 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Referring Image Segmentation Using Text Supervision
Aug 28, 2023

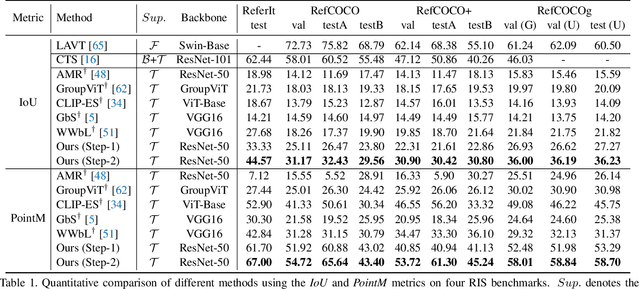
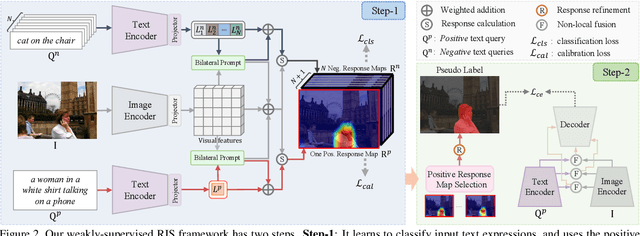
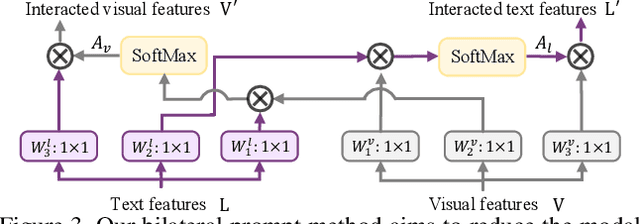
Existing Referring Image Segmentation (RIS) methods typically require expensive pixel-level or box-level annotations for supervision. In this paper, we observe that the referring texts used in RIS already provide sufficient information to localize the target object. Hence, we propose a novel weakly-supervised RIS framework to formulate the target localization problem as a classification process to differentiate between positive and negative text expressions. While the referring text expressions for an image are used as positive expressions, the referring text expressions from other images can be used as negative expressions for this image. Our framework has three main novelties. First, we propose a bilateral prompt method to facilitate the classification process, by harmonizing the domain discrepancy between visual and linguistic features. Second, we propose a calibration method to reduce noisy background information and improve the correctness of the response maps for target object localization. Third, we propose a positive response map selection strategy to generate high-quality pseudo-labels from the enhanced response maps, for training a segmentation network for RIS inference. For evaluation, we propose a new metric to measure localization accuracy. Experiments on four benchmarks show that our framework achieves promising performances to existing fully-supervised RIS methods while outperforming state-of-the-art weakly-supervised methods adapted from related areas. Code is available at https://github.com/fawnliu/TRIS.
Dynamic Frame Interpolation in Wavelet Domain
Sep 07, 2023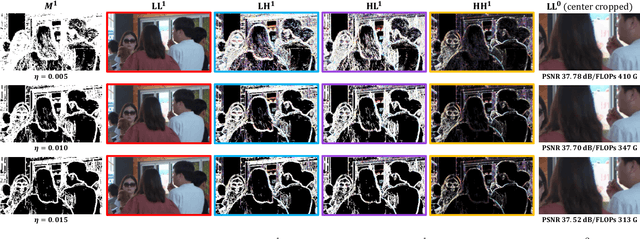

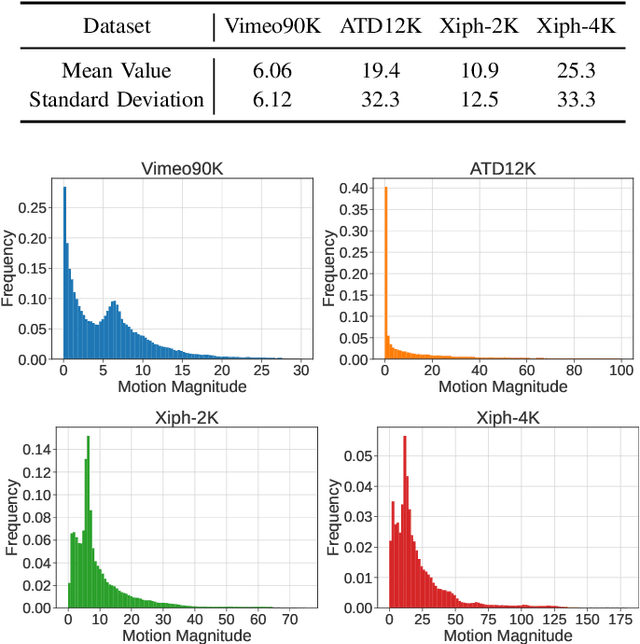

Video frame interpolation is an important low-level vision task, which can increase frame rate for more fluent visual experience. Existing methods have achieved great success by employing advanced motion models and synthesis networks. However, the spatial redundancy when synthesizing the target frame has not been fully explored, that can result in lots of inefficient computation. On the other hand, the computation compression degree in frame interpolation is highly dependent on both texture distribution and scene motion, which demands to understand the spatial-temporal information of each input frame pair for a better compression degree selection. In this work, we propose a novel two-stage frame interpolation framework termed WaveletVFI to address above problems. It first estimates intermediate optical flow