 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attention Where It Matters: Rethinking Visual Document Understanding with Selective Region Concentration
Sep 03, 2023

We propose a novel end-to-end document understanding model called SeRum (SElective Region Understanding Model) for extracting meaningful information from document images, including document analysis, retrieval, and office automation. Unlike state-of-the-art approaches that rely on multi-stage technical schemes and are computationally expensive, SeRum converts document image understanding and recognition tasks into a local decoding process of the visual tokens of interest, using a content-aware token merge module. This mechanism enables the model to pay more attention to regions of interest generated by the query decoder, improving the model's effectiveness and speeding up the decoding speed of the generative scheme. We also designed several pre-training tasks to enhance the understanding and local awareness of the model. Experimental results demonstrate that SeRum achieves state-of-the-art performance on document understanding tasks and competitive results on text spotting tasks. SeRum represents a substantial advancement towards enabling efficient and effective end-to-end document understanding.
A Cross-Linguistic Pressure for Uniform Information Density in Word Order
Jun 06, 2023
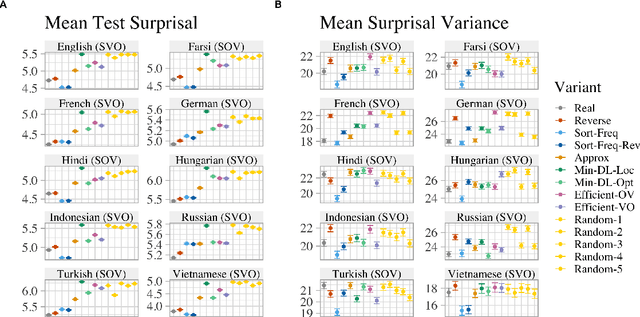

While natural languages differ widely in both canonical word order and word order flexibility, their word orders still follow shared cross-linguistic statistical patterns, often attributed to functional pressures. In the effort to identify these pressures, prior work has compared real and counterfactual word orders. Yet one functional pressure has been overlooked in such investigations: the uniform information density (UID) hypothesis, which holds that information should be spread evenly throughout an utterance. Here, we ask whether a pressure for UID may have influenced word order patterns cross-linguistically. To this end, we use computational models to test whether real orders lead to greater information uniformity than counterfactual orders. In our empirical study of 10 typologically diverse languages, we find that: (i) among SVO languages, real word orders consistently have greater uniformity than reverse word orders, and (ii) only linguistically implausible counterfactual orders consistently exceed the uniformity of real orders. These findings are compatible with a pressure for information uniformity in the development and usage of natural languages.
GujiBERT and GujiGPT: Construction of Intelligent Information Processing Foundation Language Models for Ancient Texts
Jul 11, 2023

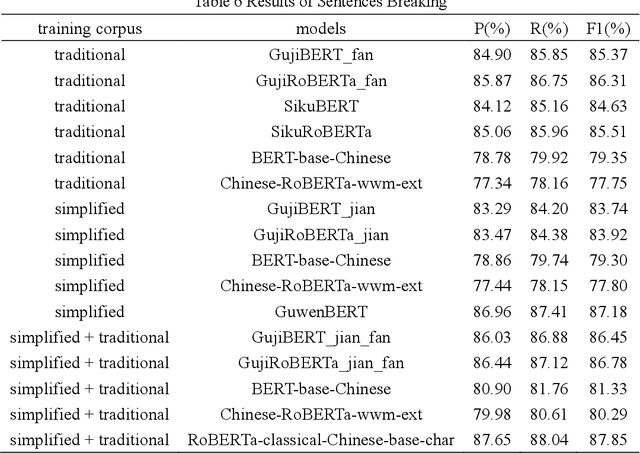
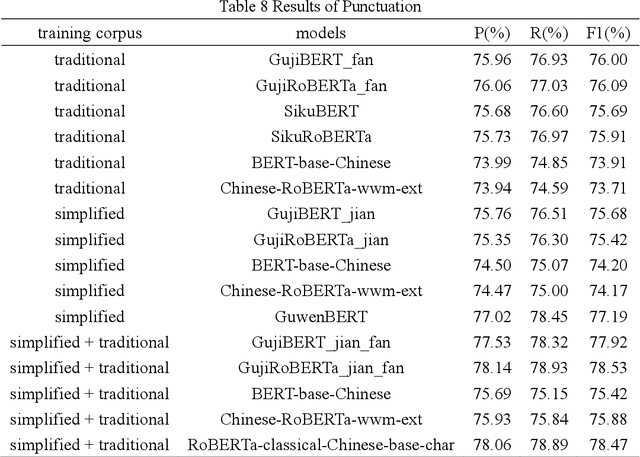
