 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Classification and Calibration Performance in Decision-Making LLMs via Calibration Aware Reinforcement Learning
Jan 19, 2026Large language models (LLMs) are increasingly deployed in decision-making tasks, where not only accuracy but also reliable confidence estimates are essential. Well-calibrated confidence enables downstream systems to decide when to trust a model and when to defer to fallback mechanisms. In this work, we conduct a systematic study of calibration in two widely used fine-tuning paradigms: supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). We show that while RLVR improves task performance, it produces extremely overconfident models, whereas SFT yields substantially better calibration, even under distribution shift, though with smaller performance gains. Through targeted experiments, we diagnose RLVR's failure, showing that decision tokens act as extraction steps of the decision in reasoning traces and do not carry confidence information, which prevents reinforcement learning from surfacing calibrated alternatives. Based on this insight, we propose a calibration-aware reinforcement learning formulation that directly adjusts decision-token probabilities. Our method preserves RLVR's accuracy level while mitigating overconfidence, reducing ECE scores up to 9 points.
Exploration of Plan-Guided Summarization for Narrative Texts: the Case of Small Language Models
Apr 12, 2025



Plan-guided summarization attempts to reduce hallucinations in small language models (SLMs) by grounding generated summaries to the source text, typically by targeting fine-grained details such as dates or named entities. In this work, we investigate whether plan-based approaches in SLMs improve summarization in long document, narrative tasks. Narrative texts' length and complexity often mean they are difficult to summarize faithfully. We analyze existing plan-guided solutions targeting fine-grained details, and also propose our own higher-level, narrative-based plan formulation. Our results show that neither approach significantly improves on a baseline without planning in either summary quality or faithfulness. Human evaluation reveals that while plan-guided approaches are often well grounded to their plan, plans are equally likely to contain hallucinations compared to summaries. As a result, the plan-guided summaries are just as unfaithful as those from models without planning. Our work serves as a cautionary tale to plan-guided approaches to summarization, especially for long, complex domains such as narrative texts.
A Multi-Modal Multilingual Benchmark for Document Image Classification
Oct 25, 2023



Document image classification is different from plain-text document classification and consists of classifying a document by understanding the content and structure of documents such as forms, emails, and other such documents. We show that the only existing dataset for this task (Lewis et al., 2006) has several limitations and we introduce two newly curated multilingual datasets WIKI-DOC and MULTIEURLEX-DOC that overcome these limitations. We further undertake a comprehensive study of popular visually-rich document understanding or Document AI models in previously untested setting in document image classification such as 1) multi-label classification, and 2) zero-shot cross-lingual transfer setup. Experimental results show limitations of multilingual Document AI models on cross-lingual transfer across typologically distant languages. Our datasets and findings open the door for future research into improving Document AI models.
A Weak Supervision Approach for Few-Shot Aspect Based Sentiment
May 19, 2023



We explore how weak supervision on abundant unlabeled data can be leveraged to improve few-shot performance in aspect-based sentiment analysis (ABSA) tasks. We propose a pipeline approach to construct a noisy ABSA dataset, and we use it to adapt a pre-trained sequence-to-sequence model to the ABSA tasks. We test the resulting model on three widely used ABSA datasets, before and after fine-tuning. Our proposed method preserves the full fine-tuning performance while showing significant improvements (15.84% absolute F1) in the few-shot learning scenario for the harder tasks. In zero-shot (i.e., without fine-tuning), our method outperforms the previous state of the art on the aspect extraction sentiment classification (AESC) task and is, additionally, capable of performing the harder aspect sentiment triplet extraction (ASTE) task.
Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis
Oct 12, 2022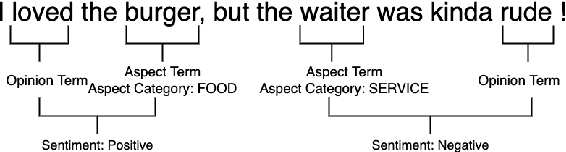
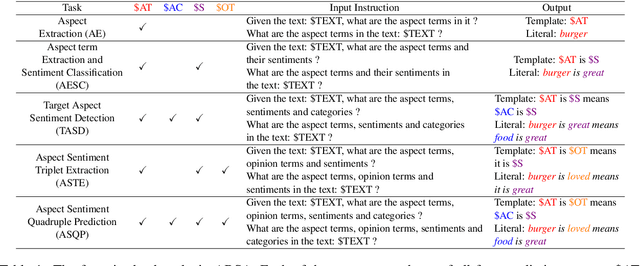
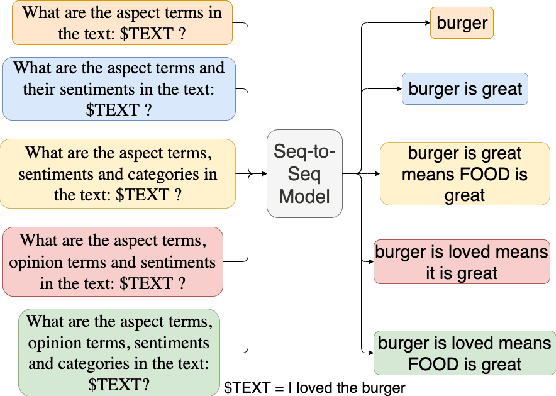
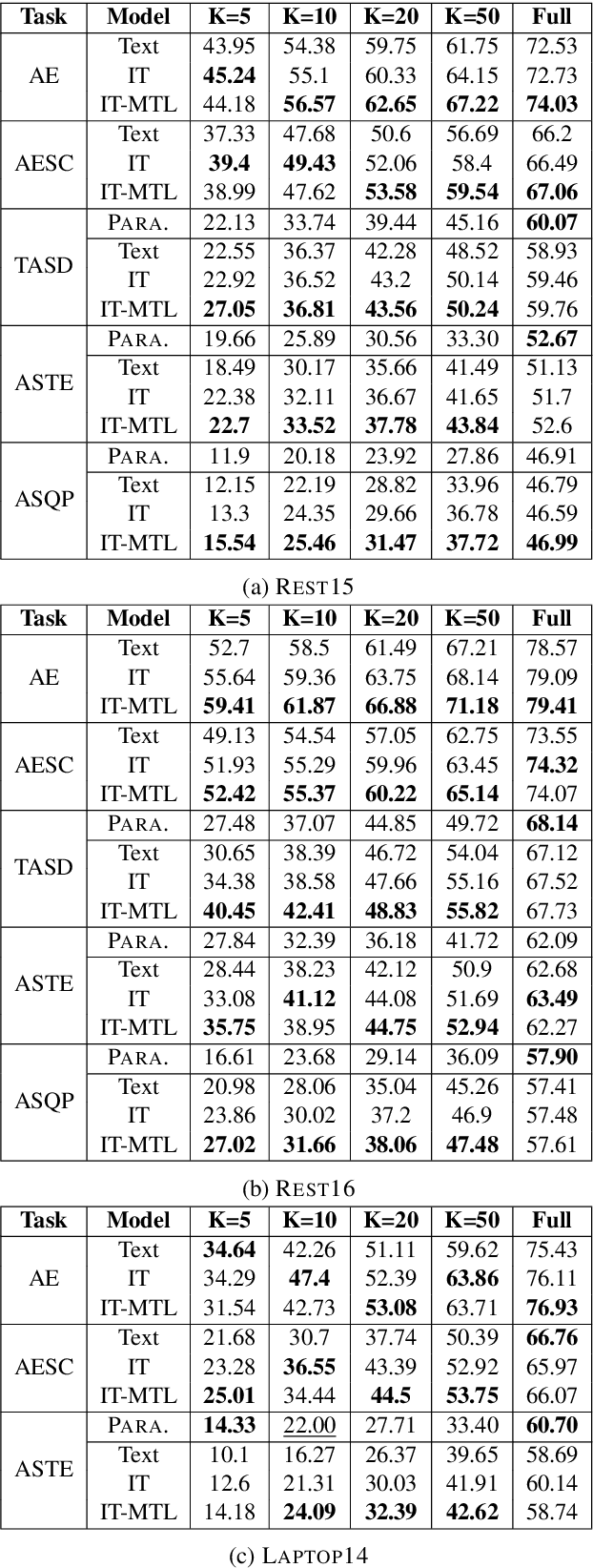
Aspect-based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task which involves four elements from user-generated texts: aspect term, aspect category, opinion term, and sentiment polarity. Most computational approaches focus on some of the ABSA sub-tasks such as tuple (aspect term, sentiment polarity) or triplet (aspect term, opinion term, sentiment polarity) extraction using either pipeline or joint modeling approaches. Recently, generative approaches have been proposed to extract all four elements as (one or more) quadruplets from text as a single task. In this work, we take a step further and propose a unified framework for solving ABSA, and the associated sub-tasks to improve the performance in few-shot scenarios. To this end, we fine-tune a T5 model with instructional prompts in a multi-task learning fashion covering all the sub-tasks, as well as the entire quadruple prediction task. In experiments with multiple benchmark data sets, we show that the proposed multi-task prompting approach brings performance boost (by absolute $6.75$ F1) in the few-shot learning setting.
