 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAConformer: Frequency-Aware Convolutional Transformer for Auditory Attention Decoding
Jun 12, 2026Auditory attention decoding (AAD) aims to infer the attended speaker from neural responses in multi-speaker acoustic environments and is a key problem for neuro-steered hearing systems. Although recent studies have achieved encouraging progress, existing AAD models still do not fully exploit frequency domain electroencephalography (EEG) information. In particular, most approaches introduce multi-band information through handcrafted feature extraction or direct cross-band feature concatenation, which mainly exploit frequency information at a shallow level and may overlook band-specific patterns and cross-band interactions. To address these limitations, this paper proposes FAConformer, a frequency-aware CNN-Transformer framework for AAD that explicitly integrates band-specific encoding and adaptive cross-band interaction. Specifically, FAConformer first decomposes EEG signals into multiple frequency bands and assigns each band to an independent CNN-Transformer encoder for band-specific modeling. The resulting band-wise features are then adaptively fused by a carefully designed frequency-aware attention (FAA) module that models cross-band dependencies by treating band-wise features as tokens. Further, band-wise auxiliary supervision (BAS) is introduced to prevent weakly contributing branches from being under-optimized during joint training. In this way, FAConformer performs frequency-aware modeling that more effectively exploits frequency domain information. Extensive experiments on two public AAD datasets with three decision-window lengths demonstrated that FAConformer consistently outperformed 12 competitive baselines, surpassing the current state-of-the-art model by 4.9%. Further analyses of band importance, ablation, and parameter sensitivity verify the effectiveness, robustness, and interpretability of the proposed framework. Code is available at https://github.com/wzwvv/FAConformer.
Feature Weighting Improves Pool-Based Sequential Active Learning for Regression
Apr 02, 2026Pool-based sequential active learning for regression (ALR) optimally selects a small number of samples sequentially from a large pool of unlabeled samples to label, so that a more accurate regression model can be constructed under a given labeling budget. Representativeness and diversity, which involve computing the distances among different samples, are important considerations in ALR. However, previous ALR approaches do not incorporate the importance of different features in inter-sample distance computation, resulting in sub-optimal sample selection. This paper proposes three feature weighted single-task ALR approaches and two feature weighted multi-task ALR approaches, where the ridge regression coefficients trained from a small amount of previously labeled samples are used to weight the corresponding features in inter-sample distance computation. Experiments showed that this easy-to-implement enhancement almost always improves the performance of four existing ALR approaches, in both single-task and multi-task regression problems. The feature weighting strategy may also be easily extended to stream-based ALR, and classification algorithms.
Synthetic Data Generation for Brain-Computer Interfaces: Overview, Benchmarking, and Future Directions
Mar 11, 2026Deep learning has achieved transformative performance across diverse domains, largely driven by the large-scale, high-quality training data. In contrast, the development of brain-computer interfaces (BCIs) is fundamentally constrained by the limited, heterogeneous, and privacy-sensitive neural recordings. Generating synthetic yet physiologically plausible brain signals has therefore emerged as a compelling way to mitigate data scarcity and enhance model capacity. This survey provides a comprehensive review of brain signal generation for BCIs, covering methodological taxonomies, benchmark experiments, evaluation metrics, and key applications. We systematically categorize existing generative algorithms into four types: knowledge-based, feature-based, model-based, and translation-based approaches. Furthermore, we benchmark existing brain signal generation approaches across four representative BCI paradigms to provide an objective performance comparison. Finally, we discuss the potentials and challenges of current generation approaches and prospect future research on accurate, data-efficient, and privacy-aware BCI systems. The benchmark codebase is publicized at https://github.com/wzwvv/DG4BCI.
StackingNet: Collective Inference Across Independent AI Foundation Models
Feb 14, 2026Artificial intelligence built on large foundation models has transformed language understanding, vision and reasoning, yet these systems remain isolated and cannot readily share their capabilities. Integrating the complementary strengths of such independent foundation models is essential for building trustworthy intelligent systems. Despite rapid progress in individual model design, there is no established approach for coordinating such black-box heterogeneous models. Here we show that coordination can be achieved through a meta-ensemble framework termed StackingNet, which draws on principles of collective intelligence to combine model predictions during inference. StackingNet improves accuracy, reduces bias, enables reliability ranking, and identifies or prunes models that degrade performance, all operating without access to internal parameters or training data. Across tasks involving language comprehension, visual estimation, and academic paper rating, StackingNet consistently improves accuracy, robustness, and fairness, compared with individual models and classic ensembles. By turning diversity from a source of inconsistency into collaboration, StackingNet establishes a practical foundation for coordinated artificial intelligence, suggesting that progress may emerge from not only larger single models but also principled cooperation among many specialized ones.
