 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Robotic Visual Grasping Design: Rethinking Convolution Neural Network with High-Resolutions
Sep 16, 2022

High-resolution representations are important for vision-based robotic grasping problems. Existing works generally encode the input images into low-resolution representations via sub-networks and then recover high-resolution representations. This will lose spatial information, and errors introduced by the decoder will be more serious when multiple types of objects are considered or objects are far away from the camera. To address these issues, we revisit the design paradigm of CNN for robotic perception tasks. We demonstrate that using parallel branches as opposed to serial stacked convolutional layers will be a more powerful design for robotic visual grasping tasks. In particular, guidelines of neural network design are provided for robotic perception tasks, e.g., high-resolution representation and lightweight design, which respond to the challenges in different manipulation scenarios. We then develop a novel grasping visual architecture referred to as HRG-Net, a parallel-branch structure that always maintains a high-resolution representation and repeatedly exchanges information across resolutions. Extensive experiments validate that these two designs can effectively enhance the accuracy of visual-based grasping and accelerate network training. We show a series of comparative experiments in real physical environments at Youtube: https://youtu.be/Jhlsp-xzHFY.
Deep Bidirectional Language-Knowledge Graph Pretraining
Oct 19, 2022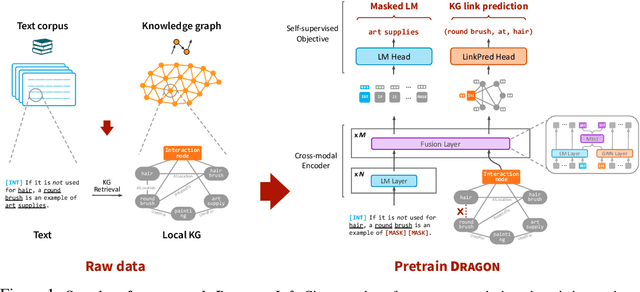

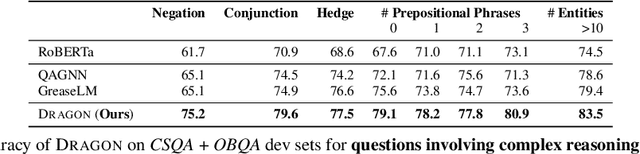

Pretraining a language model (LM) on text has been shown to help various downstream NLP tasks. Recent works show that a knowledge graph (KG) can complement text data, offering structured background knowledge that provides a useful scaffold for reasoning. However, these works are not pretrained to learn a deep fusion of the two modalities at scale, limiting the potential to acquire fully joint representations of text and KG. Here we propose DRAGON (Deep Bidirectional Language-Knowledge Graph Pretraining), a self-supervised approach to pretraining a deeply joint language-knowledge foundation model from text and KG at scale. Specifically, our model takes pairs of text segments and relevant KG subgraphs as input and bidirectionally fuses information from both modalities. We pretrain this model by unifying two self-supervised reasoning tasks, masked language modeling and KG link prediction. DRAGON outperforms existing LM and LM+KG models on diverse downstream tasks including question answering across general and biomedical domains, with +5% absolute gain on average. In particular, DRAGON achieves notable performance on complex reasoning about language and knowledge (+10% on questions involving long contexts or multi-step reasoning) and low-resource QA (+8% on OBQA and RiddleSense), and new state-of-the-art results on various BioNLP tasks. Our code and trained models are available at https://github.com/michiyasunaga/dragon.