DeSePtion: Dual Sequence Prediction and Adversarial Examples for Improved Fact-Checking
Apr 27, 2020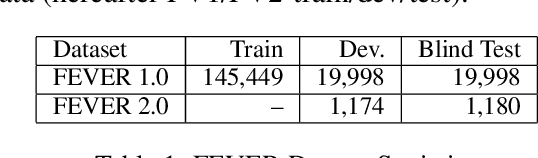
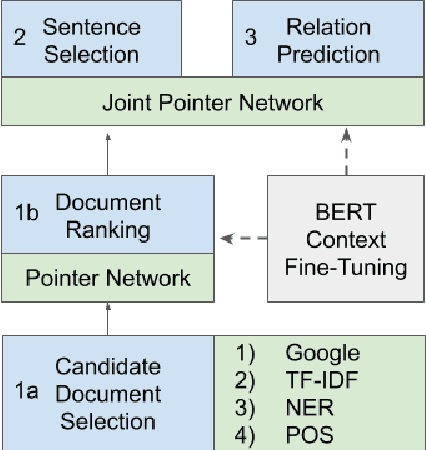
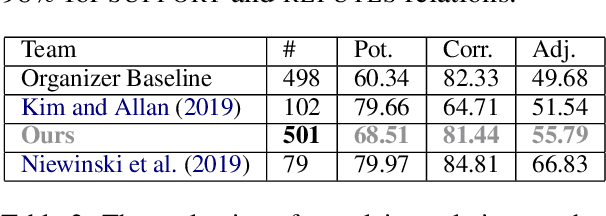
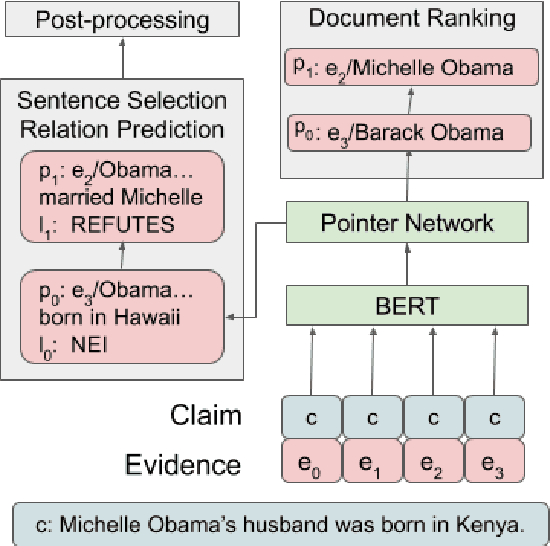
The increased focus on misinformation has spurred development of data and systems for detecting the veracity of a claim as well as retrieving authoritative evidence. The Fact Extraction and VERification (FEVER) dataset provides such a resource for evaluating end-to-end fact-checking, requiring retrieval of evidence from Wikipedia to validate a veracity prediction. We show that current systems for FEVER are vulnerable to three categories of realistic challenges for fact-checking -- multiple propositions, temporal reasoning, and ambiguity and lexical variation -- and introduce a resource with these types of claims. Then we present a system designed to be resilient to these "attacks" using multiple pointer networks for document selection and jointly modeling a sequence of evidence sentences and veracity relation predictions. We find that in handling these attacks we obtain state-of-the-art results on FEVER, largely due to improved evidence retrieval.
