 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CorticalFlow: A Diffeomorphic Mesh Deformation Module for Cortical Surface Reconstruction
Jun 06, 2022
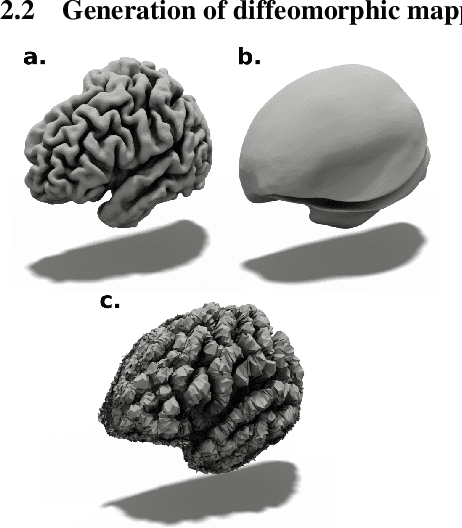
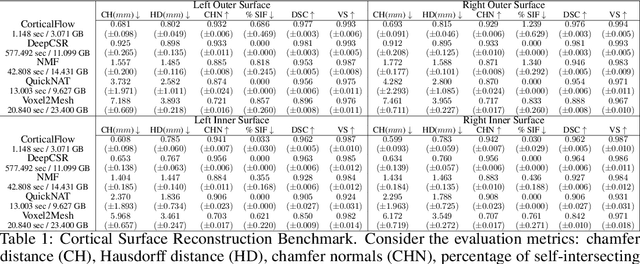
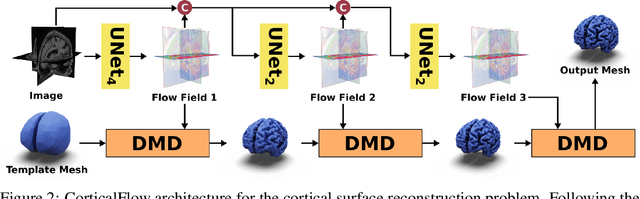
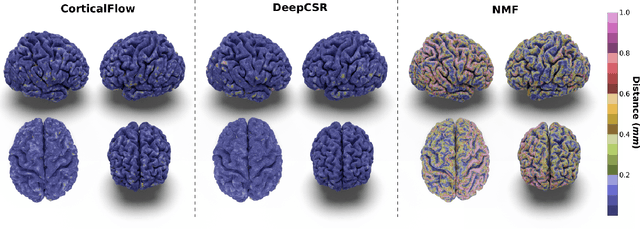
In this paper we introduce CorticalFlow, a new geometric deep-learning model that, given a 3-dimensional image, learns to deform a reference template towards a targeted object. To conserve the template mesh's topological properties, we train our model over a set of diffeomorphic transformations. This new implementation of a flow Ordinary Differential Equation (ODE) framework benefits from a small GPU memory footprint, allowing the generation of surfaces with several hundred thousand vertices. To reduce topological errors introduced by its discrete resolution, we derive numeric conditions which improve the manifoldness of the predicted triangle mesh. To exhibit the utility of CorticalFlow, we demonstrate its performance for the challenging task of brain cortical surface reconstruction. In contrast to current state-of-the-art, CorticalFlow produces superior surfaces while reducing the computation time from nine and a half minutes to one second. More significantly, CorticalFlow enforces the generation of anatomically plausible surfaces; the absence of which has been a major impediment restricting the clinical relevance of such surface reconstruction methods.