In the context of the rapid development of large language models, we have meticulously trained and introduced the GujiBERT and GujiGPT language models, which are foundational models specifically designed for intelligent information processing of ancient texts. These models have been trained on an extensive dataset that encompasses both simplified and traditional Chinese characters, allowing them to effectively handle various natural language processing tasks related to ancient books, including but not limited to automatic sentence segmentation, punctuation, word segmentation, part-of-speech tagging, entity recognition, and automatic translation. Notably, these models have exhibited exceptional performance across a range of validation tasks using publicly available datasets. Our research findings highlight the efficacy of employing self-supervised methods to further train the models using classical text corpora, thus enhancing their capability to tackle downstream tasks. Moreover, it is worth emphasizing that the choice of font, the scale of the corpus, and the initial model selection all exert significant influence over the ultimate experimental outcomes. To cater to the diverse text processing preferences of researchers in digital humanities and linguistics, we have developed three distinct categories comprising a total of nine model variations. We believe that by sharing these foundational language models specialized in the domain of ancient texts, we can facilitate the intelligent processing and scholarly exploration of ancient literary works and, consequently, contribute to the global dissemination of China's rich and esteemed traditional culture in this new era.
StreamMapNet: Streaming Mapping Network for Vectorized Online HD Map Construction
Aug 27, 2023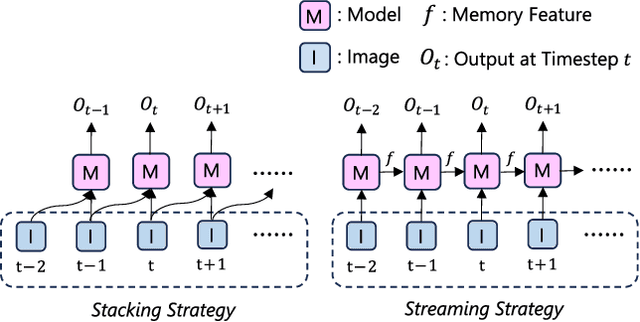
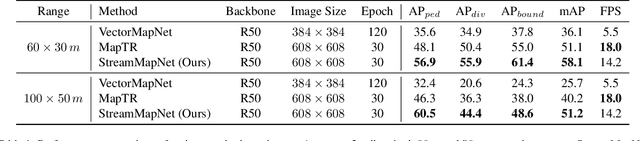
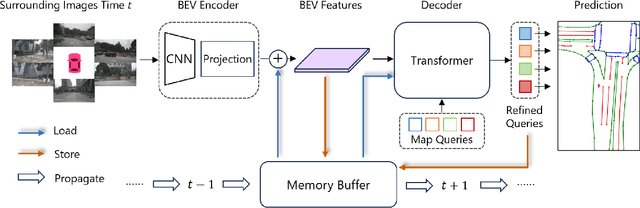
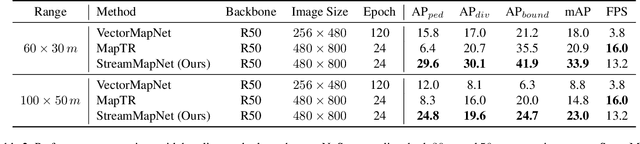
High-Definition (HD) maps are essential for the safety of autonomous driving systems. While existing techniques employ camera images and onboard sensors to generate vectorized high-precision maps, they are constrained by their reliance on single-frame input. This approach limits their stability and performance in complex scenarios such as occlusions, largely due to the absence of temporal information. Moreover, their performance diminishes when applied to broader perception ranges. In this paper, we present StreamMapNet, a novel online mapping pipeline adept at long-sequence temporal modeling of videos. StreamMapNet employs multi-point attention and temporal information which empowers the construction of large-range local HD maps with high stability and further addresses the limitations of existing methods. Furthermore, we critically examine widely used online HD Map construction benchmark and datasets, Argoverse2 and nuScenes, revealing significant bias in the existing evaluation protocols. We propose to resplit the benchmarks according to geographical spans, promoting fair and precise evaluations. Experimental results validate that StreamMapNet significantly outperforms existing methods across all settings while maintaining an online inference speed of $14.2$ FPS. Our code is available at https://github.com/yuantianyuan01/StreamMapNet.
