 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: Cost-aware Refinement And Front-aware Tuning of Prompts
Jun 03, 2026Prompts tuned for accuracy often grow long, raising inference cost on every model call. The best accuracy-cost trade-off depends on the task and the budget, so prompt optimization is a search over the Pareto front of accuracy and prompt-token cost rather than for one prompt. The usual shortcut, collapsing the objectives into a weighted sum, fixes the trade-off weight before search and often recovers only a narrow region of the front, a failure we call scalarization collapse. We present CRAFT (Cost-aware Refinement And Front-aware Tuning), a Pareto-front prompt optimizer that treats target-LLM validation calls as the scarce resource and allocates them to candidates near the optimistic candidate front. Each round, complementary accuracy-oriented and cost-oriented generators propose edits, Pareto-gap acquisition spends the per-round validation budget, and NSGA-II retention keeps a spread-out population. Across six classification and reasoning benchmarks, CRAFT's retained fronts reach both high-accuracy and low-cost regions, while accuracy-only, cost-only, and weighted-sum baselines each concentrate in narrower regions. The accuracy-cost trade-off becomes a post-search choice, not a pre-search weight.
VLMs Need Words: Vision Language Models Ignore Visual Detail In Favor of Semantic Anchors
Apr 02, 2026Vision Language Models (VLMs) achieve impressive performance across a wide range of multimodal tasks. However, on some tasks that demand fine-grained visual perception, they often fail even when the required information is present in their internal representations. In this work, we demonstrate that this gap arises from their narrow training pipeline which focuses on moving visual information to the textual space. Consequently, VLMs can only reason about visual entities that can be mapped to known concepts in the language space, leaving vision-focused tasks such as visual correspondence and reasoning about novel visual entities poorly supported. As a result, VLMs are severely limited in several important multimodal capabilities because they rely on brittle, hallucinated textual descriptions of visual entities that they cannot map to textual representations. We verify this behavior through visual correspondence tasks, in which VLMs must detect matching entities between two images. Testing across semantic, shape, and face correspondence tasks, we find that VLMs perform much better when the relevant entities are nameable in language than when they are unnameable. Mechanistically, our Logit Lens analyses confirm that VLMs explicitly assign semantic labels to nameable entities and surface more unique corresponding tokens compared to unnameable entities. Furthermore, we show that teaching completely arbitrary names for unknown entities improves performance, yet task-specific finetuning yields even stronger generalization without relying on language priors. Our findings suggest that current VLM failures on visual tasks reflect learned shortcuts from their training, rather than a fundamental limitation of multimodal architectures.
LinguDistill: Recovering Linguistic Ability in Vision- Language Models via Selective Cross-Modal Distillation
Apr 01, 2026Adapting pretrained language models (LMs) into vision-language models (VLMs) can degrade their native linguistic capability due to representation shift and cross-modal interference introduced during multimodal adaptation. Such loss is difficult to recover, even with targeted task-specific fine-tuning using standard objectives. Prior recovery approaches typically introduce additional modules that act as intermediate alignment layers to maintain or isolate modality-specific subspaces, which increases architectural complexity, adds parameters at inference time, and limits flexibility across models and settings. We propose LinguDistill, an adapter-free distillation method that restores linguistic capability by utilizing the original frozen LM as a teacher. We overcome the key challenge of enabling vision-conditioned teacher supervision by introducing layer-wise KV-cache sharing, which exposes the teacher to the student's multimodal representations without modifying the architecture of either model. We then selectively distill the teacher's strong linguistic signal on language-intensive data to recover language capability, while preserving the student's visual grounding on multimodal tasks. As a result, LinguDistill recovers $\sim$10% of the performance lost on language and knowledge benchmarks, while maintaining comparable performance on vision-heavy tasks. Our findings demonstrate that linguistic capability can be recovered without additional modules, providing an efficient and practical solution to modality-specific degradation in multimodal models.
