 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncertainty-Aware Multi-View Representation Learning
Jan 15, 2022
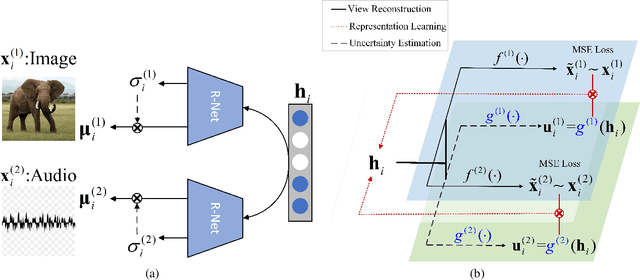
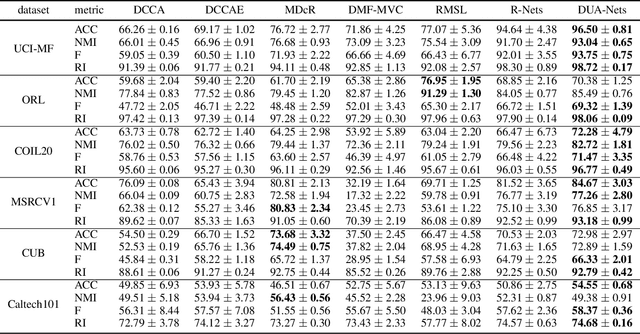
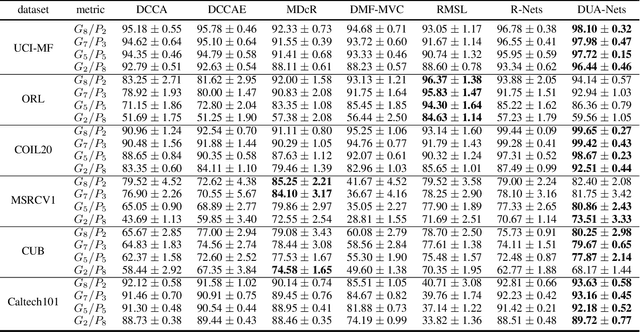
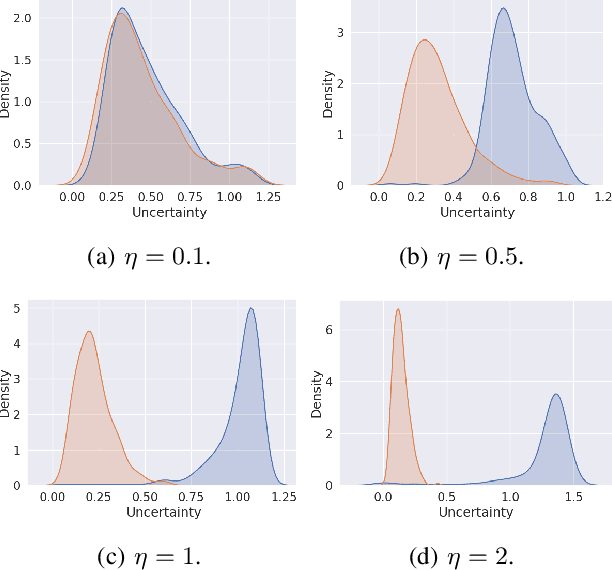
Learning from different data views by exploring the underlying complementary information among them can endow the representation with stronger expressive ability. However, high-dimensional features tend to contain noise, and furthermore, the quality of data usually varies for different samples (even for different views), i.e., one view may be informative for one sample but not the case for another. Therefore, it is quite challenging to integrate multi-view noisy data under unsupervised setting. Traditional multi-view methods either simply treat each view with equal importance or tune the weights of different views to fixed values, which are insufficient to capture the dynamic noise in multi-view data. In this work, we devise a novel unsupervised multi-view learning approach, termed as Dynamic Uncertainty-Aware Networks (DUA-Nets). Guided by the uncertainty of data estimated from the generation perspective, intrinsic information from multiple views is integrated to obtain noise-free representations. Under the help of uncertainty, DUA-Nets weigh each view of individual sample according to data quality so that the high-quality samples (or views) can be fully exploited while the effects from the noisy samples (or views) will be alleviated. Our model achieves superior performance in extensive experiments and shows the robustness to noisy data.
