 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of Plan-Guided Summarization for Narrative Texts: the Case of Small Language Models
Apr 12, 2025



Plan-guided summarization attempts to reduce hallucinations in small language models (SLMs) by grounding generated summaries to the source text, typically by targeting fine-grained details such as dates or named entities. In this work, we investigate whether plan-based approaches in SLMs improve summarization in long document, narrative tasks. Narrative texts' length and complexity often mean they are difficult to summarize faithfully. We analyze existing plan-guided solutions targeting fine-grained details, and also propose our own higher-level, narrative-based plan formulation. Our results show that neither approach significantly improves on a baseline without planning in either summary quality or faithfulness. Human evaluation reveals that while plan-guided approaches are often well grounded to their plan, plans are equally likely to contain hallucinations compared to summaries. As a result, the plan-guided summaries are just as unfaithful as those from models without planning. Our work serves as a cautionary tale to plan-guided approaches to summarization, especially for long, complex domains such as narrative texts.
A Multi-Modal Multilingual Benchmark for Document Image Classification
Oct 25, 2023



Document image classification is different from plain-text document classification and consists of classifying a document by understanding the content and structure of documents such as forms, emails, and other such documents. We show that the only existing dataset for this task (Lewis et al., 2006) has several limitations and we introduce two newly curated multilingual datasets WIKI-DOC and MULTIEURLEX-DOC that overcome these limitations. We further undertake a comprehensive study of popular visually-rich document understanding or Document AI models in previously untested setting in document image classification such as 1) multi-label classification, and 2) zero-shot cross-lingual transfer setup. Experimental results show limitations of multilingual Document AI models on cross-lingual transfer across typologically distant languages. Our datasets and findings open the door for future research into improving Document AI models.
Characterizing and Measuring Linguistic Dataset Drift
May 26, 2023


NLP models often degrade in performance when real world data distributions differ markedly from training data. However, existing dataset drift metrics in NLP have generally not considered specific dimensions of linguistic drift that affect model performance, and they have not been validated in their ability to predict model performance at the individual example level, where such metrics are often used in practice. In this paper, we propose three dimensions of linguistic dataset drift: vocabulary, structural, and semantic drift. These dimensions correspond to content word frequency divergences, syntactic divergences, and meaning changes not captured by word frequencies (e.g. lexical semantic change). We propose interpretable metrics for all three drift dimensions, and we modify past performance prediction methods to predict model performance at both the example and dataset level for English sentiment classification and natural language inference. We find that our drift metrics are more effective than previous metrics at predicting out-of-domain model accuracies (mean 16.8% root mean square error decrease), particularly when compared to popular fine-tuned embedding distances (mean 47.7% error decrease). Fine-tuned embedding distances are much more effective at ranking individual examples by expected performance, but decomposing into vocabulary, structural, and semantic drift produces the best example rankings of all considered model-agnostic drift metrics (mean 6.7% ROC AUC increase).
Taxonomy Expansion for Named Entity Recognition
May 22, 2023



Training a Named Entity Recognition (NER) model often involves fixing a taxonomy of entity types. However, requirements evolve and we might need the NER model to recognize additional entity types. A simple approach is to re-annotate entire dataset with both existing and additional entity types and then train the model on the re-annotated dataset. However, this is an extremely laborious task. To remedy this, we propose a novel approach called Partial Label Model (PLM) that uses only partially annotated datasets. We experiment with 6 diverse datasets and show that PLM consistently performs better than most other approaches (0.5 - 2.5 F1), including in novel settings for taxonomy expansion not considered in prior work. The gap between PLM and all other approaches is especially large in settings where there is limited data available for the additional entity types (as much as 11 F1), thus suggesting a more cost effective approaches to taxonomy expansion.
Comparing Biases and the Impact of Multilingual Training across Multiple Languages
May 18, 2023



