languages, including low-resource and endangered ones. We aim to address this issue by creating a text classification dataset encompassing a large number of languages, many of which currently have little to no annotated data available. We leverage parallel translations of the Bible to construct such a dataset by first developing applicable topics and employing a crowdsourcing tool to collect annotated data. By annotating the English side of the data and projecting the labels onto other languages through aligned verses, we generate text classification datasets for more than 1500 languages. We extensively benchmark several existing multilingual language models using our dataset. To facilitate the advancement of research in this area, we will release our dataset and code.
Large Language Models as Topological Structure Enhancers for Text-Attributed Graphs
Nov 24, 2023The latest advancements in large language models (LLMs) have revolutionized the field of natural language processing (NLP). Inspired by the success of LLMs in NLP tasks, some recent work has begun investigating the potential of applying LLMs in graph learning tasks. However, most of the existing work focuses on utilizing LLMs as powerful node feature augmenters, leaving employing LLMs to enhance graph topological structures an understudied problem. In this work, we explore how to leverage the information retrieval and text generation capabilities of LLMs to refine/enhance the topological structure of text-attributed graphs (TAGs) under the node classification setting. First, we propose using LLMs to help remove unreliable edges and add reliable ones in the TAG. Specifically, we first let the LLM output the semantic similarity between node attributes through delicate prompt designs, and then perform edge deletion and edge addition based on the similarity. Second, we propose using pseudo-labels generated by the LLM to improve graph topology, that is, we introduce the pseudo-label propagation as a regularization to guide the graph neural network (GNN) in learning proper edge weights. Finally, we incorporate the two aforementioned LLM-based methods for graph topological refinement into the process of GNN training, and perform extensive experiments on four real-world datasets. The experimental results demonstrate the effectiveness of LLM-based graph topology refinement (achieving a 0.15%--2.47% performance gain on public benchmarks).