Fundamental Limits of Obfuscation for Linear Gaussian Dynamical Systems: An Information-Theoretic Approach
Oct 29, 2020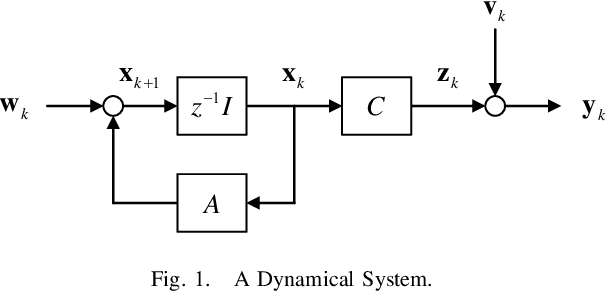
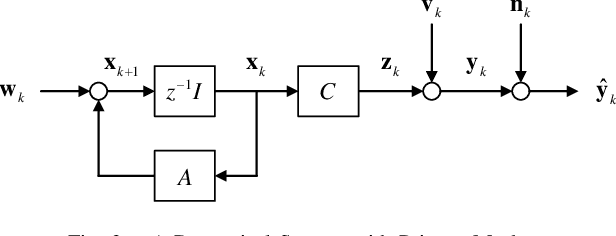
In this paper, we study the fundamental limits of obfuscation in terms of privacy-distortion tradeoffs for linear Gaussian dynamical systems via an information-theoretic approach. Particularly, we obtain analytical formulas that capture the fundamental privacy-distortion tradeoffs when privacy masks are to be added to the outputs of the dynamical systems, while indicating explicitly how to design the privacy masks in an optimal way: The privacy masks should be colored Gaussian with power spectra shaped specifically based upon the system and noise properties.
Live Laparoscopic Video Retrieval with Compressed Uncertainty
Mar 08, 2022Searching through large volumes of medical data to retrieve relevant information is a challenging yet crucial task for clinical care. However the primitive and most common approach to retrieval, involving text in the form of keywords, is severely limited when dealing with complex media formats. Content-based retrieval offers a way to overcome this limitation, by using rich media as the query itself. Surgical video-to-video retrieval in particular is a new and largely unexplored research problem with high clinical value, especially in the real-time case: using real-time video hashing, search can be achieved directly inside of the operating room. Indeed, the process of hashing converts large data entries into compact binary arrays or hashes, enabling large-scale search operations at a very fast rate. However, due to fluctuations over the course of a video, not all bits in a given hash are equally reliable. In this work, we propose a method capable of mitigating this uncertainty while maintaining a light computational footprint. We present superior retrieval results (3-4 % top 10 mean average precision) on a multi-task evaluation protocol for surgery, using cholecystectomy phases, bypass phases, and coming from an entirely new dataset introduced here, critical events across six different surgery types. Success on this multi-task benchmark shows the generalizability of our approach for surgical video retrieval.