Studies in bias and fairness in natural language processing have primarily examined social biases within a single language and/or across few attributes (e.g. gender, race). However, biases can manifest differently across various languages for individual attributes. As a result, it is critical to examine biases within each language and attribute. Of equal importance is to study how these biases compare across languages and how the biases are affected when training a model on multilingual data versus monolingual data. We present a bias analysis across Italian, Chinese, English, Hebrew, and Spanish on the downstream sentiment analysis task to observe whether specific demographics are viewed more positively. We study bias similarities and differences across these languages and investigate the impact of multilingual vs. monolingual training data. We adapt existing sentiment bias templates in English to Italian, Chinese, Hebrew, and Spanish for four attributes: race, religion, nationality, and gender. Our results reveal similarities in bias expression such as favoritism of groups that are dominant in each language's culture (e.g. majority religions and nationalities). Additionally, we find an increased variation in predictions across protected groups, indicating bias amplification, after multilingual finetuning in comparison to multilingual pretraining.
Simple Yet Effective Synthetic Dataset Construction for Unsupervised Opinion Summarization
Mar 21, 2023



Opinion summarization provides an important solution for summarizing opinions expressed among a large number of reviews. However, generating aspect-specific and general summaries is challenging due to the lack of annotated data. In this work, we propose two simple yet effective unsupervised approaches to generate both aspect-specific and general opinion summaries by training on synthetic datasets constructed with aspect-related review contents. Our first approach, Seed Words Based Leave-One-Out (SW-LOO), identifies aspect-related portions of reviews simply by exact-matching aspect seed words and outperforms existing methods by 3.4 ROUGE-L points on SPACE and 0.5 ROUGE-1 point on OPOSUM+ for aspect-specific opinion summarization. Our second approach, Natural Language Inference Based Leave-One-Out (NLI-LOO) identifies aspect-related sentences utilizing an NLI model in a more general setting without using seed words and outperforms existing approaches by 1.2 ROUGE-L points on SPACE for aspect-specific opinion summarization and remains competitive on other metrics.
Dynamic Benchmarking of Masked Language Models on Temporal Concept Drift with Multiple Views
Feb 23, 2023



Temporal concept drift refers to the problem of data changing over time. In NLP, that would entail that language (e.g. new expressions, meaning shifts) and factual knowledge (e.g. new concepts, updated facts) evolve over time. Focusing on the latter, we benchmark $11$ pretrained masked language models (MLMs) on a series of tests designed to evaluate the effect of temporal concept drift, as it is crucial that widely used language models remain up-to-date with the ever-evolving factual updates of the real world. Specifically, we provide a holistic framework that (1) dynamically creates temporal test sets of any time granularity (e.g. month, quarter, year) of factual data from Wikidata, (2) constructs fine-grained splits of tests (e.g. updated, new, unchanged facts) to ensure comprehensive analysis, and (3) evaluates MLMs in three distinct ways (single-token probing, multi-token generation, MLM scoring). In contrast to prior work, our framework aims to unveil how robust an MLM is over time and thus to provide a signal in case it has become outdated, by leveraging multiple views of evaluation.
Contrastive Training Improves Zero-Shot Classification of Semi-structured Documents
Oct 11, 2022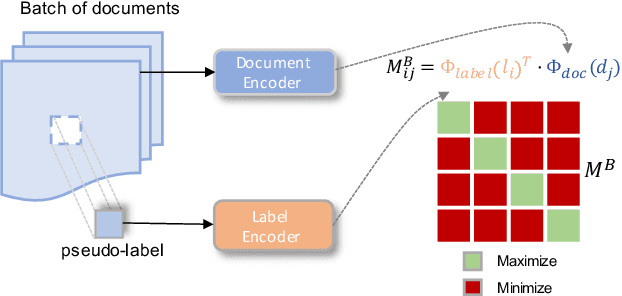


