 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HopFIR: Hop-wise GraphFormer with Intragroup Joint Refinement for 3D Human Pose Estimation
Feb 28, 2023
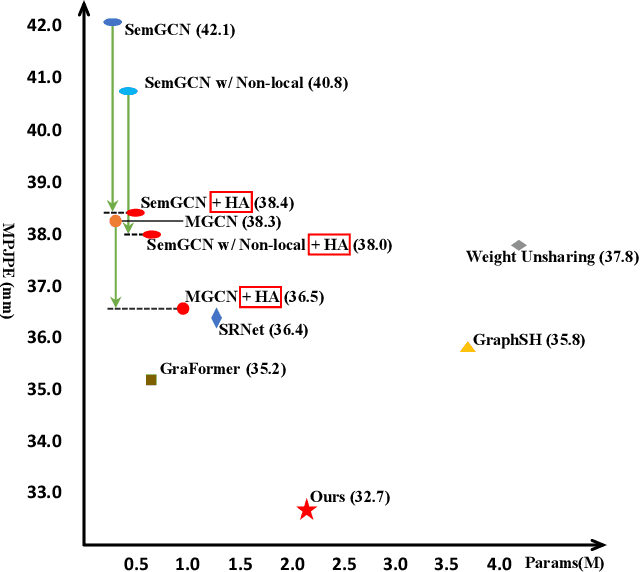
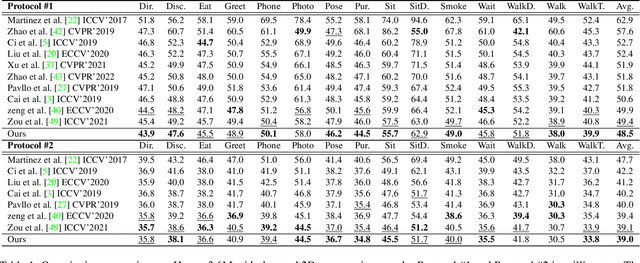
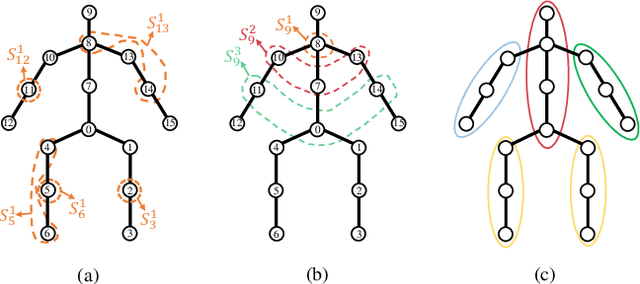
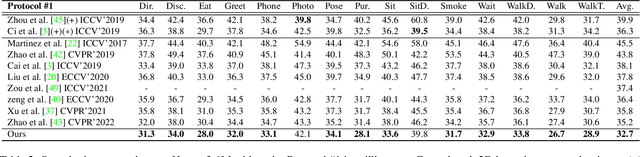
2D-to-3D human pose lifting is fundamental for 3D human pose estimation (HPE). Graph Convolutional Network (GCN) has been proven inherently suitable to model the human skeletal topology. However, current GCN-based 3D HPE methods update the node features by aggregating their neighbors' information without considering the interaction of joints in different motion patterns. Although some studies import limb information to learn the movement patterns, the latent synergies among joints, such as maintaining balance in the motion are seldom investigated. We propose a hop-wise GraphFormer with intragroup joint refinement (HopFIR) to tackle the 3D HPE problem. The HopFIR mainly consists of a novel Hop-wise GraphFormer(HGF) module and an Intragroup Joint Refinement(IJR) module which leverages the prior limb information for peripheral joints refinement. The HGF module groups the joints by $k$-hop neighbors and utilizes a hop-wise transformer-like attention mechanism among these groups to discover latent joint synergy. Extensive experimental results show that HopFIR outperforms the SOTA methods with a large margin (on the Human3.6M dataset, the mean per joint position error (MPJPE) is 32.67mm). Furthermore, it is also demonstrated that previous SOTA GCN-based methods can benefit from the proposed hop-wise attention mechanism efficiently with significant performance promotion, such as SemGCN and MGCN are improved by 8.9% and 4.5%, respectively.