Scale Estimation with Dual Quadrics for Monocular Object SLAM
Feb 10, 2022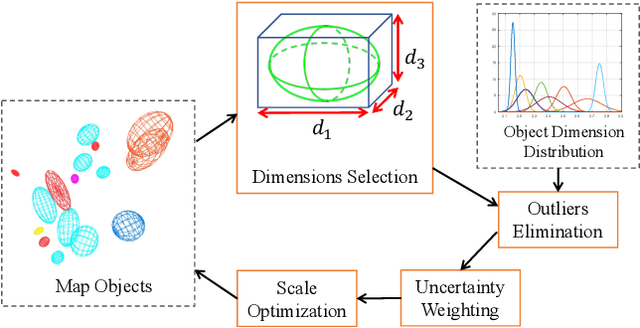
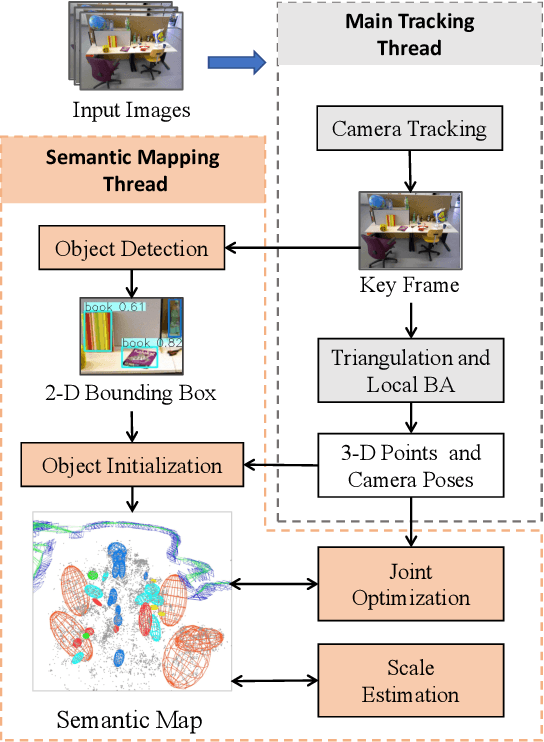
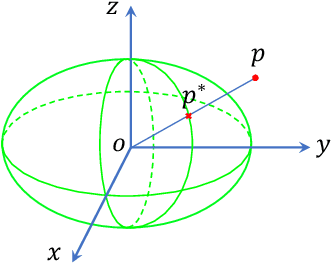
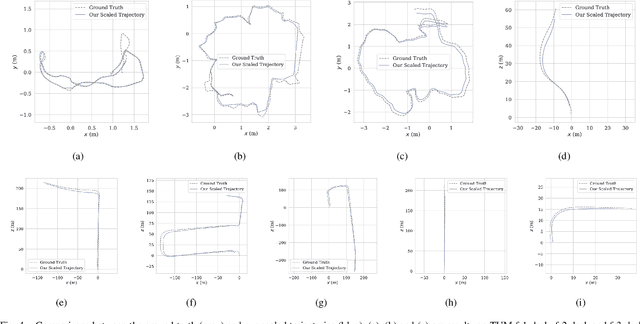
The scale ambiguity problem is inherently unsolvable to monocular SLAM without the metric baseline between moving cameras. In this paper, we present a novel scale estimation approach based on an object-level SLAM system. To obtain the absolute scale of the reconstructed map, we derive a nonlinear optimization method to make the scaled dimensions of objects conforming to the distribution of their sizes in the physical world, without relying on any prior information of gravity direction. We adopt the dual quadric to represent objects for its ability to fit objects compactly and accurately. In the proposed monocular object-level SLAM system, dual quadrics are fastly initialized based on constraints of 2-D detections and fitted oriented bounding box and are further optimized to provide reliable dimensions for scale estimation.
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 15, 2022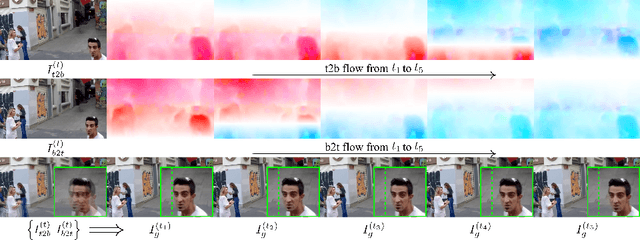

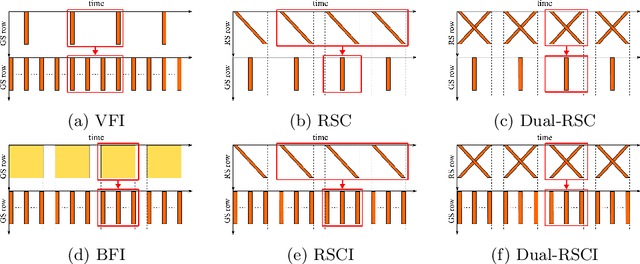
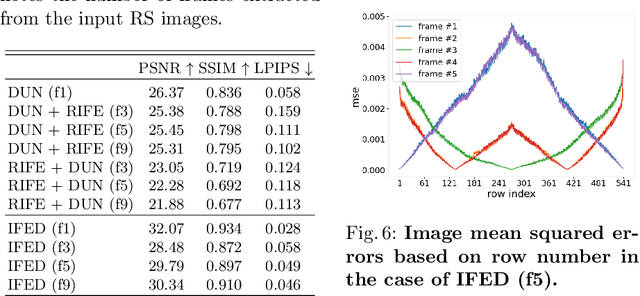
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
Source-free Domain Adaptation for Multi-site and Lifespan Brain Skull Stripping
Mar 08, 2022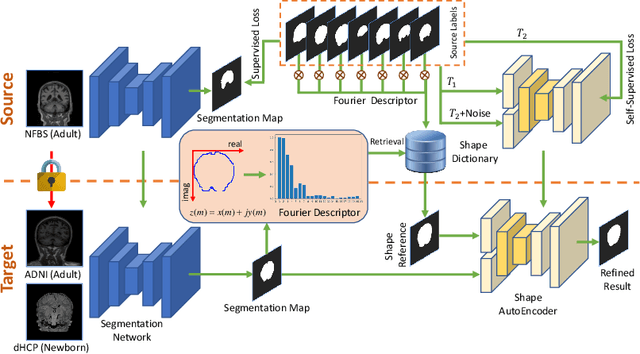

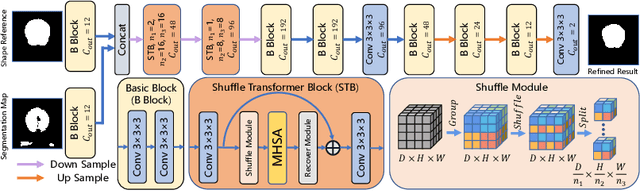

Skull stripping is a crucial prerequisite step in the analysis of brain magnetic resonance (MR) images. Although many excellent works or tools have been proposed, they suffer from low generalization capability. For instance, the model trained on a dataset with specific imaging parameters (source domain) cannot be well applied to other datasets with different imaging parameters (target domain). Especially, for