SPECS: Specificity-Enhanced CLIP-Score for Long Image Caption Evaluation
Sep 04, 2025As interest grows in generating long, detailed image captions, standard evaluation metrics become increasingly unreliable. N-gram-based metrics though efficient, fail to capture semantic correctness. Representational Similarity (RS) metrics, designed to address this, initially saw limited use due to high computational costs, while today, despite advances in hardware, they remain unpopular due to low correlation to human judgments. Meanwhile, metrics based on large language models (LLMs) show strong correlation with human judgments, but remain too expensive for iterative use during model development. We introduce SPECS (Specificity-Enhanced CLIPScore), a reference-free RS metric tailored to long image captioning. SPECS modifies CLIP with a new objective that emphasizes specificity: rewarding correct details and penalizing incorrect ones. We show that SPECS matches the performance of open-source LLM-based metrics in correlation to human judgments, while being far more efficient. This makes it a practical alternative for iterative checkpoint evaluation during image captioning model development.Our code can be found at https://github.com/mbzuai-nlp/SPECS.
CONCAP: Seeing Beyond English with Concepts Retrieval-Augmented Captioning
Jul 27, 2025



Multilingual vision-language models have made significant strides in image captioning, yet they still lag behind their English counterparts due to limited multilingual training data and costly large-scale model parameterization. Retrieval-augmented generation (RAG) offers a promising alternative by conditioning caption generation on retrieved examples in the target language, reducing the need for extensive multilingual training. However, multilingual RAG captioning models often depend on retrieved captions translated from English, which can introduce mismatches and linguistic biases relative to the source language. We introduce CONCAP, a multilingual image captioning model that integrates retrieved captions with image-specific concepts, enhancing the contextualization of the input image and grounding the captioning process across different languages. Experiments on the XM3600 dataset indicate that CONCAP enables strong performance on low- and mid-resource languages, with highly reduced data requirements. Our findings highlight the effectiveness of concept-aware retrieval augmentation in bridging multilingual performance gaps.
The Devil is in the EOS: Sequence Training for Detailed Image Captioning
Jul 26, 2025Despite significant advances in vision-language models (VLMs), image captioning often suffers from a lack of detail, with base models producing short, generic captions. This limitation persists even though VLMs are equipped with strong vision and language backbones. While supervised data and complex reward functions have been proposed to improve detailed image captioning, we identify a simpler underlying issue: a bias towards the end-of-sequence (EOS) token, which is introduced during cross-entropy training. We propose an unsupervised method to debias the model's tendency to predict the EOS token prematurely. By reducing this bias, we encourage the generation of longer, more detailed captions without the need for intricate reward functions or supervision. Our approach is straightforward, effective, and easily applicable to any pretrained model. We demonstrate its effectiveness through experiments with three VLMs and on three detailed captioning benchmarks. Our results show a substantial increase in caption length and relevant details, albeit with an expected increase in the rate of hallucinations.
LLMs Can Compensate for Deficiencies in Visual Representations
Jun 05, 2025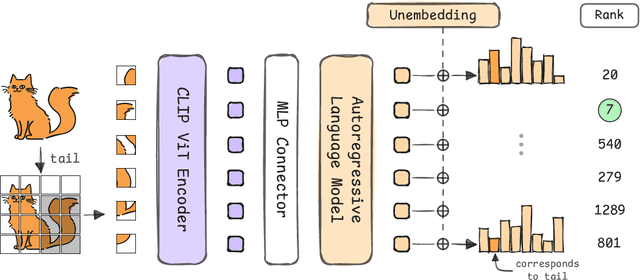
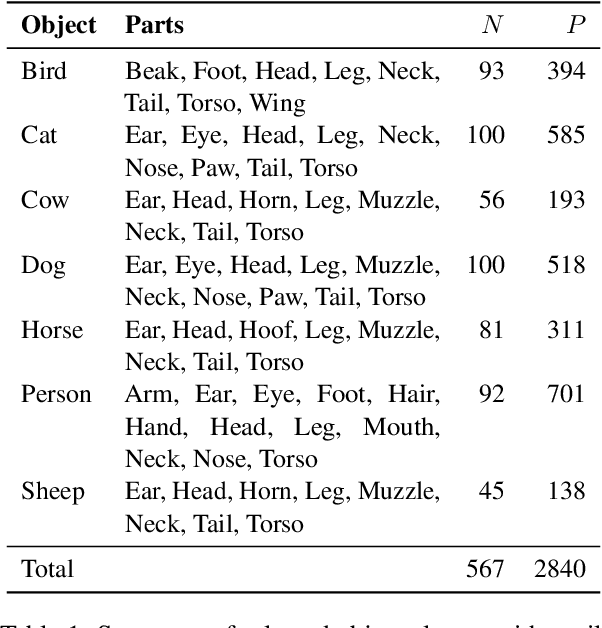
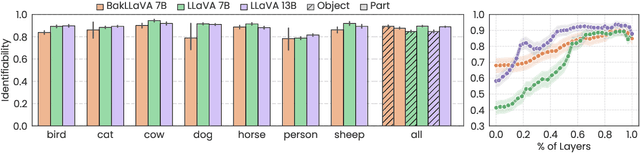