with a lightweight motion perception network, and then a wavelet synthesis network uses flow aligned context features to predict multi-scale wavelet coefficients with sparse convolution for efficient target frame reconstruction, where the sparse valid masks that control computation in each scale are determined by a crucial threshold ratio. Instead of setting a fixed value like previous methods, we find that embedding a classifier in the motion perception network to learn a dynamic threshold for each sample can achieve more computation reduction with almost no loss of accuracy. On the common high resolution and animation frame interpolation benchmarks, proposed WaveletVFI can reduce computation up to 40% while maintaining similar accuracy, making it perform more efficiently against other state-of-the-arts. Code is available at https://github.com/ltkong218/WaveletVFI.
Fully Onboard SLAM for Distributed Mapping with a Swarm of Nano-Drones
Sep 07, 2023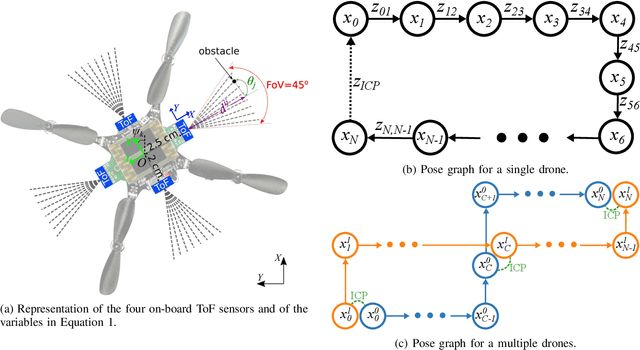
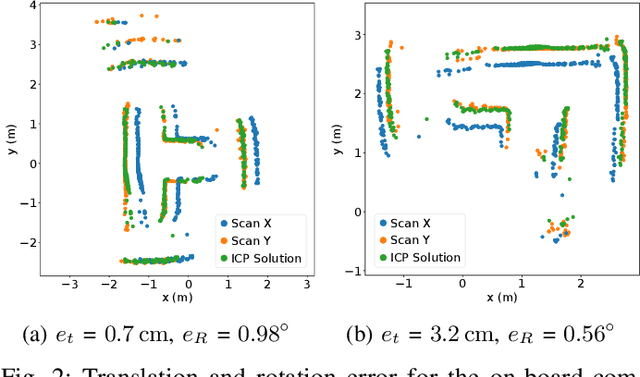
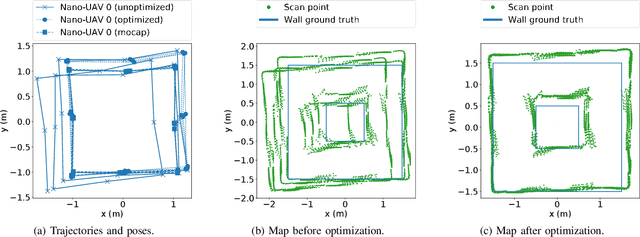
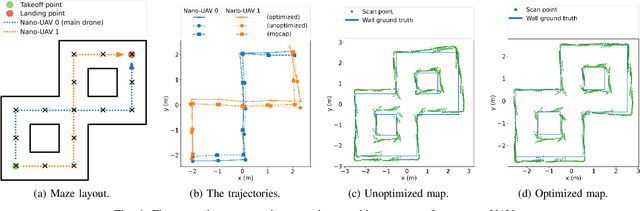
The use of Unmanned Aerial Vehicles (UAVs) is rapidly increasing in applications ranging from surveillance and first-aid missions to industrial automation involving cooperation with other machines or humans. To maximize area coverage and reduce mission latency, swarms of collaborating drones have become a significant research direction. However, this approach requires open challenges in positioning, mapping, and communications to be addressed. This work describes a distributed mapping system based on a swarm of nano-UAVs, characterized by a limited payload of 35 g and tightly constrained on-board sensing and computing capabilities. Each nano-UAV is equipped with four 64-pixel depth sensors that measure the relative distance to obstacles in four directions. The proposed system merges the information from the swarm and generates a coherent grid map without relying on any external infrastructure. The data fusion is performed using the iterative closest point algorithm and a graph-based simultaneous localization and mapping algorithm, running entirely on-board the UAV's low-power ARM Cortex-M microcontroller with just 192 kB of SRAM memory. Field results gathered in three different mazes from a swarm of up to 4 nano-UAVs prove a mapping accuracy of 12 cm and demonstrate that the mapping time is inversely proportional to the number of agents. The proposed framework scales linearly in terms of communication bandwidth and on-board computational complexity, supporting communication between up to 20 nano-UAVs and mapping of areas up to 180 m2 with the chosen configuration requiring only 50 kB of memory.