the lifespan datasets, the model trained on an adult dataset is not applicable to an infant dataset due to the large domain difference. To address this issue, numerous domain adaptation (DA) methods have been proposed to align the extracted features between the source and target domains, requiring concurrent access to the input images of both domains. Unfortunately, it is problematic to share the images due to privacy. In this paper, we design a source-free domain adaptation framework (SDAF) for multi-site and lifespan skull stripping that can accomplish domain adaptation without access to source domain images. Our method only needs to share the source labels as shape dictionaries and the weights trained on the source data, without disclosing private information from source domain subjects. To deal with the domain shift between multi-site lifespan datasets, we take advantage of the brain shape prior which is invariant to imaging parameters and ages. Experiments demonstrate that our framework can significantly outperform the state-of-the-art methods on multi-site lifespan datasets.
Shaped Four-Dimensional Modulation Formats for Optical Fiber Communication Systems
Dec 23, 2021We review the design of multidimensional modulations by maximizing generalized mutual information and compare the maximum transmission reach of recently introduced 4D formats. A model-based optimization for nonlinear-tolerant 4D modulations is also discussed.
Multi-Robot Collaborative Perception with Graph Neural Networks
Jan 05, 2022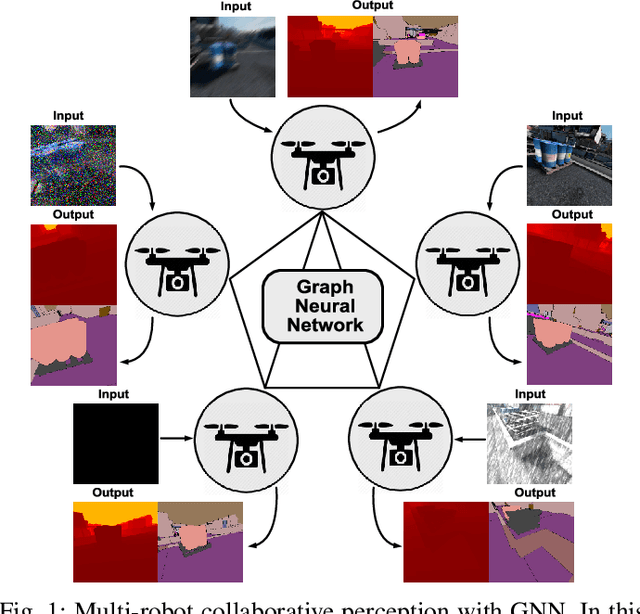

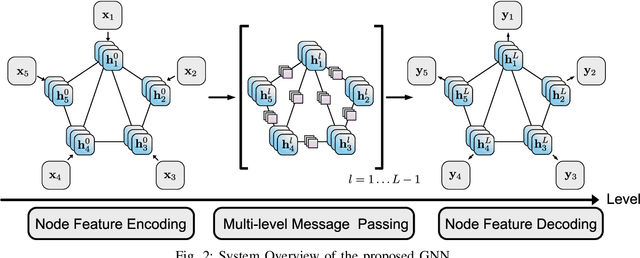
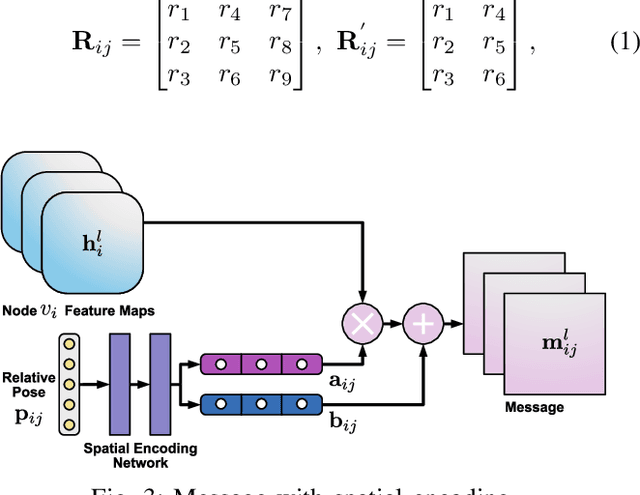
Multi-robot systems such as swarms of aerial robots are naturally suited to offer additional flexibility, resilience, and robustness in several tasks compared to a single robot by enabling cooperation among the agents. To enhance the autonomous robot decision-making process and situational awareness, multi-robot systems have to coordinate their perception capabilities to collect, share, and fuse environment information