Translating Clinical Delineation of Diabetic Foot Ulcers into Machine Interpretable Segmentation
Apr 22, 2022
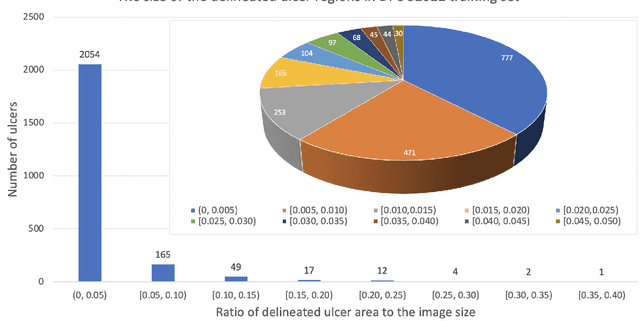
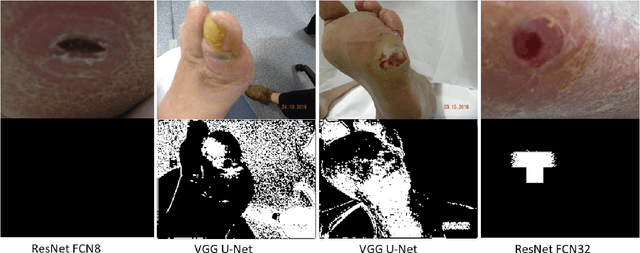
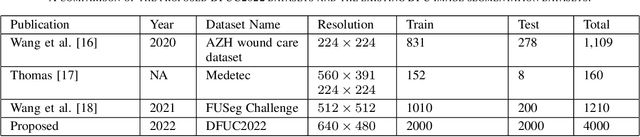
Diabetic foot ulcer is a severe condition that requires close monitoring and management. For training machine learning methods to auto-delineate the ulcer, clinical staff must provide ground truth annotations. In this paper, we propose a new diabetic foot ulcers dataset, namely DFUC2022, the largest segmentation dataset where ulcer regions were manually delineated by clinicians. We assess whether the clinical delineations are machine interpretable by deep learning networks or if image processing refined contour should be used. By providing benchmark results using a selection of popular deep learning algorithms, we draw new insights into the limitations of DFU wound delineation and report on the associated issues. This paper provides some observations on baseline models to facilitate DFUC2022 Challenge in conjunction with MICCAI 2022. The leaderboard will be ranked by Dice score, where the best FCN-based method is 0.5708 and DeepLabv3+ achieved the best score of 0.6277. This paper demonstrates that image processing using refined contour as ground truth can provide better agreement with machine predicted results. DFUC2022 will be released on the 27th April 2022.
Region Specific Optimization (RSO)-based Deep Interactive Registration
Mar 08, 2022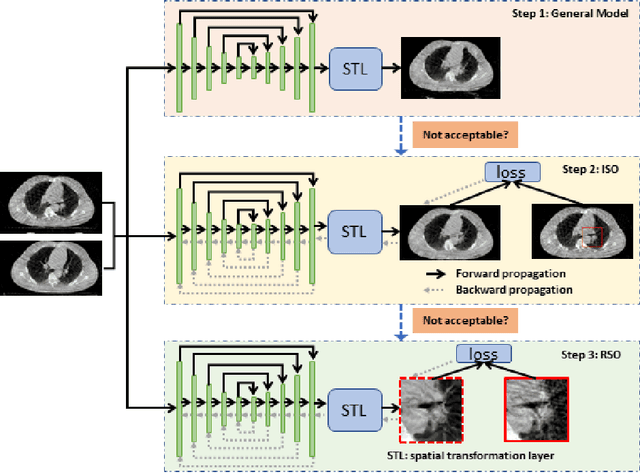
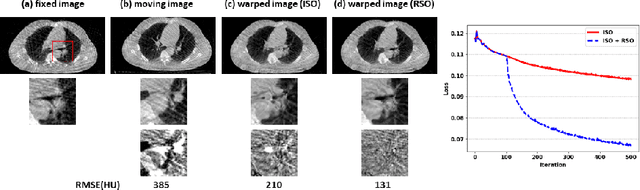

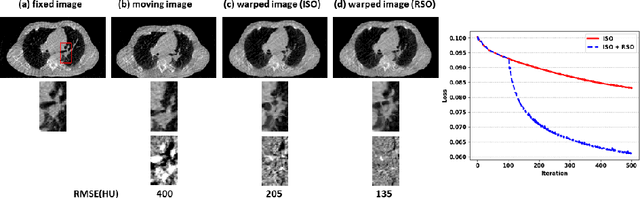
Medical image registration is a fundamental and vital task which will affect the efficacy of many downstream clinical tasks. Deep learning (DL)-based deformable image registration (DIR) methods have been investigated, showing state-of-the-art performance. A test time optimization (TTO) technique was proposed to further improve the DL models' performance. Despite the substantial accuracy improvement with this TTO technique, there still remained some regions that exhibited large registration errors even after many TTO iterations. To mitigate this challenge, we firstly identified the reason why the TTO technique was slow, or even failed, to improve those regions' registration results. We then proposed a two-levels TTO technique, i.e., image-specific optimization (ISO) and region-specific optimization (RSO), where the region can be interactively indicated by the clinician during the registration result reviewing process. For both efficiency and accuracy, we further envisioned a three-step DL-based image registration workflow. Experimental results showed that our proposed method outperformed the conventional method qualitatively and quantitatively.