Efficient solutions to the relative pose of three calibrated cameras from four points using virtual correspondences
Mar 28, 2023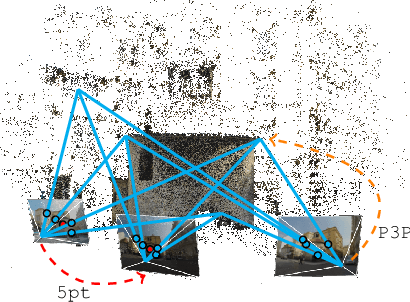
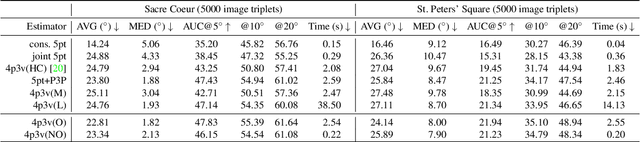
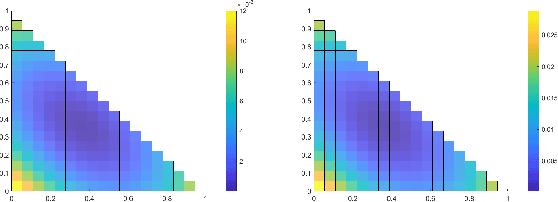

We study the challenging problem of estimating the relative pose of three calibrated cameras. We propose two novel solutions to the notoriously difficult configuration of four points in three views, known as the 4p3v problem. Our solutions are based on the simple idea of generating one additional virtual point correspondence in two views by using the information from the locations of the four input correspondences in the three views. For the first solver, we train a network to predict this point correspondence. The second solver uses a much simpler and more efficient strategy based on the mean points of three corresponding input points. The new solvers are efficient and easy to implement since they are based on the existing efficient minimal solvers, i.e., the well-known 5-point relative pose and the P3P solvers. The solvers achieve state-of-the-art results on real data. The idea of solving minimal problems using virtual correspondences is general and can be applied to other problems, e.g., the 5-point relative pose problem. In this way, minimal problems can be solved using simpler non-minimal solvers or even using sub-minimal samples inside RANSAC. In addition, we compare different variants of 4p3v solvers with the baseline solver for the minimal configuration consisting of three triplets of points and two points visible in two views. We discuss which configuration of points is potentially the most practical in real applications.
Unsupervised Traffic Scene Generation with Synthetic 3D Scene Graphs
Mar 15, 2023
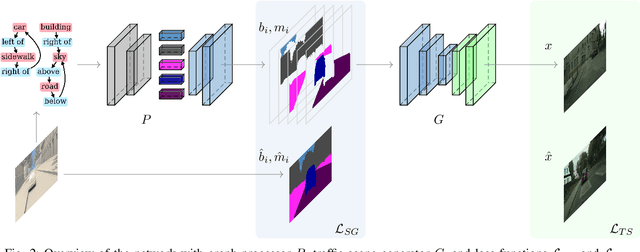
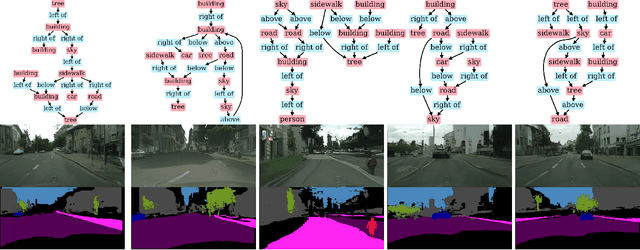
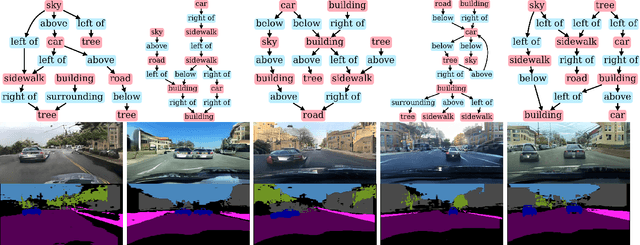
Image synthesis driven by computer graphics achieved recently a remarkable realism, yet synthetic image data generated this way reveals a significant domain gap with respect to real-world data. This is especially true in autonomous driving scenarios, which represent a critical aspect for overcoming utilizing synthetic data for training neural networks. We propose a method based on domain-invariant scene representation to directly synthesize traffic scene imagery without rendering. Specifically, we rely on synthetic scene graphs as our internal representation and introduce an unsupervised neural network architecture for realistic traffic scene synthesis. We enhance synthetic scene graphs with spatial information about the scene and demonstrate the effectiveness of our approach through scene manipulation.
