 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Beamforming and Antenna Movement Design for Moveable Antenna Systems Based on Statistical CSI
Aug 13, 2023
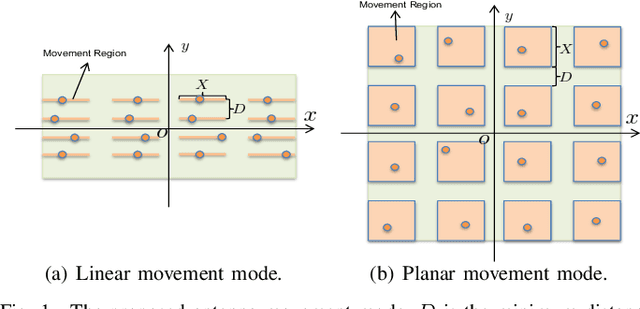
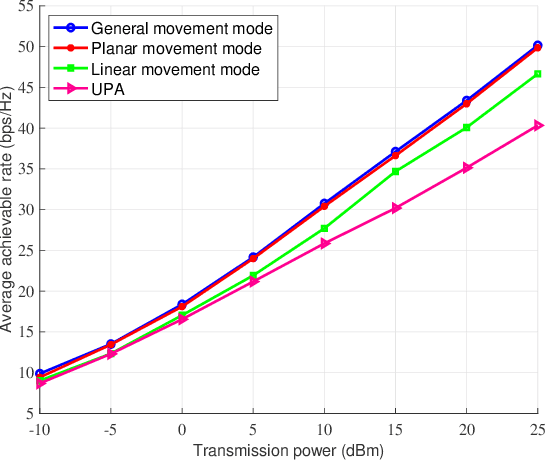
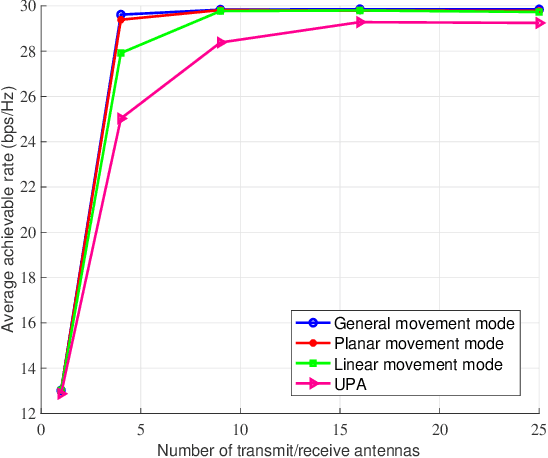
This paper studies a novel movable antenna (MA)-enhanced multiple-input multiple-output (MIMO) system to leverage the corresponding spatial degrees of freedom (DoFs) for improving the performance of wireless communications. We aim to maximize the achievable rate by jointly optimizing the MA positions and the transmit covariance matrix based on statistical channel state information (CSI). To solve the resulting design problem, we develop a constrained stochastic successive convex approximation (CSSCA) algorithm applicable for the general movement mode. Furthermore, we propose two simplified antenna movement modes, namely the linear movement mode and the planar movement mode, to facilitate efficient antenna movement and reduce the computational complexity of the CSSCA algorithm. Numerical results show that the considered MA-enhanced system can significantly improve the achievable rate compared to conventional MIMO systems employing uniform planar arrays (UPAs) and that the proposed planar movement mode performs closely to the performance upper bound achieved by the general movement mode.