AnomalyHop: An SSL-based Image Anomaly Localization Method
May 08, 2021

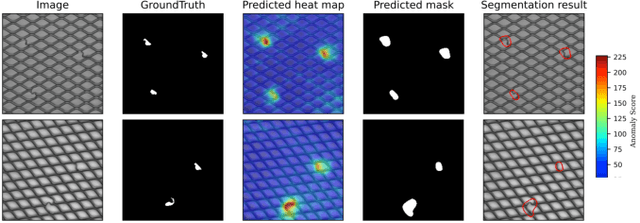
An image anomaly localization method based on the successive subspace learning (SSL) framework, called AnomalyHop, is proposed in this work. AnomalyHop consists of three modules: 1) feature extraction via successive subspace learning (SSL), 2) normality feature distributions modeling via Gaussian models, and 3) anomaly map generation and fusion. Comparing with state-of-the-art image anomaly localization methods based on deep neural networks (DNNs), AnomalyHop is mathematically transparent, easy to train, and fast in its inference speed. Besides, its area under the ROC curve (ROC-AUC) performance on the MVTec AD dataset is 95.9%, which is among the best of several benchmarking methods. Our codes are publicly available at Github.
Anomaly Detection with Test Time Augmentation and Consistency Evaluation
Jun 06, 2022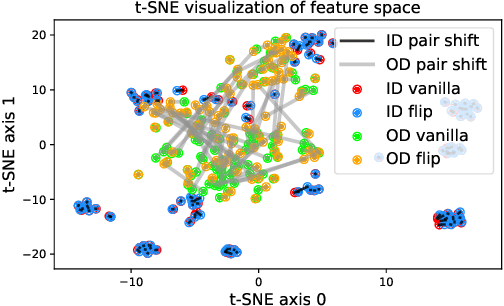
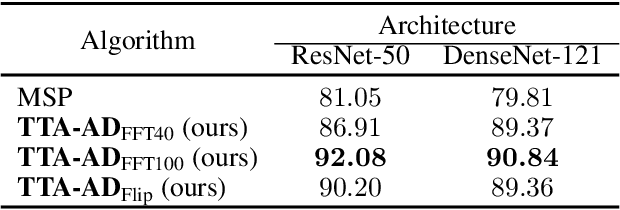

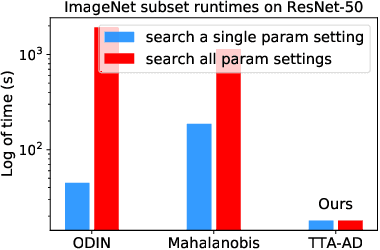
Deep neural networks are known to be vulnerable to unseen data: they may wrongly assign high confidence stcores to out-distribuion samples. Recent works try to solve the problem using representation learning methods and specific metrics. In this paper, we propose a simple, yet effective post-hoc anomaly detection algorithm named Test Time Augmentation Anomaly Detection (TTA-AD), inspired by a novel observation. Specifically, we observe that in-distribution data enjoy more consistent predictions for its original and augmented versions on a trained network than out-distribution data, which separates in-distribution and out-distribution samples. Experiments on various high-resolution image benchmark datasets demonstrate that TTA-AD achieves comparable or better detection performance under dataset-vs-dataset anomaly detection settings with a 60%~90\% running time reduction of existing classifier-based algorithms. We provide empirical verification that the key to TTA-AD lies in the remaining classes between augmented features, which has long been partially ignored by previous works. Additionally, we use RUNS as a surrogate to analyze our algorithm theoretically.
