 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: Gaussian Unified Instance Detection for Enhanced Obstacle Perception in Autonomous Driving
Nov 17, 2025In the realm of autonomous driving, accurately detecting surrounding obstacles is crucial for effective decision-making. Traditional methods primarily rely on 3D bounding boxes to represent these obstacles, which often fail to capture the complexity of irregularly shaped, real-world objects. To overcome these limitations, we present GUIDE, a novel framework that utilizes 3D Gaussians for instance detection and occupancy prediction. Unlike conventional occupancy prediction methods, GUIDE also offers robust tracking capabilities. Our framework employs a sparse representation strategy, using Gaussian-to-Voxel Splatting to provide fine-grained, instance-level occupancy data without the computational demands associated with dense voxel grids. Experimental validation on the nuScenes dataset demonstrates GUIDE's performance, with an instance occupancy mAP of 21.61, marking a 50\% improvement over existing methods, alongside competitive tracking capabilities. GUIDE establishes a new benchmark in autonomous perception systems, effectively combining precision with computational efficiency to better address the complexities of real-world driving environments.
SAM4D: Segment Anything in Camera and LiDAR Streams
Jun 26, 2025


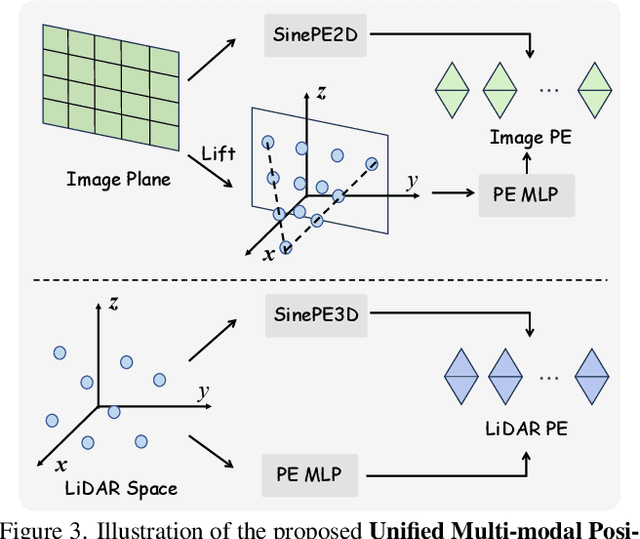
We present SAM4D, a multi-modal and temporal foundation model designed for promptable segmentation across camera and LiDAR streams. Unified Multi-modal Positional Encoding (UMPE) is introduced to align camera and LiDAR features in a shared 3D space, enabling seamless cross-modal prompting and interaction. Additionally, we propose Motion-aware Cross-modal Memory Attention (MCMA), which leverages ego-motion compensation to enhance temporal consistency and long-horizon feature retrieval, ensuring robust segmentation across dynamically changing autonomous driving scenes. To avoid annotation bottlenecks, we develop a multi-modal automated data engine that synergizes VFM-driven video masklets, spatiotemporal 4D reconstruction, and cross-modal masklet fusion. This framework generates camera-LiDAR aligned pseudo-labels at a speed orders of magnitude faster than human annotation while preserving VFM-derived semantic fidelity in point cloud representations. We conduct extensive experiments on the constructed Waymo-4DSeg, which demonstrate the powerful cross-modal segmentation ability and great potential in data annotation of proposed SAM4D.
PointLoRA: Low-Rank Adaptation with Token Selection for Point Cloud Learning
Apr 22, 2025



Self-supervised representation learning for point cloud has demonstrated effectiveness in improving pre-trained model performance across diverse tasks. However, as pre-trained models grow in complexity, fully fine-tuning them for downstream applications demands substantial computational and storage resources. Parameter-efficient fine-tuning (PEFT) methods offer a promising solution to mitigate these resource requirements, yet most current approaches rely on complex adapter and prompt mechanisms that increase tunable parameters. In this paper, we propose PointLoRA, a simple yet effective method that combines low-rank adaptation (LoRA) with multi-scale token selection to efficiently fine-tune point cloud models. Our approach embeds LoRA layers within the most parameter-intensive components of point cloud transformers, reducing the need for tunable parameters while enhancing global feature capture. Additionally, multi-scale token selection extracts critical local information to serve as prompts for downstream fine-tuning, effectively complementing the global context captured by LoRA. The experimental results across various pre-trained models and three challenging public datasets demonstrate that our approach achieves competitive performance with only 3.43% of the trainable parameters, making it highly effective for resource-constrained applications. Source code is available at: https://github.com/songw-zju/PointLoRA.
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023



Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.