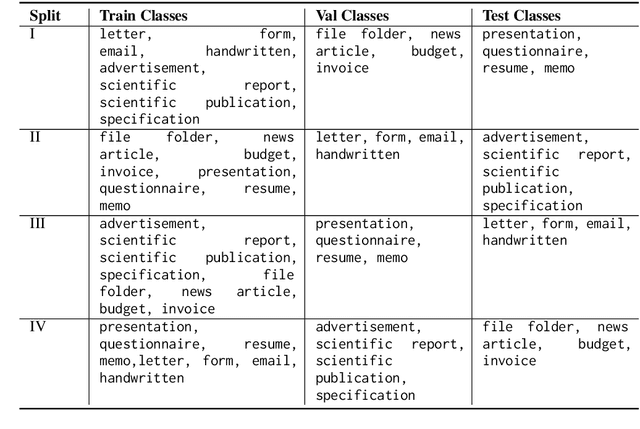
We investigate semi-structured document classification in a zero-shot setting. Classification of semi-structured documents is more challenging than that of standard unstructured documents, as positional, layout, and style information play a vital role in interpreting such documents. The standard classification setting where categories are fixed during both training and testing falls short in dynamic environments where new document categories could potentially emerge. We focus exclusively on the zero-shot setting where inference is done on new unseen classes. To address this task, we propose a matching-based approach that relies on a pairwise contrastive objective for both pretraining and fine-tuning. Our results show a significant boost in Macro F$_1$ from the proposed pretraining step in both supervised and unsupervised zero-shot settings.
Efficient Classification of Long Documents Using Transformers
Mar 21, 2022
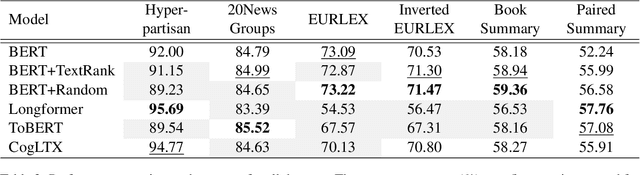
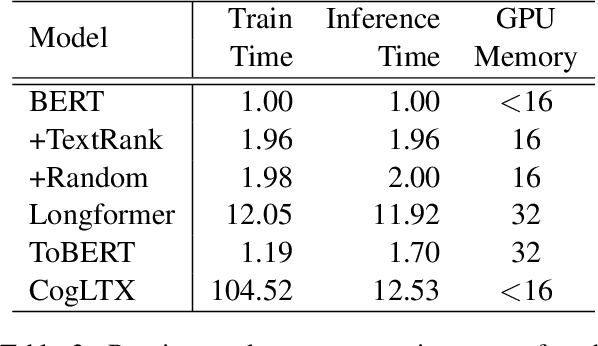
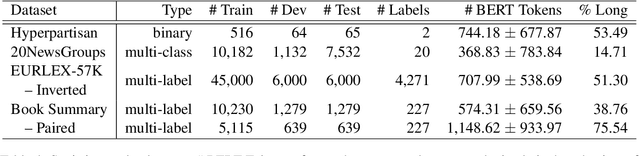
Several methods have been proposed for classifying long textual documents using Transformers. However, there is a lack of consensus on a benchmark to enable a fair comparison among different approaches. In this paper, we provide a comprehensive evaluation of the relative efficacy measured against various baselines and diverse datasets -- both in terms of accuracy as well as time and space overheads. Our datasets cover binary, multi-class, and