ASTER: Automatic Speech Recognition System Accessibility Testing for Stutterers
Aug 30, 2023
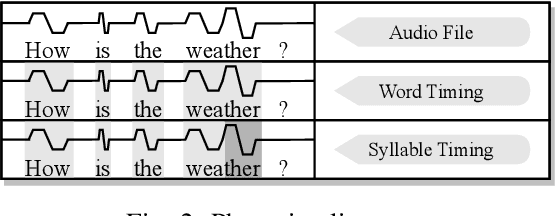
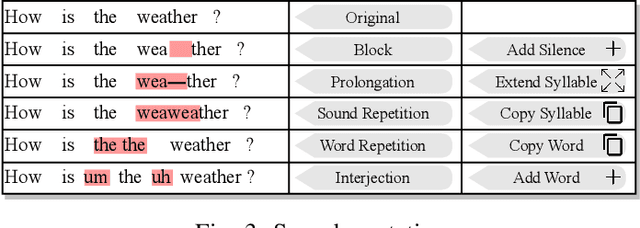
The popularity of automatic speech recognition (ASR) systems nowadays leads to an increasing need for improving their accessibility. Handling stuttering speech is an important feature for accessible ASR systems. To improve the accessibility of ASR systems for stutterers, we need to expose and analyze the failures of ASR systems on stuttering speech. The speech datasets recorded from stutterers are not diverse enough to expose most of the failures. Furthermore, these datasets lack ground truth information about the non-stuttered text, rendering them unsuitable as comprehensive test suites. Therefore, a methodology for generating stuttering speech as test inputs to test and analyze the performance of ASR systems is needed. However, generating valid test inputs in this scenario is challenging. The reason is that although the generated test inputs should mimic how stutterers speak, they should also be diverse enough to trigger more failures. To address the challenge, we propose ASTER, a technique for automatically testing the accessibility of ASR systems. ASTER can generate valid test cases by injecting five different types of stuttering. The generated test cases can both simulate realistic stuttering speech and expose failures in ASR systems. Moreover, ASTER can further enhance the quality of the test cases with a multi-objective optimization-based seed updating algorithm. We implemented ASTER as a framework and evaluated it on four open-source ASR models and three commercial ASR systems. We conduct a comprehensive evaluation of ASTER and find that it significantly increases the word error rate, match error rate, and word information loss in the evaluated ASR systems. Additionally, our user study demonstrates that the generated stuttering audio is indistinguishable from real-world stuttering audio clips.
