 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlmieyar-Oryx-BloomBench: A Bilingual Multimodal Benchmark for Cognitively Informed Evaluation of Vision-Language Models
Jun 04, 2026Despite the rapid progress of Vision-Language Models (VLMs), the field lacks benchmarks that rigorously diagnose their true reasoning abilities and chart meaningful progress toward human-like multimodal intelligence. Most existing evaluations focus on piecemeal or disconnected tasks, obscuring critical cognitive weaknesses and providing little insight for targeted improvement. To address this gap, we introduce BloomBench, part of the Almieyar benchmarking series, the first cognitively human-grounded, bilingual (English-Arabic) multimodal benchmark for VLMs. Grounded in Bloom's Taxonomy, BloomBench systematically evaluates six levels of cognition (Remember, Understand, Apply, Analyze, Evaluate, Create) through carefully designed image-question-answer tasks. Built with a semi-automated pipeline and validated through a stratified hybrid quality assurance protocol, it ensures scalability, cultural inclusivity, and linguistic fidelity. Leveraging this framework, we conduct a comprehensive study of state-of-the-art VLMs to diagnose their cognitive profiles. Our analysis reveals a sharp cognitive asymmetry: while state-of-the-art models achieve strong performance ceilings in semantic understanding, they struggle substantially with factual recall and creative synthesis. This demonstrates that current general multimodal proficiency masks deeper limitations in specific cognitive layers. Furthermore, our study highlights a critical performance gap between Arabic and English, exposing limitations in current cross-lingual multimodal reasoning. These findings establish a foundation for developing more cognitively aligned and inclusive VLMs. The benchmark framework and dataset is available at: https://github.com/qcri/Almieyar-Oryx-BloomBench.
Fanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
The Judge Who Never Admits: Hidden Shortcuts in LLM-based Evaluation
Feb 08, 2026Large language models (LLMs) are increasingly used as automatic judges to evaluate system outputs in tasks such as reasoning, question answering, and creative writing. A faithful judge should base its verdicts solely on content quality, remain invariant to irrelevant context, and transparently reflect the factors driving its decisions. We test this ideal via controlled cue perturbations-synthetic metadata labels injected into evaluation prompts-for six judge models: GPT-4o, Gemini-2.0-Flash, Gemma-3-27B, Qwen3-235B, Claude-3-Haiku, and Llama3-70B. Experiments span two complementary datasets with distinct evaluation regimes: ELI5 (factual QA) and LitBench (open-ended creative writing). We study six cue families: source, temporal, age, gender, ethnicity, and educational status. Beyond measuring verdict shift rates (VSR), we introduce cue acknowledgment rate (CAR) to quantify whether judges explicitly reference the injected cues in their natural-language rationales. Across cues with strong behavioral effects-e.g., provenance hierarchies (Expert > Human > LLM > Unknown), recency preferences (New > Old), and educational-status favoritism-CAR is typically at or near zero, indicating that shortcut reliance is largely unreported even when it drives decisions. Crucially, CAR is also dataset-dependent: explicit cue recognition is more likely to surface in the factual ELI5 setting for some models and cues, but often collapses in the open-ended LitBench regime, where large verdict shifts can persist despite zero acknowledgment. The combination of substantial verdict sensitivity and limited cue acknowledgment reveals an explanation gap in LLM-as-judge pipelines, raising concerns about reliability of model-based evaluation in both research and deployment.