"Would life be more interesting if I were in AI?" Answering Counterfactuals based on Probabilistic Inductive Logic Programming
Aug 30, 2023Probabilistic logic programs are logic programs where some facts hold with a specified probability. Here, we investigate these programs with a causal framework that allows counterfactual queries. Learning the program structure from observational data is usually done through heuristic search relying on statistical tests. However, these statistical tests lack information about the causal mechanism generating the data, which makes it unfeasible to use the resulting programs for counterfactual reasoning. To address this, we propose a language fragment that allows reconstructing a program from its induced distribution. This further enables us to learn programs supporting counterfactual queries.
* In Proceedings ICLP 2023, arXiv:2308.14898
Task-Based MoE for Multitask Multilingual Machine Translation
Aug 30, 2023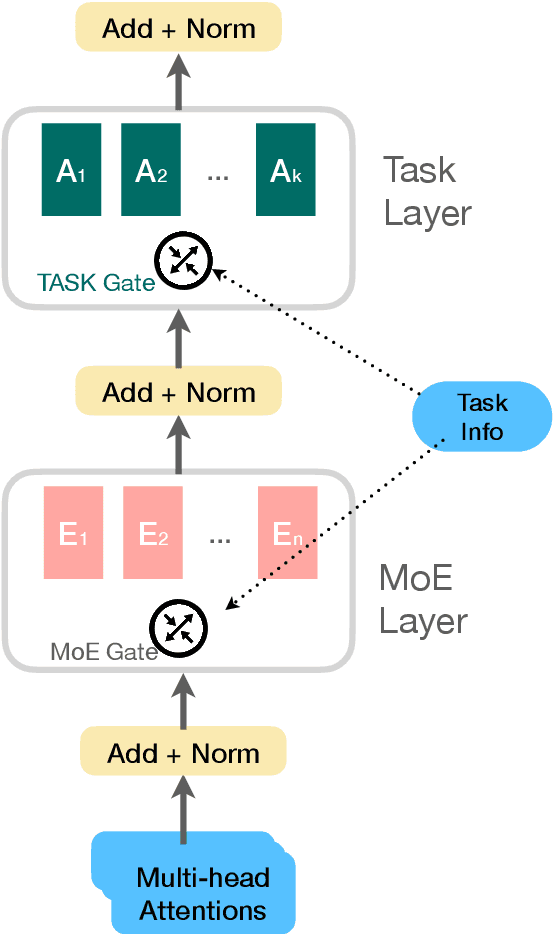
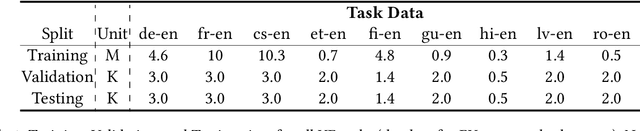
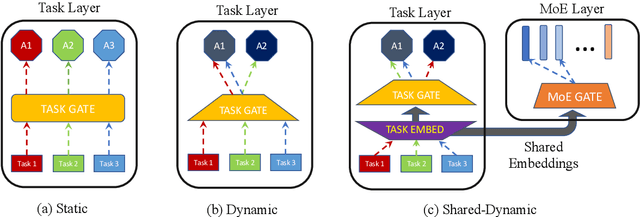
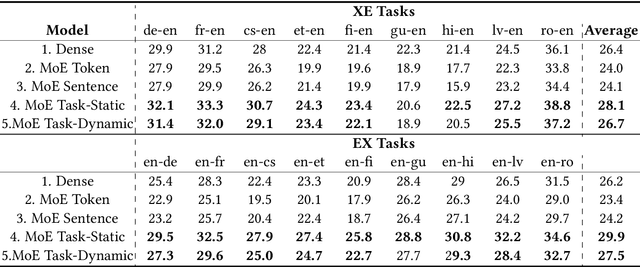
Mixture-of-experts (MoE) architecture has been proven a powerful method for diverse tasks in training deep models in many applications. However, current MoE implementations are task agnostic, treating all tokens from different tasks in the same manner. In this work, we instead design a novel method that incorporates task information into MoE models at different granular levels with shared dynamic task-based adapters. Our experiments and analysis show the advantages of our approaches over the dense and canonical MoE models on multi-task multilingual machine translations. With task-specific adapters, our models can additionally generalize to new tasks efficiently.
