 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Latent Dynamical Causal Processes for Single-Cell Perturbation Prediction
May 25, 2026Single-cell perturbation prediction aims to infer how cells respond to unseen interventions and to achieve out-of-distribution (OOD) generalization, providing a computational route to understanding how perturbations reshape cellular programs over time. Existing machine learning methods have made important progress, but typically capture only one side of the response. Latent causal approaches seek mechanisms that support generalization and interpretation, yet often treat perturbation effects as static outcomes. Temporal models describe how gene expression changes across time, but usually do not explicitly recover the latent causal generative mechanisms driving these changes. In practice, perturbation effects are both latent and dynamical: interventions act through unobserved cellular programs, whose states evolve over time and give rise to observed expression profiles. Motivated by this view, we propose a latent dynamical causal generative model for single-cell perturbation data that jointly captures latent cellular programs, perturbation-conditioned mechanisms, and temporal evolution. We further provide an identifiability analysis showing that, under suitable conditions, the latent causal variables are recoverable up to standard equivalence classes. Guided by this analysis, we develop CITE-VAE, a learning framework for recovering latent cellular programs and their perturbation-driven dynamics from single-cell sequencing data. Experiments on Causal-3DIdent validate the theoretical results and the effectiveness of the proposed method in controlled settings. Additional experiments on real-world CRISPR-based single-cell perturbation data show improved generalization to unseen perturbations compared with state-of-the-art baselines, highlighting the practical robustness of our approach.
What Makes a Representation Good for Single-Cell Perturbation Prediction?
May 19, 2026Single-cell perturbation modeling is fundamental for understanding and predicting cellular responses to genetic perturbations. However, existing approaches, from causal representation learning to foundation models, often struggle with an overlooked challenge: gene expression is dominated by perturbation-invariant information, while perturbation-specific signals are intrinsically sparse. As a result, learned representations either entangle invariant and perturbation-specific information, leading to spurious and non-generalizable predictors, or suppress perturbation-specific signals altogether, rendering them ineffective for prediction. To address this, we propose PerturbedVAE, a general framework designed to resolve this signal imbalance. The framework explicitly separates perturbation-specific information from dominant invariant structure and recovers causal representations to effectively utilize such information for prediction. We further provide an identifiability analysis that characterizes the conditions under which sparse perturbation effects can be reliably recovered, thereby clarifying how the framework can be concretely specified under such conditions. Empirically, PerturbedVAE achieves state-of-the-art performance on a widely used benchmark across multiple evaluation settings, yielding significant gains on out-of-distribution combinatorial predictions and uncovering interpretable perturbation-response programs.
Dual Strategies for Test-Time Adaptation
Apr 19, 2026Conventional test-time adaptation (TTA) approaches typically adapt the model using only a small fraction of test samples, often those with low-entropy predictions, thereby failing to fully leverage the available information in the test distribution. This paper introduces DualTTA, a novel framework that improves performance under distribution shifts by utilizing a larger and more diverse set of test samples. DualTTA identifies two distinct groups: one where the model's predictions are likely consistent with the underlying semantics, and another where predictions are likely incorrect. For the first group, it minimizes prediction entropy to reinforce reliable decisions; for the second, it maximizes entropy to suppress overconfident errors and unlearn spurious behavior. These groups are adaptively selected using a new reliability criterion that measures prediction stability under both semantic-preserving and semantic-altering transformations, addressing the limitations of purely entropy-based selection. We further provide theoretical analysis and empirical justification showing that our approach enables a tighter separation between reliable and unreliable samples, in the context of their suitability for adaptation, leading to provably more effective model updates.
Truth as a Trajectory: What Internal Representations Reveal About Large Language Model Reasoning
Mar 01, 2026Existing explainability methods for Large Language Models (LLMs) typically treat hidden states as static points in activation space, assuming that correct and incorrect inferences can be separated using representations from an individual layer. However, these activations are saturated with polysemantic features, leading to linear probes learning surface-level lexical patterns rather than underlying reasoning structures. We introduce Truth as a Trajectory (TaT), which models the transformer inference as an unfolded trajectory of iterative refinements, shifting analysis from static activations to layer-wise geometric displacement. By analyzing displacement of representations across layers, TaT uncovers geometric invariants that distinguish valid reasoning from spurious behavior. We evaluate TaT across dense and Mixture-of-Experts (MoE) architectures on benchmarks spanning commonsense reasoning, question answering, and toxicity detection. Without access to the activations themselves and using only changes in activations across layers, we show that TaT effectively mitigates reliance on static lexical confounds, outperforming conventional probing, and establishes trajectory analysis as a complementary perspective on LLM explainability.
