 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Bottlenecks: Scalable Diffusion Models for 3D Molecular Generation
Jan 13, 2026Diffusion models have emerged as a powerful class of generative models for molecular design, capable of capturing complex structural distributions and achieving high fidelity in 3D molecule generation. However, their widespread use remains constrained by long sampling trajectories, stochastic variance in the reverse process, and limited structural awareness in denoising dynamics. The Directly Denoising Diffusion Model (DDDM) mitigates these inefficiencies by replacing stochastic reverse MCMC updates with deterministic denoising step, substantially reducing inference time. Yet, the theoretical underpinnings of such deterministic updates have remained opaque. In this work, we provide a principled reinterpretation of DDDM through the lens of the Reverse Transition Kernel (RTK) framework by Huang et al. 2024, unifying deterministic and stochastic diffusion under a shared probabilistic formalism. By expressing the DDDM reverse process as an approximate kernel operator, we show that the direct denoising process implicitly optimizes a structured transport map between noisy and clean samples. This perspective elucidates why deterministic denoising achieves efficient inference. Beyond theoretical clarity, this reframing resolves several long-standing bottlenecks in molecular diffusion. The RTK view ensures numerical stability by enforcing well-conditioned reverse kernels, improves sample consistency by eliminating stochastic variance, and enables scalable and symmetry-preserving denoisers that respect SE(3) equivariance. Empirically, we demonstrate that RTK-guided deterministic denoising achieves faster convergence and higher structural fidelity than stochastic diffusion models, while preserving chemical validity across GEOM-DRUGS dataset. Code, models, and datasets are publicly available in our project repository.
Pharmacophore-Conditioned Diffusion Model for Ligand-Based De Novo Drug Design
May 15, 2025



Developing bioactive molecules remains a central, time- and cost-heavy challenge in drug discovery, particularly for novel targets lacking structural or functional data. Pharmacophore modeling presents an alternative for capturing the key features required for molecular bioactivity against a biological target. In this work, we present PharmaDiff, a pharmacophore-conditioned diffusion model for 3D molecular generation. PharmaDiff employs a transformer-based architecture to integrate an atom-based representation of the 3D pharmacophore into the generative process, enabling the precise generation of 3D molecular graphs that align with predefined pharmacophore hypotheses. Through comprehensive testing, PharmaDiff demonstrates superior performance in matching 3D pharmacophore constraints compared to ligand-based drug design methods. Additionally, it achieves higher docking scores across a range of proteins in structure-based drug design, without the need for target protein structures. By integrating pharmacophore modeling with 3D generative techniques, PharmaDiff offers a powerful and flexible framework for rational drug design.
Diffusion Models in $\textit{De Novo}$ Drug Design
Jun 07, 2024



Diffusion models have emerged as powerful tools for molecular generation, particularly in the context of 3D molecular structures. Inspired by non-equilibrium statistical physics, these models can generate 3D molecular structures with specific properties or requirements crucial to drug discovery. Diffusion models were particularly successful at learning 3D molecular geometries' complex probability distributions and their corresponding chemical and physical properties through forward and reverse diffusion processes. This review focuses on the technical implementation of diffusion models tailored for 3D molecular generation. It compares the performance, evaluation methods, and implementation details of various diffusion models used for molecular generation tasks. We cover strategies for atom and bond representation, architectures of reverse diffusion denoising networks, and challenges associated with generating stable 3D molecular structures. This review also explores the applications of diffusion models in $\textit{de novo}$ drug design and related areas of computational chemistry, such as structure-based drug design, including target-specific molecular generation, molecular docking, and molecular dynamics of protein-ligand complexes. We also cover conditional generation on physical properties, conformation generation, and fragment-based drug design. By summarizing the state-of-the-art diffusion models for 3D molecular generation, this review sheds light on their role in advancing drug discovery as well as their current limitations.
Controllable Text Generation in the Instruction-Tuning Era
May 02, 2024While most research on controllable text generation has focused on steering base Language Models, the emerging instruction-tuning and prompting paradigm offers an alternate approach to controllability. We compile and release ConGenBench, a testbed of 17 different controllable generation tasks, using a subset of it to benchmark the performance of 9 different baselines and methods on Instruction-tuned Language Models. To our surprise, we find that prompting-based approaches outperform controllable text generation methods on most datasets and tasks, highlighting a need for research on controllable text generation with Instruction-tuned Language Models in specific. Prompt-based approaches match human performance on most stylistic tasks while lagging on structural tasks, foregrounding a need to study more varied constraints and more challenging stylistic tasks. To facilitate such research, we provide an algorithm that uses only a task dataset and a Large Language Model with in-context capabilities to automatically generate a constraint dataset. This method eliminates the fields dependence on pre-curated constraint datasets, hence vastly expanding the range of constraints that can be studied in the future.
Task-Based MoE for Multitask Multilingual Machine Translation
Sep 11, 2023Mixture-of-experts (MoE) architecture has been proven a powerful method for diverse tasks in training deep models in many applications. However, current MoE implementations are task agnostic, treating all tokens from different tasks in the same manner. In this work, we instead design a novel method that incorporates task information into MoE models at different granular levels with shared dynamic task-based adapters. Our experiments and analysis show the advantages of our approaches over the dense and canonical MoE models on multi-task multilingual machine translations. With task-specific adapters, our models can additionally generalize to new tasks efficiently.
Objective-Agnostic Enhancement of Molecule Properties via Multi-Stage VAE
Sep 10, 2023Variational autoencoder (VAE) is a popular method for drug discovery and various architectures and pipelines have been proposed to improve its performance. However, VAE approaches are known to suffer from poor manifold recovery when the data lie on a low-dimensional manifold embedded in a higher dimensional ambient space [Dai and Wipf, 2019]. The consequences of it in drug discovery are somewhat under-explored. In this paper, we explore applying a multi-stage VAE approach, that can improve manifold recovery on a synthetic dataset, to the field of drug discovery. We experimentally evaluate our multi-stage VAE approach using the ChEMBL dataset and demonstrate its ability to improve the property statistics of generated molecules substantially from pre-existing methods without incorporating property predictors into the training pipeline. We further fine-tune our models on two curated and much smaller molecule datasets that target different proteins. Our experiments show an increase in the number of active molecules generated by the multi-stage VAE in comparison to their one-stage equivalent. For each of the two tasks, our baselines include methods that use learned property predictors to incorporate target metrics directly into the training objective and we discuss complications that arise with this methodology.
Improving Molecule Properties Through 2-Stage VAE
Dec 06, 2022