Towards Accurate Subgraph Similarity Computation via Neural Graph Pruning
Oct 19, 2022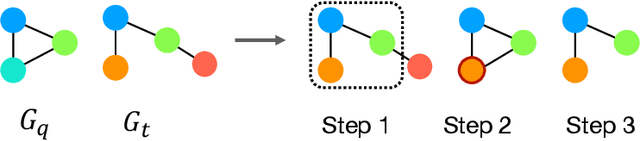
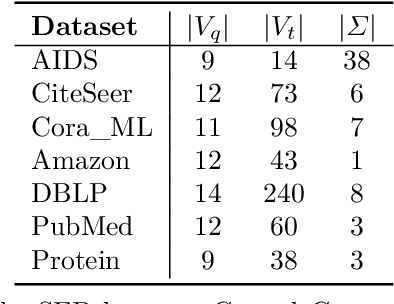
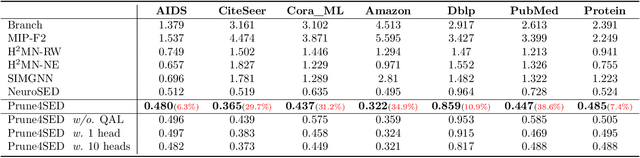
Subgraph similarity search, one of the core problems in graph search, concerns whether a target graph approximately contains a query graph. The problem is recently touched by neural methods. However, current neural methods do not consider pruning the target graph, though pruning is critically important in traditional calculations of subgraph similarities. One obstacle to applying pruning in neural methods is {the discrete property of pruning}. In this work, we convert graph pruning to a problem of node relabeling and then relax it to a differentiable problem. Based on this idea, we further design a novel neural network to approximate a type of subgraph distance: the subgraph edit distance (SED). {In particular, we construct the pruning component using a neural structure, and the entire model can be optimized end-to-end.} In the design of the model, we propose an attention mechanism to leverage the information about the query graph and guide the pruning of the target graph. Moreover, we develop a multi-head pruning strategy such that the model can better explore multiple ways of pruning the target graph. The proposed model establishes new state-of-the-art results across seven benchmark datasets. Extensive analysis of the model indicates that the proposed model can reasonably prune the target graph for SED computation. The implementation of our algorithm is released at our Github repo: https://github.com/tufts-ml/Prune4SED.
Domain generalization Person Re-identification on Attention-aware multi-operation strategery
Oct 19, 2022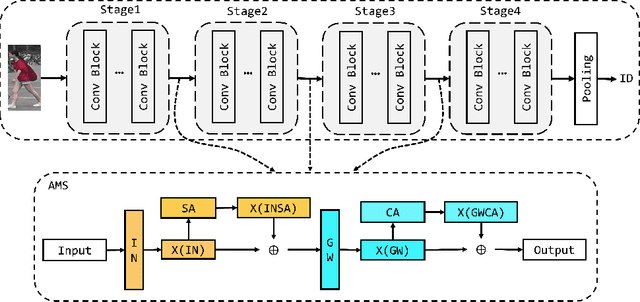
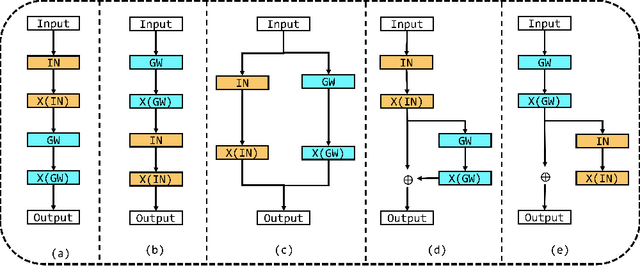
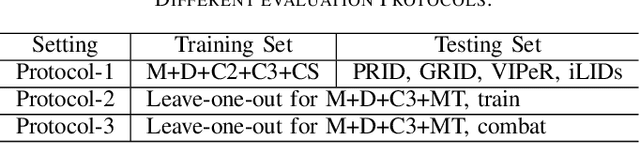
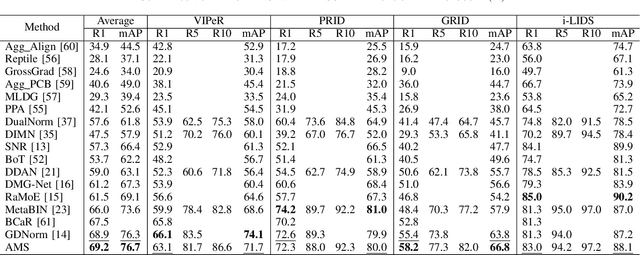
Domain generalization person re-identification (DG Re-ID) aims to directly deploy a model trained on the source domain to the unseen target domain with good generalization, which is a challenging problem and has practical value in a real-world deployment. In the existing DG Re-ID methods, invariant operations are effective in extracting domain generalization features, and Instance Normalization (IN) or Batch Normalization (BN) is used to alleviate the bias to unseen domains. Due to domain-specific information being used to capture discriminability of the individual source domain, the generalized ability for unseen domains is unsatisfactory. To address this problem, an Attention-aware Multi-operation Strategery (AMS) for DG Re-ID is proposed to extract more generalized features. We investigate invariant operations and construct a multi-operation module based on IN and group whitening (GW) to extract domain-invariant feature representations. Furthermore, we analyze different domain-invariant characteristics, and apply spatial attention to the IN operation and channel attention to the GW operation to enhance the domain-invariant features. The proposed AMS module can be used as a plug-and-play module to incorporate into existing network architectures. Extensive experimental results show that AMS can effectively enhance the model's generalization ability to unseen domains and significantly improves the recognition performance in DG Re-ID on three protocols with ten datasets.