EcomGPT: Instruction-tuning Large Language Model with Chain-of-Task Tasks for E-commerce
Aug 14, 2023
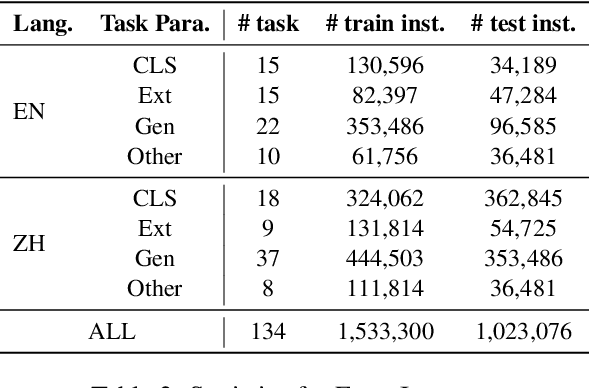
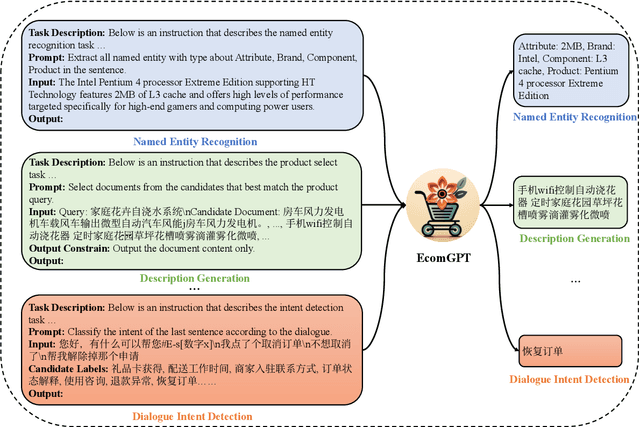
Recently, instruction-following Large Language Models (LLMs) , represented by ChatGPT, have exhibited exceptional performance in general Natural Language Processing (NLP) tasks. However, the unique characteristics of E-commerce data pose significant challenges to general LLMs. An LLM tailored specifically for E-commerce scenarios, possessing robust cross-dataset/task generalization capabilities, is a pressing necessity. To solve this issue, in this work, we proposed the first e-commerce instruction dataset EcomInstruct, with a total of 2.5 million instruction data. EcomInstruct scales up the data size and task diversity by constructing atomic tasks with E-commerce basic data types, such as product information, user reviews. Atomic tasks are defined as intermediate tasks implicitly involved in solving a final task, which we also call Chain-of-Task tasks. We developed EcomGPT with different parameter scales by training the backbone model BLOOMZ with the EcomInstruct. Benefiting from the fundamental semantic understanding capabilities acquired from the Chain-of-Task tasks, EcomGPT exhibits excellent zero-shot generalization capabilities. Extensive experiments and human evaluations demonstrate that EcomGPT outperforms ChatGPT in term of cross-dataset/task generalization on E-commerce tasks.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023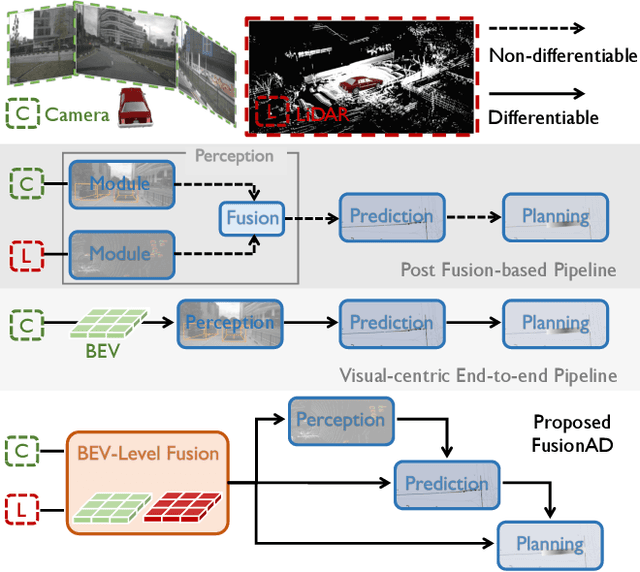
