 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Impact of Generative Artificial Intelligence in Education: A Thematic Analysis
Jan 17, 2025



The recent advancements in Generative Artificial intelligence (GenAI) technology have been transformative for the field of education. Large Language Models (LLMs) such as ChatGPT and Bard can be leveraged to automate boilerplate tasks, create content for personalised teaching, and handle repetitive tasks to allow more time for creative thinking. However, it is important to develop guidelines, policies, and assessment methods in the education sector to ensure the responsible integration of these tools. In this article, thematic analysis has been performed on seven essays obtained from professionals in the education sector to understand the advantages and pitfalls of using GenAI models such as ChatGPT and Bard in education. Exploratory Data Analysis (EDA) has been performed on the essays to extract further insights from the text. The study found several themes which highlight benefits and drawbacks of GenAI tools, as well as suggestions to overcome these limitations and ensure that students are using these tools in a responsible and ethical manner.
Adaptive Self-Supervised Learning Strategies for Dynamic On-Device LLM Personalization
Sep 25, 2024



Large language models (LLMs) have revolutionized how we interact with technology, but their personalization to individual user preferences remains a significant challenge, particularly in on-device applications. Traditional methods often depend heavily on labeled datasets and can be resource-intensive. To address these issues, we present Adaptive Self-Supervised Learning Strategies (ASLS), which utilizes self-supervised learning techniques to personalize LLMs dynamically. The framework comprises a user profiling layer for collecting interaction data and a neural adaptation layer for real-time model fine-tuning. This innovative approach enables continuous learning from user feedback, allowing the model to generate responses that align closely with user-specific contexts. The adaptive mechanisms of ASLS minimize computational demands and enhance personalization efficiency. Experimental results across various user scenarios illustrate the superior performance of ASLS in boosting user engagement and satisfaction, highlighting its potential to redefine LLMs as highly responsive and context-aware systems on-device.
Doppler-aware Odometry from FMCW Scanning Radar
Aug 21, 2023



This work explores Doppler information from a millimetre-Wave (mm-W) Frequency-Modulated Continuous-Wave (FMCW) scanning radar to make odometry estimation more robust and accurate. Firstly, doppler information is added to the scan masking process to enhance correlative scan matching. Secondly, we train a Neural Network (NN) for regressing forward velocity directly from a single radar scan; we fuse this estimate with the correlative scan matching estimate and show improved robustness to bad estimates caused by challenging environment geometries, e.g. narrow tunnels. We test our method with a novel custom dataset which is released with this work at https://ori.ox.ac.uk/publications/datasets.
Fool Me Once: Robust Selective Segmentation via Out-of-Distribution Detection with Contrastive Learning
Mar 01, 2021
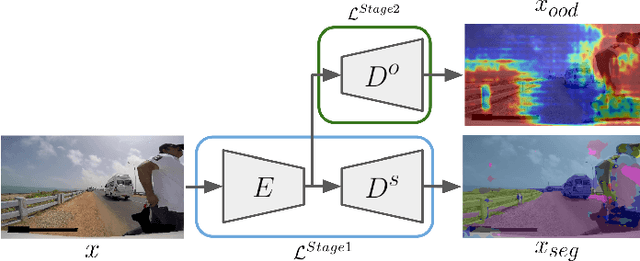