Over-the-Air Computation: Foundations, Technologies, and Applications
Oct 19, 2022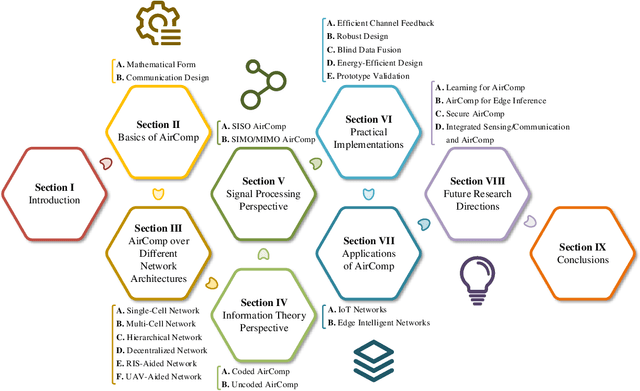
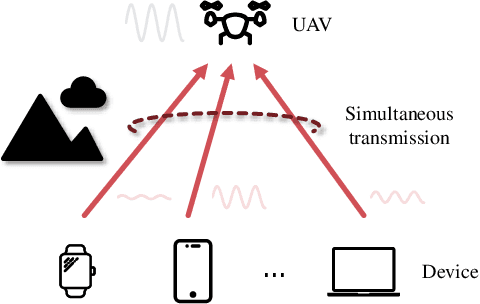
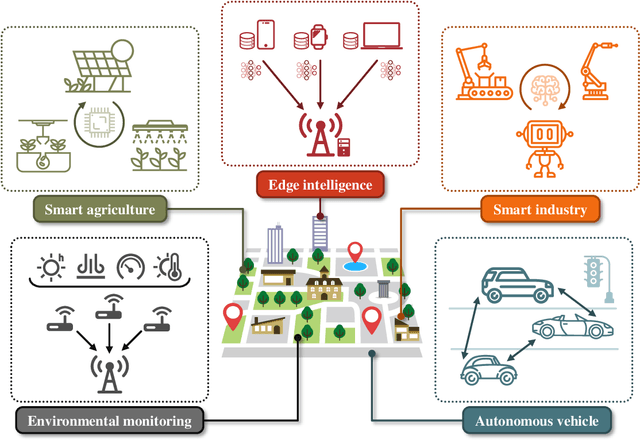
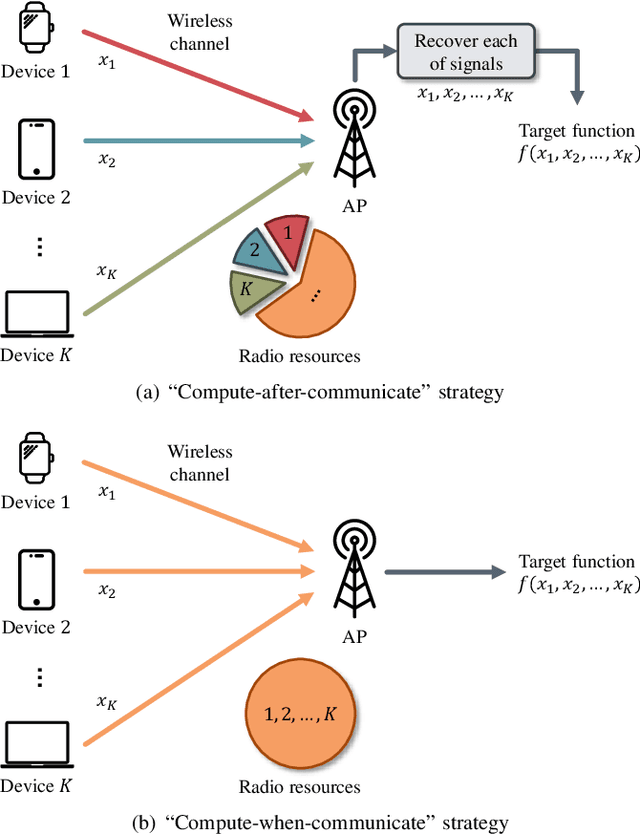
The rapid advancement of artificial intelligence technologies has given rise to diversified intelligent services, which place unprecedented demands on massive connectivity and gigantic data aggregation. However, the scarce radio resources and stringent latency requirement make it challenging to meet these demands. To tackle these challenges, over-the-air computation (AirComp) emerges as a potential technology. Specifically, AirComp seamlessly integrates the communication and computation procedures through the superposition property of multiple-access channels, which yields a revolutionary multiple-access paradigm shift from "compute-after-communicate" to "compute-when-communicate". Meanwhile, low-latency and spectral-efficient wireless data aggregation can be achieved via AirComp by allowing multiple devices to access the wireless channels non-orthogonally. In this paper, we aim to present the recent advancement of AirComp in terms of foundations, technologies, and applications. The mathematical form and communication design are introduced as the foundations of AirComp, and the critical issues of AirComp over different network architectures are then