Detecting Gang-Involved Escalation on Social Media Using Context
Sep 10, 2018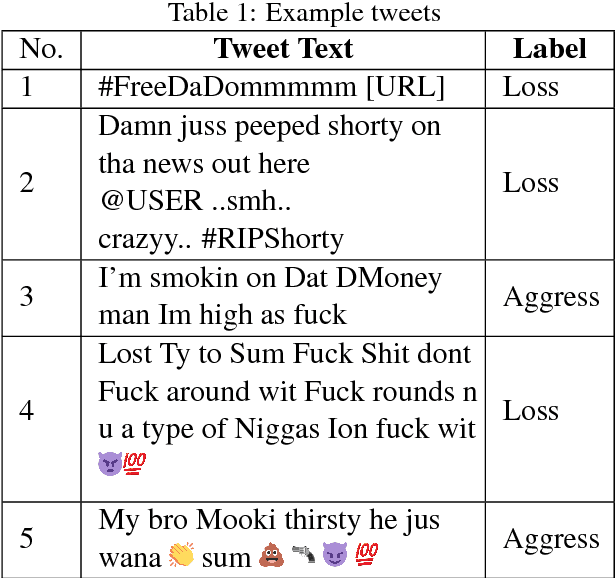
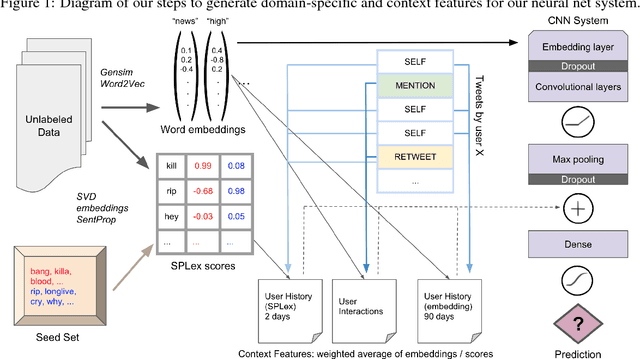
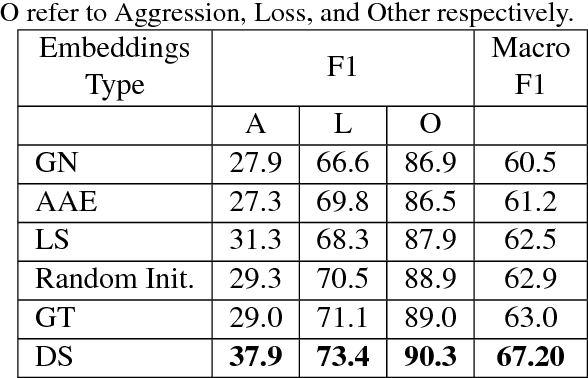
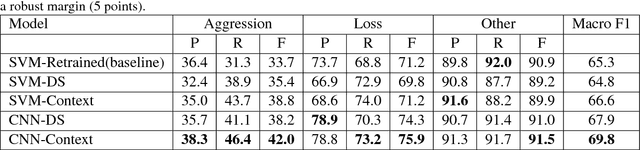
Gang-involved youth in cities such as Chicago have increasingly turned to social media to post about their experiences and intents online. In some situations, when they experience the loss of a loved one, their online expression of emotion may evolve into aggression towards rival gangs and ultimately into real-world violence. In this paper, we present a novel system for detecting Aggression and Loss in social media. Our system features the use of domain-specific resources automatically derived from a large unlabeled corpus, and contextual representations of the emotional and semantic content of the user's recent tweets as well as their interactions with other users. Incorporating context in our Convolutional Neural Network (CNN) leads to a significant improvement.