Residual-based attention and connection to information bottleneck theory in PINNs
Jul 01, 2023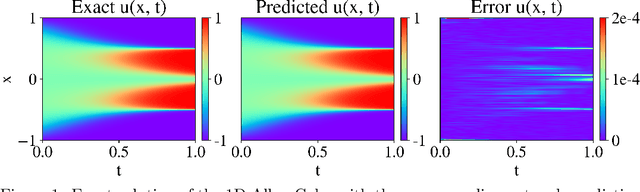
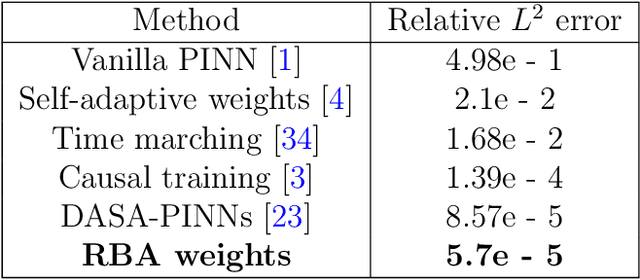
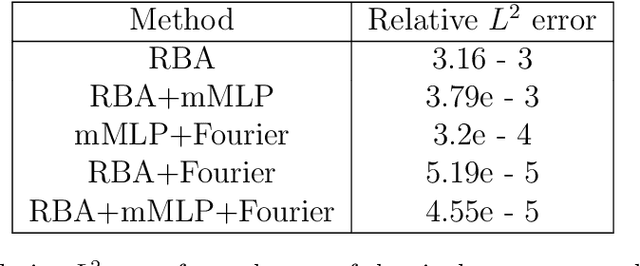
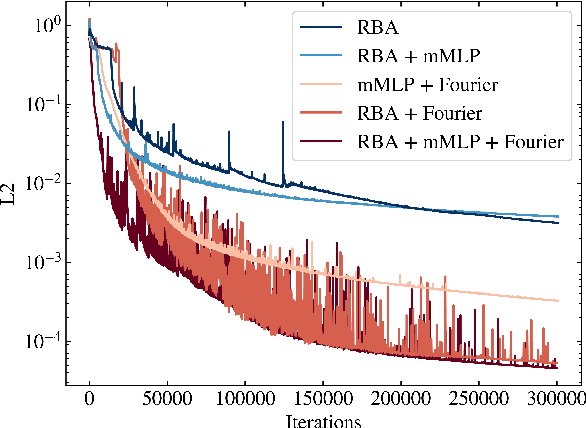
Driven by the need for more efficient and seamless integration of physical models and data, physics-informed neural networks (PINNs) have seen a surge of interest in recent years. However, ensuring the reliability of their convergence and accuracy remains a challenge. In this work, we propose an efficient, gradient-less weighting scheme for PINNs, that accelerates the convergence of dynamic or static systems. This simple yet effective attention mechanism is a function of the evolving cumulative residuals and aims to make the optimizer aware of problematic regions at no extra computational cost or adversarial learning. We illustrate that this general method consistently achieves a relative $L^{2}$ error of the order of $10^{-5}$ using standard optimizers on typical benchmark cases of the literature. Furthermore, by investigating the evolution of weights during training, we identify two distinct learning phases reminiscent of the fitting and diffusion phases proposed by the information bottleneck (IB) theory. Subsequent gradient analysis supports this hypothesis by aligning the transition from high to low signal-to-noise ratio (SNR) with the transition from fitting to diffusion regimes of the adopted weights. This novel correlation between PINNs and IB theory could open future possibilities for understanding the underlying mechanisms behind the training and stability of PINNs and, more broadly, of neural operators.
