 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Token Modeling for Multi-Stem Music Source Separation with Language Models
Apr 10, 2026We propose a generative framework for multi-track music source separation (MSS) that reformulates the task as conditional discrete token generation. Unlike conventional approaches that directly estimate continuous signals in the time or frequency domain, our method combines a Conformer-based conditional encoder, a dual-path neural audio codec (HCodec), and a decoder-only language model to autoregressively generate audio tokens for four target tracks. The generated tokens are decoded back to waveforms through the codec decoder. Evaluation on the MUSDB18-HQ benchmark shows that our generative approach achieves perceptual quality approaching state-of-the-art discriminative methods, while attaining the highest NISQA score on the vocals track. Ablation studies confirm the effectiveness of the learnable Conformer encoder and the benefit of sequential cross-track generation.
ASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas
Jan 29, 2026Large language models (LLMs) are increasingly used as tool-augmented agents for multi-step decision making, yet training robust tool-using agents remains challenging. Existing methods still require manual intervention, depend on non-verifiable simulated environments, rely exclusively on either supervised fine-tuning (SFT) or reinforcement learning (RL), and struggle with stable long-horizon, multi-turn learning. To address these challenges, we introduce ASTRA, a fully automated end-to-end framework for training tool-augmented language model agents via scalable data synthesis and verifiable reinforcement learning. ASTRA integrates two complementary components. First, a pipeline that leverages the static topology of tool-call graphs synthesizes diverse, structurally grounded trajectories, instilling broad and transferable tool-use competence. Second, an environment synthesis framework that captures the rich, compositional topology of human semantic reasoning converts decomposed question-answer traces into independent, code-executable, and rule-verifiable environments, enabling deterministic multi-turn RL. Based on this method, we develop a unified training methodology that integrates SFT with online RL using trajectory-level rewards to balance task completion and interaction efficiency. Experiments on multiple agentic tool-use benchmarks demonstrate that ASTRA-trained models achieve state-of-the-art performance at comparable scales, approaching closed-source systems while preserving core reasoning ability. We release the full pipelines, environments, and trained models at https://github.com/LianjiaTech/astra.
A Hybrid Discriminative and Generative System for Universal Speech Enhancement
Jan 27, 2026Universal speech enhancement aims at handling inputs with various speech distortions and recording conditions. In this work, we propose a novel hybrid architecture that synergizes the signal fidelity of discriminative modeling with the reconstruction capabilities of generative modeling. Our system utilizes the discriminative TF-GridNet model with the Sampling-Frequency-Independent strategy to handle variable sampling rates universally. In parallel, an autoregressive model combined with spectral mapping modeling generates detail-rich speech while effectively suppressing generative artifacts. Finally, a fusion network learns adaptive weights of the two outputs under the optimization of signal-level losses and the comprehensive Speech Quality Assessment (SQA) loss. Our proposed system is evaluated in the ICASSP 2026 URGENT Challenge (Track 1) and ranks the third place.
QuarkAudio Technical Report
Dec 23, 2025Many existing audio processing and generation models rely on task-specific architectures, resulting in fragmented development efforts and limited extensibility. It is therefore promising to design a unified framework capable of handling multiple tasks, while providing robust instruction and audio understanding and high-quality audio generation. This requires a compatible paradigm design, a powerful backbone, and a high-fidelity audio reconstruction module. To meet these requirements, this technical report introduces QuarkAudio, a decoder-only autoregressive (AR) LM-based generative framework that unifies multiple tasks. The framework includes a unified discrete audio tokenizer, H-Codec, which incorporates self-supervised learning (SSL) representations into the tokenization and reconstruction process. We further propose several improvements to H-Codec, such as a dynamic frame-rate mechanism and extending the audio sampling rate to 48 kHz. QuarkAudio unifies tasks by using task-specific conditional information as the conditioning sequence of the decoder-only LM, and predicting discrete target audio tokens in an AR manner. The framework supports a wide range of audio processing and generation tasks, including speech restoration (SR), target speaker extraction (TSE), speech separation (SS), voice conversion (VC), and language-queried audio source separation (LASS). In addition, we extend downstream tasks to universal free-form audio editing guided by natural language instructions (including speech semantic editing and audio event editing). Experimental results show that H-Codec achieves high-quality audio reconstruction with a low frame rate, improving both the efficiency and performance of downstream audio generation, and that QuarkAudio delivers competitive or comparable performance to state-of-the-art task-specific or multi-task systems across multiple tasks.
