 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffusionLight: Light Probes for Free by Painting a Chrome Ball
Dec 14, 2023
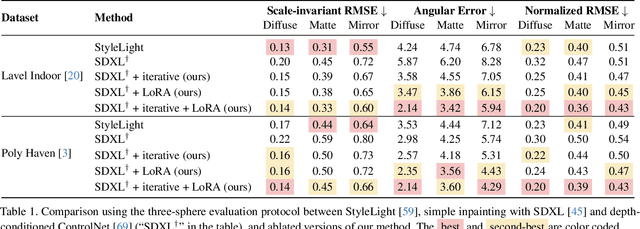


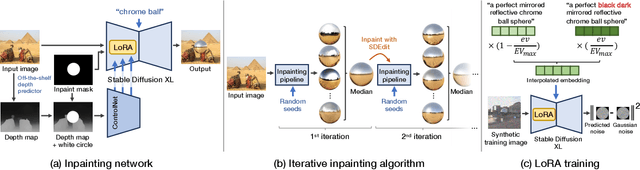
We present a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.
Tokenize Anything via Prompting
Dec 14, 2023We present a unified, promptable model capable of simultaneously segmenting, recognizing, and captioning anything. Unlike SAM, we aim to build a versatile region representation in the wild via visual prompting. To achieve this, we train a generalizable model with massive segmentation masks, e.g., SA-1B masks, and semantic priors from a pre-trained CLIP model with 5 billion parameters. Specifically, we construct a promptable image decoder by adding a semantic token to each mask token. The semantic token is responsible for learning the semantic priors in a predefined concept space. Through joint optimization of segmentation on mask tokens and concept prediction on semantic tokens, our model exhibits strong regional recognition and localization capabilities. For example, an additional 38M-parameter causal text decoder trained from scratch sets a new record with a CIDEr score of 150.7 on the Visual Genome region captioning task. We believe this model can be a versatile region-level image tokenizer, capable of encoding general-purpose region context for a broad range of perception tasks. Code and models are available at https://github.com/baaivision/tokenize-anything.
Fusion of Deep and Shallow Features for Face Kinship Verification
Dec 16, 2023Kinship verification from face images is a novel and formidable challenge in the realms of pattern recognition and computer vision. This work makes notable contributions by incorporating a preprocessing technique known as Multiscale Retinex (MSR), which enhances image quality. Our approach harnesses the strength of complementary deep (VGG16) and shallow texture descriptors (BSIF) by combining them at the score level using Logistic Regression (LR) technique. We assess the effectiveness of our approach by conducting comprehensive experiments on three challenging kinship datasets: Cornell Kin Face, UB Kin Face and TS Kin Face
High-fidelity Person-centric Subject-to-Image Synthesis
Nov 17, 2023Current subject-driven image generation methods encounter significant challenges in person-centric image generation. The reason is that they learn the semantic scene and person generation by fine-tuning a common pre-trained diffusion, which involves an irreconcilable training imbalance. Precisely, to generate realistic persons, they need to sufficiently tune the pre-trained model, which inevitably causes the model to forget the rich semantic scene prior and makes scene generation over-fit to the training data. Moreover, even with sufficient fine-tuning, these methods can still not generate high-fidelity persons since joint learning of the scene and person generation also lead to quality compromise. In this paper, we propose Face-diffuser, an effective collaborative generation pipeline to eliminate the above training imbalance and quality compromise. Specifically, we first develop two specialized pre-trained diffusion models, i.e., Text-driven Diffusion Model (TDM) and Subject-augmented Diffusion Model (SDM), for scene and person generation, respectively. The sampling process is divided into three sequential stages, i.e., semantic scene construction, subject-scene fusion, and subject enhancement. The first and last stages are performed by TDM and SDM respectively. The subject-scene fusion stage, that is the collaboration achieved through a novel and highly effective mechanism, Saliency-adaptive Noise Fusion (SNF). Specifically, it is based on our key observation that there exists a robust link between classifier-free guidance responses and the saliency of generated images. In each time step, SNF leverages the unique strengths of each model and allows for the spatial blending of predicted noises from both models automatically in a saliency-aware manner. Extensive experiments confirm the impressive effectiveness and robustness of the Face-diffuser.