Learning Compact Compositional Embeddings via Regularized Pruning for Recommendation
Sep 08, 2023
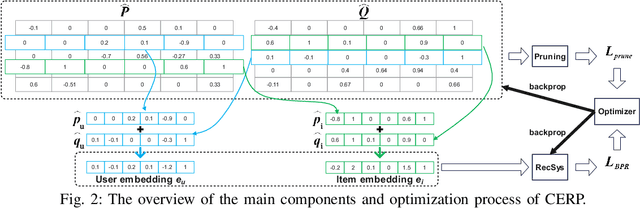
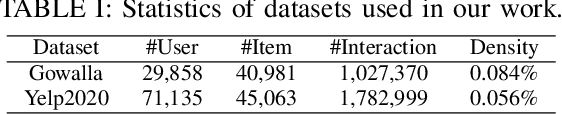
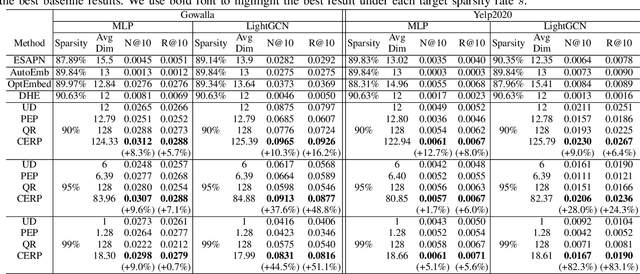
Latent factor models are the dominant backbones of contemporary recommender systems (RSs) given their performance advantages, where a unique vector embedding with a fixed dimensionality (e.g., 128) is required to represent each entity (commonly a user/item). Due to the large number of users and items on e-commerce sites, the embedding table is arguably the least memory-efficient component of RSs. For any lightweight recommender that aims to efficiently scale with the growing size of users/items or to remain applicable in resource-constrained settings, existing solutions either reduce the number of embeddings needed via hashing, or sparsify the full embedding table to switch off selected embedding dimensions. However, as hash collision arises or embeddings become overly sparse, especially when adapting to a tighter memory budget, those lightweight recommenders inevitably have to compromise their accuracy. To this end, we propose a novel compact embedding framework for RSs, namely Compositional Embedding with Regularized Pruning (CERP). Specifically, CERP represents each entity by combining a pair of embeddings from two independent, substantially smaller meta-embedding tables, which are then jointly pruned via a learnable element-wise threshold. In addition, we innovatively design a regularized pruning mechanism in CERP, such that the two sparsified meta-embedding tables are encouraged to encode information that is mutually complementary. Given the compatibility with agnostic latent factor models, we pair CERP with two popular recommendation models for extensive experiments, where results on two real-world datasets under different memory budgets demonstrate its superiority against state-of-the-art baselines. The codebase of CERP is available in https://github.com/xurong-liang/CERP.