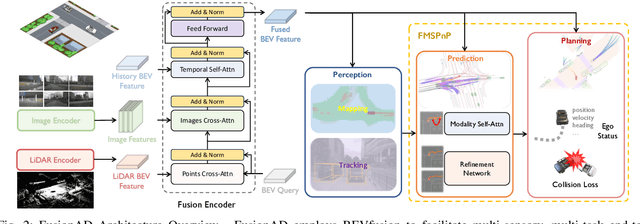
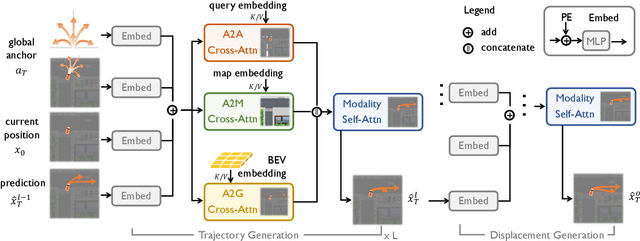
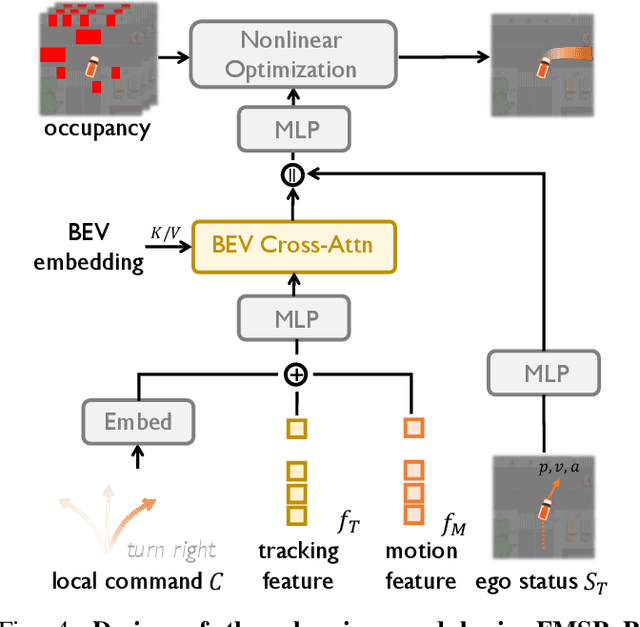
Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
Towards Deeply Unified Depth-aware Panoptic Segmentation with Bi-directional Guidance Learning
Aug 14, 2023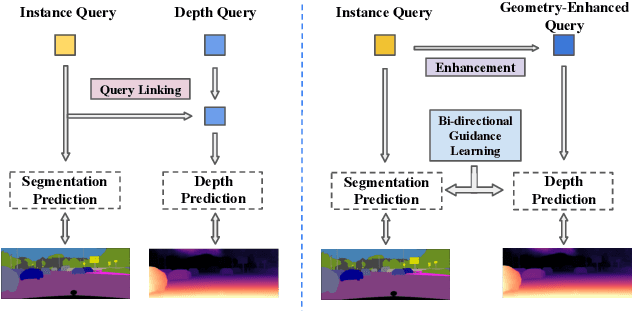
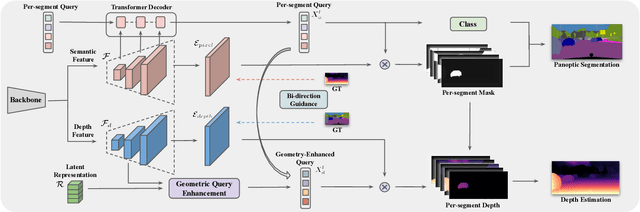
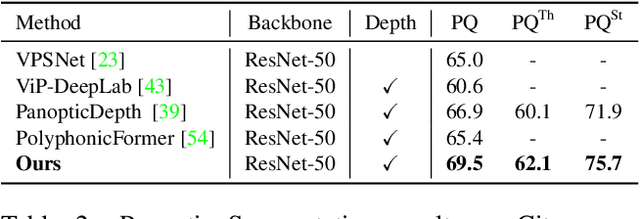
Depth-aware panoptic segmentation is an emerging topic in computer vision which combines semantic and geometric understanding for more robust scene interpretation. Recent works pursue unified frameworks to tackle this challenge but mostly still treat it as two individual learning tasks, which limits their potential for exploring cross-domain information. We propose a deeply unified framework for depth-aware panoptic segmentation, which performs joint segmentation and depth estimation both in a per-segment manner with identical object queries. To narrow the gap between the two tasks, we further design a geometric query enhancement method, which is able to integrate scene geometry into object queries using latent representations. In addition, we propose a bi-directional guidance learning approach to facilitate cross-task feature learning by taking advantage of their mutual relations. Our method sets the new state of the art for depth-aware panoptic segmentation on both Cityscapes-DVPS and SemKITTI-DVPS datasets. Moreover, our guidance learning approach is shown to deliver performance improvement even under incomplete supervision labels.