Carve3D: Improving Multi-view Reconstruction Consistency for Diffusion Models with RL Finetuning
Dec 21, 2023Recent advancements in the text-to-3D task leverage finetuned text-to-image diffusion models to generate multi-view images, followed by NeRF reconstruction. Yet, existing supervised finetuned (SFT) diffusion models still suffer from multi-view inconsistency and the resulting NeRF artifacts. Although training longer with SFT improves consistency, it also causes distribution shift, which reduces diversity and realistic details. We argue that the SFT of multi-view diffusion models resembles the instruction finetuning stage of the LLM alignment pipeline and can benefit from RL finetuning (RLFT) methods. Essentially, RLFT methods optimize models beyond their SFT data distribution by using their own outputs, effectively mitigating distribution shift. To this end, we introduce Carve3D, a RLFT method coupled with the Multi-view Reconstruction Consistency (MRC) metric, to improve the consistency of multi-view diffusion models. To compute MRC on a set of multi-view images, we compare them with their corresponding renderings of the reconstructed NeRF at the same viewpoints. We validate the robustness of MRC with extensive experiments conducted under controlled inconsistency levels. We enhance the base RLFT algorithm to stabilize the training process, reduce distribution shift, and identify scaling laws. Through qualitative and quantitative experiments, along with a user study, we demonstrate Carve3D's improved multi-view consistency, the resulting superior NeRF reconstruction quality, and minimal distribution shift compared to longer SFT. Project webpage: https://desaixie.github.io/carve-3d.
A Dense Subframe-based SLAM Framework with Side-scan Sonar
Dec 21, 2023Side-scan sonar (SSS) is a lightweight acoustic sensor that is commonly deployed on autonomous underwater vehicles (AUVs) to provide high-resolution seafloor images. However, leveraging side-scan images for simultaneous localization and mapping (SLAM) presents a notable challenge, primarily due to the difficulty of establishing sufficient amount of accurate correspondences between these images. To address this, we introduce a novel subframe-based dense SLAM framework utilizing side-scan sonar data, enabling effective dense matching in overlapping regions of paired side-scan images. With each image being evenly divided into subframes, we propose a robust estimation pipeline to estimate the relative pose between each paired subframes, by using a good inlier set identified from dense correspondences. These relative poses are then integrated as edge constraints in a factor graph to optimize the AUV pose trajectory. The proposed framework is evaluated on three real datasets collected by a Hugin AUV. Among one of them includes manually-annotated keypoint correspondences as ground truth and is used for evaluation of pose trajectory. We also present a feasible way of evaluating mapping quality against multi-beam echosounder (MBES) data without the influence of pose. Experimental results demonstrate that our approach effectively mitigates drift from the dead-reckoning (DR) system and enables quasi-dense bathymetry reconstruction. An open-source implementation of this work is available.
DECO: Query-Based End-to-End Object Detection with ConvNets
Dec 21, 2023Detection Transformer (DETR) and its variants have shown great potential for accurate object detection in recent years. The mechanism of object query enables DETR family to directly obtain a fixed number of object predictions and streamlines the detection pipeline. Meanwhile, recent studies also reveal that with proper architecture design, convolution networks (ConvNets) also achieve competitive performance with transformers, \eg, ConvNeXt. To this end, in this paper we explore whether we could build a query-based end-to-end object detection framework with ConvNets instead of sophisticated transformer architecture. The proposed framework, \ie, Detection ConvNet (DECO), is composed of a backbone and convolutional encoder-decoder architecture. We carefully design the DECO encoder and propose a novel mechanism for our DECO decoder to perform interaction between object queries and image features via convolutional layers. We compare the proposed DECO against prior detectors on the challenging COCO benchmark. Despite its simplicity, our DECO achieves competitive performance in terms of detection accuracy and running speed. Specifically, with the ResNet-50 and ConvNeXt-Tiny backbone, DECO obtains $38.6\%$ and $40.8\%$ AP on COCO \textit{val} set with $35$ and $28$ FPS respectively and outperforms the DETR model. Incorporated with advanced multi-scale feature module, our DECO+ achieves $47.8\%$ AP with $34$ FPS. We hope the proposed DECO brings another perspective for designing object detection framework.