The Quest for Winning Tickets in Low-Rank Adapters
Dec 27, 2025The Lottery Ticket Hypothesis (LTH) suggests that over-parameterized neural networks contain sparse subnetworks ("winning tickets") capable of matching full model performance when trained from scratch. With the growing reliance on fine-tuning large pretrained models, we investigate whether LTH extends to parameter-efficient fine-tuning (PEFT), specifically focusing on Low-Rank Adaptation (LoRA) methods. Our key finding is that LTH holds within LoRAs, revealing sparse subnetworks that can match the performance of dense adapters. In particular, we find that the effectiveness of sparse subnetworks depends more on how much sparsity is applied in each layer than on the exact weights included in the subnetwork. Building on this insight, we propose Partial-LoRA, a method that systematically identifies said subnetworks and trains sparse low-rank adapters aligned with task-relevant subspaces of the pre-trained model. Experiments across 8 vision and 12 language tasks in both single-task and multi-task settings show that Partial-LoRA reduces the number of trainable parameters by up to 87\%, while maintaining or improving accuracy. Our results not only deepen our theoretical understanding of transfer learning and the interplay between pretraining and fine-tuning but also open new avenues for developing more efficient adaptation strategies.
Decomposing Task Vectors for Refined Model Editing
Dec 27, 2025Large pre-trained models have transformed machine learning, yet adapting these models effectively to exhibit precise, concept-specific behaviors remains a significant challenge. Task vectors, defined as the difference between fine-tuned and pre-trained model parameters, provide a mechanism for steering neural networks toward desired behaviors. This has given rise to large repositories dedicated to task vectors tailored for specific behaviors. The arithmetic operation of these task vectors allows for the seamless combination of desired behaviors without the need for large datasets. However, these vectors often contain overlapping concepts that can interfere with each other during arithmetic operations, leading to unpredictable outcomes. We propose a principled decomposition method that separates each task vector into two components: one capturing shared knowledge across multiple task vectors, and another isolating information unique to each specific task. By identifying invariant subspaces across projections, our approach enables more precise control over concept manipulation without unintended amplification or diminution of other behaviors. We demonstrate the effectiveness of our decomposition method across three domains: improving multi-task merging in image classification by 5% using shared components as additional task vectors, enabling clean style mixing in diffusion models without generation degradation by mixing only the unique components, and achieving 47% toxicity reduction in language models while preserving performance on general knowledge tasks by negating the toxic information isolated to the unique component. Our approach provides a new framework for understanding and controlling task vector arithmetic, addressing fundamental limitations in model editing operations.
Certified but Fooled! Breaking Certified Defences with Ghost Certificates
Nov 18, 2025Certified defenses promise provable robustness guarantees. We study the malicious exploitation of probabilistic certification frameworks to better understand the limits of guarantee provisions. Now, the objective is to not only mislead a classifier, but also manipulate the certification process to generate a robustness guarantee for an adversarial input certificate spoofing. A recent study in ICLR demonstrated that crafting large perturbations can shift inputs far into regions capable of generating a certificate for an incorrect class. Our study investigates if perturbations needed to cause a misclassification and yet coax a certified model into issuing a deceptive, large robustness radius for a target class can still be made small and imperceptible. We explore the idea of region-focused adversarial examples to craft imperceptible perturbations, spoof certificates and achieve certification radii larger than the source class ghost certificates. Extensive evaluations with the ImageNet demonstrate the ability to effectively bypass state-of-the-art certified defenses such as Densepure. Our work underscores the need to better understand the limits of robustness certification methods.
CEDL: Centre-Enhanced Discriminative Learning for Anomaly Detection
Nov 15, 2025



Supervised anomaly detection methods perform well in identifying known anomalies that are well represented in the training set. However, they often struggle to generalise beyond the training distribution due to decision boundaries that lack a clear definition of normality. Existing approaches typically address this by regularising the representation space during training, leading to separate optimisation in latent and label spaces. The learned normality is therefore not directly utilised at inference, and their anomaly scores often fall within arbitrary ranges that require explicit mapping or calibration for probabilistic interpretation. To achieve unified learning of geometric normality and label discrimination, we propose Centre-Enhanced Discriminative Learning (CEDL), a novel supervised anomaly detection framework that embeds geometric normality directly into the discriminative objective. CEDL reparameterises the conventional sigmoid-derived prediction logit through a centre-based radial distance function, unifying geometric and discriminative learning in a single end-to-end formulation. This design enables interpretable, geometry-aware anomaly scoring without post-hoc thresholding or reference calibration. Extensive experiments on tabular, time-series, and image data demonstrate that CEDL achieves competitive and balanced performance across diverse real-world anomaly detection tasks, validating its effectiveness and broad applicability.