Spatial Self-Distillation for Object Detection with Inaccurate Bounding Boxes
Aug 15, 2023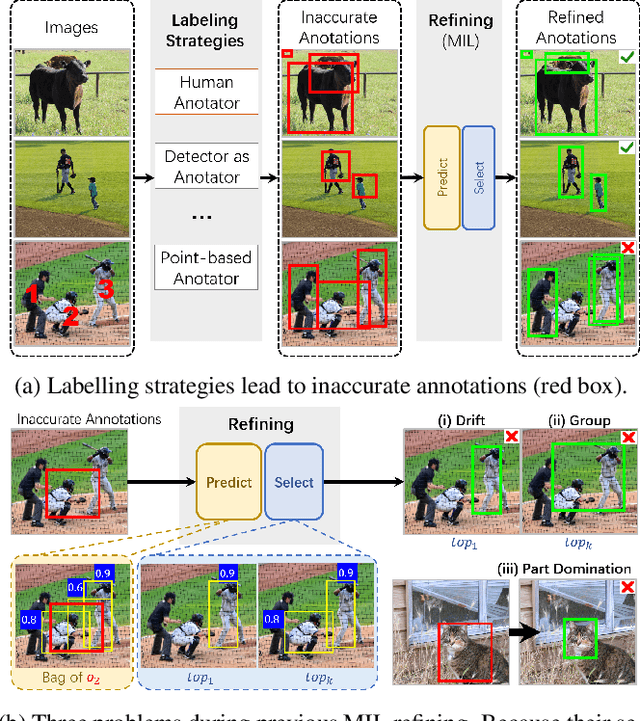
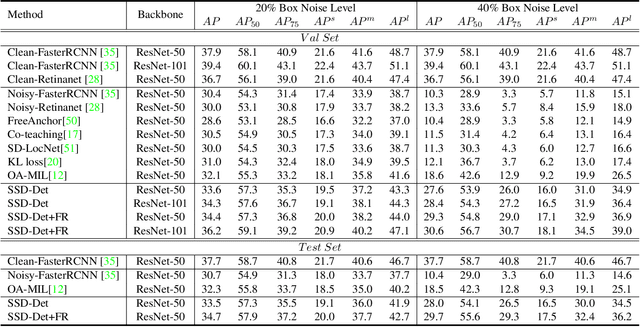
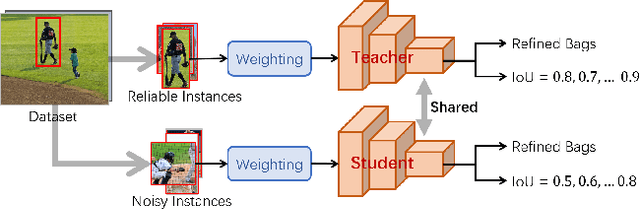
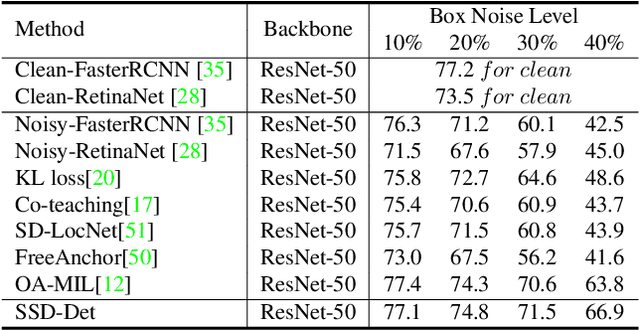
Object detection via inaccurate bounding boxes supervision has boosted a broad interest due to the expensive high-quality annotation data or the occasional inevitability of low annotation quality (\eg tiny objects). The previous works usually utilize multiple instance learning (MIL), which highly depends on category information, to select and refine a low-quality box. Those methods suffer from object drift, group prediction and part domination problems without exploring spatial information. In this paper, we heuristically propose a \textbf{Spatial Self-Distillation based Object Detector (SSD-Det)} to mine spatial information to refine the inaccurate box in a self-distillation fashion. SSD-Det utilizes a Spatial Position Self-Distillation \textbf{(SPSD)} module to exploit spatial information and an interactive structure to combine spatial information and category information, thus constructing a high-quality proposal bag. To further improve the selection procedure, a Spatial Identity Self-Distillation \textbf{(SISD)} module is introduced in SSD-Det to obtain spatial confidence to help select the best proposals. Experiments on MS-COCO and VOC datasets with noisy box annotation verify our method's effectiveness and achieve state-of-the-art performance. The code is available at https://github.com/ucas-vg/PointTinyBenchmark/tree/SSD-Det.