Improving Aspect-Based Sentiment with End-to-End Semantic Role Labeling Model
Jul 27, 2023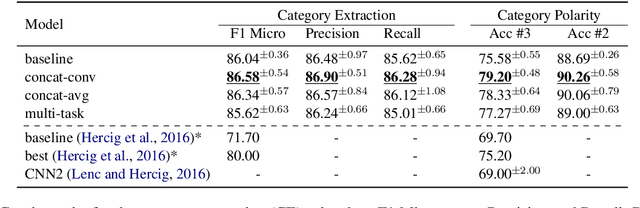
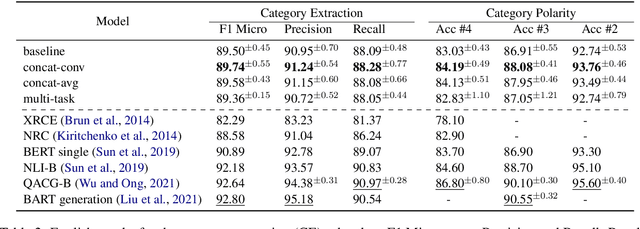
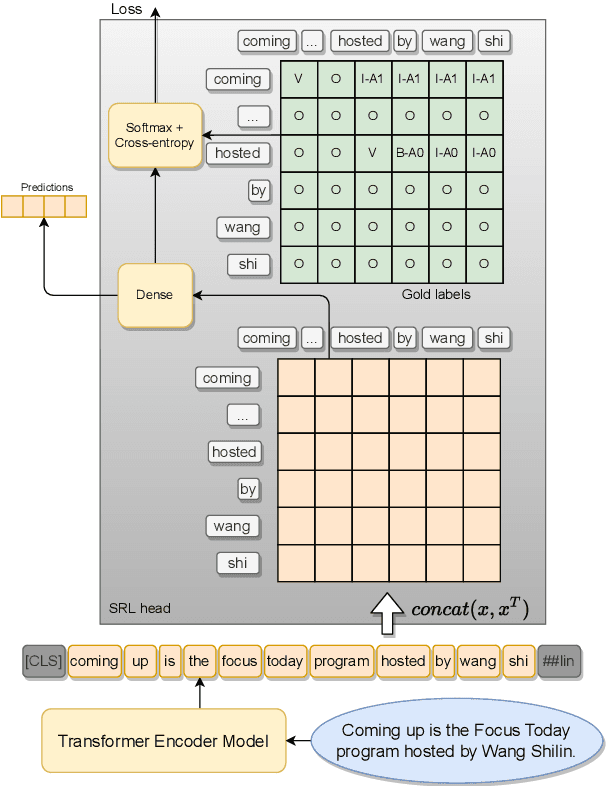
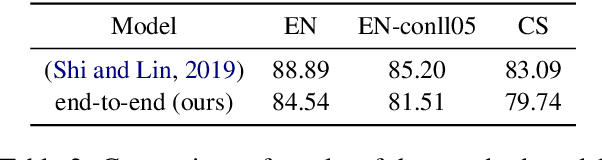
This paper presents a series of approaches aimed at enhancing the performance of Aspect-Based Sentiment Analysis (ABSA) by utilizing extracted semantic information from a Semantic Role Labeling (SRL) model. We propose a novel end-to-end Semantic Role Labeling model that effectively captures most of the structured semantic information within the Transformer hidden state. We believe that this end-to-end model is well-suited for our newly proposed models that incorporate semantic information. We evaluate the proposed models in two languages, English and Czech, employing ELECTRA-small models. Our combined models improve ABSA performance in both languages. Moreover, we achieved new state-of-the-art results on the Czech ABSA.