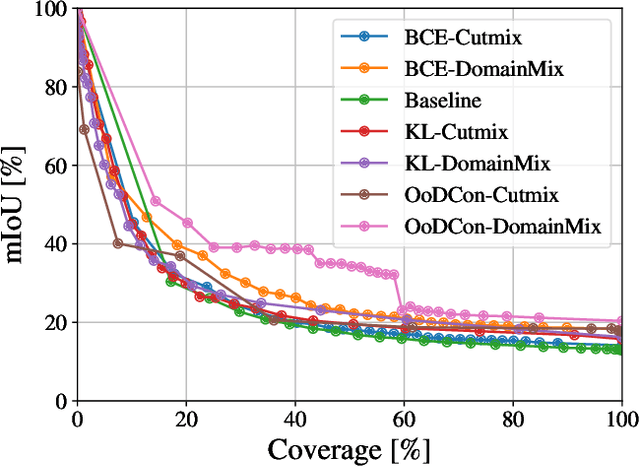
In this work, we train a network to simultaneously perform segmentation and pixel-wise Out-of-Distribution (OoD) detection, such that the segmentation of unknown regions of scenes can be rejected. This is made possible by leveraging an OoD dataset with a novel contrastive objective and data augmentation scheme. By combining data including unknown classes in the training data, a more robust feature representation can be learned with known classes represented distinctly from those unknown. When presented with unknown classes or conditions, many current approaches for segmentation frequently exhibit high confidence in their inaccurate segmentations and cannot be trusted in many operational environments. We validate our system on a real-world dataset of unusual driving scenes, and show that by selectively segmenting scenes based on what is predicted as OoD, we can increase the segmentation accuracy by an IoU of 0.2 with respect to alternative techniques.
Keep off the Grass: Permissible Driving Routes from Radar with Weak Audio Supervision
May 11, 2020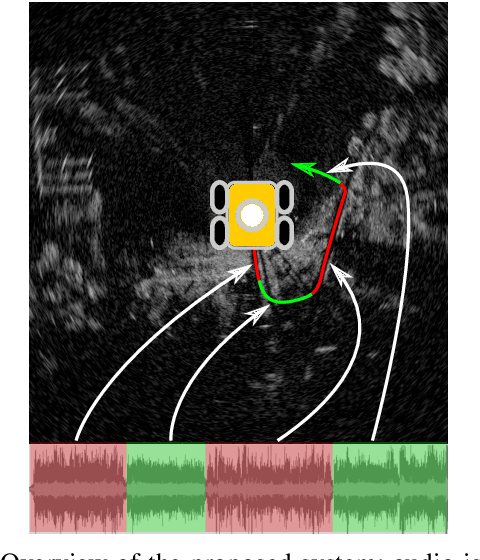
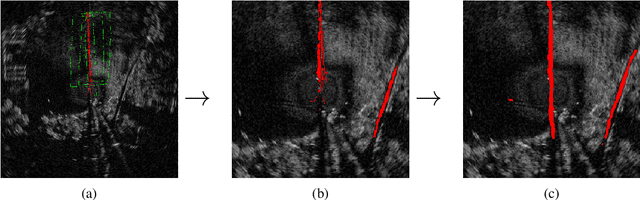

Reliable outdoor deployment of mobile robots requires the robust identification of permissible driving routes in a given environment. The performance of LiDAR and vision-based perception systems deteriorates significantly if certain environmental factors are present e.g. rain, fog, darkness. Perception systems based on FMCW scanning radar maintain full performance regardless of environmental conditions and with a longer range than alternative sensors. Learning to segment a radar scan based on driveability in a fully supervised manner is not feasible as labelling each radar scan on a bin-by-bin basis is both difficult and time-consuming to do by hand. We therefore weakly supervise the training of the radar-based classifier through an audio-based classifier that is able to predict the terrain type underneath the robot. By combining odometry, GPS and the terrain labels from the audio classifier, we are able to construct a terrain labelled trajectory of the robot in the environment which is then used to label the radar scans. Using a curriculum learning procedure, we then train a radar segmentation network to generalise beyond the initial labelling and to detect all permissible driving routes in the environment.
Coupling Rendering and Generative Adversarial Networks for Artificial SAS Image Generation
Oct 02, 2019
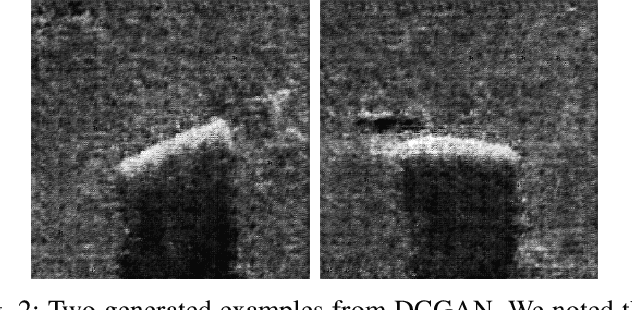
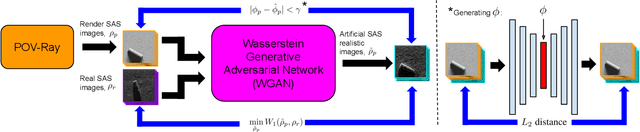