Synergistic Multiscale Detail Refinement via Intrinsic Supervision for Underwater Image Enhancement
Aug 23, 2023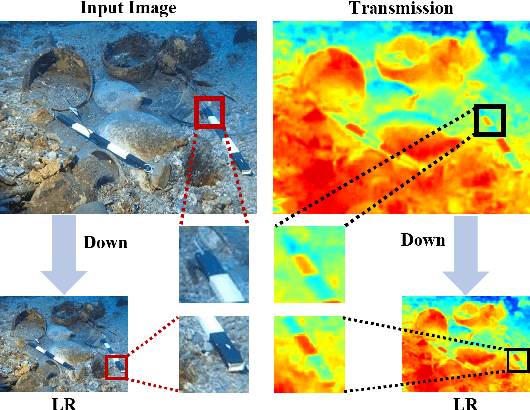
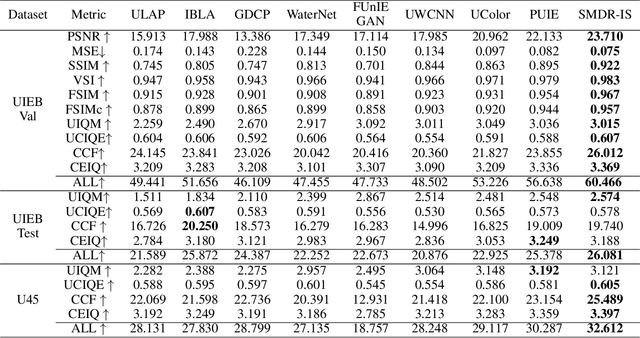
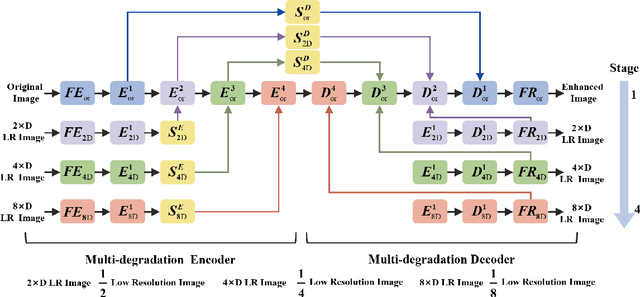

Visual restoration of underwater scenes is crucial for visual tasks, and avoiding interference from underwater media has become a prominent concern. In this work, we present a synergistic multiscale detail refinement via intrinsic supervision (SMDR-IS) to recover underwater scene details. The low-degradation stage provides multiscale detail for original stage, which achieves synergistic multiscale detail refinement through feature propagation via the adaptive selective intrinsic supervised feature module (ASISF), which achieves synergistic multiscale detail refinement. ASISF is developed using intrinsic supervision to precisely control and guide feature transmission in the multi-degradation stages. ASISF improves the multiscale detail refinement while reducing interference from irrelevant scene information from the low-degradation stage. Additionally, within the multi-degradation encoder-decoder of SMDR-IS, we introduce a bifocal intrinsic-context attention module (BICA). This module is designed to effectively leverage multi-scale scene information found in images, using intrinsic supervision principles as its foundation. BICA facilitates the guidance of higher-resolution spaces by leveraging lower-resolution spaces, considering the significant dependency of underwater image restoration on spatial contextual relationships. During the training process, the network gains advantages from the integration of a multi-degradation loss function. This function serves as a constraint, enabling the network to effectively exploit information across various scales. When compared with state-of-the-art methods, SMDR-IS demonstrates its outstanding performance. Code will be made publicly available.