multi-label classification tasks and represent various ways information is organized in a long text (e.g. information that is critical to making the classification decision is at the beginning or towards the end of the document). Our results show that more complex models often fail to outperform simple baselines and yield inconsistent performance across datasets. These findings emphasize the need for future studies to consider comprehensive baselines and datasets that better represent the task of long document classification to develop robust models.
Quantifying Social Biases in NLP: A Generalization and Empirical Comparison of Extrinsic Fairness Metrics
Jun 28, 2021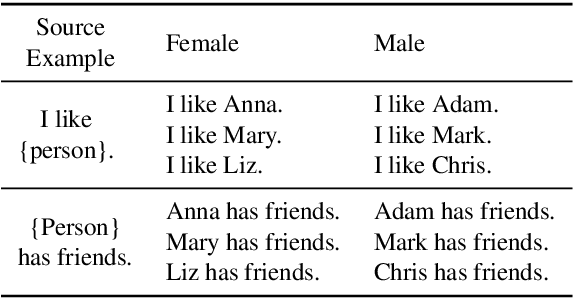
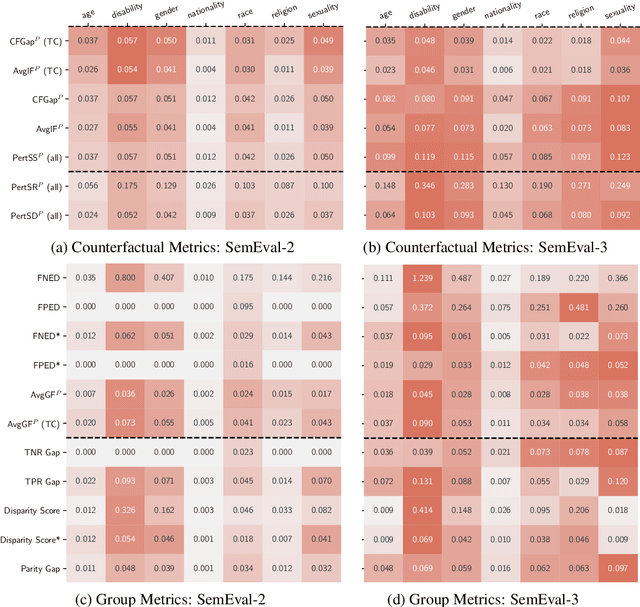
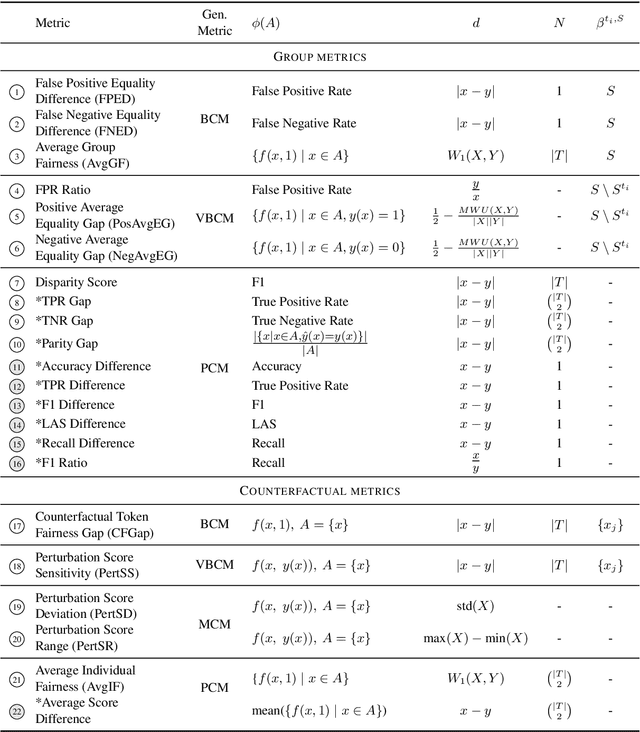
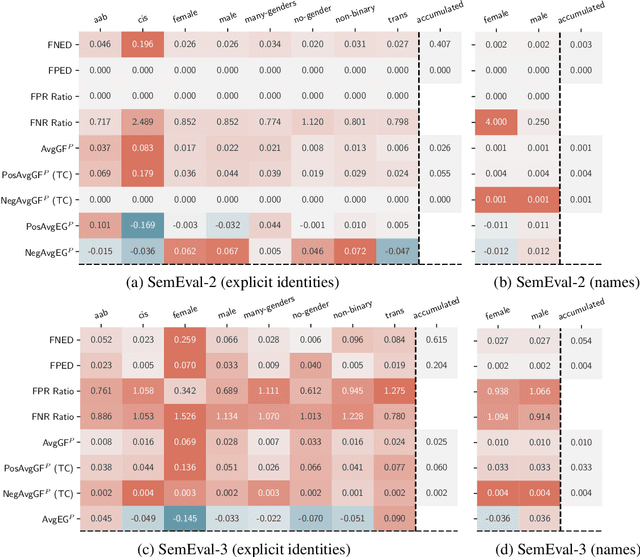
Measuring bias is key for better understanding and addressing unfairness in NLP/ML models. This is often done via fairness metrics which quantify the differences in a model's behaviour across a range of demographic groups. In this work, we shed more light on the differences and similarities between the fairness metrics used in NLP. First, we unify a broad range of existing metrics under three generalized fairness metrics, revealing the connections between them. Next, we carry out an extensive empirical comparison of existing metrics and demonstrate that the observed differences in bias measurement can be systematically explained via differences in parameter choices for our generalized metrics.