Gradient-based Parameter Selection for Efficient Fine-Tuning
Dec 15, 2023With the growing size of pre-trained models, full fine-tuning and storing all the parameters for various downstream tasks is costly and infeasible. In this paper, we propose a new parameter-efficient fine-tuning method, Gradient-based Parameter Selection (GPS), demonstrating that only tuning a few selected parameters from the pre-trained model while keeping the remainder of the model frozen can generate similar or better performance compared with the full model fine-tuning method. Different from the existing popular and state-of-the-art parameter-efficient fine-tuning approaches, our method does not introduce any additional parameters and computational costs during both the training and inference stages. Another advantage is the model-agnostic and non-destructive property, which eliminates the need for any other design specific to a particular model. Compared with the full fine-tuning, GPS achieves 3.33% (91.78% vs. 88.45%, FGVC) and 9.61% (73.1% vs. 65.57%, VTAB) improvement of the accuracy with tuning only 0.36% parameters of the pre-trained model on average over 24 image classification tasks; it also demonstrates a significant improvement of 17% and 16.8% in mDice and mIoU, respectively, on medical image segmentation task. Moreover, GPS achieves state-of-the-art performance compared with existing PEFT methods.
UniAR: Unifying Human Attention and Response Prediction on Visual Content
Dec 15, 2023Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior such as human attention and explicit, later-stage behavior such as subjective ratings/preferences. Yet, most prior research has focused on modeling implicit and explicit human behavior in isolation. Can we build a unified model of human attention and preference behavior that reliably works across diverse types of visual content? Such a model would enable predicting subjective feedback such as overall satisfaction or aesthetic quality ratings, along with the underlying human attention or interaction heatmaps and viewing order, enabling designers and content-creation models to optimize their creation for human-centric improvements. In this paper, we propose UniAR -- a unified model that predicts both implicit and explicit human behavior across different types of visual content. UniAR leverages a multimodal transformer, featuring distinct prediction heads for each facet, and predicts attention heatmap, scanpath or viewing order, and subjective rating/preference. We train UniAR on diverse public datasets spanning natural images, web pages and graphic designs, and achieve leading performance on multiple benchmarks across different image domains and various behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/digital designs/images, and serving as a reward model to further optimize design/image creation.
Towards the Unification of Generative and Discriminative Visual Foundation Model: A Survey
Dec 15, 2023The advent of foundation models, which are pre-trained on vast datasets, has ushered in a new era of computer vision, characterized by their robustness and remarkable zero-shot generalization capabilities. Mirroring the transformative impact of foundation models like large language models (LLMs) in natural language processing, visual foundation models (VFMs) have become a catalyst for groundbreaking developments in computer vision. This review paper delineates the pivotal trajectories of VFMs, emphasizing their scalability and proficiency in generative tasks such as text-to-image synthesis, as well as their adeptness in discriminative tasks including image segmentation. While generative and discriminative models have historically charted distinct paths, we undertake a comprehensive examination of the recent strides made by VFMs in both domains, elucidating their origins, seminal breakthroughs, and pivotal methodologies. Additionally, we collate and discuss the extensive resources that facilitate the development of VFMs and address the challenges that pave the way for future research endeavors. A crucial direction for forthcoming innovation is the amalgamation of generative and discriminative paradigms. The nascent application of generative models within discriminative contexts signifies the early stages of this confluence. This survey aspires to be a contemporary compendium for scholars and practitioners alike, charting the course of VFMs and illuminating their multifaceted landscape.