KG-ECO: Knowledge Graph Enhanced Entity Correction for Query Rewriting
Feb 22, 2023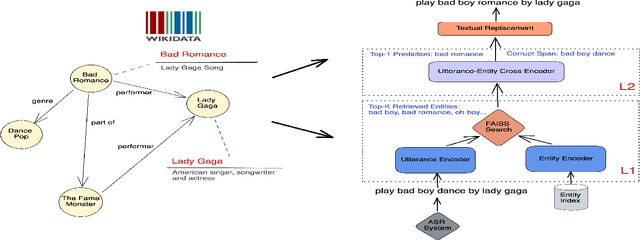

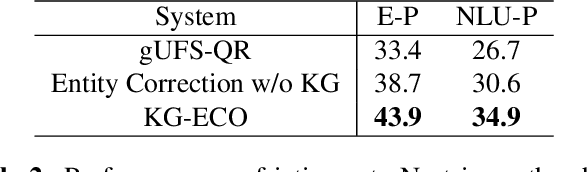
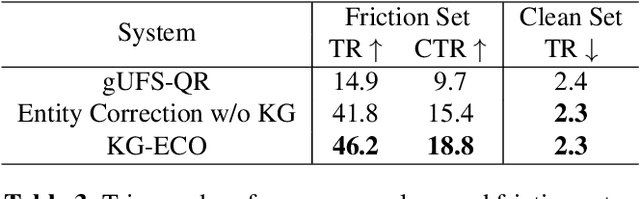
Query Rewriting (QR) plays a critical role in large-scale dialogue systems for reducing frictions. When there is an entity error, it imposes extra challenges for a dialogue system to produce satisfactory responses. In this work, we propose KG-ECO: Knowledge Graph enhanced Entity COrrection for query rewriting, an entity correction system with corrupt entity span detection and entity retrieval/re-ranking functionalities. To boost the model performance, we incorporate Knowledge Graph (KG) to provide entity structural information (neighboring entities encoded by graph neural networks) and textual information (KG entity descriptions encoded by RoBERTa). Experimental results show that our approach yields a clear performance gain over two baselines: utterance level QR and entity correction without utilizing KG information. The proposed system is particularly effective for few-shot learning cases where target entities are rarely seen in training or there is a KG relation between the target entity and other contextual entities in the query.
