 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions
May 19, 2026Conversational AI has now reached billions of users, yet existing datasets capture only what people say, not what they think. We introduce ThoughtTrace, the first large-scale dataset that pairs real-world multi-turn human--AI conversations with users' self-reported thoughts: their reasons for sending prompts and reactions to assistant responses. ThoughtTrace comprises 1,058 users, 2,155 conversations, 17,058 turns, and 10,174 thought annotations collected across 20 language models. Our analysis shows that ThoughtTrace captures long-horizon, topically diverse interactions, and that thoughts are semantically distinct from messages, difficult for frontier LLMs to infer from context, diverse in content, and tied to conversation stages. We further demonstrate the utility of thoughts for downstream modeling. First, thoughts improve user-behavior prediction as inference-time context. Second, thought-guided rewrites provide fine-grained alignment signals for training personalized assistants. Together, ThoughtTrace establishes user thoughts as a new data modality for studying the cognitive dynamics behind human--AI interaction and provides a foundation for building assistants that better understand and adapt to users' latent goals, preferences, and needs.
UniAR: Unifying Human Attention and Response Prediction on Visual Content
Dec 15, 2023Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior such as human attention and explicit, later-stage behavior such as subjective ratings/preferences. Yet, most prior research has focused on modeling implicit and explicit human behavior in isolation. Can we build a unified model of human attention and preference behavior that reliably works across diverse types of visual content? Such a model would enable predicting subjective feedback such as overall satisfaction or aesthetic quality ratings, along with the underlying human attention or interaction heatmaps and viewing order, enabling designers and content-creation models to optimize their creation for human-centric improvements. In this paper, we propose UniAR -- a unified model that predicts both implicit and explicit human behavior across different types of visual content. UniAR leverages a multimodal transformer, featuring distinct prediction heads for each facet, and predicts attention heatmap, scanpath or viewing order, and subjective rating/preference. We train UniAR on diverse public datasets spanning natural images, web pages and graphic designs, and achieve leading performance on multiple benchmarks across different image domains and various behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/digital designs/images, and serving as a reward model to further optimize design/image creation.
From Thumbnails to Summaries - A single Deep Neural Network to Rule Them All
Aug 01, 2018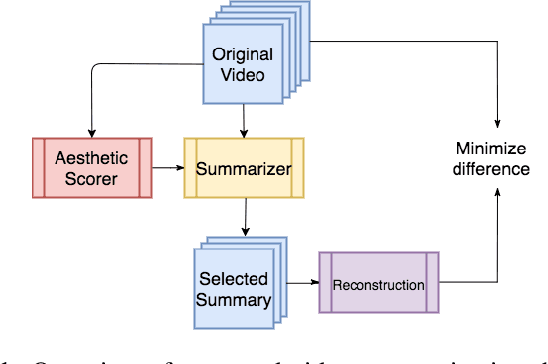
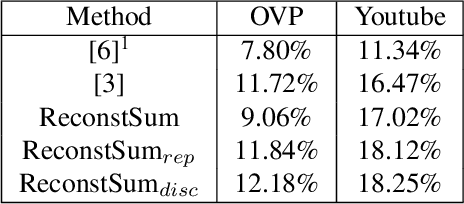
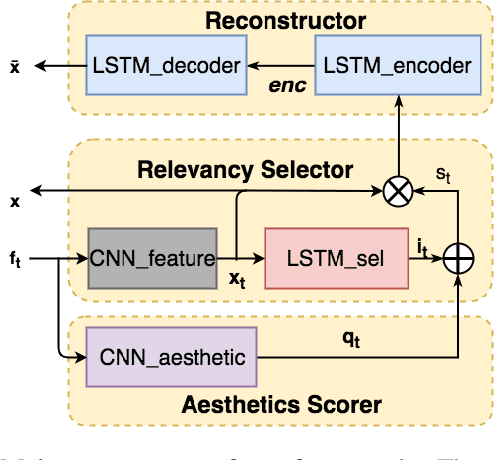
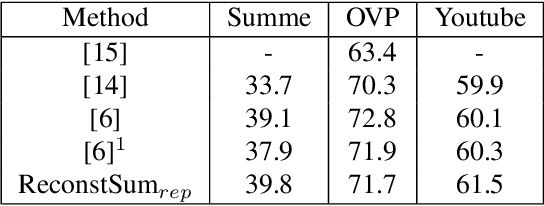
Video summaries come in many forms, from traditional single-image thumbnails, animated thumbnails, storyboards, to trailer-like video summaries. Content creators use the summaries to display the most attractive portion of their videos; the users use them to quickly evaluate if a video is worth watching. All forms of summaries are essential to video viewers, content creators, and advertisers. Often video content management systems have to generate multiple versions of summaries that vary in duration and presentational forms. We present a framework ReconstSum that utilizes LSTM-based autoencoder architecture to extract and select a sparse subset of video frames or keyshots that optimally represent the input video in an unsupervised manner. The encoder selects a subset from the input video while the decoder seeks to reconstruct the video from the selection. The goal is to minimize the difference between the original input video and the reconstructed video. Our method is easily extendable to generate a variety of applications including static video thumbnails, animated thumbnails, storyboards and "trailer-like" highlights. We specifically study and evaluate two most popular use cases: thumbnail generation and storyboard generation. We demonstrate that our methods generate better results than the state-of-the-art techniques in both use cases.