 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAM-SAM: Automated Prompting and Mask Calibration for Segment Anything Model
Oct 13, 2024



Segment Anything Model (SAM) has gained significant recognition in the field of semantic segmentation due to its versatile capabilities and impressive performance. Despite its success, SAM faces two primary limitations: (1) it relies heavily on meticulous human-provided prompts like key points, bounding boxes or text messages, which is labor-intensive; (2) the mask decoder's feature representation is sometimes inaccurate, as it solely employs dot product operations at the end of mask decoder, which inadequately captures the necessary correlations for precise segmentation. Current solutions to these problems such as fine-tuning SAM often require retraining a large number of parameters, which needs huge amount of time and computing resources. To address these limitations, we propose an automated prompting and mask calibration method called AM-SAM based on a bi-level optimization framework. Our approach automatically generates prompts for an input image, eliminating the need for human involvement with a good performance in early training epochs, achieving faster convergence. Additionally, we freeze the main part of SAM, and modify the mask decoder with Low-Rank Adaptation (LoRA), enhancing the mask decoder's feature representation by incorporating advanced techniques that go beyond simple dot product operations to more accurately capture and utilize feature correlations. Our experimental results demonstrate that AM-SAM achieves significantly accurate segmentation, matching or exceeding the effectiveness of human-generated and default prompts. Notably, on the body segmentation dataset, our method yields a 5% higher dice score with a 4-example few-shot training set compared to the SOTA method, underscoring its superiority in semantic segmentation tasks.
Beyond Thumbs Up/Down: Untangling Challenges of Fine-Grained Feedback for Text-to-Image Generation
Jun 24, 2024Human feedback plays a critical role in learning and refining reward models for text-to-image generation, but the optimal form the feedback should take for learning an accurate reward function has not been conclusively established. This paper investigates the effectiveness of fine-grained feedback which captures nuanced distinctions in image quality and prompt-alignment, compared to traditional coarse-grained feedback (for example, thumbs up/down or ranking between a set of options). While fine-grained feedback holds promise, particularly for systems catering to diverse societal preferences, we show that demonstrating its superiority to coarse-grained feedback is not automatic. Through experiments on real and synthetic preference data, we surface the complexities of building effective models due to the interplay of model choice, feedback type, and the alignment between human judgment and computational interpretation. We identify key challenges in eliciting and utilizing fine-grained feedback, prompting a reassessment of its assumed benefits and practicality. Our findings -- e.g., that fine-grained feedback can lead to worse models for a fixed budget, in some settings; however, in controlled settings with known attributes, fine grained rewards can indeed be more helpful -- call for careful consideration of feedback attributes and potentially beckon novel modeling approaches to appropriately unlock the potential value of fine-grained feedback in-the-wild.
Generalizable and Stable Finetuning of Pretrained Language Models on Low-Resource Texts
Mar 19, 2024Pretrained Language Models (PLMs) have advanced Natural Language Processing (NLP) tasks significantly, but finetuning PLMs on low-resource datasets poses significant challenges such as instability and overfitting. Previous methods tackle these issues by finetuning a strategically chosen subnetwork on a downstream task, while keeping the remaining weights fixed to the pretrained weights. However, they rely on a suboptimal criteria for sub-network selection, leading to suboptimal solutions. To address these limitations, we propose a regularization method based on attention-guided weight mixup for finetuning PLMs. Our approach represents each network weight as a mixup of task-specific weight and pretrained weight, controlled by a learnable attention parameter, providing finer control over sub-network selection. Furthermore, we employ a bi-level optimization (BLO) based framework on two separate splits of the training dataset, improving generalization and combating overfitting. We validate the efficacy of our proposed method through extensive experiments, demonstrating its superiority over previous methods, particularly in the context of finetuning PLMs on low-resource datasets.
BLO-SAM: Bi-level Optimization Based Overfitting-Preventing Finetuning of SAM
Mar 11, 2024The Segment Anything Model (SAM), a foundation model pretrained on millions of images and segmentation masks, has significantly advanced semantic segmentation, a fundamental task in computer vision. Despite its strengths, SAM encounters two major challenges. Firstly, it struggles with segmenting specific objects autonomously, as it relies on users to manually input prompts like points or bounding boxes to identify targeted objects. Secondly, SAM faces challenges in excelling at specific downstream tasks, like medical imaging, due to a disparity between the distribution of its pretraining data, which predominantly consists of general-domain images, and the data used in downstream tasks. Current solutions to these problems, which involve finetuning SAM, often lead to overfitting, a notable issue in scenarios with very limited data, like in medical imaging. To overcome these limitations, we introduce BLO-SAM, which finetunes SAM based on bi-level optimization (BLO). Our approach allows for automatic image segmentation without the need for manual prompts, by optimizing a learnable prompt embedding. Furthermore, it significantly reduces the risk of overfitting by training the model's weight parameters and the prompt embedding on two separate subsets of the training dataset, each at a different level of optimization. We apply BLO-SAM to diverse semantic segmentation tasks in general and medical domains. The results demonstrate BLO-SAM's superior performance over various state-of-the-art image semantic segmentation methods.
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mar 07, 2024



Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Current watermarking algorithms, however, face the challenge of achieving both the detectability of inserted watermarks and the semantic integrity of generated texts, where enhancing one aspect often undermines the other. To overcome this, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
UniAR: Unifying Human Attention and Response Prediction on Visual Content
Dec 15, 2023Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior such as human attention and explicit, later-stage behavior such as subjective ratings/preferences. Yet, most prior research has focused on modeling implicit and explicit human behavior in isolation. Can we build a unified model of human attention and preference behavior that reliably works across diverse types of visual content? Such a model would enable predicting subjective feedback such as overall satisfaction or aesthetic quality ratings, along with the underlying human attention or interaction heatmaps and viewing order, enabling designers and content-creation models to optimize their creation for human-centric improvements. In this paper, we propose UniAR -- a unified model that predicts both implicit and explicit human behavior across different types of visual content. UniAR leverages a multimodal transformer, featuring distinct prediction heads for each facet, and predicts attention heatmap, scanpath or viewing order, and subjective rating/preference. We train UniAR on diverse public datasets spanning natural images, web pages and graphic designs, and achieve leading performance on multiple benchmarks across different image domains and various behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/digital designs/images, and serving as a reward model to further optimize design/image creation.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023



Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).
Large Language Models for Compiler Optimization
Sep 11, 2023



We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
Learning to compile smartly for program size reduction
Jan 09, 2023Compiler optimization passes are an important tool for improving program efficiency and reducing program size, but manually selecting optimization passes can be time-consuming and error-prone. While human experts have identified a few fixed sequences of optimization passes (e.g., the Clang -Oz passes) that perform well for a wide variety of programs, these sequences are not conditioned on specific programs. In this paper, we propose a novel approach that learns a policy to select passes for program size reduction, allowing for customization and adaptation to specific programs. Our approach uses a search mechanism that helps identify useful pass sequences and a GNN with customized attention that selects the optimal sequence to use. Crucially it is able to generalize to new, unseen programs, making it more flexible and general than previous approaches. We evaluate our approach on a range of programs and show that it leads to size reduction compared to traditional optimization techniques. Our results demonstrate the potential of a single policy that is able to optimize many programs.
Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations
Feb 16, 2022

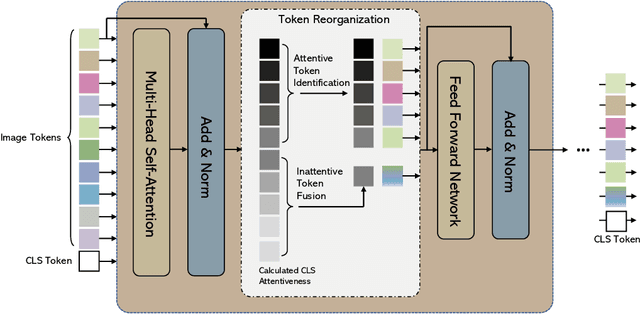
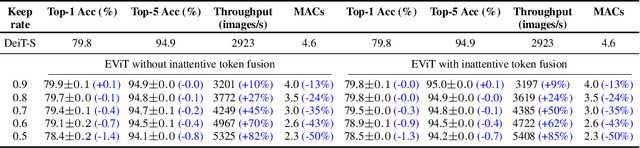
Vision Transformers (ViTs) take all the image patches as tokens and construct multi-head self-attention (MHSA) among them. Complete leverage of these image tokens brings redundant computations since not all the tokens are attentive in MHSA. Examples include that tokens containing semantically meaningless or distractive image backgrounds do not positively contribute to the ViT predictions. In this work, we propose to reorganize image tokens during the feed-forward process of ViT models, which is integrated into ViT during training. For each forward inference, we identify the attentive image tokens between MHSA and FFN (i.e., feed-forward network) modules, which is guided by the corresponding class token attention. Then, we reorganize image tokens by preserving attentive image tokens and fusing inattentive ones to expedite subsequent MHSA and FFN computations. To this end, our method EViT improves ViTs from two perspectives. First, under the same amount of input image tokens, our method reduces MHSA and FFN computation for efficient inference. For instance, the inference speed of DeiT-S is increased by 50% while its recognition accuracy is decreased by only 0.3% for ImageNet classification. Second, by maintaining the same computational cost, our method empowers ViTs to take more image tokens as input for recognition accuracy improvement, where the image tokens are from higher resolution images. An example is that we improve the recognition accuracy of DeiT-S by 1% for ImageNet classification at the same computational cost of a vanilla DeiT-S. Meanwhile, our method does not introduce more parameters to ViTs. Experiments on the standard benchmarks show the effectiveness of our method. The code is available at https://github.com/youweiliang/evit