discussed along with the review of existing literature. The technologies employed for the analysis and optimization on AirComp are reviewed from the information theory and signal processing perspectives. Moreover, we present the existing studies that tackle the practical implementation issues in AirComp systems, and elaborate the applications of AirComp in Internet of Things and edge intelligent networks. Finally, potential research directions are highlighted to motivate the future development of AirComp.
RL-MD: A Novel Reinforcement Learning Approach for DNA Motif Discovery
Sep 30, 2022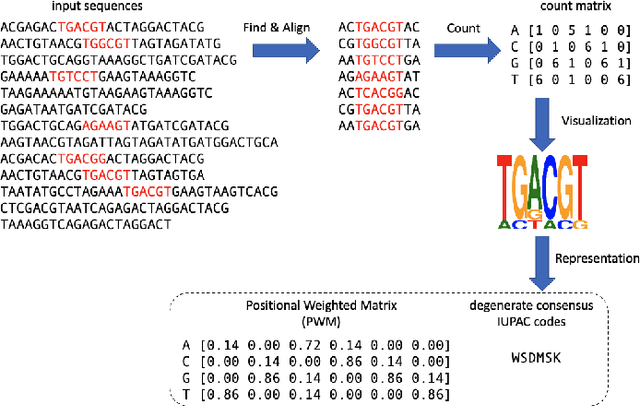
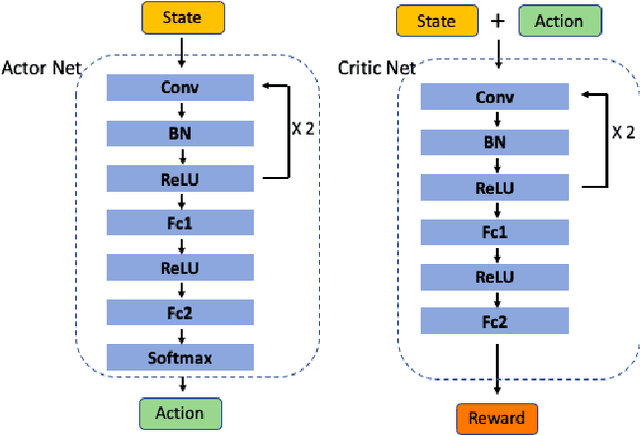

The extraction of sequence patterns from a collection of functionally linked unlabeled DNA sequences is known as DNA motif discovery, and it is a key task in computational biology. Several deep learning-based techniques have recently been introduced to address this issue. However, these algorithms can not be used in real-world situations because of the need for labeled data. Here, we presented RL-MD, a novel reinforcement learning based approach for DNA motif discovery task. RL-MD takes unlabelled data as input, employs a relative information-based method to evaluate each proposed motif, and utilizes these continuous evaluation results as the reward. The experiments show that RL-MD can identify high-quality motifs in real-world data.