UniSE: A Unified Framework for Decoder-only Autoregressive LM-based Speech Enhancement
Oct 23, 2025



The development of neural audio codecs (NACs) has largely promoted applications of language models (LMs) to speech processing and understanding. However, there lacks the verification on the effectiveness of autoregressive (AR) LMbased models in unifying different sub-tasks of speech enhancement (SE). In this work, we propose UniSE, a unified decoder-only LM-based framework to handle different SE tasks including speech restoration, target speaker extraction and speech separation. It takes input speech features as conditions and generates discrete tokens of the target speech using AR modeling, which facilitates a compatibility between distinct learning patterns of multiple tasks. Experiments on several benchmarks indicate the proposed UniSE can achieve competitive performance compared to discriminative and generative baselines, showing the capacity of LMs in unifying SE tasks. The demo page is available here: https://github.com/hyyan2k/UniSE.
A Vision for Auto Research with LLM Agents
Apr 26, 2025This paper introduces Agent-Based Auto Research, a structured multi-agent framework designed to automate, coordinate, and optimize the full lifecycle of scientific research. Leveraging the capabilities of large language models (LLMs) and modular agent collaboration, the system spans all major research phases, including literature review, ideation, methodology planning, experimentation, paper writing, peer review response, and dissemination. By addressing issues such as fragmented workflows, uneven methodological expertise, and cognitive overload, the framework offers a systematic and scalable approach to scientific inquiry. Preliminary explorations demonstrate the feasibility and potential of Auto Research as a promising paradigm for self-improving, AI-driven research processes.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
An Empirical Study of Vulnerability Detection using Federated Learning
Nov 25, 2024Although Deep Learning (DL) methods becoming increasingly popular in vulnerability detection, their performance is seriously limited by insufficient training data. This is mainly because few existing software organizations can maintain a complete set of high-quality samples for DL-based vulnerability detection. Due to the concerns about privacy leakage, most of them are reluctant to share data, resulting in the data silo problem. Since enables collaboratively model training without data sharing, Federated Learning (FL) has been investigated as a promising means of addressing the data silo problem in DL-based vulnerability detection. However, since existing FL-based vulnerability detection methods focus on specific applications, it is still far unclear i) how well FL adapts to common vulnerability detection tasks and ii) how to design a high-performance FL solution for a specific vulnerability detection task. To answer these two questions, this paper first proposes VulFL, an effective evaluation framework for FL-based vulnerability detection. Then, based on VulFL, this paper conducts a comprehensive study to reveal the underlying capabilities of FL in dealing with different types of CWEs, especially when facing various data heterogeneity scenarios. Our experimental results show that, compared to independent training, FL can significantly improve the detection performance of common AI models on all investigated CWEs, though the performance of FL-based vulnerability detection is limited by heterogeneous data. To highlight the performance differences between different FL solutions for vulnerability detection, we extensively investigate the impacts of different configuration strategies for each framework component of VulFL. Our study sheds light on the potential of FL in vulnerability detection, which can be used to guide the design of FL-based solutions for vulnerability detection.