Deep Optical Coding Design in Computational Imaging
Jun 27, 2022
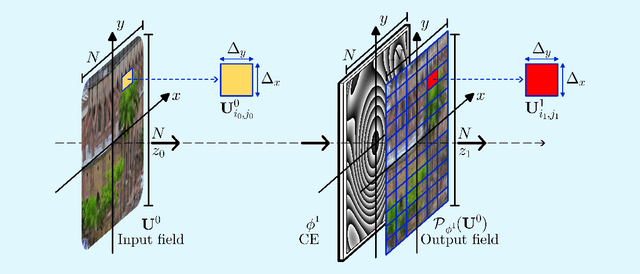
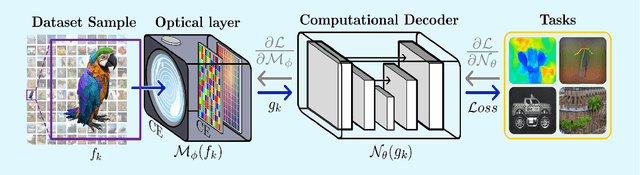
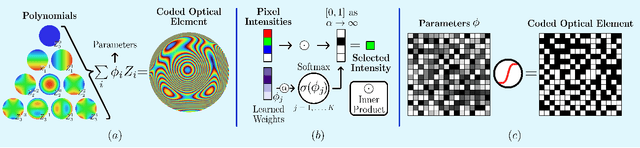
Computational optical imaging (COI) systems leverage optical coding elements (CE) in their setups to encode a high-dimensional scene in a single or multiple snapshots and decode it by using computational algorithms. The performance of COI systems highly depends on the design of its main components: the CE pattern and the computational method used to perform a given task. Conventional approaches rely on random patterns or analytical designs to set the distribution of the CE. However, the available data and algorithm capabilities of deep neural networks (DNNs) have opened a new horizon in CE data-driven designs that jointly consider the optical encoder and computational decoder. Specifically, by modeling the COI measurements through a fully differentiable image formation model that considers the physics-based propagation of light and its interaction with the CEs, the parameters that define the CE and the computational decoder can be optimized in an end-to-end (E2E) manner. Moreover, by optimizing just CEs in the same framework, inference tasks can be performed from pure optics. This work surveys the recent advances on CE data-driven design and provides guidelines on how to parametrize different optical elements to include them in the E2E framework. Since the E2E framework can handle different inference applications by changing the loss function and the DNN, we present low-level tasks such as spectral imaging reconstruction or high-level tasks such as pose estimation with privacy preserving enhanced by using optimal task-based optical architectures. Finally, we illustrate classification and 3D object recognition applications performed at the speed of the light using all-optics DNN.
Learning self-calibrated optic disc and cup segmentation from multi-rater annotations
Jun 14, 2022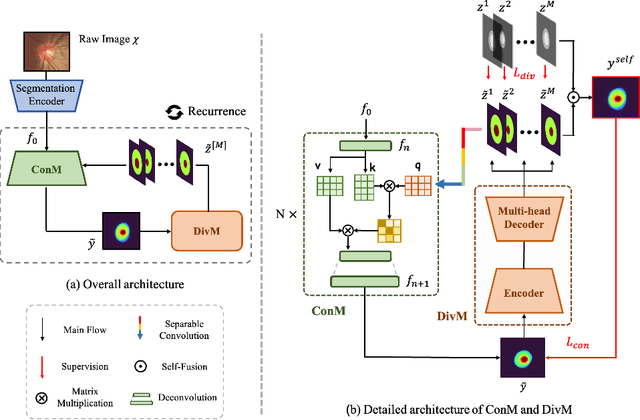
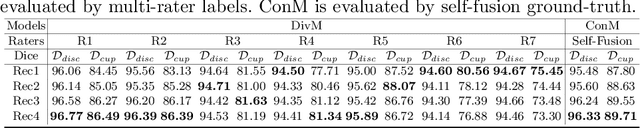
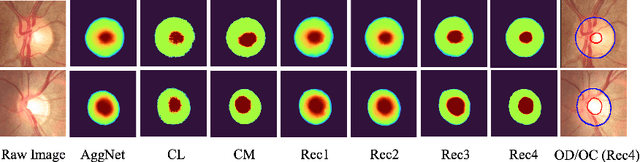
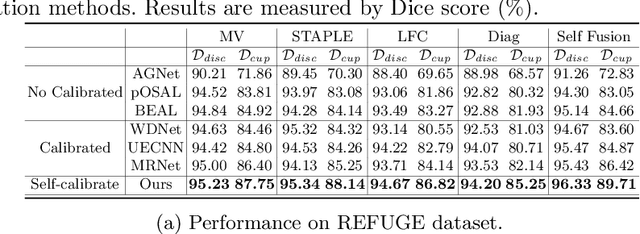