Variational autoencoder (VAE) is a popular method for drug discovery and there had been a great deal of architectures and pipelines proposed to improve its performance. But the VAE model itself suffers from deficiencies such as poor manifold recovery when data lie on low-dimensional manifold embedded in higher dimensional ambient space and they manifest themselves in each applications differently. The consequences of it in drug discovery is somewhat under-explored. In this paper, we study how to improve the similarity of the data generated via VAE and the training dataset by improving manifold recovery via a 2-stage VAE where the second stage VAE is trained on the latent space of the first one. We experimentally evaluated our approach using the ChEMBL dataset as well as a polymer datasets. In both dataset, the 2-stage VAE method is able to improve the property statistics significantly from a pre-existing method.
Modeling Task Effects on Meaning Representation in the Brain via Zero-Shot MEG Prediction
Sep 17, 2020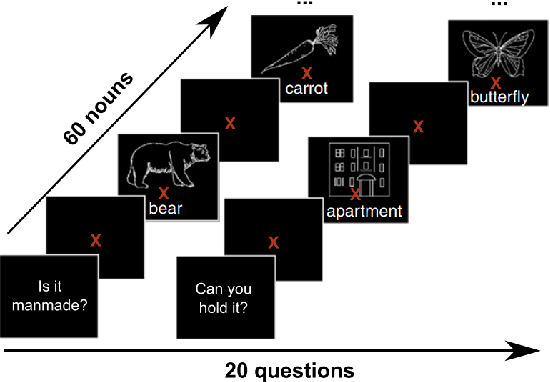

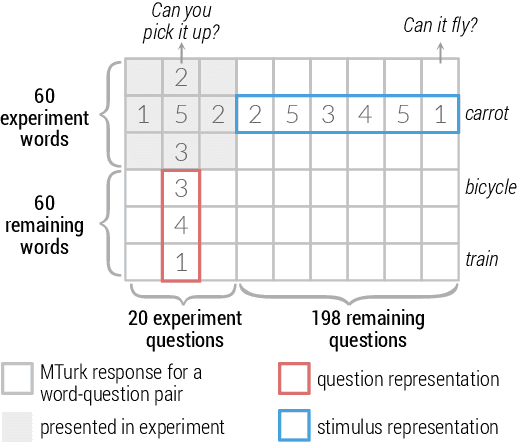
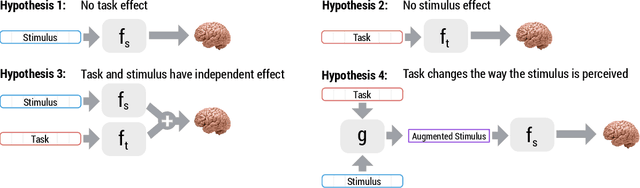
How meaning is represented in the brain is still one of the big open questions in neuroscience. Does a word (e.g., bird) always have the same representation, or does the task under which the word is processed alter its representation (answering "can you eat it?" versus "can it fly?")? The brain activity of subjects who read the same word while performing different semantic tasks has been shown to differ across tasks. However, it is still not understood how the task itself contributes to this difference. In the current work, we study Magnetoencephalography (MEG) brain recordings of participants tasked with answering questions about concrete nouns. We investigate the effect of the task (i.e. the question being asked) on the processing of the concrete noun by predicting the millisecond-resolution MEG recordings as a function of both the semantics of the noun and the task. Using this approach, we test several hypotheses about the task-stimulus interactions by comparing the zero-shot predictions made by these hypotheses for novel tasks and nouns not seen during training. We find that incorporating the task semantics significantly improves the prediction of MEG recordings, across participants. The improvement occurs 475-550ms after the participants first see the word, which corresponds to what is considered to be the ending time of semantic processing for a word. These results suggest that only the end of semantic processing of a word is task-dependent, and pose a challenge for future research to formulate new hypotheses for earlier task effects as a function of the task and stimuli.
Robust Handwriting Recognition with Limited and Noisy Data
Aug 18, 2020