RAICL: Retrieval-Augmented In-Context Learning for Vision-Language-Model Based EEG Seizure Detection
Jan 25, 2026Electroencephalogram (EEG) decoding is a critical component of medical diagnostics, rehabilitation engineering, and brain-computer interfaces. However, contemporary decoding methodologies remain heavily dependent on task-specific datasets to train specialized neural network architectures. Consequently, limited data availability impedes the development of generalizable large brain decoding models. In this work, we propose a paradigm shift from conventional signal-based decoding by leveraging large-scale vision-language models (VLMs) to analyze EEG waveform plots. By converting multivariate EEG signals into stacked waveform images and integrating neuroscience domain expertise into textual prompts, we demonstrate that foundational VLMs can effectively differentiate between different patterns in the human brain. To address the inherent non-stationarity of EEG signals, we introduce a Retrieval-Augmented In-Context Learning (RAICL) approach, which dynamically selects the most representative and relevant few-shot examples to condition the autoregressive outputs of the VLM. Experiments on EEG-based seizure detection indicate that state-of-the-art VLMs under RAICL achieved better or comparable performance with traditional time series based approaches. These findings suggest a new direction in physiological signal processing that effectively bridges the modalities of vision, language, and neural activities. Furthermore, the utilization of off-the-shelf VLMs, without the need for retraining or downstream architecture construction, offers a readily deployable solution for clinical applications.
EEG Foundation Models: Progresses, Benchmarking, and Open Problems
Jan 25, 2026Electroencephalography (EEG) foundation models have recently emerged as a promising paradigm for brain-computer interfaces (BCIs), aiming to learn transferable neural representations from large-scale heterogeneous recordings. Despite rapid progresses, there lacks fair and comprehensive comparisons of existing EEG foundation models, due to inconsistent pre-training objectives, preprocessing choices, and downstream evaluation protocols. This paper fills this gap. We first review 50 representative models and organize their design choices into a unified taxonomic framework including data standardization, model architectures, and self-supervised pre-training strategies. We then evaluate 12 open-source foundation models and competitive specialist baselines across 13 EEG datasets spanning nine BCI paradigms. Emphasizing real-world deployments, we consider both cross-subject generalization under a leave-one-subject-out protocol and rapid calibration under a within-subject few-shot setting. We further compare full-parameter fine-tuning with linear probing to assess the transferability of pre-trained representations, and examine the relationship between model scale and downstream performance. Our results indicate that: 1) linear probing is frequently insufficient; 2) specialist models trained from scratch remain competitive across many tasks; and, 3) larger foundation models do not necessarily yield better generalization performance under current data regimes and training practices.
Backpropagation-Free Test-Time Adaptation for Lightweight EEG-Based Brain-Computer Interfaces
Jan 12, 2026Electroencephalogram (EEG)-based brain-computer interfaces (BCIs) face significant deployment challenges due to inter-subject variability, signal non-stationarity, and computational constraints. While test-time adaptation (TTA) mitigates distribution shifts under online data streams without per-use calibration sessions, existing TTA approaches heavily rely on explicitly defined loss objectives that require backpropagation for updating model parameters, which incurs computational overhead, privacy risks, and sensitivity to noisy data streams. This paper proposes Backpropagation-Free Transformations (BFT), a TTA approach for EEG decoding that eliminates such issues. BFT applies multiple sample-wise transformations of knowledge-guided augmentations or approximate Bayesian inference to each test trial, generating multiple prediction scores for a single test sample. A learning-to-rank module enhances the weighting of these predictions, enabling robust aggregation for uncertainty suppression during inference under theoretical justifications. Extensive experiments on five EEG datasets of motor imagery classification and driver drowsiness regression tasks demonstrate the effectiveness, versatility, robustness, and efficiency of BFT. This research enables lightweight plug-and-play BCIs on resource-constrained devices, broadening the real-world deployment of decoding algorithms for EEG-based BCI.