Simple Pooling Front-ends For Efficient Audio Classification
Oct 07, 2022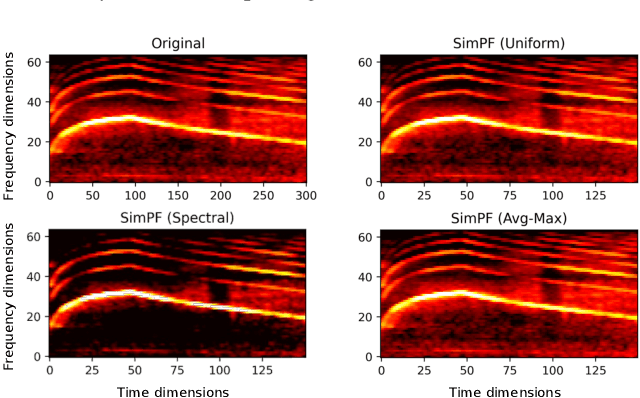
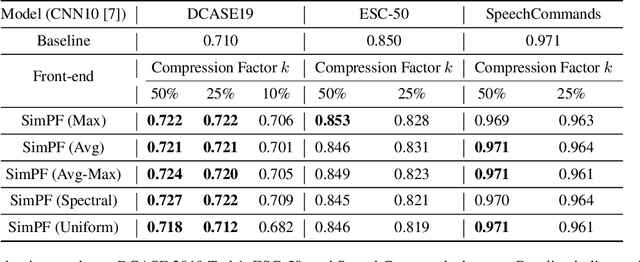

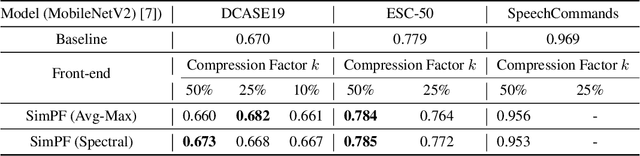
Recently, there has been increasing interest in building efficient audio neural networks for on-device scenarios. While most existing approaches are designed to reduce the size of audio neural networks using methods such as model pruning. In this work, we show that instead of reducing model size using complex methods, eliminating the temporal redundancy in the input audio features (e.g., Mel-spectrogram) could be an effective approach for efficient audio classification. To do so, we proposed a family of simple pooling front-ends (SimPFs) which use simple non-parametric pooling operations to reduce the redundant information within the Mel-spectrogram. We perform extensive experiments on four audio classification tasks to evaluate the performance of SimPFs. Experimental results