Stereo Matching in Time: 100+ FPS Video Stereo Matching for Extended Reality
Sep 08, 2023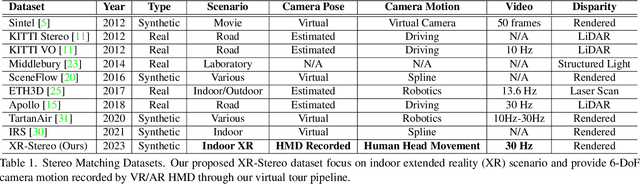
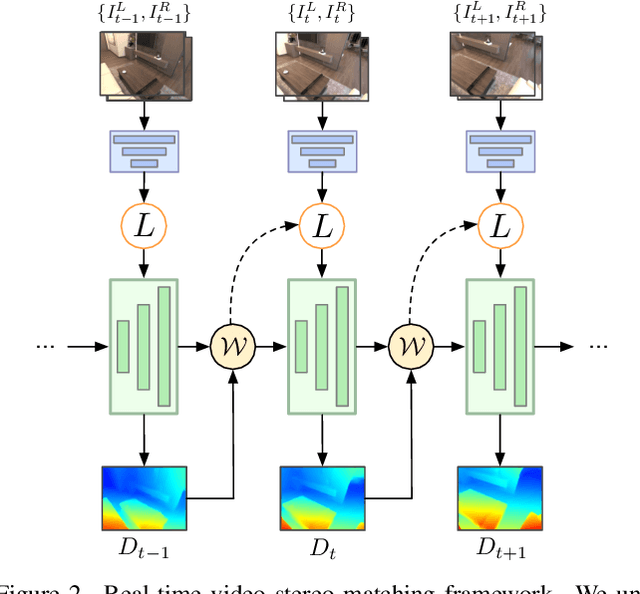
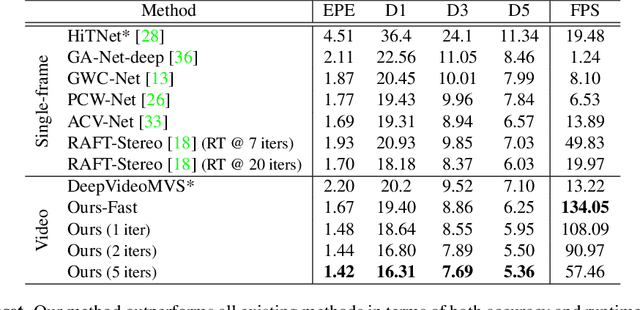
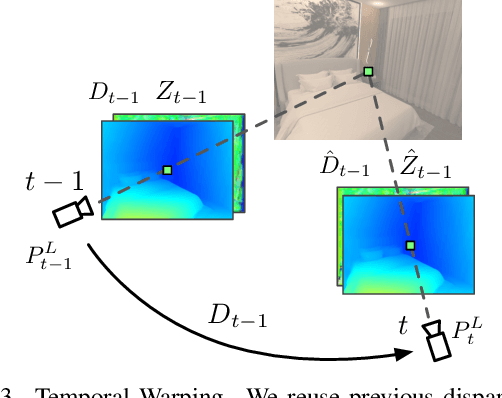
Real-time Stereo Matching is a cornerstone algorithm for many Extended Reality (XR) applications, such as indoor 3D understanding, video pass-through, and mixed-reality games. Despite significant advancements in deep stereo methods, achieving real-time depth inference with high accuracy on a low-power device remains a major challenge. One of the major difficulties is the lack of high-quality indoor video stereo training datasets captured by head-mounted VR/AR glasses. To address this issue, we introduce a novel video stereo synthetic dataset that comprises photorealistic renderings of various indoor scenes and realistic camera motion captured by a 6-DoF moving VR/AR head-mounted display (HMD). This facilitates the evaluation of existing approaches and promotes further research on indoor augmented reality scenarios. Our newly proposed dataset enables us to develop a novel framework for continuous video-rate stereo matching. As another contribution, our dataset enables us to proposed a new video-based stereo matching approach tailored for XR applications, which achieves real-time inference at an impressive 134fps on a standard desktop computer, or 30fps on a battery-powered HMD. Our key insight is that disparity and contextual information are highly correlated and redundant between consecutive stereo frames. By unrolling an iterative cost aggregation in time (i.e. in the temporal dimension), we are able to distribute and reuse the aggregated features over time. This approach leads to a substantial reduction in computation without sacrificing accuracy. We conducted extensive evaluations and comparisons and demonstrated that our method achieves superior performance compared to the current state-of-the-art, making it a strong contender for real-time stereo matching in VR/AR applications.