ToddlerBERTa: Exploiting BabyBERTa for Grammar Learning and Language Understanding
Aug 30, 2023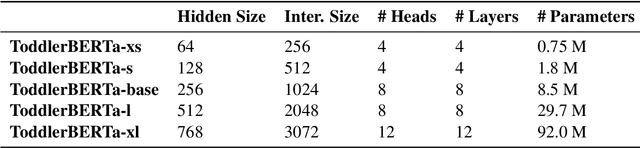
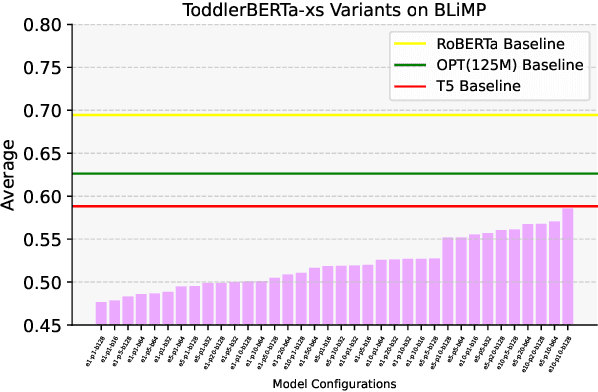
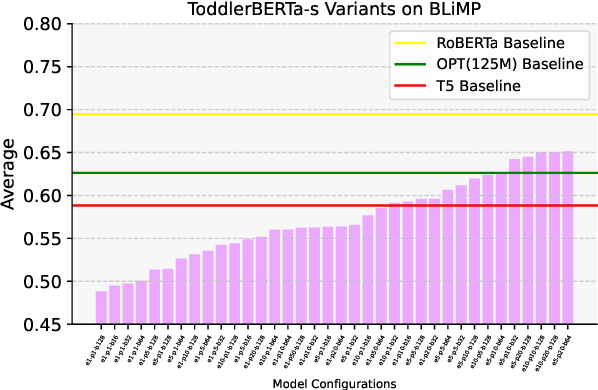

We present ToddlerBERTa, a BabyBERTa-like language model, exploring its capabilities through five different models with varied hyperparameters. Evaluating on BLiMP, SuperGLUE, MSGS, and a Supplement benchmark from the BabyLM challenge, we find that smaller models can excel in specific tasks, while larger models perform well with substantial data. Despite training on a smaller dataset, ToddlerBERTa demonstrates commendable performance, rivalling the state-of-the-art RoBERTa-base. The model showcases robust language understanding, even with single-sentence pretraining, and competes with baselines that leverage broader contextual information. Our work provides insights into hyperparameter choices, and data utilization, contributing to the advancement of language models.
Doppler-aware Odometry from FMCW Scanning Radar
Aug 21, 2023
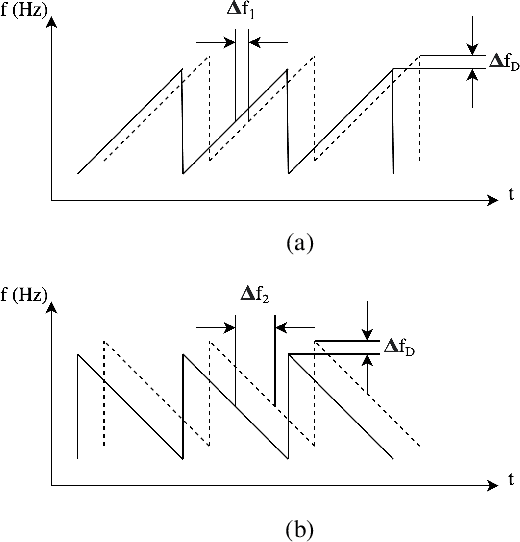
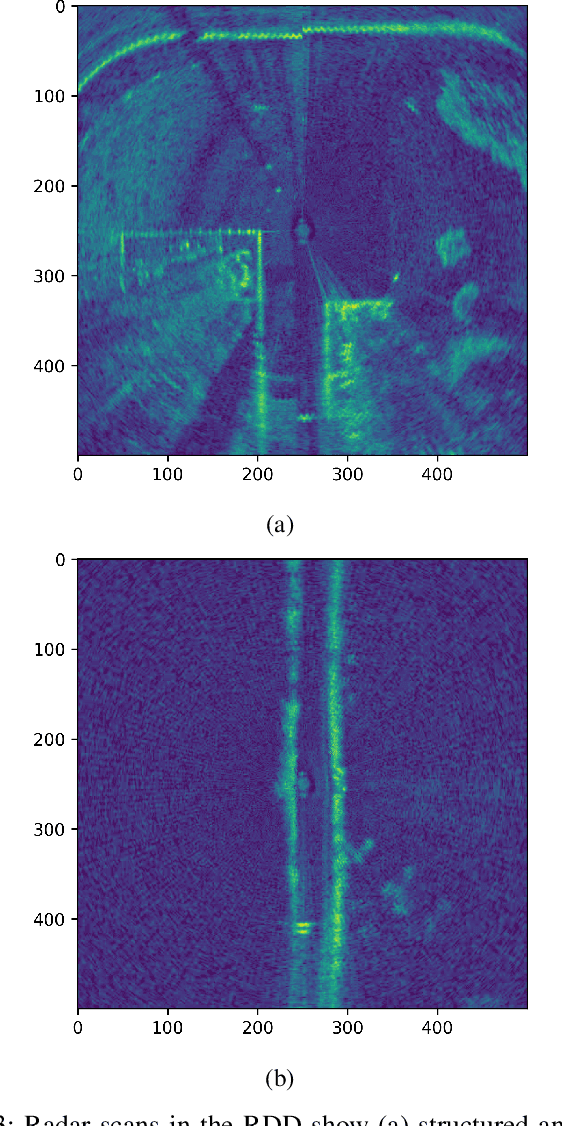
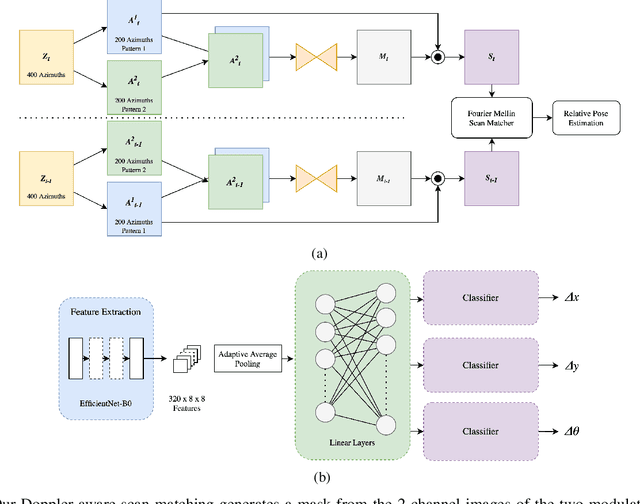
This work explores Doppler information from a millimetre-Wave (mm-W) Frequency-Modulated Continuous-Wave (FMCW) scanning radar to make odometry estimation more robust and accurate. Firstly, doppler information is added to the scan masking process to enhance correlative scan matching. Secondly, we train a Neural Network (NN) for regressing forward velocity directly from a single radar scan; we fuse this estimate with the correlative scan matching estimate and show improved robustness to bad estimates caused by challenging environment geometries, e.g. narrow tunnels. We test our method with a novel custom dataset which is released with this work at https://ori.ox.ac.uk/publications/datasets.
Measuring and Improving Chain-of-Thought Reasoning in Vision-Language Models
Sep 08, 2023