ASTER: Automatic Speech Recognition System Accessibility Testing for Stutterers
Aug 30, 2023



The popularity of automatic speech recognition (ASR) systems nowadays leads to an increasing need for improving their accessibility. Handling stuttering speech is an important feature for accessible ASR systems. To improve the accessibility of ASR systems for stutterers, we need to expose and analyze the failures of ASR systems on stuttering speech. The speech datasets recorded from stutterers are not diverse enough to expose most of the failures. Furthermore, these datasets lack ground truth information about the non-stuttered text, rendering them unsuitable as comprehensive test suites. Therefore, a methodology for generating stuttering speech as test inputs to test and analyze the performance of ASR systems is needed. However, generating valid test inputs in this scenario is challenging. The reason is that although the generated test inputs should mimic how stutterers speak, they should also be diverse enough to trigger more failures. To address the challenge, we propose ASTER, a technique for automatically testing the accessibility of ASR systems. ASTER can generate valid test cases by injecting five different types of stuttering. The generated test cases can both simulate realistic stuttering speech and expose failures in ASR systems. Moreover, ASTER can further enhance the quality of the test cases with a multi-objective optimization-based seed updating algorithm. We implemented ASTER as a framework and evaluated it on four open-source ASR models and three commercial ASR systems. We conduct a comprehensive evaluation of ASTER and find that it significantly increases the word error rate, match error rate, and word information loss in the evaluated ASR systems. Additionally, our user study demonstrates that the generated stuttering audio is indistinguishable from real-world stuttering audio clips.
Thermal Infrared Colorization via Conditional Generative Adversarial Network
Nov 05, 2018
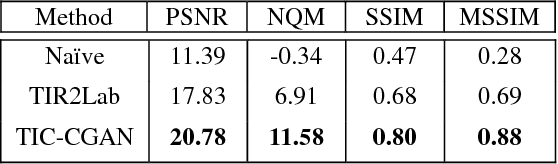
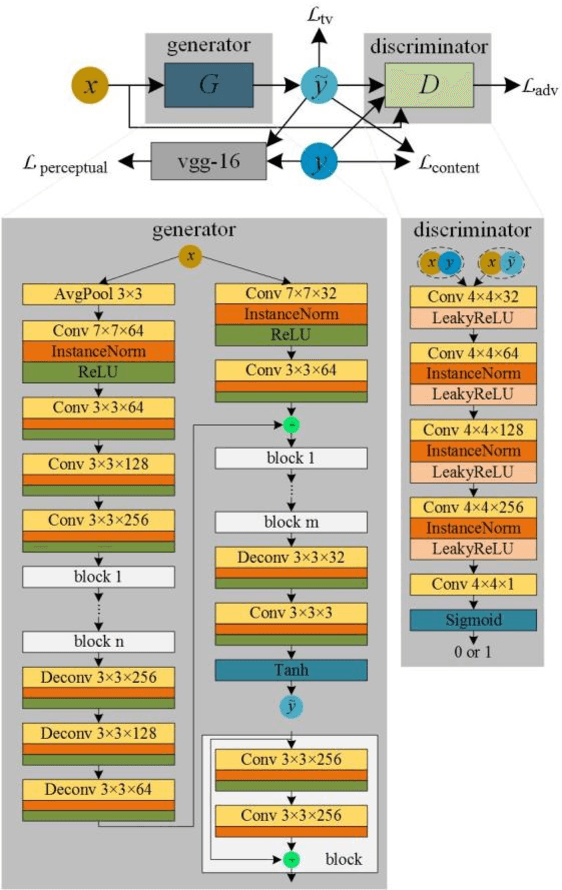

Transforming a thermal infrared image into a realistic RGB image is a challenging task. In this paper we propose a deep learning method to bridge this gap. We propose learning the transformation mapping using a coarse-to-fine generator that preserves the details. Since the standard mean squared loss cannot penalize the distance between colorized and ground truth images well, we propose a composite loss function that combines content, adversarial, perceptual and total variation losses. The content loss is used to recover global image information while the latter three losses are used to synthesize local realistic textures. Quantitative and qualitative experiments demonstrate that our approach significantly outperforms existing approaches.