 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation as a Bridging Action: Transferring Manipulation Skills from Humans to Robots
Jun 26, 2026We study whether we can learn novel manipulation skills from human actions to a bi-manual robot with parallel grippers. Human action data is cheap, abundant, and diverse, making it one of the most promising resources for scaling up robot learning. Yet transferring skills from humans to robots remains hard: most prior work treats humans as just another bi-manual 6DoF embodiment, where hand-pose estimates are noisy and the contact patterns of human fingers differ fundamentally from those of a parallel gripper. We argue that learning rotation-inclusive action signals from human data is therefore sub-optimal, and instead propose a bridging action representation: the relative wrist translation within the initial head-camera frame, an action space shared by humans and robots. To handle the potential absence of certain action components in different embodiments, we build a $π_0$-like vision-language-action model with interleaved action tokens and attention masking. On a suite of novel bi-manual manipulation tasks, our bridging action transfers human manipulation knowledge to robots far more effectively than noisy 6DoF human actions and scales with the amount of human data.
TTT-VLA: Test-Time Latent Prompt Optimization for Vision-Language-Action Models
Jun 02, 2026Vision-Language-Action (VLA) models trained on large-scale data have made remarkable progress, but they remain vulnerable to distribution shifts at deployment time. Recent VLA models suggest that prompts can serve as an efficient interface for steering policy behavior, but existing prompt-based steering typically relies on external guidance. This raises a natural question: can test-time training (TTT) for VLA be achieved by optimizing a prompt, so that the steering interface itself can be learned and adapted from interaction? We address this question with TTT-VLA, a test-time training framework based on Latent Prompt Optimization (LPO). During training, the latent prompt is learned with an additional proxy task, providing an extra learned conditioning signal for policy learning. At test time, TTT is performed by collecting interaction data from the current environment and optimizing only the latent prompt on those data using the proxy task's self-supervised signal, without modifying the policy itself. Experiments on SimplerEnv demonstrate that the proposed method consistently improves task success rates in both single- and multi-embodiment settings. Further analysis shows that the gains arise primarily from correcting a small number of critical decisions rather than globally altering policy behavior. These results suggest that LPO provides an effective and practical pathway for deployment-time improvement of foundation manipulation policies.
OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
Mar 02, 2026OmniLottie is a versatile framework that generates high quality vector animations from multi-modal instructions. For flexible motion and visual content control, we focus on Lottie, a light weight JSON formatting for both shapes and animation behaviors representation. However, the raw Lottie JSON files contain extensive invariant structural metadata and formatting tokens, posing significant challenges for learning vector animation generation. Therefore, we introduce a well designed Lottie tokenizer that transforms JSON files into structured sequences of commands and parameters representing shapes, animation functions and control parameters. Such tokenizer enables us to build OmniLottie upon pretrained vision language models to follow multi-modal interleaved instructions and generate high quality vector animations. To further advance research in vector animation generation, we curate MMLottie-2M, a large scale dataset of professionally designed vector animations paired with textual and visual annotations. With extensive experiments, we validate that OmniLottie can produce vivid and semantically aligned vector animations that adhere closely to multi modal human instructions.
World Guidance: World Modeling in Condition Space for Action Generation
Feb 25, 2026Leveraging future observation modeling to facilitate action generation presents a promising avenue for enhancing the capabilities of Vision-Language-Action (VLA) models. However, existing approaches struggle to strike a balance between maintaining efficient, predictable future representations and preserving sufficient fine-grained information to guide precise action generation. To address this limitation, we propose WoG (World Guidance), a framework that maps future observations into compact conditions by injecting them into the action inference pipeline. The VLA is then trained to simultaneously predict these compressed conditions alongside future actions, thereby achieving effective world modeling within the condition space for action inference. We demonstrate that modeling and predicting this condition space not only facilitates fine-grained action generation but also exhibits superior generalization capabilities. Moreover, it learns effectively from substantial human manipulation videos. Extensive experiments across both simulation and real-world environments validate that our method significantly outperforms existing methods based on future prediction. Project page is available at: https://selen-suyue.github.io/WoGNet/
DSPv2: Improved Dense Policy for Effective and Generalizable Whole-body Mobile Manipulation
Sep 19, 2025Learning whole-body mobile manipulation via imitation is essential for generalizing robotic skills to diverse environments and complex tasks. However, this goal is hindered by significant challenges, particularly in effectively processing complex observation, achieving robust generalization, and generating coherent actions. To address these issues, we propose DSPv2, a novel policy architecture. DSPv2 introduces an effective encoding scheme that aligns 3D spatial features with multi-view 2D semantic features. This fusion enables the policy to achieve broad generalization while retaining the fine-grained perception necessary for precise control. Furthermore, we extend the Dense Policy paradigm to the whole-body mobile manipulation domain, demonstrating its effectiveness in generating coherent and precise actions for the whole-body robotic platform. Extensive experiments show that our method significantly outperforms existing approaches in both task performance and generalization ability. Project page is available at: https://selen-suyue.github.io/DSPv2Net/.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
Apr 08, 2025
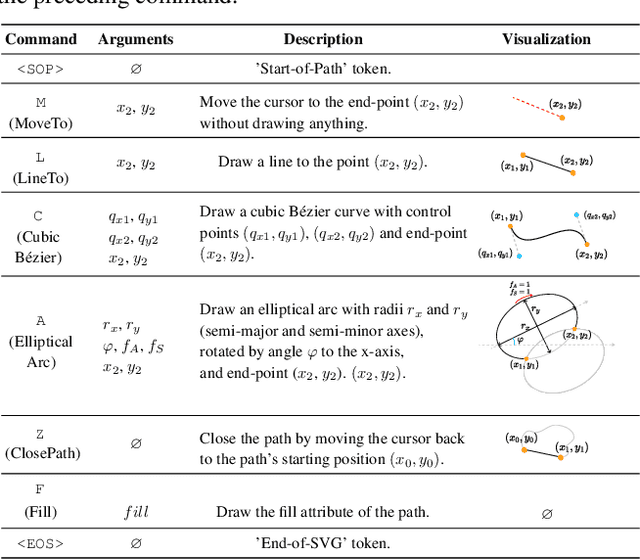


Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.
Decoding Game: On Minimax Optimality of Heuristic Text Generation Strategies
Oct 04, 2024


Decoding strategies play a pivotal role in text generation for modern language models, yet a puzzling gap divides theory and practice. Surprisingly, strategies that should intuitively be optimal, such as Maximum a Posteriori (MAP), often perform poorly in practice. Meanwhile, popular heuristic approaches like Top-$k$ and Nucleus sampling, which employ truncation and normalization of the conditional next-token probabilities, have achieved great empirical success but lack theoretical justifications. In this paper, we propose Decoding Game, a comprehensive theoretical framework which reimagines text generation as a two-player zero-sum game between Strategist, who seeks to produce text credible in the true distribution, and Nature, who distorts the true distribution adversarially. After discussing the decomposibility of multi-step generation, we derive the optimal strategy in closed form for one-step Decoding Game. It is shown that the adversarial Nature imposes an implicit regularization on likelihood maximization, and truncation-normalization methods are first-order approximations to the optimal strategy under this regularization. Additionally, by generalizing the objective and parameters of Decoding Game, near-optimal strategies encompass diverse methods such as greedy search, temperature scaling, and hybrids thereof. Numerical experiments are conducted to complement our theoretical analysis.
Takin: A Cohort of Superior Quality Zero-shot Speech Generation Models
Sep 18, 2024



With the advent of the big data and large language model era, zero-shot personalized rapid customization has emerged as a significant trend. In this report, we introduce Takin AudioLLM, a series of techniques and models, mainly including Takin TTS, Takin VC, and Takin Morphing, specifically designed for audiobook production. These models are capable of zero-shot speech production, generating high-quality speech that is nearly indistinguishable from real human speech and facilitating individuals to customize the speech content according to their own needs. Specifically, we first introduce Takin TTS, a neural codec language model that builds upon an enhanced neural speech codec and a multi-task training framework, capable of generating high-fidelity natural speech in a zero-shot way. For Takin VC, we advocate an effective content and timbre joint modeling approach to improve the speaker similarity, while advocating for a conditional flow matching based decoder to further enhance its naturalness and expressiveness. Last, we propose the Takin Morphing system with highly decoupled and advanced timbre and prosody modeling approaches, which enables individuals to customize speech production with their preferred timbre and prosody in a precise and controllable manner. Extensive experiments validate the effectiveness and robustness of our Takin AudioLLM series models. For detailed demos, please refer to https://takinaudiollm.github.io.
MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
Jun 14, 2024



Recently, 3D assets created via reconstruction and generation have matched the quality of manually crafted assets, highlighting their potential for replacement. However, this potential is largely unrealized because these assets always need to be converted to meshes for 3D industry applications, and the meshes produced by current mesh extraction methods are significantly inferior to Artist-Created Meshes (AMs), i.e., meshes created by human artists. Specifically, current mesh extraction methods rely on dense faces and ignore geometric features, leading to inefficiencies, complicated post-processing, and lower representation quality. To address these issues, we introduce MeshAnything, a model that treats mesh extraction as a generation problem, producing AMs aligned with specified shapes. By converting 3D assets in any 3D representation into AMs, MeshAnything can be integrated with various 3D asset production methods, thereby enhancing their application across the 3D industry. The architecture of MeshAnything comprises a VQ-VAE and a shape-conditioned decoder-only transformer. We first learn a mesh vocabulary using the VQ-VAE, then train the shape-conditioned decoder-only transformer on this vocabulary for shape-conditioned autoregressive mesh generation. Our extensive experiments show that our method generates AMs with hundreds of times fewer faces, significantly improving storage, rendering, and simulation efficiencies, while achieving precision comparable to previous methods.
MeshXL: Neural Coordinate Field for Generative 3D Foundation Models
May 31, 2024



The polygon mesh representation of 3D data exhibits great flexibility, fast rendering speed, and storage efficiency, which is widely preferred in various applications. However, given its unstructured graph representation, the direct generation of high-fidelity 3D meshes is challenging. Fortunately, with a pre-defined ordering strategy, 3D meshes can be represented as sequences, and the generation process can be seamlessly treated as an auto-regressive problem. In this paper, we validate the Neural Coordinate Field (NeurCF), an explicit coordinate representation with implicit neural embeddings, is a simple-yet-effective representation for large-scale sequential mesh modeling. After that, we present MeshXL, a family of generative pre-trained auto-regressive models, which addresses the process of 3D mesh generation with modern large language model approaches. Extensive experiments show that MeshXL is able to generate high-quality 3D meshes, and can also serve as foundation models for various down-stream applications.