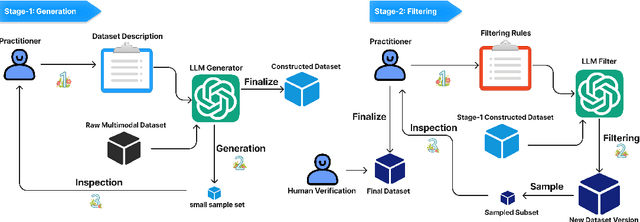
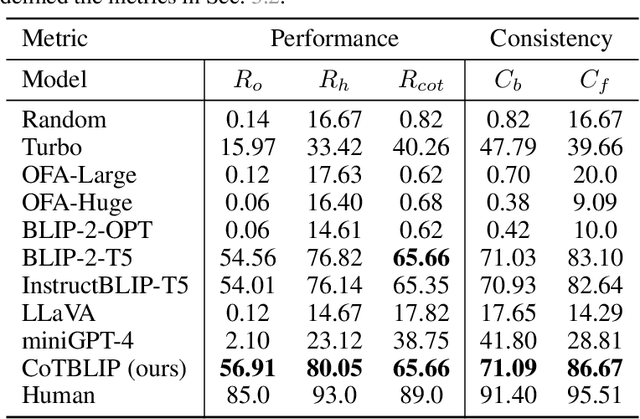
Vision-language models (VLMs) have recently demonstrated strong efficacy as visual assistants that can parse natural queries about the visual content and generate human-like outputs. In this work, we explore the ability of these models to demonstrate human-like reasoning based on the perceived information. To address a crucial concern regarding the extent to which their reasoning capabilities are fully consistent and grounded, we also measure the reasoning consistency of these models. We achieve this by proposing a chain-of-thought (CoT) based consistency measure. However, such an evaluation requires a benchmark that encompasses both high-level inference and detailed reasoning chains, which is costly. We tackle this challenge by proposing a LLM-Human-in-the-Loop pipeline, which notably reduces cost while simultaneously ensuring the generation of a high-quality dataset. Based on this pipeline and the existing coarse-grained annotated dataset, we build the CURE benchmark to measure both the zero-shot reasoning performance and consistency of VLMs. We evaluate existing state-of-the-art VLMs, and find that even the best-performing model is unable to demonstrate strong visual reasoning capabilities and consistency, indicating that substantial efforts are required to enable VLMs to perform visual reasoning as systematically and consistently as humans. As an early step, we propose a two-stage training framework aimed at improving both the reasoning performance and consistency of VLMs. The first stage involves employing supervised fine-tuning of VLMs using step-by-step reasoning samples automatically generated by LLMs. In the second stage, we further augment the training process by incorporating feedback provided by LLMs to produce reasoning chains that are highly consistent and grounded. We empirically highlight the effectiveness of our framework in both reasoning performance and consistency.