WDiscOOD: Out-of-Distribution Detection via Whitened Linear Discriminant Analysis
Mar 22, 2023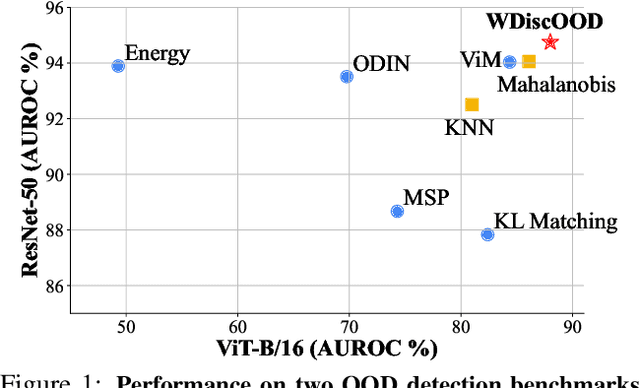
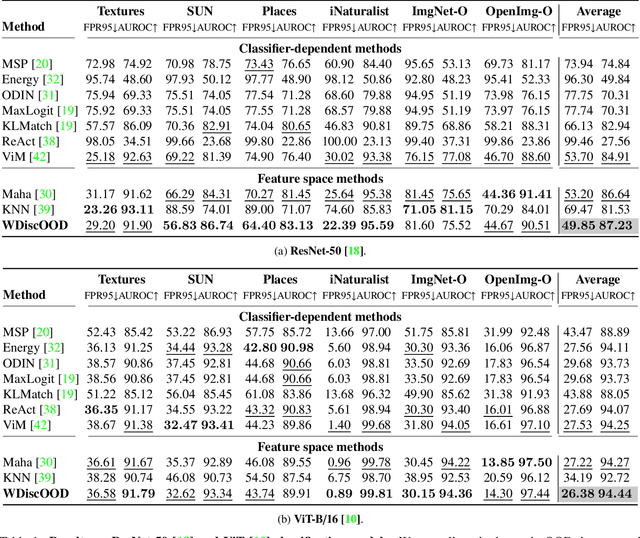
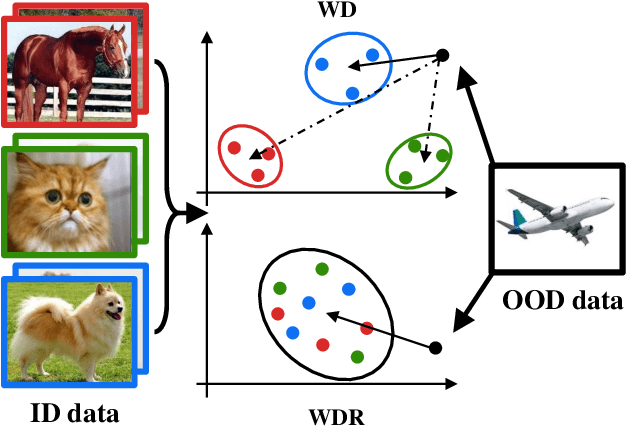

Deep neural networks are susceptible to generating overconfident yet erroneous predictions when presented with data beyond known concepts. This challenge underscores the importance of detecting out-of-distribution (OOD) samples in the open world. In this work, we propose a novel feature-space OOD detection score that jointly reasons with both class-specific and class-agnostic information. Specifically, our approach utilizes Whitened Linear Discriminant Analysis to project features into two subspaces - the discriminative and residual subspaces - in which the ID classes are maximally separated and closely clustered, respectively. The OOD score is then determined by combining the deviation from the input data to the ID distribution in both subspaces. The efficacy of our method, named WDiscOOD, is verified on the large-scale ImageNet-1k benchmark, with six OOD datasets that covers a variety of distribution shifts. WDiscOOD demonstrates superior performance on deep classifiers with diverse backbone architectures, including CNN and vision transformer. Furthermore, we also show that our method can more effectively detect novel concepts in representation space trained with contrastive objectives, including supervised contrastive loss and multi-modality contrastive loss.
NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
Mar 22, 2023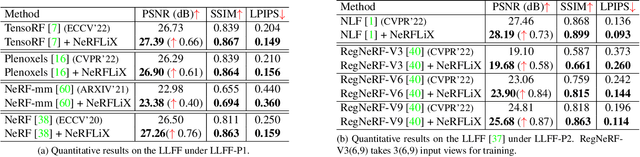
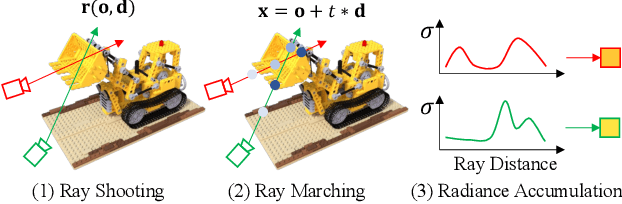
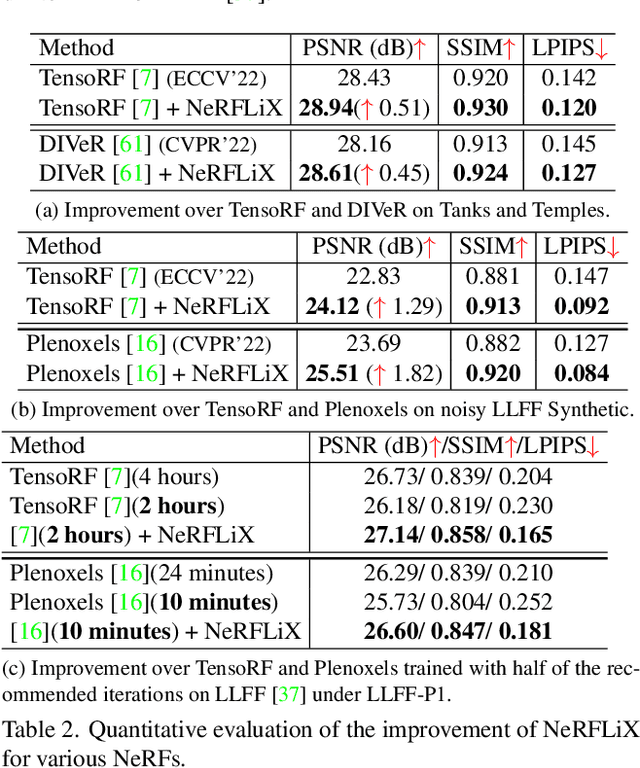
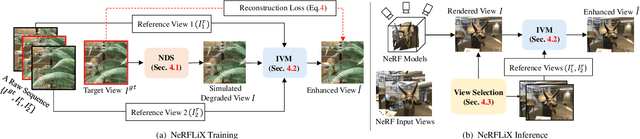
Neural radiance fields (NeRF) show great success in novel view synthesis. However, in real-world scenes, recovering high-quality details from the source images is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise, blur, etc. Towards to improve the synthesis quality of NeRF-based approaches, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm by learning a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for existing deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that is able to fuse highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views.
360BEV: Panoramic Semantic Mapping for Indoor Bird's-Eye View
Mar 22, 2023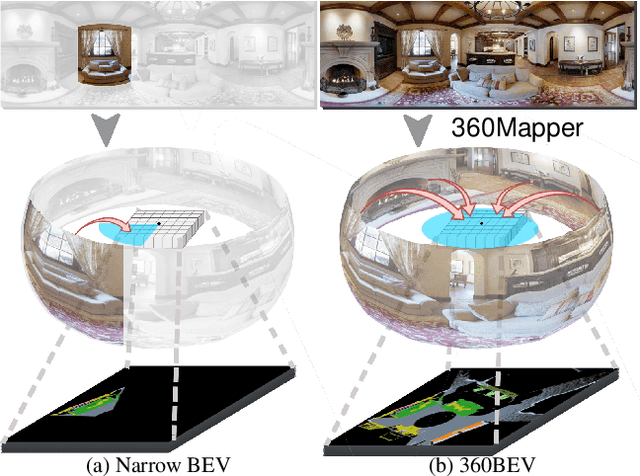
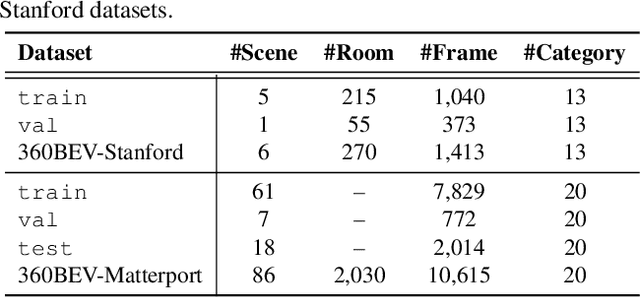
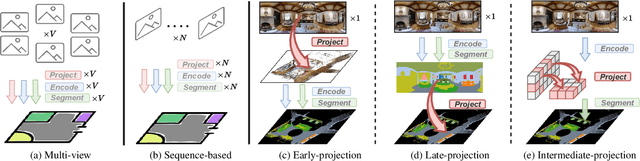
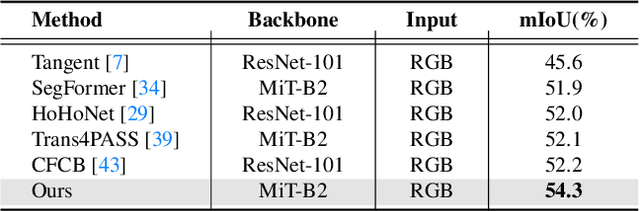
Seeing only a tiny part of the whole is not knowing the full circumstance. Bird's-eye-view (BEV) perception, a process of obtaining allocentric maps from egocentric views, is restricted when using a narrow Field of View (FoV) alone. In this work, mapping from 360{\deg} panoramas to BEV semantics, the 360BEV task, is established for the first time to achieve holistic representations of indoor scenes in a top-down view. Instead of relying on narrow-FoV image sequences, a panoramic image with depth information is sufficient to generate a holistic BEV semantic map. To benchmark 360BEV, we present two indoor datasets, 360BEV-Matterport and 360BEV-Stanford, both of which include