 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian Methods for Media Mix Modelling with shape and funnel effects
Nov 09, 2023
In recent years, significant progress in generative AI has highlighted the important role of physics-inspired models that utilize advanced mathematical concepts based on fundamental physics principles to enhance artificial intelligence capabilities. Among these models, those based on diffusion equations have greatly improved image quality. This study aims to explore the potential uses of Maxwell-Boltzmann equation, which forms the basis of the kinetic theory of gases, and the Michaelis-Menten model in Marketing Mix Modelling (MMM) applications. We propose incorporating these equations into Hierarchical Bayesian models to analyse consumer behaviour in the context of advertising. These equation sets excel in accurately describing the random dynamics in complex systems like social interactions and consumer-advertising interactions.
LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents
Nov 09, 2023LLaVA-Plus is a general-purpose multimodal assistant that expands the capabilities of large multimodal models. It maintains a skill repository of pre-trained vision and vision-language models and can activate relevant tools based on users' inputs to fulfill real-world tasks. LLaVA-Plus is trained on multimodal instruction-following data to acquire the ability to use tools, covering visual understanding, generation, external knowledge retrieval, and compositions. Empirical results show that LLaVA-Plus outperforms LLaVA in existing capabilities and exhibits new ones. It is distinct in that the image query is directly grounded and actively engaged throughout the entire human-AI interaction sessions, significantly improving tool use performance and enabling new scenarios.
Exploiting Image-Related Inductive Biases in Single-Branch Visual Tracking
Oct 30, 2023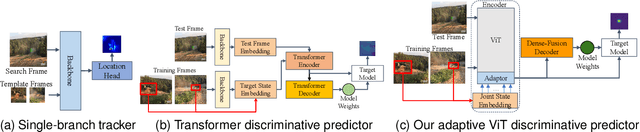
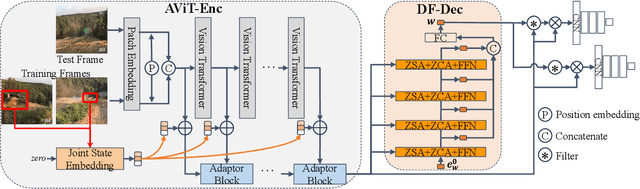

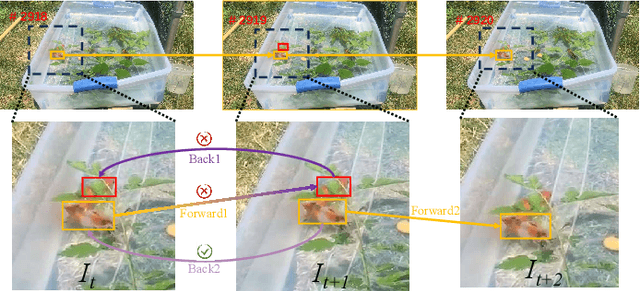
Despite achieving state-of-the-art performance in visual tracking, recent single-branch trackers tend to overlook the weak prior assumptions associated with the Vision Transformer (ViT) encoder and inference pipeline. Moreover, the effectiveness of discriminative trackers remains constrained due to the adoption of the dual-branch pipeline. To tackle the inferior effectiveness of the vanilla ViT, we propose an Adaptive ViT Model Prediction tracker (AViTMP) to bridge the gap between single-branch network and discriminative models. Specifically, in the proposed encoder AViT-Enc, we introduce an adaptor module and joint target state embedding to enrich the dense embedding paradigm based on ViT. Then, we combine AViT-Enc with a dense-fusion decoder and a discriminative target model to predict accurate location. Further, to mitigate the limitations of conventional inference practice, we present a novel inference pipeline called CycleTrack, which bolsters the tracking robustness in the presence of distractors via bidirectional cycle tracking verification. Lastly, we propose a dual-frame update inference strategy that adeptively handles significant challenges in long-term scenarios. In the experiments, we evaluate AViTMP on ten tracking benchmarks for a comprehensive assessment, including LaSOT, LaSOTExtSub, AVisT, etc. The experimental results unequivocally establish that AViTMP attains state-of-the-art performance, especially on long-time tracking and robustness.