The segmentation of optic disc(OD) and optic cup(OC) from fundus images is an important fundamental task for glaucoma diagnosis. In the clinical practice, it is often necessary to collect opinions from multiple experts to obtain the final OD/OC annotation. This clinical routine helps to mitigate the individual bias. But when data is multiply annotated, standard deep learning models will be inapplicable. In this paper, we propose a novel neural network framework to learn OD/OC segmentation from multi-rater annotations. The segmentation results are self-calibrated through the iterative optimization of multi-rater expertness estimation and calibrated OD/OC segmentation. In this way, the proposed method can realize a mutual improvement of both tasks and finally obtain a refined segmentation result. Specifically, we propose Diverging Model(DivM) and Converging Model(ConM) to process the two tasks respectively. ConM segments the raw image based on the multi-rater expertness map provided by DivM. DivM generates multi-rater expertness map from the segmentation mask provided by ConM. The experiment results show that by recurrently running ConM and DivM, the results can be self-calibrated so as to outperform a range of state-of-the-art(SOTA) multi-rater segmentation methods.
CD$^2$: Fine-grained 3D Mesh Reconstruction with Twice Chamfer Distance
Jun 01, 2022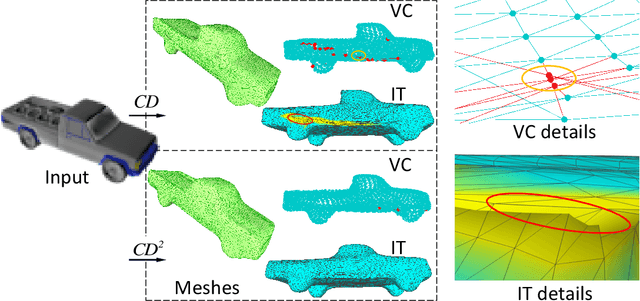


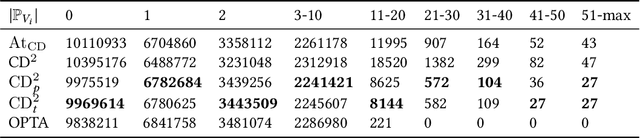
Monocular 3D reconstruction is to reconstruct the shape of object and its other detailed information from a single RGB image. In 3D reconstruction, polygon mesh is the most prevalent expression form obtained from deep learning models, with detailed surface information and low computational cost. However, some state-of-the-art works fail to generate well-structured meshes, these meshes have two severe problems which we call Vertices Clustering and Illegal Twist. By delving into the mesh deformation procedure, we pinpoint the inadequate usage of Chamfer Distance(CD) metric in deep learning model. In this paper, we initially demonstrate the problems resulting from CD with visual examples and quantitative analyses. To solve these problems, we propose a fine-grained reconstruction method CD$^2$ with Chamfer distance adopted twice to perform a plausible and adaptive deformation. Extensive experiments on two 3D datasets and the comparison of our newly proposed mesh quality metrics demonstrate that our CD$^2$ outperforms others by generating better-structured meshes.
