 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCMBench: A Comprehensive Financial Credit Multimodal Benchmark for Real-world Applications
Jan 06, 2026As multimodal AI becomes widely used for credit risk assessment and document review, a domain-specific benchmark is urgently needed that (1) reflects documents and workflows specific to financial credit applications, (2) includes credit-specific understanding and real-world robustness, and (3) preserves privacy compliance without sacrificing practical utility. Here, we introduce FCMBench-V1.0 -- a large-scale financial credit multimodal benchmark for real-world applications, covering 18 core certificate types, with 4,043 privacy-compliant images and 8,446 QA samples. The FCMBench evaluation framework consists of three dimensions: Perception, Reasoning, and Robustness, including 3 foundational perception tasks, 4 credit-specific reasoning tasks that require decision-oriented understanding of visual evidence, and 10 real-world acquisition artifact types for robustness stress testing. To reconcile compliance with realism, we construct all samples via a closed synthesis-capture pipeline: we manually synthesize document templates with virtual content and capture scenario-aware images in-house. This design also mitigates pre-training data leakage by avoiding web-sourced or publicly released images. FCMBench can effectively discriminate performance disparities and robustness across modern vision-language models. Extensive experiments were conducted on 23 state-of-the-art vision-language models (VLMs) from 14 top AI companies and research institutes. Among them, Gemini 3 Pro achieves the best F1(\%) score as a commercial model (64.61), Qwen3-VL-235B achieves the best score as an open-source baseline (57.27), and our financial credit-specific model, Qfin-VL-Instruct, achieves the top overall score (64.92). Robustness evaluations show that even top-performing models suffer noticeable performance drops under acquisition artifacts.
Learning self-calibrated optic disc and cup segmentation from multi-rater annotations
Jun 14, 2022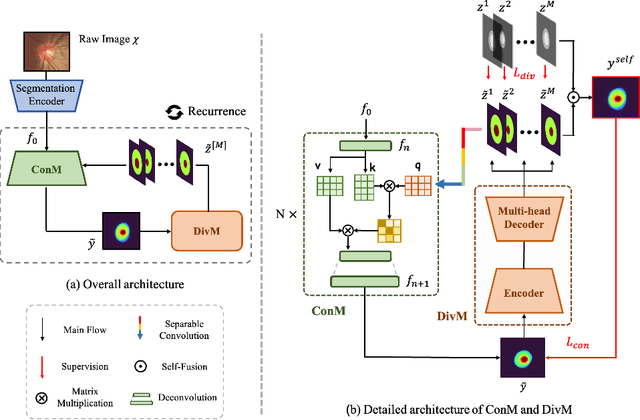
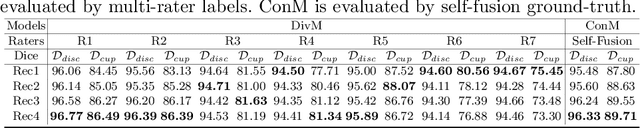
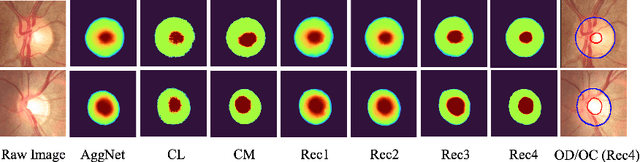
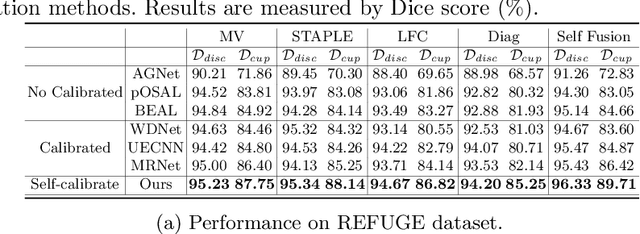
The segmentation of optic disc(OD) and optic cup(OC) from fundus images is an important fundamental task for glaucoma diagnosis. In the clinical practice, it is often necessary to collect opinions from multiple experts to obtain the final OD/OC annotation. This clinical routine helps to mitigate the individual bias. But when data is multiply annotated, standard deep learning models will be inapplicable. In this paper, we propose a novel neural network framework to learn OD/OC segmentation from multi-rater annotations. The segmentation results are self-calibrated through the iterative optimization of multi-rater expertness estimation and calibrated OD/OC segmentation. In this way, the proposed method can realize a mutual improvement of both tasks and finally obtain a refined segmentation result. Specifically, we propose Diverging Model(DivM) and Converging Model(ConM) to process the two tasks respectively. ConM segments the raw image based on the multi-rater expertness map provided by DivM. DivM generates multi-rater expertness map from the segmentation mask provided by ConM. The experiment results show that by recurrently running ConM and DivM, the results can be self-calibrated so as to outperform a range of state-of-the-art(SOTA) multi-rater segmentation methods.
Contrastive Centroid Supervision Alleviates Domain Shift in Medical Image Classification
May 31, 2022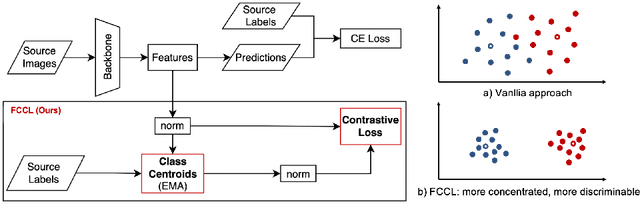


Deep learning based medical imaging classification models usually suffer from the domain shift problem, where the classification performance drops when training data and real-world data differ in imaging equipment manufacturer, image acquisition protocol, patient populations, etc. We propose Feature Centroid Contrast Learning (FCCL), which can improve target domain classification performance by extra supervision during training with contrastive loss between instance and class centroid. Compared with current unsupervised domain adaptation and domain generalization methods, FCCL performs better while only requires labeled image data from a single source domain and no target domain. We verify through extensive experiments that FCCL can achieve superior performance on at least three imaging modalities, i.e. fundus photographs, dermatoscopic images, and H & E tissue images.