Towards Higher Effective Rank in Parameter-efficient Fine-tuning using Khatri--Rao Product
Aug 01, 2025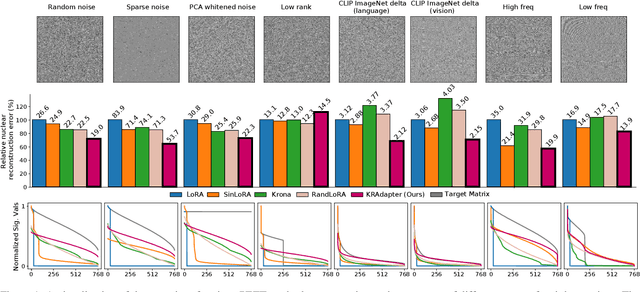
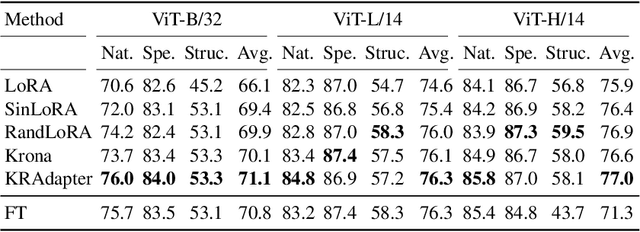
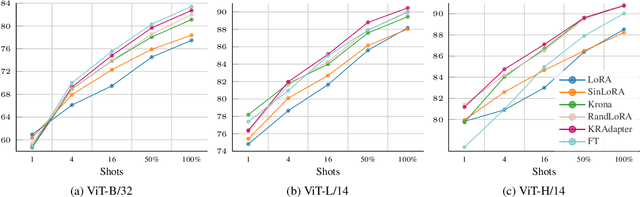
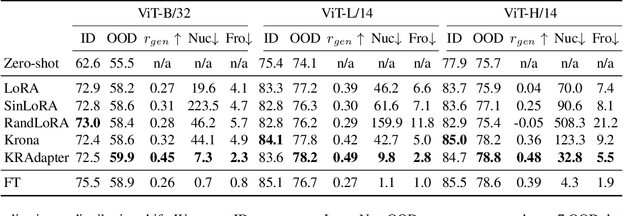
Parameter-efficient fine-tuning (PEFT) has become a standard approach for adapting large pre-trained models. Amongst PEFT methods, low-rank adaptation (LoRA) has achieved notable success. However, recent studies have highlighted its limitations compared against full-rank alternatives, particularly when applied to multimodal and large language models. In this work, we present a quantitative comparison amongst full-rank and low-rank PEFT methods using a synthetic matrix approximation benchmark with controlled spectral properties. Our results confirm that LoRA struggles to approximate matrices with relatively flat spectrums or high frequency components -- signs of high effective ranks. To this end, we introduce KRAdapter, a novel PEFT algorithm that leverages the Khatri-Rao product to produce weight updates, which, by construction, tends to produce matrix product with a high effective rank. We demonstrate performance gains with KRAdapter on vision-language models up to 1B parameters and on large language models up to 8B parameters, particularly on unseen common-sense reasoning tasks. In addition, KRAdapter maintains the memory and compute efficiency of LoRA, making it a practical and robust alternative to fine-tune billion-scale parameter models.
Learning to Reason and Navigate: Parameter Efficient Action Planning with Large Language Models
May 12, 2025The remote embodied referring expression (REVERIE) task requires an agent to navigate through complex indoor environments and localize a remote object specified by high-level instructions, such as "bring me a spoon", without pre-exploration. Hence, an efficient navigation plan is essential for the final success. This paper proposes a novel parameter-efficient action planner using large language models (PEAP-LLM) to generate a single-step instruction at each location. The proposed model consists of two modules, LLM goal planner (LGP) and LoRA action planner (LAP). Initially, LGP extracts the goal-oriented plan from REVERIE instructions, including the target object and room. Then, LAP generates a single-step instruction with the goal-oriented plan, high-level instruction, and current visual observation as input. PEAP-LLM enables the embodied agent to interact with LAP as the path planner on the fly. A simple direct application of LLMs hardly achieves good performance. Also, existing hard-prompt-based methods are error-prone in complicated scenarios and need human intervention. To address these issues and prevent the LLM from generating hallucinations and biased information, we propose a novel two-stage method for fine-tuning the LLM, consisting of supervised fine-tuning (STF) and direct preference optimization (DPO). SFT improves the quality of generated instructions, while DPO utilizes environmental feedback. Experimental results show the superiority of our proposed model on REVERIE compared to the previous state-of-the-art.