Communication-Efficient Framework for Distributed Image Semantic Wireless Transmission
Aug 07, 2023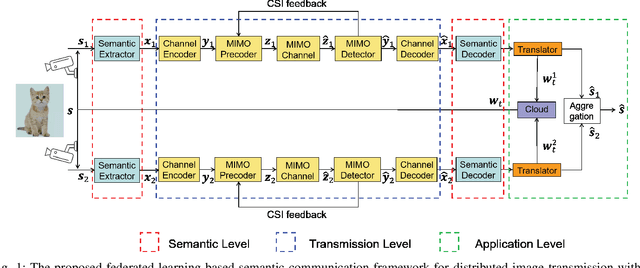
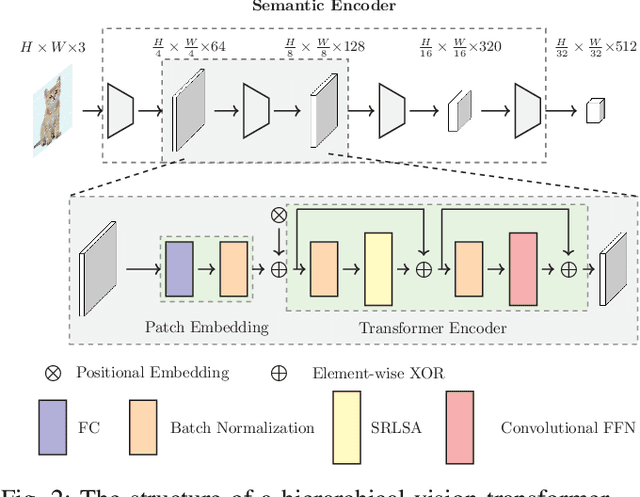
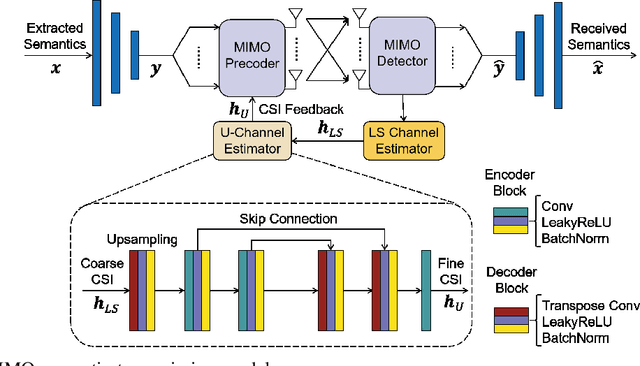
Multi-node communication, which refers to the interaction among multiple devices, has attracted lots of attention in many Internet-of-Things (IoT) scenarios. However, its huge amounts of data flows and inflexibility for task extension have triggered the urgent requirement of communication-efficient distributed data transmission frameworks. In this paper, inspired by the great superiorities on bandwidth reduction and task adaptation of semantic communications, we propose a federated learning-based semantic communication (FLSC) framework for multi-task distributed image transmission with IoT devices. Federated learning enables the design of independent semantic communication link of each user while further improves the semantic extraction and task performance through global aggregation. Each link in FLSC is composed of a hierarchical vision transformer (HVT)-based extractor and a task-adaptive translator for coarse-to-fine semantic extraction and meaning translation according to specific tasks. In order to extend the FLSC into more realistic conditions, we design a channel state information-based multiple-input multiple-output transmission module to combat channel fading and noise. Simulation results show that the coarse semantic information can deal with a range of image-level tasks. Moreover, especially in low signal-to-noise ratio and channel bandwidth ratio regimes, FLSC evidently outperforms the traditional scheme, e.g. about 10 peak signal-to-noise ratio gain in the 3 dB channel condition.
ChatGPT for Software Security: Exploring the Strengths and Limitations of ChatGPT in the Security Applications
Aug 10, 2023ChatGPT, as a versatile large language model, has demonstrated remarkable potential in addressing inquiries across various domains. Its ability to analyze, comprehend, and synthesize information from both online sources and user inputs has garnered significant attention. Previous research has explored ChatGPT's competence in code generation and code reviews. In this paper, we delve into ChatGPT's capabilities in security-oriented program analysis, focusing on perspectives from both attackers and security analysts. We present a case study involving several security-oriented program analysis tasks while deliberately introducing challenges to assess ChatGPT's responses. Through an examination of the quality of answers provided by ChatGPT, we gain a clearer understanding of its strengths and limitations in the realm of security-oriented program analysis.