among the agents in an efficient and meaningful way such to accurately obtain context-appropriate information or gain resilience to sensor noise or failures. In this paper, we propose a general-purpose Graph Neural Network (GNN) with the main goal to increase, in multi-robot perception tasks, single robots' inference perception accuracy as well as resilience to sensor failures and disturbances. We show that the proposed framework can address multi-view visual perception problems such as monocular depth estimation and semantic segmentation. Several experiments both using photo-realistic and real data gathered from multiple aerial robots' viewpoints show the effectiveness of the proposed approach in challenging inference conditions including images corrupted by heavy noise and camera occlusions or failures.
TransCMD: Cross-Modal Decoder Equipped with Transformer for RGB-D Salient Object Detection
Dec 04, 2021



Most of the existing RGB-D salient object detection methods utilize the convolution operation and construct complex interweave fusion structures to achieve cross-modal information integration. The inherent local connectivity of convolution operation constrains the performance of the convolution-based methods to a ceiling. In this work, we rethink this task from the perspective of global information alignment and transformation. Specifically, the proposed method (TransCMD) cascades several cross-modal integration units to construct a top-down transformer-based information propagation path (TIPP). TransCMD treats the multi-scale and multi-modal feature integration as a sequence-to-sequence context propagation and update process built on the transformer. Besides, considering the quadratic complexity w.r.t. the number of input tokens, we design a patch-wise token re-embedding strategy (PTRE) with acceptable computational cost. Experimental results on seven RGB-D SOD benchmark datasets demonstrate that a simple two-stream encoder-decoder framework can surpass the state-of-the-art purely CNN-based methods when it is equipped with the TIPP.