A Perceptual Shape Loss for Monocular 3D Face Reconstruction
Oct 30, 2023Monocular 3D face reconstruction is a wide-spread topic, and existing approaches tackle the problem either through fast neural network inference or offline iterative reconstruction of face geometry. In either case carefully-designed energy functions are minimized, commonly including loss terms like a photometric loss, a landmark reprojection loss, and others. In this work we propose a new loss function for monocular face capture, inspired by how humans would perceive the quality of a 3D face reconstruction given a particular image. It is widely known that shading provides a strong indicator for 3D shape in the human visual system. As such, our new 'perceptual' shape loss aims to judge the quality of a 3D face estimate using only shading cues. Our loss is implemented as a discriminator-style neural network that takes an input face image and a shaded render of the geometry estimate, and then predicts a score that perceptually evaluates how well the shaded render matches the given image. This 'critic' network operates on the RGB image and geometry render alone, without requiring an estimate of the albedo or illumination in the scene. Furthermore, our loss operates entirely in image space and is thus agnostic to mesh topology. We show how our new perceptual shape loss can be combined with traditional energy terms for monocular 3D face optimization and deep neural network regression, improving upon current state-of-the-art results.
* Accepted to PG 2023. Project page: https://studios.disneyresearch.com/2023/10/09/a-perceptual-shape-loss-for-monocular-3d-face-reconstruction/ Video: https://www.youtube.com/watch?v=RYdyoIZEuUI
Impressions: Understanding Visual Semiotics and Aesthetic Impact
Oct 27, 2023Is aesthetic impact different from beauty? Is visual salience a reflection of its capacity for effective communication? We present Impressions, a novel dataset through which to investigate the semiotics of images, and how specific visual features and design choices can elicit specific emotions, thoughts and beliefs. We posit that the impactfulness of an image extends beyond formal definitions of aesthetics, to its success as a communicative act, where style contributes as much to meaning formation as the subject matter. However, prior image captioning datasets are not designed to empower state-of-the-art architectures to model potential human impressions or interpretations of images. To fill this gap, we design an annotation task heavily inspired by image analysis techniques in the Visual Arts to collect 1,440 image-caption pairs and 4,320 unique annotations exploring impact, pragmatic image description, impressions, and aesthetic design choices. We show that existing multimodal image captioning and conditional generation models struggle to simulate plausible human responses to images. However, this dataset significantly improves their ability to model impressions and aesthetic evaluations of images through fine-tuning and few-shot adaptation.
DUBLINE: A Deep Unfolding Network for B-line Detection in Lung Ultrasound Images
Nov 11, 2023In the context of lung ultrasound, the detection of B-lines, which are indicative of interstitial lung disease and pulmonary edema, plays a pivotal role in clinical diagnosis. Current methods still rely on visual inspection by experts. Vision-based automatic B-line detection methods have been developed, but their performance has yet to improve in terms of both accuracy and computational speed. This paper presents a novel approach to posing B-line detection as an inverse problem via deep unfolding of the Alternating Direction Method of Multipliers (ADMM). It tackles the challenges of data labelling and model training in lung ultrasound image analysis by harnessing the capabilities of deep neural networks and model-based methods. Our objective is to substantially enhance diagnostic accuracy while ensuring efficient real-time capabilities. The results show that the proposed method runs more than 90 times faster than the traditional model-based method and achieves an F1 score that is 10.6% higher.