Acquisition of Synthetic Aperture Sonar (SAS) datasets is bottlenecked by the costly deployment of SAS imaging systems, and even when data acquisition is possible,the data is often skewed towards containing barren seafloor rather than objects of interest. We present a novel pipeline, called SAS GAN, which couples an optical renderer with a generative adversarial network (GAN) to synthesize realistic SAS images of targets on the seafloor. This coupling enables high levels of SAS image realism while enabling control over image geometry and parameters. We demonstrate qualitative results by presenting examples of images created with our pipeline. We also present quantitative results through the use of t-SNE and the Fr\'echet Inception Distance to argue that our generated SAS imagery potentially augments SAS datasets more effectively than an off-the-shelf GAN.
Additional Representations for Improving Synthetic Aperture Sonar Classification Using Convolutional Neural Networks
Oct 15, 2018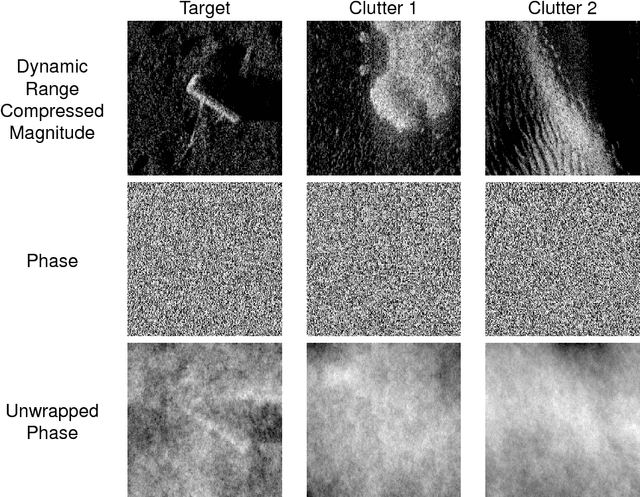
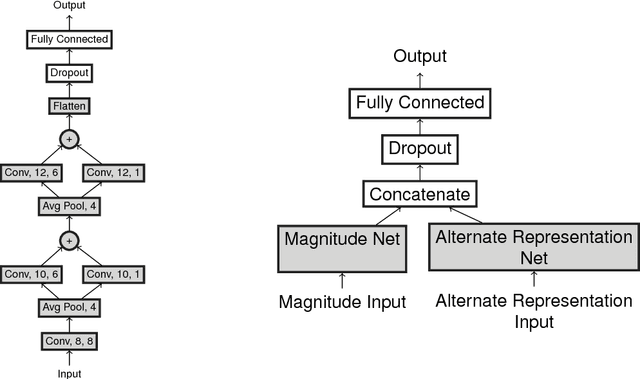
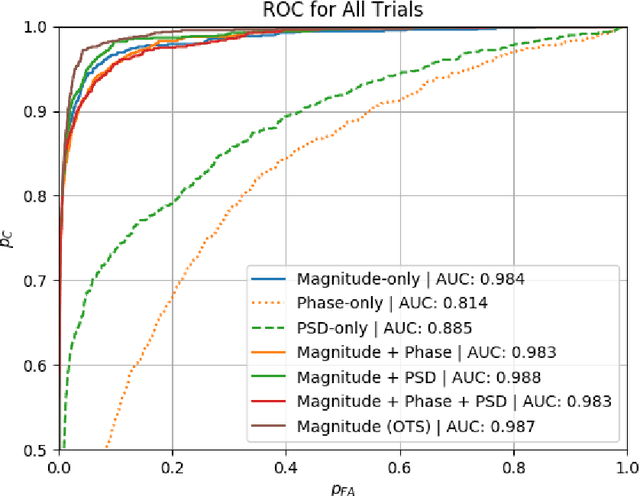

Object classification in synthetic aperture sonar (SAS) imagery is usually a data starved and class imbalanced problem. There are few objects of interest present among much benign seafloor. Despite these problems, current classification techniques discard a large portion of the collected SAS information. In particular, a beamformed SAS image, which we call a single-look complex (SLC) image, contains complex pixels composed of real and imaginary parts. For human consumption, the SLC is converted to a magnitude-phase representation and the phase information is discarded. Even more problematic, the magnitude information usually exhibits a large dynamic range (>80dB) and must be dynamic range compressed for human display. Often it is this dynamic range compressed representation, originally designed for human consumption, which is fed into a classifier. Consequently, the classification process is completely void of the phase information. In this work, we show improvements in classification performance using the phase information from the SLC as well as information from an alternate source: photographs. We perform statistical testing to demonstrate the validity of our results.