egocentric panoramic images and semantic segmentation labels, as well as allocentric semantic maps. Besides delving deep into different mapping paradigms, we propose a dedicated solution for panoramic semantic mapping, namely 360Mapper. Through extensive experiments, our methods achieve 44.32% and 45.78% in mIoU on both datasets respectively, surpassing previous counterparts with gains of +7.60% and +9.70% in mIoU. Code and datasets will be available at: https://jamycheung.github.io/360BEV.html.
ProtoCon: Pseudo-label Refinement via Online Clustering and Prototypical Consistency for Efficient Semi-supervised Learning
Mar 22, 2023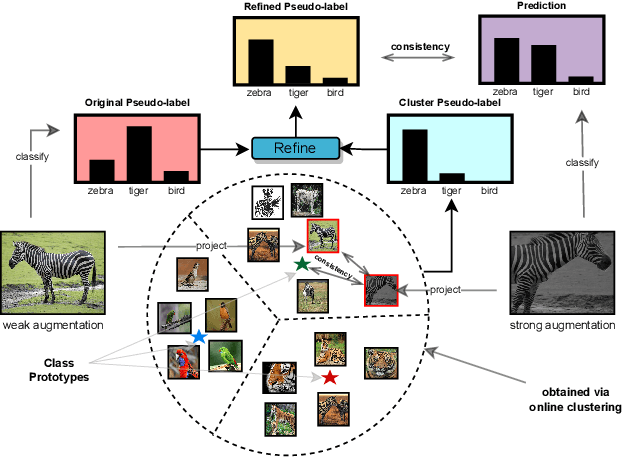
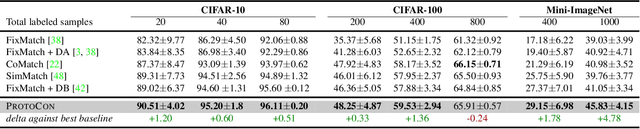
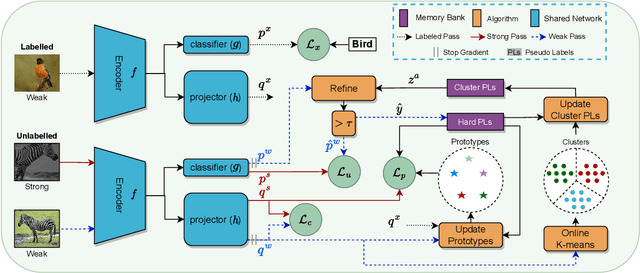
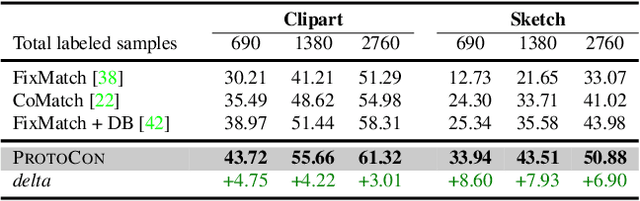
Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually underperform. ProtoCon refines the pseudo-labels by leveraging their nearest neighbours' information. The neighbours are identified as the training proceeds using an online clustering approach operating in an embedding space trained via a prototypical loss to encourage well-formed clusters. The online nature of ProtoCon allows it to utilise the label history of the entire dataset in one training cycle to refine labels in the following cycle without the need to store image embeddings. Hence, it can seamlessly scale to larger datasets at a low cost. Finally, ProtoCon addresses the poor training signal in the initial phase of training (due to fewer confident predictions) by introducing an auxiliary self-supervised loss. It delivers significant gains and faster convergence over state-of-the-art across 5 datasets, including CIFARs, ImageNet and DomainNet.