A Smart Robotic System for Industrial Plant Supervision
Aug 10, 2023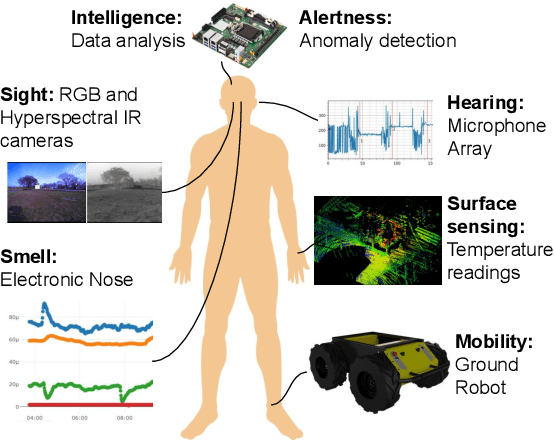

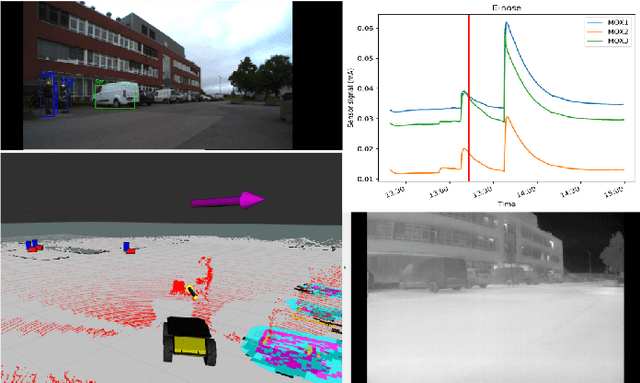
In today's chemical production plants, human field operators perform frequent checks on the plant's integrity to guarantee high safety standards, and thus are possibly the first to encounter dangerous operating conditions. To alleviate their tasks of failure detection and monitoring by audio, visual, and olfactory perceptions, we present a robotic system that consists of an autonomously navigating robot integrated with various sensors and data processing. We aim to resemble the human sensing and interpretation capabilities of sight, smell, and hearing, for providing automated inspection. We evaluate our system extensively at a wastewater facility in full working conditions. Our results demonstrate that the system is able to robustly navigate a plant and to provide useful information about critical operating conditions.
Advancing Relation Extraction through Language Probing with Exemplars from Set Co-Expansion
Aug 18, 2023
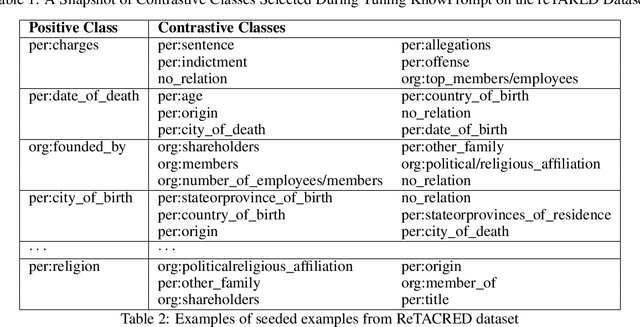
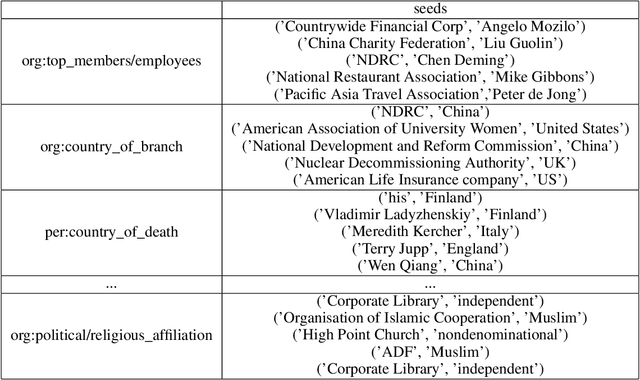

Relation Extraction (RE) is a pivotal task in automatically extracting structured information from unstructured text. In this paper, we present a multi-faceted approach that integrates representative examples and through co-set expansion. The primary goal of our method is to enhance relation classification accuracy and mitigating confusion between contrastive classes. Our approach begins by seeding each relationship class with representative examples. Subsequently, our co-set expansion algorithm enriches training objectives by incorporating similarity measures between target pairs and representative pairs from the target class. Moreover, the co-set expansion process involves a class ranking procedure that takes into account exemplars from contrastive classes. Contextual details encompassing relation mentions are harnessed via context-free Hearst patterns to ascertain contextual similarity. Empirical evaluation demonstrates the efficacy of our co-set expansion approach, resulting in a significant enhancement of relation classification performance. Our method achieves an observed margin of at least 1 percent improvement in accuracy in most settings, on top of existing fine-tuning approaches. To further refine our approach, we conduct an in-depth analysis that focuses on tuning contrastive examples. This strategic selection and tuning effectively reduce confusion between classes sharing similarities, leading to a more precise classification process. Experimental results underscore the effectiveness of our proposed framework for relation extraction. The synergy between co-set expansion and context-aware prompt tuning substantially contributes to improved classification accuracy. Furthermore, the reduction in confusion between contrastive classes through contrastive examples tuning validates the robustness and reliability of our method.