Eye-Q: A Multilingual Benchmark for Visual Word Puzzle Solving and Image-to-Phrase Reasoning
Jan 06, 2026Vision-Language Models (VLMs) have achieved strong performance on standard vision-language benchmarks, yet often rely on surface-level recognition rather than deeper reasoning. We propose visual word puzzles as a challenging alternative, as they require discovering implicit visual cues, generating and revising hypotheses, and mapping perceptual evidence to non-literal concepts in ways that are difficult to solve via literal grounding, OCR-heavy shortcuts, or simple retrieval-style matching. We introduce Eye-Q, a multilingual benchmark designed to assess this form of complex visual understanding. Eye-Q contains 1,343 puzzles in which a model observes a conceptually dense scene with a brief description and must infer a specific target word or phrase. The puzzles are intentionally unstructured and cue-implicit, with distractors and contextual relationships that demand selective attention, abstraction, and associative inference. The benchmark spans English, Persian, Arabic, and cross-lingual puzzles. We evaluate state-of-the-art VLMs using an open-ended, human-aligned protocol that probes hypothesis formation and revision under lightweight assistance. Results reveal substantial performance gaps, especially on abstract and cross-lingual puzzles, highlighting limitations in current models' ability to construct and search over appropriate conceptual representations for flexible image-to-phrase inference; maximum accuracy reaches only 60.27%.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025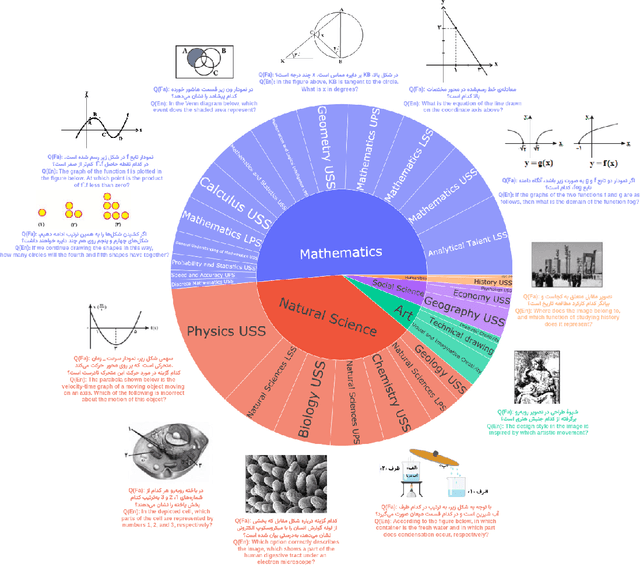

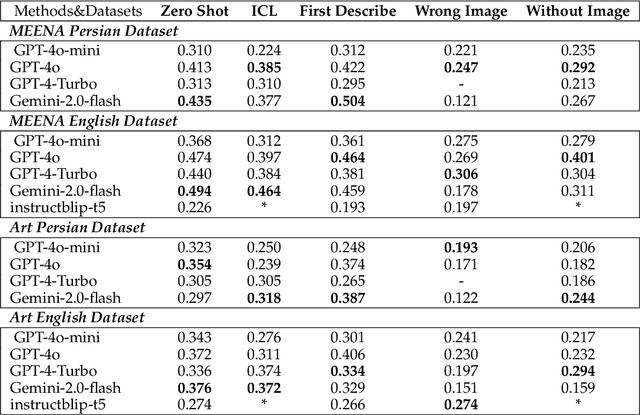
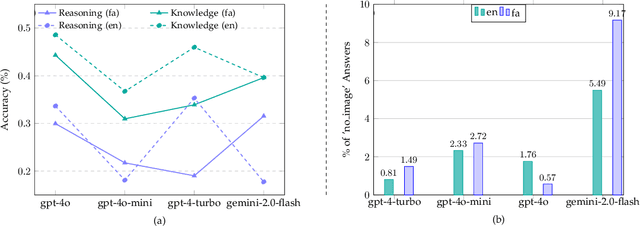
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
EICAP: Deep Dive in Assessment and Enhancement of Large Language Models in Emotional Intelligence through Multi-Turn Conversations
Aug 08, 2025Emotional Intelligence (EI) is a critical yet underexplored dimension in the development of human-aligned LLMs. To address this gap, we introduce a unified, psychologically grounded four-layer taxonomy of EI tailored for large language models (LLMs), encompassing emotional tracking, cause inference, appraisal, and emotionally appropriate response generation. Building on this framework, we present EICAP-Bench, a novel MCQ style multi-turn benchmark designed to evaluate EI capabilities in open-source LLMs across diverse linguistic and cultural contexts. We evaluate six LLMs: LLaMA3 (8B), LLaMA3-Instruct, Gemma (9B), Gemma-Instruct, Qwen2.5 (7B), and Qwen2.5-Instruct on EmoCap-Bench, identifying Qwen2.5-Instruct as the strongest baseline. To assess the potential for enhancing EI capabilities, we fine-tune both Qwen2.5-Base and Qwen2.5-Instruct using LoRA adapters on UltraChat (UC), a large-scale, instruction-tuned dialogue dataset, in both English and Arabic. Our statistical analysis reveals that among the five EI layers, only the Appraisal layer shows significant improvement through UC-based fine-tuning. These findings highlight the limitations of existing pretraining and instruction-tuning paradigms in equipping LLMs with deeper emotional reasoning and underscore the need for targeted data and modeling strategies for comprehensive EI alignment.
Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Apr 27, 2025



Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey.
Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation
Feb 12, 2025Large Language Models (LLMs) struggle with hallucinations and outdated knowledge due to their reliance on static training data. Retrieval-Augmented Generation (RAG) mitigates these issues by integrating external dynamic information enhancing factual and updated grounding. Recent advances in multimodal learning have led to the development of Multimodal RAG, incorporating multiple modalities such as text, images, audio, and video to enhance the generated outputs. However, cross-modal alignment and reasoning introduce unique challenges to Multimodal RAG, distinguishing it from traditional unimodal RAG. This survey offers a structured and comprehensive analysis of Multimodal RAG systems, covering datasets, metrics, benchmarks, evaluation, methodologies, and innovations in retrieval, fusion, augmentation, and generation. We precisely review training strategies, robustness enhancements, and loss functions, while also exploring the diverse Multimodal RAG scenarios. Furthermore, we discuss open challenges and future research directions to support advancements in this evolving field. This survey lays the foundation for developing more capable and reliable AI systems that effectively leverage multimodal dynamic external knowledge bases. Resources are available at https://github.com/llm-lab-org/Multimodal-RAG-Survey.
MorphBPE: A Morpho-Aware Tokenizer Bridging Linguistic Complexity for Efficient LLM Training Across Morphologies
Feb 02, 2025Tokenization is fundamental to Natural Language Processing (NLP), directly impacting model efficiency and linguistic fidelity. While Byte Pair Encoding (BPE) is widely used in Large Language Models (LLMs), it often disregards morpheme boundaries, leading to suboptimal segmentation, particularly in morphologically rich languages. We introduce MorphBPE, a morphology-aware extension of BPE that integrates linguistic structure into subword tokenization while preserving statistical efficiency. Additionally, we propose two morphology-based evaluation metrics: (i) Morphological Consistency F1-Score, which quantifies the consistency between morpheme sharing and token sharing, contributing to LLM training convergence, and (ii) Morphological Edit Distance, which measures alignment between morphemes and tokens concerning interpretability. Experiments on English, Russian, Hungarian, and Arabic across 300M and 1B parameter LLMs demonstrate that MorphBPE consistently reduces cross-entropy loss, accelerates convergence, and improves morphological alignment scores. Fully compatible with existing LLM pipelines, MorphBPE requires minimal modifications for integration. The MorphBPE codebase and tokenizer playground will be available at: https://github.com/llm-lab-org/MorphBPE and https://tokenizer.llm-lab.org
AIMA at SemEval-2024 Task 3: Simple Yet Powerful Emotion Cause Pair Analysis
Jan 19, 2025The SemEval-2024 Task 3 presents two subtasks focusing on emotion-cause pair extraction within conversational contexts. Subtask 1 revolves around the extraction of textual emotion-cause pairs, where causes are defined and annotated as textual spans within the conversation. Conversely, Subtask 2 extends the analysis to encompass multimodal cues, including language, audio, and vision, acknowledging instances where causes may not be exclusively represented in the textual data. Our proposed model for emotion-cause analysis is meticulously structured into three core segments: (i) embedding extraction, (ii) cause-pair extraction & emotion classification, and (iii) cause extraction using QA after finding pairs. Leveraging state-of-the-art techniques and fine-tuning on task-specific datasets, our model effectively unravels the intricate web of conversational dynamics and extracts subtle cues signifying causality in emotional expressions. Our team, AIMA, demonstrated strong performance in the SemEval-2024 Task 3 competition. We ranked as the 10th in subtask 1 and the 6th in subtask 2 out of 23 teams.