End-to-End Personalized Next Location Recommendation via Contrastive User Preference Modeling
Mar 22, 2023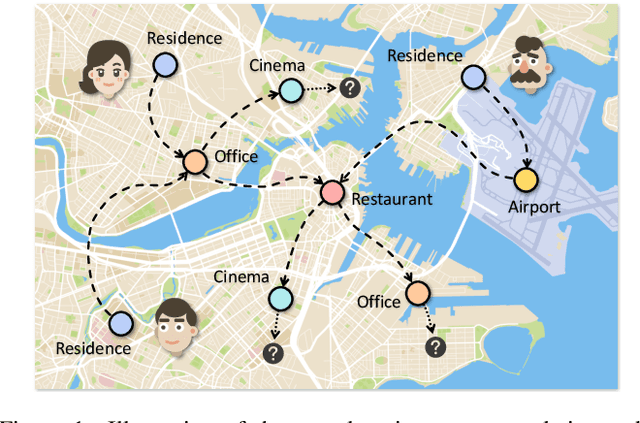
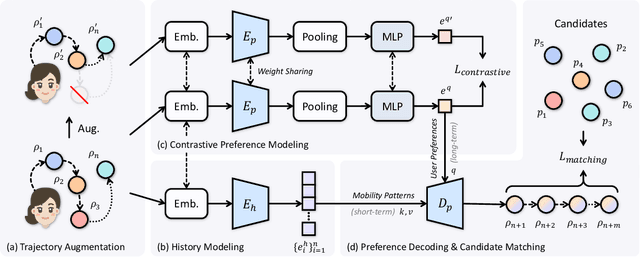
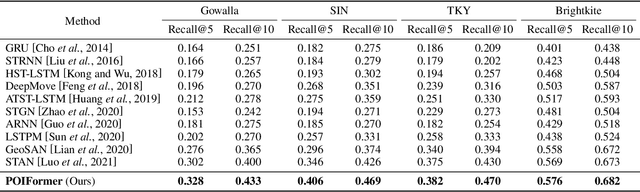
Predicting the next location is a highly valuable and common need in many location-based services such as destination prediction and route planning. The goal of next location recommendation is to predict the next point-of-interest a user might go to based on the user's historical trajectory. Most existing models learn mobility patterns merely from users' historical check-in sequences while overlooking the significance of user preference modeling. In this work, a novel Point-of-Interest Transformer (POIFormer) with contrastive user preference modeling is developed for end-to-end next location recommendation. This model consists of three major modules: history encoder, query generator, and preference decoder. History encoder is designed to model mobility patterns from historical check-in sequences, while query generator explicitly learns user preferences to generate user-specific intention queries. Finally, preference decoder combines the intention queries and historical information to predict the user's next location. Extensive comparisons with representative schemes and ablation studies on four real-world datasets demonstrate the effectiveness and superiority of the proposed scheme under various settings.