Training-Free Energy Beamforming Assisted by Wireless Sensing
Aug 18, 2023
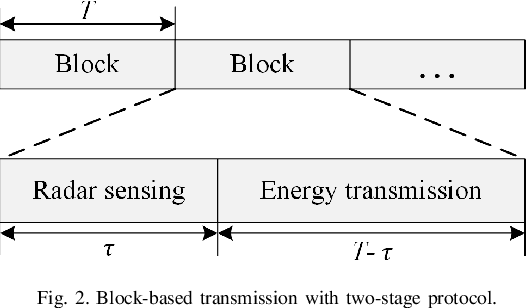
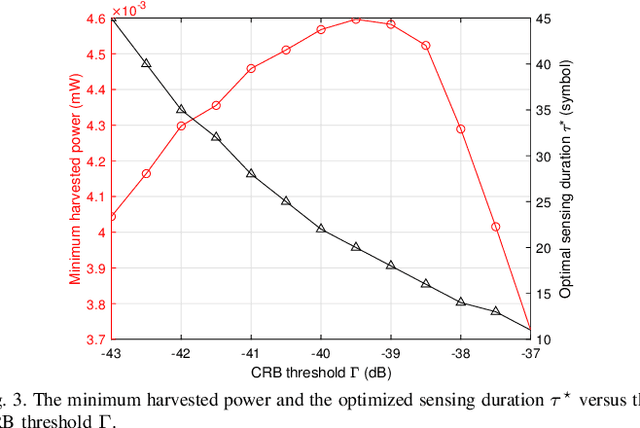
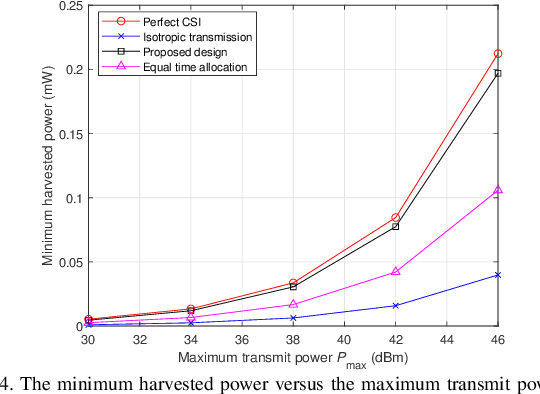
This paper studies the transmit energy beamforming in a multi-antenna wireless power transfer (WPT) system, in which an access point (AP) equipped with a uniform linear array (ULA) sends radio signals to wirelessly charge multiple single-antenna energy receivers (ERs). Different from conventional energy beamforming designs that require the AP to acquire the channel state information (CSI) via training and feedback, we propose a new training-free energy beamforming approach assisted by wireless radar sensing, which is implemented based on the following two-stage protocol. In the first stage, the AP performs wireless radar sensing to estimate the path gain and angle parameters of the ERs for constructing the corresponding CSI. In the second stage, the AP implements the transmit energy beamforming based on the constructed CSI to efficiently charge these ERs in a fair manner. Under this setup, first, we jointly optimize the sensing beamformers and duration in the first stage to minimize the sensing duration, while ensuring a given accuracy threshold for parameters estimation subject to the maximum transmit power constraint at the AP. Next, we optimize the energy beamformers in the second stage to maximize the minimum harvested energy by all ERs. In this approach, the estimation accuracy threshold for the first stage is properly designed to balance the resource allocation between the two stages for optimizing the ultimate energy harvesting performance. Finally, numerical results show that the proposed training-free energy beamforming design performs close to the performance upper bound with perfect CSI, and outperforms the benchmark schemes without such joint optimization and that with isotropic transmission.