* 12 pages
Multimodal Social Media Analysis for Gang Violence Prevention
Jul 23, 2018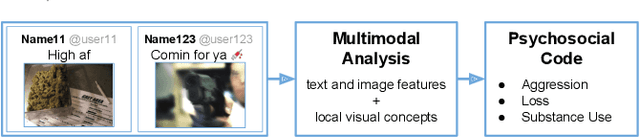
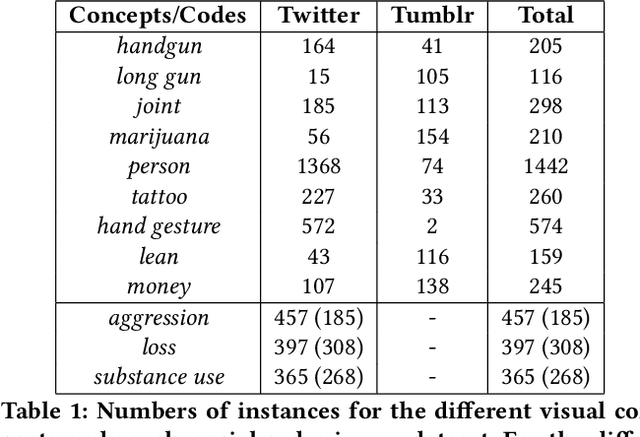

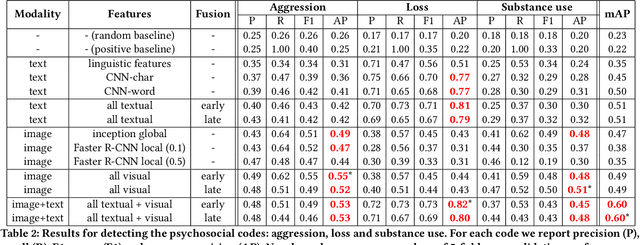
Gang violence is a severe issue in major cities across the U.S. and recent studies [Patton et al. 2017] have found evidence of social media communications that can be linked to such violence in communities with high rates of exposure to gang activity. In this paper we partnered computer scientists with social work researchers, who have domain expertise in gang violence, to analyze how public tweets with images posted by youth who mention gang associations on Twitter can be leveraged to automatically detect psychosocial factors and conditions that could potentially assist social workers and violence outreach workers in prevention and early intervention programs. To this end, we developed a rigorous methodology for collecting and annotating tweets. We gathered 1,851 tweets and accompanying annotations related to visual concepts and the psychosocial codes: aggression, loss, and substance use. These codes are relevant to social work interventions, as they represent possible pathways to violence on social media. We compare various methods for classifying tweets into these three classes, using only the text of the tweet, only the image of the tweet, or both modalities as input to the classifier. In particular, we analyze the usefulness of mid-level visual concepts and the role of different modalities for this tweet classification task. Our experiments show that individually, text information dominates classification performance of the loss class, while image information dominates the aggression and substance use classes. Our multimodal approach provides a very promising improvement (18% relative in mean average precision) over the best single modality approach. Finally, we also illustrate the complexity of understanding social media data and elaborate on open challenges.