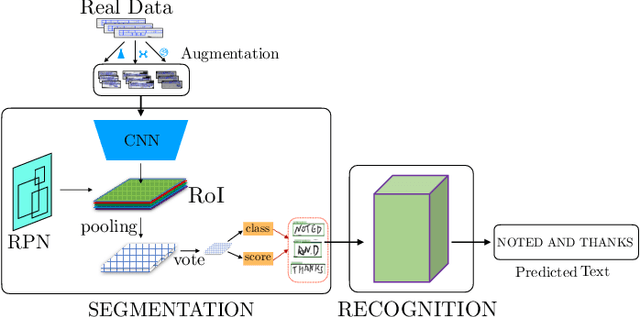
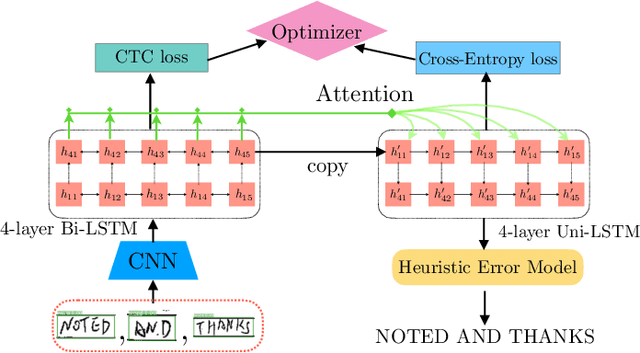
Despite the advent of deep learning in computer vision, the general handwriting recognition problem is far from solved. Most existing approaches focus on handwriting datasets that have clearly written text and carefully segmented labels. In this paper, we instead focus on learning handwritten characters from maintenance logs, a constrained setting where data is very limited and noisy. We break the problem into two consecutive stages of word segmentation and word recognition respectively and utilize data augmentation techniques to train both stages. Extensive comparisons with popular baselines for scene-text detection and word recognition show that our system achieves a lower error rate and is more suited to handle noisy and difficult documents
Nonlinear ISA with Auxiliary Variables for Learning Speech Representations
Jul 25, 2020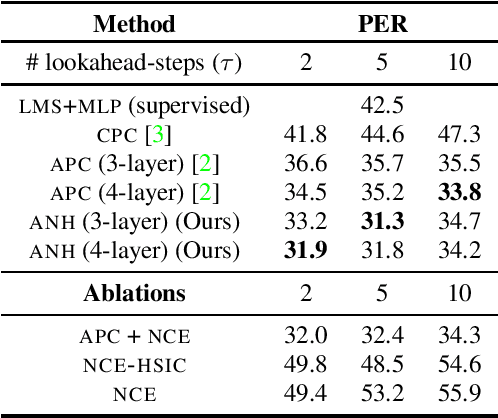
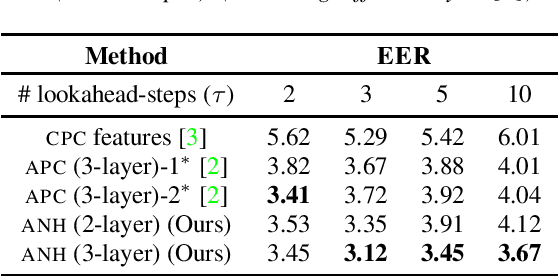
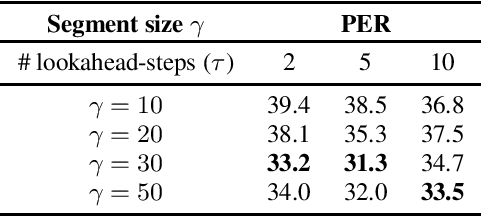
This paper extends recent work on nonlinear Independent Component Analysis (ICA) by introducing a theoretical framework for nonlinear Independent Subspace Analysis (ISA) in the presence of auxiliary variables. Observed high dimensional acoustic features like log Mel spectrograms can be considered as surface level manifestations of nonlinear transformations over individual multivariate sources of information like speaker characteristics, phonological content etc. Under assumptions of energy based models we use the theory of nonlinear ISA to propose an algorithm that learns unsupervised speech representations whose subspaces are independent and potentially highly correlated with the original non-stationary multivariate sources. We show how nonlinear ICA with auxiliary variables can be extended to a generic identifiable model for subspaces as well while also providing sufficient conditions for the identifiability of these high dimensional subspaces. Our proposed methodology is generic and can be integrated with standard unsupervised approaches to learn speech representations with subspaces that can theoretically capture independent higher order speech signals. We evaluate the gains of our algorithm when integrated with the Autoregressive Predictive Decoding (APC) model by showing empirical results on the speaker verification and phoneme recognition tasks.