show that SimPFs can achieve a reduction in more than half of the FLOPs for off-the-shelf audio neural networks, with negligible degradation or even decent improvement in audio classification performance.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021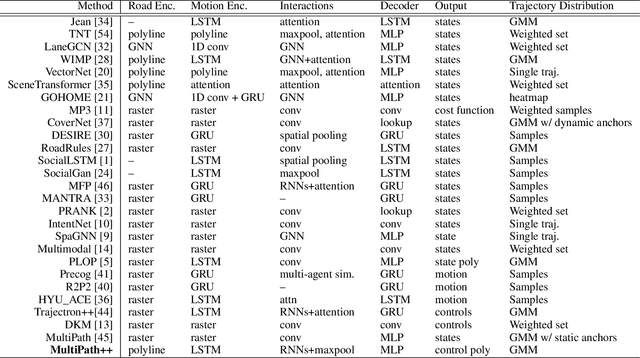
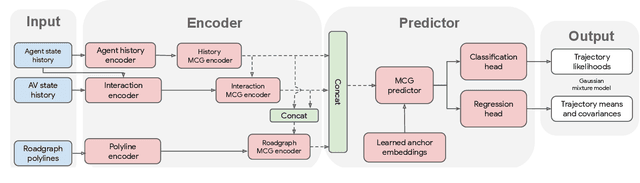
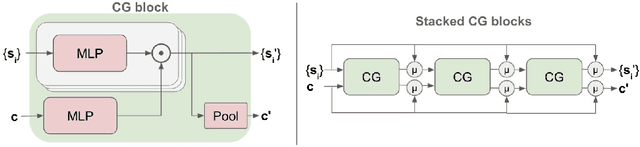
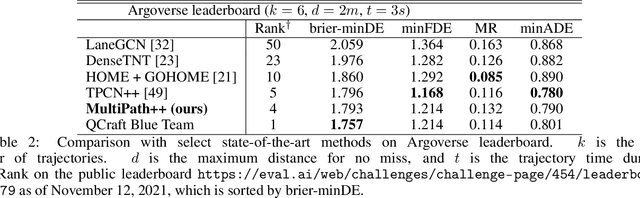
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
A New Radar Signal Multiparameter-Based Deinterleaving Method
Aug 21, 2022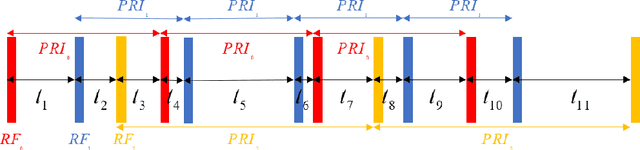
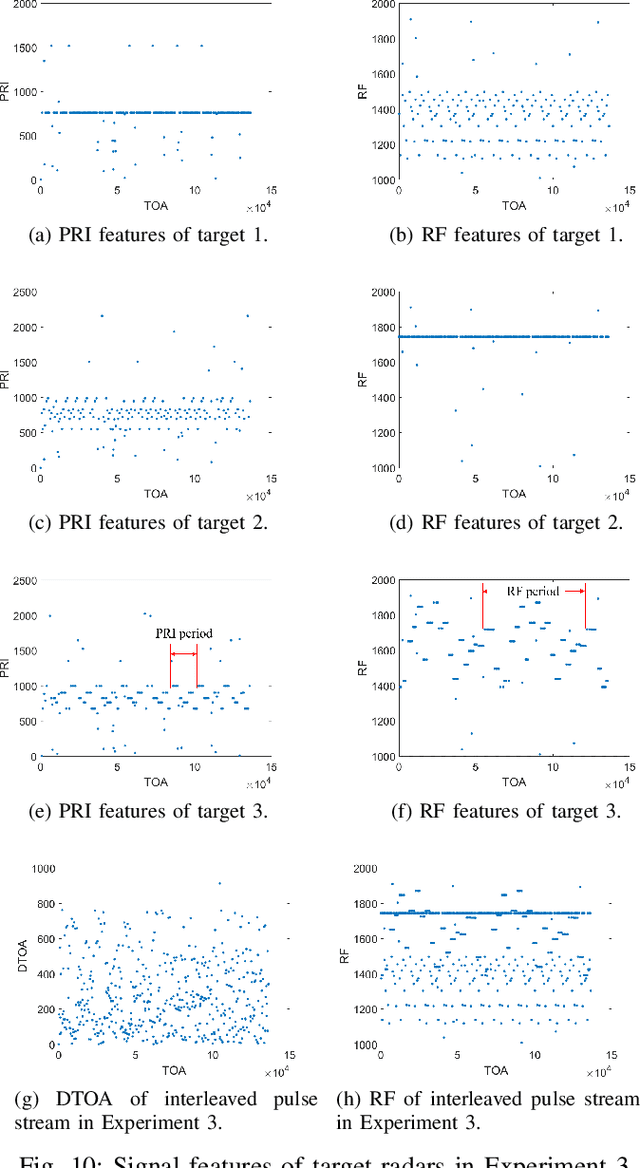
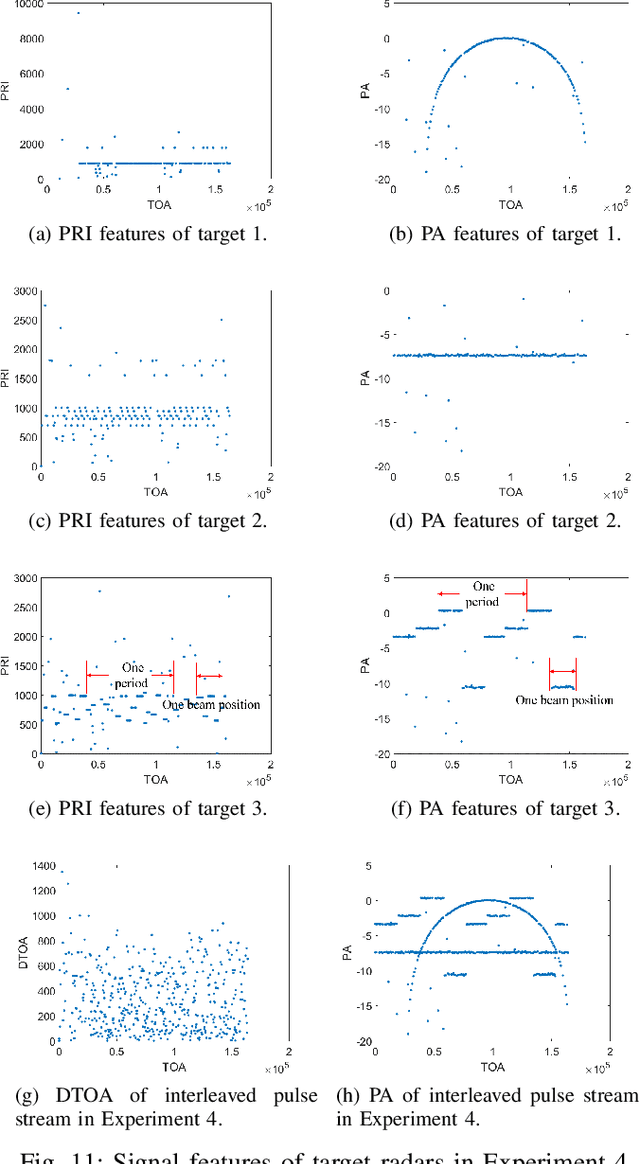
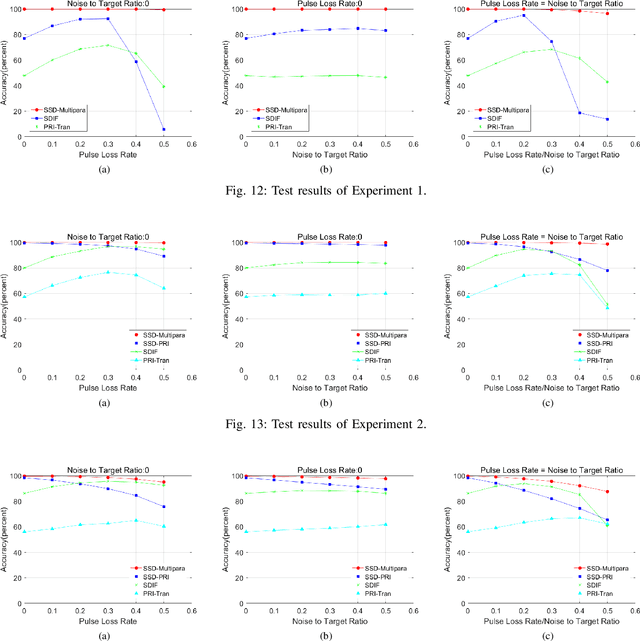
Radar signal deinterleaving has been extensively and thoroughly investigated in the electronic reconnaissance field. In this work, a new radar signal multiparameter-based deinterleaving method is proposed. In this method, semantic information composed of the pulse repetition interval (PRI), pulse width (PW), radio frequency (RF), and pulse amplitude (PA) of a radar signal is used to deinterleave radar signals. A bidirectional gated recurrent unit (BGRU) is employed, and the difference of time of arrival (DTOA)/RF, DTOA/PW, and DTOA/PA of the pulse stream are input into the BGRU. Based on the semantic information contained in different radar signal types, each pulse in the obtained pulse stream is classified according to the semantic information category, and the radar signals are deinterleaved. Compared to the PRI-based deinterleaving methods, the proposed method utilizes the multidimensional information of radar signals. As a result, higher deinterleaving accuracy is achieved. Compared to other existing radar signal multiparameter-based deinterleaving methods, the proposed method can adapt to radar signals with complex parameter features as well as to complex signal environments, and can complete the use of multiparameter in one step.