Mixture-of-Experts for Open Set Domain Adaptation: A Dual-Space Detection Approach
Nov 01, 2023Open Set Domain Adaptation (OSDA) aims to cope with the distribution and label shifts between the source and target domains simultaneously, performing accurate classification for known classes while identifying unknown class samples in the target domain. Most existing OSDA approaches, depending on the final image feature space of deep models, require manually-tuned thresholds, and may easily misclassify unknown samples as known classes. Mixture-of-Expert (MoE) could be a remedy. Within an MoE, different experts address different input features, producing unique expert routing patterns for different classes in a routing feature space. As a result, unknown class samples may also display different expert routing patterns to known classes. This paper proposes Dual-Space Detection, which exploits the inconsistencies between the image feature space and the routing feature space to detect unknown class samples without any threshold. Graph Router is further introduced to better make use of the spatial information among image patches. Experiments on three different datasets validated the effectiveness and superiority of our approach. The code will come soon.
Machine Learning-Based Tea Leaf Disease Detection: A Comprehensive Review
Nov 06, 2023Tea leaf diseases are a major challenge to agricultural productivity, with far-reaching implications for yield and quality in the tea industry. The rise of machine learning has enabled the development of innovative approaches to combat these diseases. Early detection and diagnosis are crucial for effective crop management. For predicting tea leaf disease, several automated systems have already been developed using different image processing techniques. This paper delivers a systematic review of the literature on machine learning methodologies applied to diagnose tea leaf disease via image classification. It thoroughly evaluates the strengths and constraints of various Vision Transformer models, including Inception Convolutional Vision Transformer (ICVT), GreenViT, PlantXViT, PlantViT, MSCVT, Transfer Learning Model & Vision Transformer (TLMViT), IterationViT, IEM-ViT. Moreover, this paper also reviews models like Dense Convolutional Network (DenseNet), Residual Neural Network (ResNet)-50V2, YOLOv5, YOLOv7, Convolutional Neural Network (CNN), Deep CNN, Non-dominated Sorting Genetic Algorithm (NSGA-II), MobileNetv2, and Lesion-Aware Visual Transformer. These machine-learning models have been tested on various datasets, demonstrating their real-world applicability. This review study not only highlights current progress in the field but also provides valuable insights for future research directions in the machine learning-based detection and classification of tea leaf diseases.
SCAAT: Improving Neural Network Interpretability via Saliency Constrained Adaptive Adversarial Training
Nov 10, 2023Deep Neural Networks (DNNs) are expected to provide explanation for users to understand their black-box predictions. Saliency map is a common form of explanation illustrating the heatmap of feature attributions, but it suffers from noise in distinguishing important features. In this paper, we propose a model-agnostic learning method called Saliency Constrained Adaptive Adversarial Training (SCAAT) to improve the quality of such DNN interpretability. By constructing adversarial samples under the guidance of saliency map, SCAAT effectively eliminates most noise and makes saliency maps sparser and more faithful without any modification to the model architecture. We apply SCAAT to multiple DNNs and evaluate the quality of the generated saliency maps on various natural and pathological image datasets. Evaluations on different domains and metrics show that SCAAT significantly improves the interpretability of DNNs by providing more faithful saliency maps without sacrificing their predictive power.
Towards High-quality HDR Deghosting with Conditional Diffusion Models
Nov 02, 2023High Dynamic Range (HDR) images can be recovered from several Low Dynamic Range (LDR) images by existing Deep Neural Networks (DNNs) techniques. Despite the remarkable progress, DNN-based methods still generate ghosting artifacts when LDR images have saturation and large motion, which hinders potential applications in real-world scenarios. To address this challenge, we formulate the HDR deghosting problem as an image generation that leverages LDR features as the diffusion model's condition, consisting of the feature condition generator and the noise predictor. Feature condition generator employs attention and Domain Feature Alignment (DFA) layer to transform the intermediate features to avoid ghosting artifacts. With the learned features as conditions, the noise predictor leverages a stochastic iterative denoising process for diffusion models to generate an HDR image by steering the sampling process. Furthermore, to mitigate semantic confusion caused by the saturation problem of LDR images, we design a sliding window noise estimator to sample smooth noise in a patch-based manner. In addition, an image space loss is proposed to avoid the color distortion of the estimated HDR results. We empirically evaluate our model on benchmark datasets for HDR imaging. The results demonstrate that our approach achieves state-of-the-art performances and well generalization to real-world images.