SAFE: Secure and Accurate Federated Learning for Privacy-Preserving Brain-Computer Interfaces
Jan 09, 2026Electroencephalogram (EEG)-based brain-computer interfaces (BCIs) are widely adopted due to their efficiency and portability; however, their decoding algorithms still face multiple challenges, including inadequate generalization, adversarial vulnerability, and privacy leakage. This paper proposes Secure and Accurate FEderated learning (SAFE), a federated learning-based approach that protects user privacy by keeping data local during model training. SAFE employs local batch-specific normalization to mitigate cross-subject feature distribution shifts and hence improves model generalization. It further enhances adversarial robustness by introducing perturbations in both the input space and the parameter space through federated adversarial training and adversarial weight perturbation. Experiments on five EEG datasets from motor imagery (MI) and event-related potential (ERP) BCI paradigms demonstrated that SAFE consistently outperformed 14 state-of-the-art approaches in both decoding accuracy and adversarial robustness, while ensuring privacy protection. Notably, it even outperformed centralized training approaches that do not consider privacy protection at all. To our knowledge, SAFE is the first algorithm to simultaneously achieve high decoding accuracy, strong adversarial robustness, and reliable privacy protection without using any calibration data from the target subject, making it highly desirable for real-world BCIs.
MIRepNet: A Pipeline and Foundation Model for EEG-Based Motor Imagery Classification
Jul 27, 2025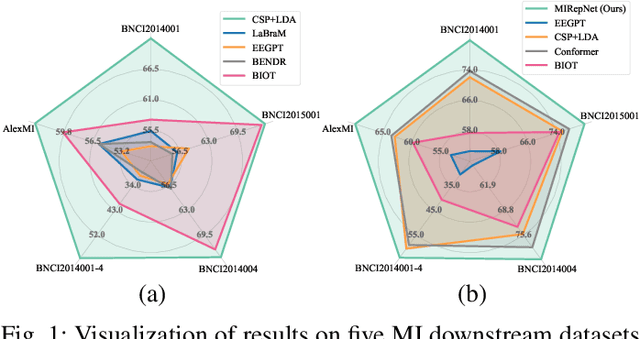



Brain-computer interfaces (BCIs) enable direct communication between the brain and external devices. Recent EEG foundation models aim to learn generalized representations across diverse BCI paradigms. However, these approaches overlook fundamental paradigm-specific neurophysiological distinctions, limiting their generalization ability. Importantly, in practical BCI deployments, the specific paradigm such as motor imagery (MI) for stroke rehabilitation or assistive robotics, is generally determined prior to data acquisition. This paper proposes MIRepNet, the first EEG foundation model tailored for the MI paradigm. MIRepNet comprises a high-quality EEG preprocessing pipeline incorporating a neurophysiologically-informed channel template, adaptable to EEG headsets with arbitrary electrode configurations. Furthermore, we introduce a hybrid pretraining strategy that combines self-supervised masked token reconstruction and supervised MI classification, facilitating rapid adaptation and accurate decoding on novel downstream MI tasks with fewer than 30 trials per class. Extensive evaluations across five public MI datasets demonstrated that MIRepNet consistently achieved state-of-the-art performance, significantly outperforming both specialized and generalized EEG models. Our code will be available on GitHub\footnote{https://github.com/staraink/MIRepNet}.
AFPM: Alignment-based Frame Patch Modeling for Cross-Dataset EEG Decoding
Jul 16, 2025Electroencephalogram (EEG) decoding models for brain-computer interfaces (BCIs) struggle with cross-dataset learning and generalization due to channel layout inconsistencies, non-stationary signal distributions, and limited neurophysiological prior integration. To address these issues, we propose a plug-and-play Alignment-Based Frame-Patch Modeling (AFPM) framework, which has two main components: 1) Spatial Alignment, which selects task-relevant channels based on brain-region priors, aligns EEG distributions across domains, and remaps the selected channels to a unified layout; and, 2) Frame-Patch Encoding, which models multi-dataset signals into unified spatiotemporal patches for EEG decoding. Compared to 17 state-of-the-art approaches that need dataset-specific tuning, the proposed calibration-free AFPM achieves performance gains of up to 4.40% on motor imagery and 3.58% on event-related potential tasks. To our knowledge, this is the first calibration-free cross-dataset EEG decoding framework, substantially enhancing the practicalness of BCIs in real-world applications.