Decoupling Predictions in Distributed Learning for Multi-Center Left Atrial MRI Segmentation
Jun 10, 2022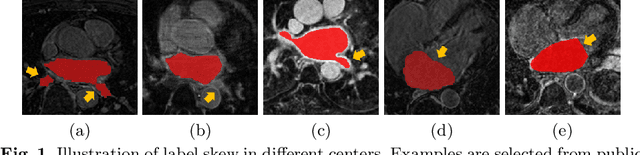
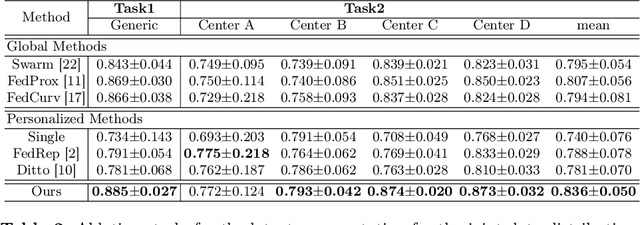
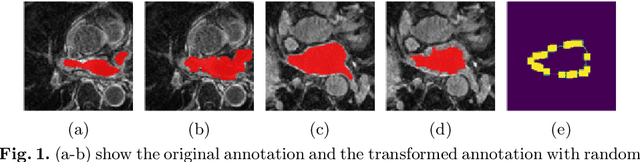

Distributed learning has shown great potential in medical image analysis. It allows to use multi-center training data with privacy protection. However, data distributions in local centers can vary from each other due to different imaging vendors, and annotation protocols. Such variation degrades the performance of learning-based methods. To mitigate the influence, two groups of methods have been proposed for different aims, i.e., the global methods and the personalized methods. The former are aimed to improve the performance of a single global model for all test data from unseen centers (known as generic data); while the latter target multiple models for each center (denoted as local data). However, little has been researched to achieve both goals simultaneously. In this work, we propose a new framework of distributed learning that bridges the gap between two groups, and improves the performance for both generic and local data. Specifically, our method decouples the predictions for generic data and local data, via distribution-conditioned adaptation matrices. Results on multi-center left atrial (LA) MRI segmentation showed that our method demonstrated superior performance over existing methods on both generic and local data. Our code is available at https://github.com/key1589745/decouple_predict
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Mar 10, 2022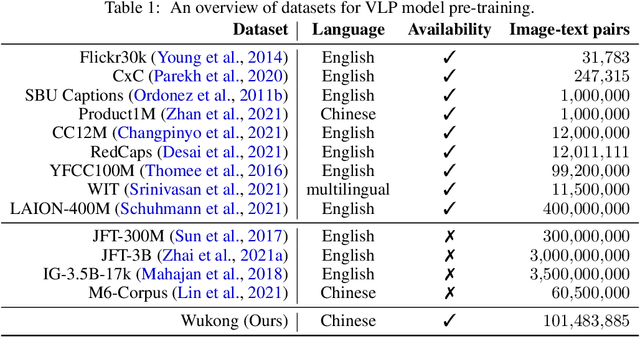
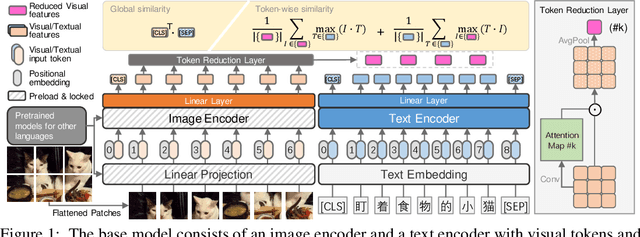


Vision-Language Pre-training (VLP) models have shown remarkable performance on various downstream tasks. Their success heavily relies on the scale of pre-trained cross-modal datasets. However, the lack of large-scale datasets and benchmarks in Chinese hinders the development of Chinese VLP models and broader multilingual applications. In this work, we release a large-scale Chinese cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Wukong aims to benchmark different multi-modal pre-training methods to facilitate the VLP research and community development. Furthermore, we release a group of models pre-trained with various image encoders (ViT-B/ViT-L/SwinT) and also apply advanced pre-training techniques into VLP such as locked-image text tuning, token-wise similarity in contrastive learning, and reduced-token interaction. Extensive experiments and a deep benchmarking of different downstream tasks are also provided. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods. For the zero-shot image classification task on 10 datasets, our model achieves an average accuracy of 73.03%. For the image-text retrieval task,our model achieves a mean recall of 71.6% on AIC-ICC which is 12.9% higher than the result of WenLan 2.0. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.