Dynamic Rectification Knowledge Distillation
Jan 27, 2022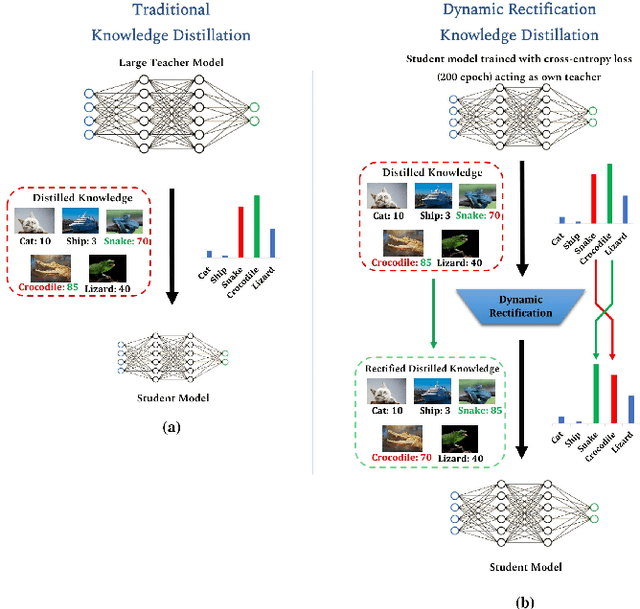
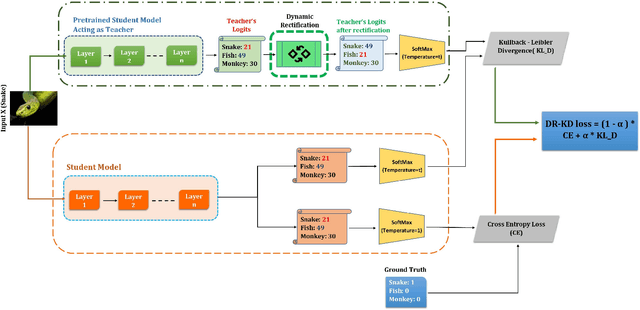
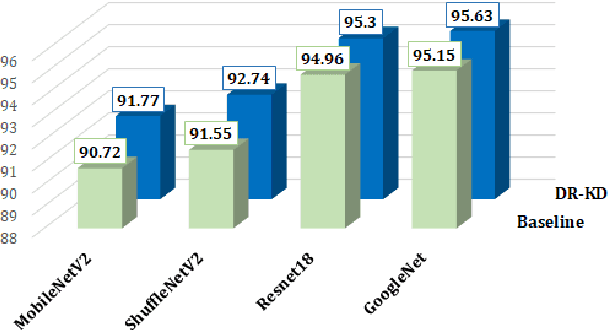
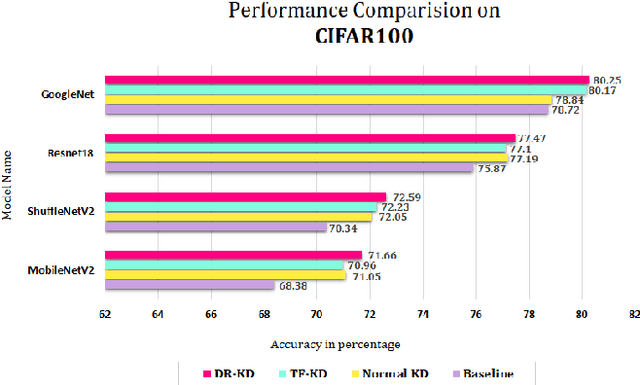
Knowledge Distillation is a technique which aims to utilize dark knowledge to compress and transfer information from a vast, well-trained neural network (teacher model) to a smaller, less capable neural network (student model) with improved inference efficiency. This approach of distilling knowledge has gained popularity as a result of the prohibitively complicated nature of such cumbersome models for deployment on edge computing devices. Generally, the teacher models used to teach smaller student models are cumbersome in nature and expensive to train. To eliminate the necessity for a cumbersome teacher model completely, we propose a simple yet effective knowledge distillation framework that we termed Dynamic Rectification Knowledge Distillation (DR-KD). Our method transforms the student into its own teacher, and if the self-teacher makes wrong predictions while distilling information, the error is rectified prior to the knowledge being distilled. Specifically, the teacher targets are dynamically tweaked by the agency of ground-truth while distilling the knowledge gained from traditional training. Our proposed DR-KD performs remarkably well in the absence of a sophisticated cumbersome teacher model and achieves comparable performance to existing state-of-the-art teacher-free knowledge distillation frameworks when implemented by a low-cost dynamic mannered teacher. Our approach is all-encompassing and can be utilized for any deep neural network training that requires categorization or object recognition. DR-KD enhances the test accuracy on Tiny ImageNet by 2.65% over prominent baseline models, which is significantly better than any other knowledge distillation approach while requiring no additional training costs.