Vote2Cap-DETR++: Decoupling Localization and Describing for End-to-End 3D Dense Captioning
Sep 06, 2023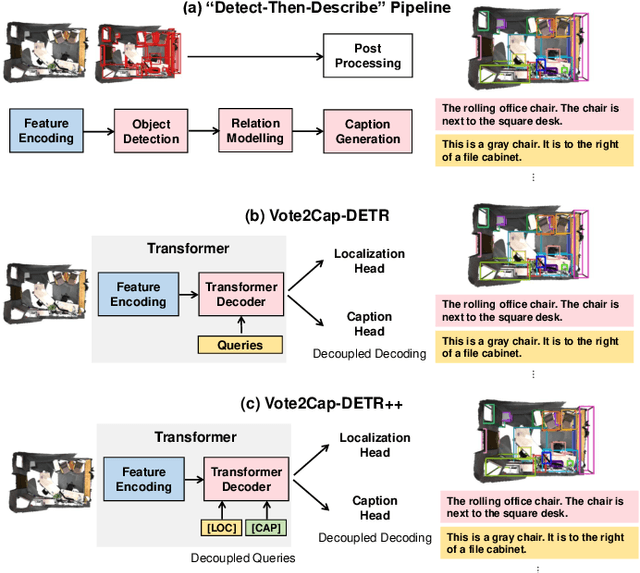
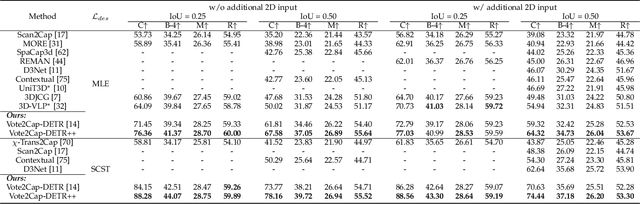
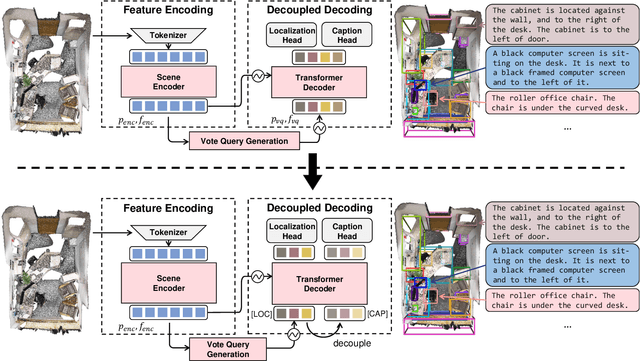
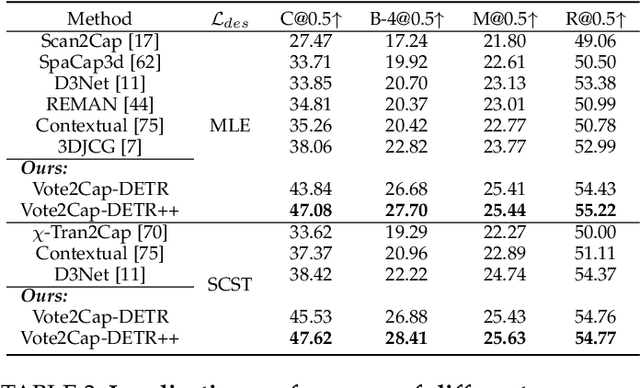
3D dense captioning requires a model to translate its understanding of an input 3D scene into several captions associated with different object regions. Existing methods adopt a sophisticated "detect-then-describe" pipeline, which builds explicit relation modules upon a 3D detector with numerous hand-crafted components. While these methods have achieved initial success, the cascade pipeline tends to accumulate errors because of duplicated and inaccurate box estimations and messy 3D scenes. In this paper, we first propose Vote2Cap-DETR, a simple-yet-effective transformer framework that decouples the decoding process of caption generation and object localization through parallel decoding. Moreover, we argue that object localization and description generation require different levels of scene understanding, which could be challenging for a shared set of queries to capture. To this end, we propose an advanced version, Vote2Cap-DETR++, which decouples the queries into localization and caption queries to capture task-specific features. Additionally, we introduce the iterative spatial refinement strategy to vote queries for faster convergence and better localization performance. We also insert additional spatial information to the caption head for more accurate descriptions. Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate Vote2Cap-DETR and Vote2Cap-DETR++ surpass conventional "detect-then-describe" methods by a large margin. Codes will be made available at https://github.com/ch3cook-fdu/Vote2Cap-DETR.