Many vision-language models (VLMs) that prove very effective at a range of multimodal task, build on CLIP-based vision encoders, which are known to have various limitations. We investigate the hypothesis that the strong language backbone in VLMs compensates for possibly weak visual features by contextualizing or enriching them. Using three CLIP-based VLMs, we perform controlled self-attention ablations on a carefully designed probing task. Our findings show that despite known limitations, CLIP visual representations offer ready-to-read semantic information to the language decoder. However, in scenarios of reduced contextualization in the visual representations, the language decoder can largely compensate for the deficiency and recover performance. This suggests a dynamic division of labor in VLMs and motivates future architectures that offload more visual processing to the language decoder.
Overcoming Vocabulary Constraints with Pixel-level Fallback
Apr 02, 2025



Subword tokenization requires balancing computational efficiency and vocabulary coverage, which often leads to suboptimal performance on languages and scripts not prioritized during training. We propose to augment pretrained language models with a vocabulary-free encoder that generates input embeddings from text rendered as pixels. Through experiments on English-centric language models, we demonstrate that our approach substantially improves machine translation performance and facilitates effective cross-lingual transfer, outperforming tokenizer-based methods. Furthermore, we find that pixel-based representations outperform byte-level approaches and standard vocabulary expansion. Our approach enhances the multilingual capabilities of monolingual language models without extensive retraining and reduces decoding latency via input compression.
JEEM: Vision-Language Understanding in Four Arabic Dialects
Mar 27, 2025We introduce JEEM, a benchmark designed to evaluate Vision-Language Models (VLMs) on visual understanding across four Arabic-speaking countries: Jordan, The Emirates, Egypt, and Morocco. JEEM includes the tasks of image captioning and visual question answering, and features culturally rich and regionally diverse content. This dataset aims to assess the ability of VLMs to generalize across dialects and accurately interpret cultural elements in visual contexts. In an evaluation of five prominent open-source Arabic VLMs and GPT-4V, we find that the Arabic VLMs consistently underperform, struggling with both visual understanding and dialect-specific generation. While GPT-4V ranks best in this comparison, the model's linguistic competence varies across dialects, and its visual understanding capabilities lag behind. This underscores the need for more inclusive models and the value of culturally-diverse evaluation paradigms.
Noise is an Efficient Learner for Zero-Shot Vision-Language Models
Feb 09, 2025



Recently, test-time adaptation has garnered attention as a method for tuning models without labeled data. The conventional modus operandi for adapting pre-trained vision-language models (VLMs) during test-time primarily focuses on tuning learnable prompts; however, this approach overlooks potential distribution shifts in the visual representations themselves. In this work, we address this limitation by introducing Test-Time Noise Tuning (TNT), a novel method for handling unpredictable shifts in the visual space. TNT leverages, for the first time, a noise adaptation strategy that optimizes learnable noise directly in the visual input space, enabling adaptive feature learning from a single test sample. We further introduce a novel approach for inter-view representation alignment by explicitly enforcing coherence in embedding distances, ensuring consistent feature representations across views. Combined with scaled logits and confident view selection at inference, TNT substantially enhances VLM generalization and calibration, achieving average gains of +7.38% on natural distributions benchmark and +0.80% on cross-dataset evaluations over zero-shot CLIP. These improvements lay a strong foundation for adaptive out-of-distribution handling.