On the Bit Error Performance of OTFS Modulation using Discrete Zak Transform
Mar 22, 2023
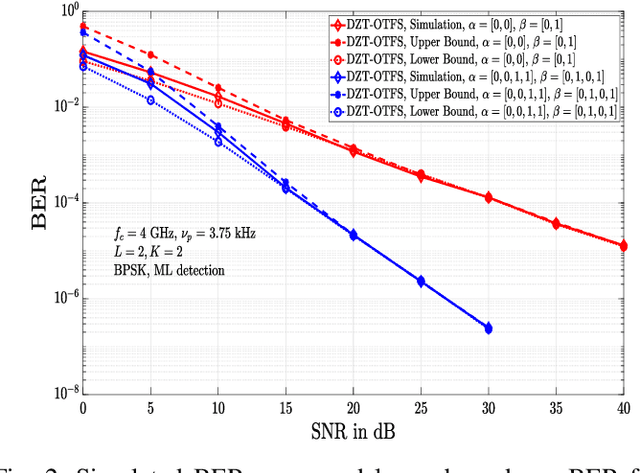
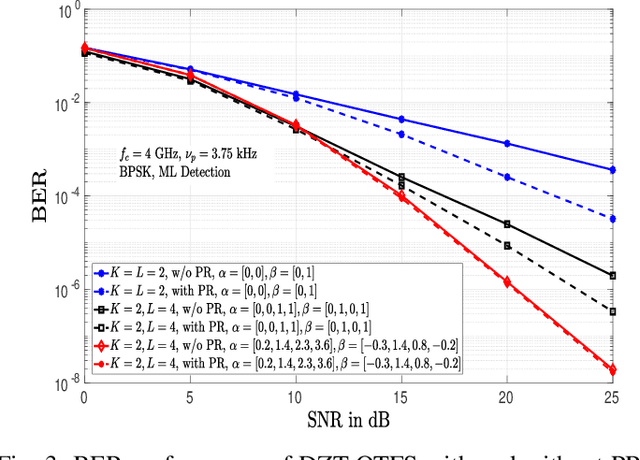
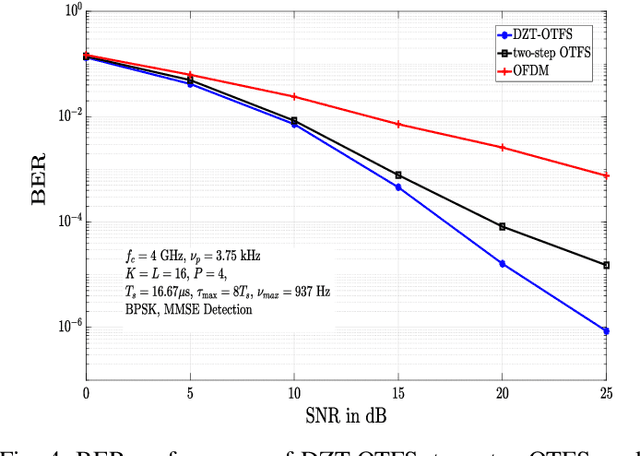
In orthogonal time frequency space (OTFS) modulation, Zak transform approach is a natural approach for converting information symbols multiplexed in the DD domain directly to time domain for transmission, and vice versa at the receiver. Past research on OTFS has primarily considered a two-step approach where DD domain symbols are first converted to time-frequency domain which are then converted to time domain for transmission, and vice versa at the receiver. The Zak transform approach can offer performance and complexity benefits compared to the two-step approach. This paper presents an early investigation on the bit error performance of OTFS realized using discrete Zak transform (DZT). We develop a compact DD domain input-output relation for DZT-OTFS using matrix decomposition that is valid for both integer and fractional delay-Dopplers. We analyze the bit error performance of DZT-OTFS using pairwise error probability analysis and simulations. Simulation results show that 1) both DZT-OTFS and two-step OTFS perform better than OFDM, and 2) DZT-OTFS achieves better performance compared to two-step OTFS over a wide range of Doppler spreads.