 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICH-Qwen: A Large Language Model Towards Chinese Intangible Cultural Heritage
May 28, 2025



The intangible cultural heritage (ICH) of China, a cultural asset transmitted across generations by various ethnic groups, serves as a significant testament to the evolution of human civilization and holds irreplaceable value for the preservation of historical lineage and the enhancement of cultural self-confidence. However, the rapid pace of modernization poses formidable challenges to ICH, including threats damage, disappearance and discontinuity of inheritance. China has the highest number of items on the UNESCO Intangible Cultural Heritage List, which is indicative of the nation's abundant cultural resources and emphasises the pressing need for ICH preservation. In recent years, the rapid advancements in large language modelling have provided a novel technological approach for the preservation and dissemination of ICH. This study utilises a substantial corpus of open-source Chinese ICH data to develop a large language model, ICH-Qwen, for the ICH domain. The model employs natural language understanding and knowledge reasoning capabilities of large language models, augmented with synthetic data and fine-tuning techniques. The experimental results demonstrate the efficacy of ICH-Qwen in executing tasks specific to the ICH domain. It is anticipated that the model will provide intelligent solutions for the protection, inheritance and dissemination of intangible cultural heritage, as well as new theoretical and practical references for the sustainable development of intangible cultural heritage. Furthermore, it is expected that the study will open up new paths for digital humanities research.
Fusing Bidirectional Chains of Thought and Reward Mechanisms A Method for Enhancing Question-Answering Capabilities of Large Language Models for Chinese Intangible Cultural Heritage
May 14, 2025



The rapid development of large language models (LLMs) has provided significant support and opportunities for the advancement of domain-specific LLMs. However, fine-tuning these large models using Intangible Cultural Heritage (ICH) data inevitably faces challenges such as bias, incorrect knowledge inheritance, and catastrophic forgetting. To address these issues, we propose a novel training method that integrates a bidirectional chains of thought and a reward mechanism. This method is built upon ICH-Qwen, a large language model specifically designed for the field of intangible cultural heritage. The proposed method enables the model to not only perform forward reasoning but also enhances the accuracy of the generated answers by utilizing reverse questioning and reverse reasoning to activate the model's latent knowledge. Additionally, a reward mechanism is introduced during training to optimize the decision-making process. This mechanism improves the quality of the model's outputs through structural and content evaluations with different weighting schemes. We conduct comparative experiments on ICH-Qwen, with results demonstrating that our method outperforms 0-shot, step-by-step reasoning, knowledge distillation, and question augmentation methods in terms of accuracy, Bleu-4, and Rouge-L scores on the question-answering task. Furthermore, the paper highlights the effectiveness of combining the bidirectional chains of thought and reward mechanism through ablation experiments. In addition, a series of generalizability experiments are conducted, with results showing that the proposed method yields improvements on various domain-specific datasets and advanced models in areas such as Finance, Wikidata, and StrategyQA. This demonstrates that the method is adaptable to multiple domains and provides a valuable approach for model training in future applications across diverse fields.
GujiBERT and GujiGPT: Construction of Intelligent Information Processing Foundation Language Models for Ancient Texts
Jul 11, 2023



In the context of the rapid development of large language models, we have meticulously trained and introduced the GujiBERT and GujiGPT language models, which are foundational models specifically designed for intelligent information processing of ancient texts. These models have been trained on an extensive dataset that encompasses both simplified and traditional Chinese characters, allowing them to effectively handle various natural language processing tasks related to ancient books, including but not limited to automatic sentence segmentation, punctuation, word segmentation, part-of-speech tagging, entity recognition, and automatic translation. Notably, these models have exhibited exceptional performance across a range of validation tasks using publicly available datasets. Our research findings highlight the efficacy of employing self-supervised methods to further train the models using classical text corpora, thus enhancing their capability to tackle downstream tasks. Moreover, it is worth emphasizing that the choice of font, the scale of the corpus, and the initial model selection all exert significant influence over the ultimate experimental outcomes. To cater to the diverse text processing preferences of researchers in digital humanities and linguistics, we have developed three distinct categories comprising a total of nine model variations. We believe that by sharing these foundational language models specialized in the domain of ancient texts, we can facilitate the intelligent processing and scholarly exploration of ancient literary works and, consequently, contribute to the global dissemination of China's rich and esteemed traditional culture in this new era.
SsciBERT: A Pre-trained Language Model for Social Science Texts
Jun 11, 2022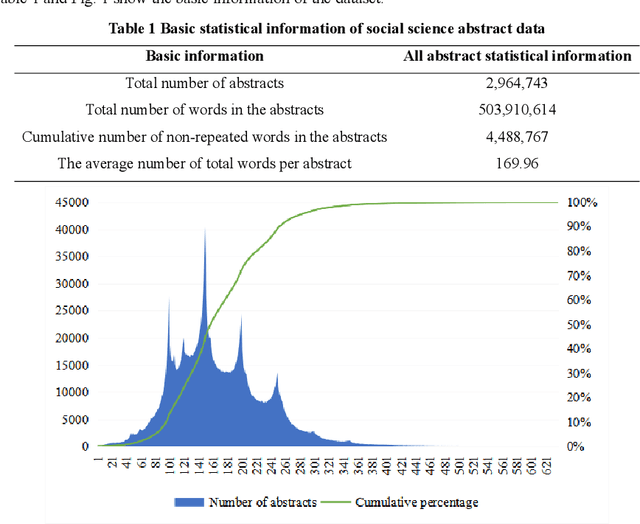
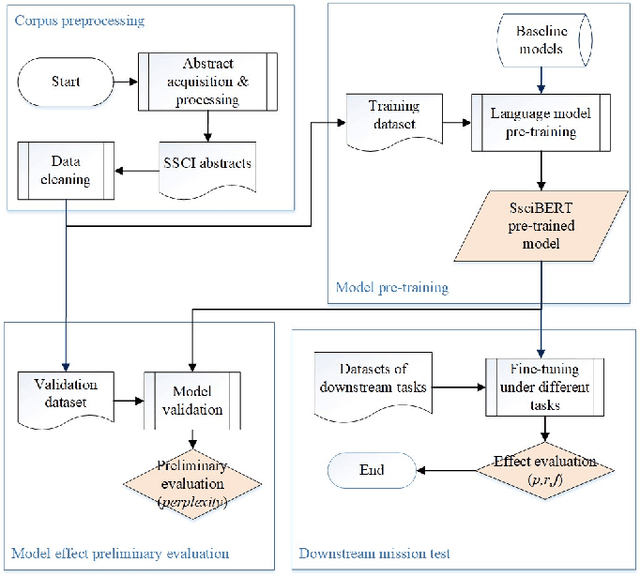

The academic literature of social sciences is the literature that records human civilization and studies human social problems. With the large-scale growth of this literature, ways to quickly find existing research on relevant issues have become an urgent demand for researchers. Previous studies, such as SciBERT, have shown that pre-training using domain-specific texts can improve the performance of natural language processing tasks in those fields. However, there is no pre-trained language model for social sciences, so this paper proposes a pre-trained model on many abstracts published in the Social Science Citation Index (SSCI) journals. The models, which are available on Github (https://github.com/S-T-Full-Text-Knowledge-Mining/SSCI-BERT), show excellent performance on discipline classification and abstract structure-function recognition tasks with the social sciences literature.