Holistic Sentence Embeddings for Better Out-of-Distribution Detection
Oct 14, 2022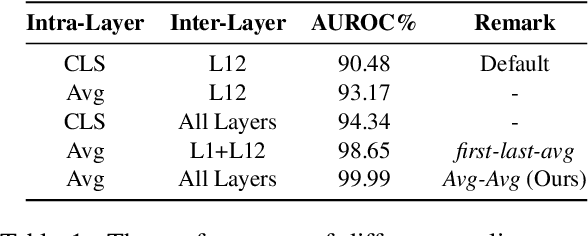
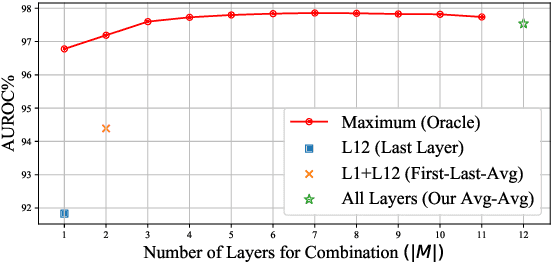
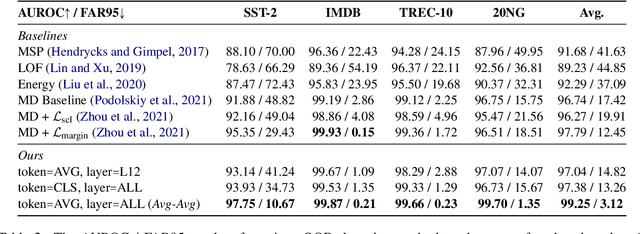
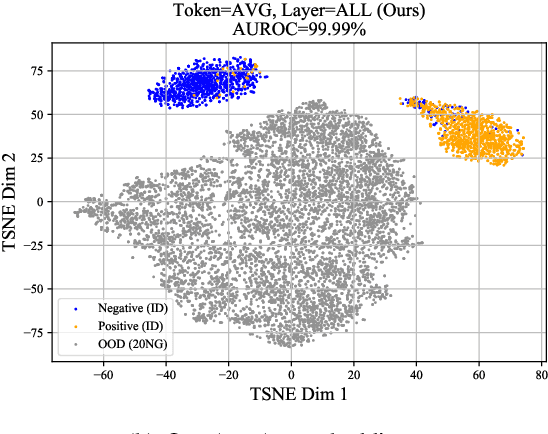
Detecting out-of-distribution (OOD) instances is significant for the safe deployment of NLP models. Among recent textual OOD detection works based on pretrained language models (PLMs), distance-based methods have shown superior performance. However, they estimate sample distance scores in the last-layer CLS embedding space and thus do not make full use of linguistic information underlying in PLMs. To address the issue, we propose to boost OOD detection by deriving more holistic sentence embeddings. On the basis of the observations that token averaging and layer combination contribute to improving OOD detection, we propose a simple embedding approach named Avg-Avg, which averages all token representations from each intermediate layer as the sentence embedding and significantly surpasses the state-of-the-art on a comprehensive suite of benchmarks by a 9.33% FAR95 margin. Furthermore, our analysis demonstrates that it indeed helps preserve general linguistic knowledge in fine-tuned PLMs and substantially benefits detecting background shifts. The simple yet effective embedding method can be applied to fine-tuned PLMs with negligible extra costs, providing a free gain in OOD detection. Our code is available at https://github.com/lancopku/Avg-Avg.