A Knowledge-enhanced Two-stage Generative Framework for Medical Dialogue Information Extraction
Jul 30, 2023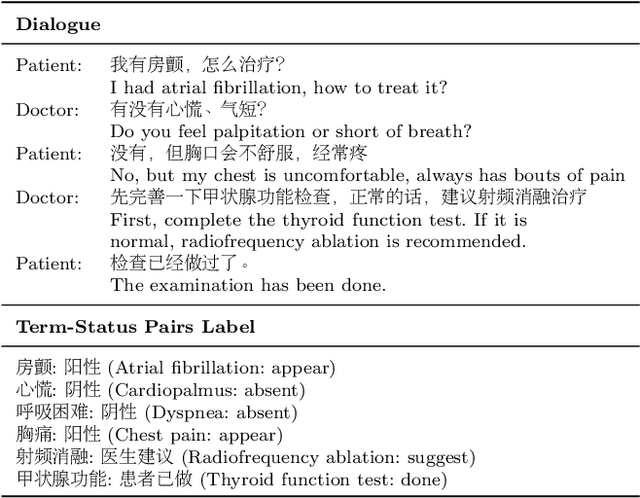
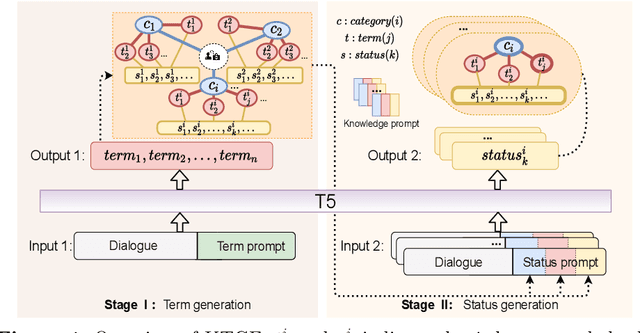
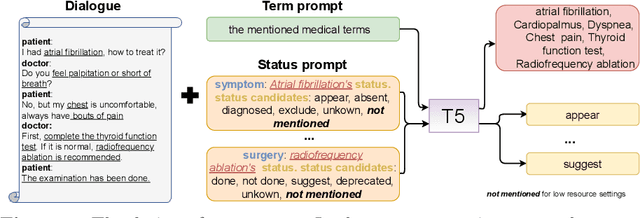
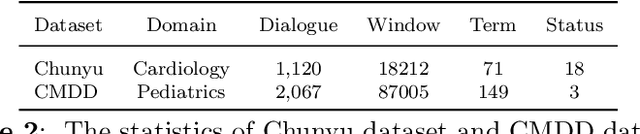
This paper focuses on term-status pair extraction from medical dialogues (MD-TSPE), which is essential in diagnosis dialogue systems and the automatic scribe of electronic medical records (EMRs). In the past few years, works on MD-TSPE have attracted increasing research attention, especially after the remarkable progress made by generative methods. However, these generative methods output a whole sequence consisting of term-status pairs in one stage and ignore integrating prior knowledge, which demands a deeper understanding to model the relationship between terms and infer the status of each term. This paper presents a knowledge-enhanced two-stage generative framework (KTGF) to address the above challenges. Using task-specific prompts, we employ a single model to complete the MD-TSPE through two phases in a unified generative form: we generate all terms the first and then generate the status of each generated term. In this way, the relationship between terms can be learned more effectively from the sequence containing only terms in the first phase, and our designed knowledge-enhanced prompt in the second phase can leverage the category and status candidates of the generated term for status generation. Furthermore, our proposed special status ``not mentioned" makes more terms available and enriches the training data in the second phase, which is critical in the low-resource setting. The experiments on the Chunyu and CMDD datasets show that the proposed method achieves superior results compared to the state-of-the-art models in the full training and low-resource settings.